







(从小到大)
①直接插入
- (第一层循环)从第一个元素i开始
- (第二层循环)取出i的下一个数,向前遍历,如果比前一个数小,就换位

public static void sort(int[] a) {
for (int i = 0; i < a.length - 1; i++) {
for (int j = i + 1; j > 0; j--) {
if (a[j] < a[j - 1]) {
int temp = a[j];
a[j] = a[j - 1];
a[j - 1] = temp;
}
}
}
}
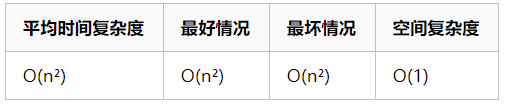
②简单选择
- (第一层循环)i遍历
- (第二层循环)从未排序序列中(i之后),找到最小的元素min,如果最小元素不是未排序序列的第一个元素(i),则min和i互换
public static void sort(int[] a) {
for (int i = 0; i < a.length; i++) {
int min = i;
//选出之后待排序中值最小的位置
for (int j = i + 1; j < a.length; j++) {
if (a[j] < a[min]) {
min = j;
}
}
//最小值不等于当前值时进行交换
if (min != i) {
int temp = a[i];
a[i] = a[min];
a[min] = temp;
}
}
}
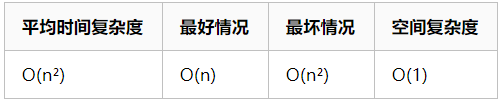
③冒泡排序
- (第一层循环)取出每个数i准备比较,只需要比较n-1个数,每次可以固定在末尾一个最大的数
- (第二层循环)每次从第一个数起比较相邻的元素。如果第一个比第二个大,就交换他们两个。从开始第一对到结尾的最后一对,一共需要比较n-i-1次(i次就代表已经固定了最大i个元素)。这步做完后,最后的元素会是最大的数。
public static void sort(int[] a) {
//外层循环控制比较的次数
for (int i = 0; i < a.length - 1; i++) {
//内层循环控制到达位置
for (int j = 0; j < a.length - i - 1; j++) {
//前面的元素比后面大就交换
if (a[j] > a[j + 1]) {
int temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
}
}
④快速排序(双路)
- 从数列中挑出一个元素,称为"基准"(pivot)。
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
递归地把小于基准值元素的子数列和大于基准值元素的子数列排序。
伪代码:
- i = L; j = R; 将基准数挖出形成第一个坑a[i]。
- j- -,由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
- i++,由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
- 再重复执行2,3二步,直到i==j,将基准数填入a[i]中
虽然 Worst Case 的时间复杂度达到了 O(n²),但是在大多数情况下都比平均时间复杂度为 O(n logn) 的排序算法表现要更好。
性能瓶颈:
- 每次排序后,pivot 左边都是比他小的,右边都是比他大的,如果排序后 pivot 正好位于数组的中间,那是理想情况,如果位于太前或者太后,就失去了二分的特性
- 待排序的系列极有可能是基本有序的,此时,总是 固定选取 left 作为 pivot,(或者无论是固定选取哪一个位置的关键字),都不合理
- 改进:
①每次随机选取 pivot
②三数取中。 即取三个关键字,左端、右端和中间三个数,先进行排序,将中间数作为枢轴,也可以随机选取。
public static void sort(int[] a, int low, int high) {
//已经排完
if (low >= high) {
return;
}
int left = low;
int right = high;
//保存基准值
int pivot = a[left];
while (left < right) {
//从后向前找到比基准小的元素
while (left < right && a[right] >= pivot)
right--;
a[left] = a[right];//此时right后面的都比他大
//从前往后找到比基准大的元素
while (left < right && a[left] <= pivot)
left++;
a[right] = a[left];//此时left前面的都比他小
}
// left=right,放置基准值,准备分治递归快排
a[left] = pivot;
sort(a, low, left - 1);
sort(a, left + 1, high);
}
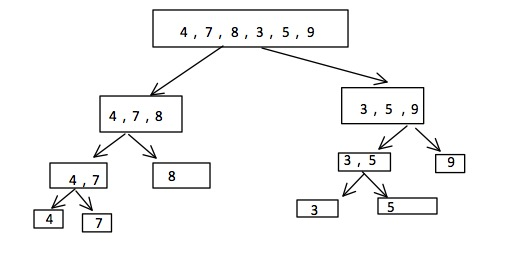
⑤归并排序

def sort(lst, low, mid, high):#合并
i = low
j = mid +1 # low到mid 代表了前面所有拍好序的一个组,mid 到 mid + 1 是乱序部分 mid+1 到最后又是另一个排好序的组
lstm = []
while i <= mid and j <= high:
if lst[i] < lst[j]: #比较两个指针指向的数的大小,把小的一个append到新列表, 并且谁放进去了,谁索引自增一
lstm.append(lst[i])
i += 1
else:
lstm.append(lst[j])
j += 1
# 出现 某一边,可能是左边可能是右边先排完了,将剩下的有序数全部处理添加到新列表
while i <= mid:
lstm.append(lst[i])
i += 1
while j <= high:
lstm.append(lst[j])
j += high
lst[low: high+1] = lstm #最后将拍好序新列表的,赋值回传入的列表的索引段
def merge_sort(lst, low, high):#分治
if low < high:
mid = (low + high) // 2
merge_sort(lst, low, mid)
merge_sort(lst, mid + 1, high)
sort(lst, low, mid, high) # 开始排序
list=[5,4,5,6,6,5,4,4,1,1,22,3,2]
n=len(list)
merge_sort(list,0,n-1)
print(list)
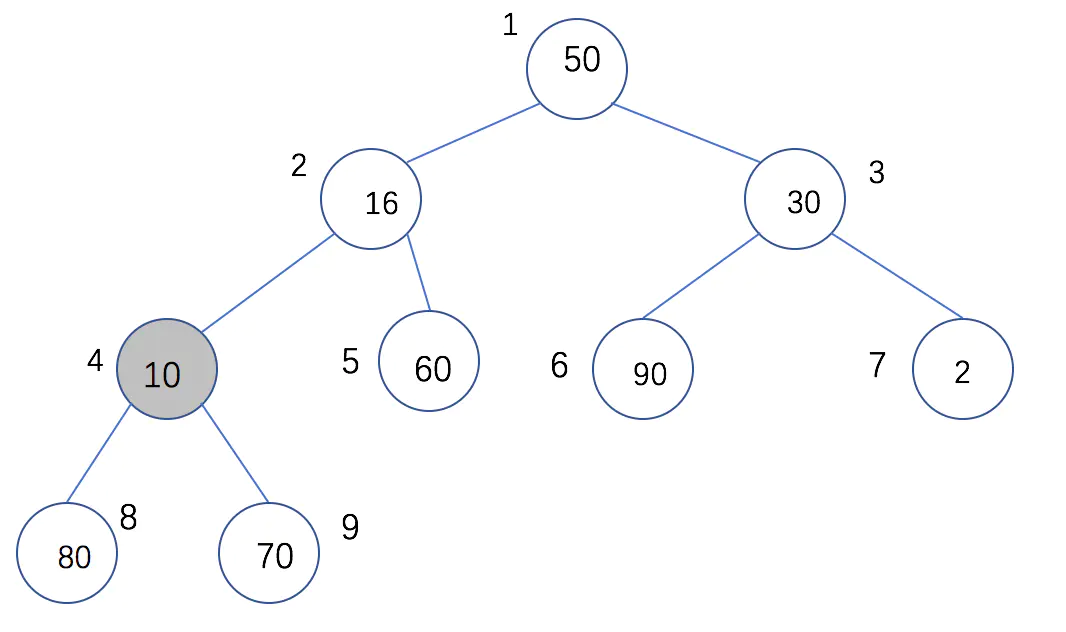
⑥堆排序
找出Top K,时间复杂度为O(N*logK)。
大根堆:每个结点的值都大于或等于左右孩子结点
小根堆:每个结点的值都小于或等于左右孩子结点
步骤:
- 首先将待排序的数组构造出一个
大根堆 - 取出这个大根堆的堆顶节点(最大值),与堆的最下最右的元素(即最小值)进行交换,然后把剩下的元素再构造出一个大根堆
(此时最大值在数组末尾,以后建堆不再用它了) - 重复第二步,直到这个大根堆里的数被取完,此时被取出的数完成
从小到大排序。
构建大根堆:
- 构造堆排序从
end // 2 - 1开始倒序,意思是找到每个有子节点的节点,调整每个小树,使它符合大顶堆 - 构建大根堆就是每个子树的根节点和较大的子节点进行值交换
def heap_sort(alist):
def siftdown(alist,begin, end): # 向下筛选
e=alist[begin]#e是最小值,处在堆顶
i, j = begin, begin * 2 + 1 # j为i的左子结点
while j < end:
if j + 1 < end and alist[j] < alist[j + 1]: # 如果左子结点小于右子结点
j += 1 # 则将j指向右子结点
if e > alist[j]: # j已经指向两个子结点中较大的位置,
break # 如果插入元素e大于j位置的值,则为3者中最大的
alist[i] = alist[j] # 能执行到这一步的话,说明j位置元素是三者中最大的,则将其上移到父结点位置
i, j = j, j * 2+1 # 更新i为被上移为父结点的原来的j的位置(左子节点),更新j为更新后i位置的左子结点
alist[i] = e # 如果e已经是某个子树3者中最大的元素,则将其赋给这个子树的父结点
end = len(alist)
for i in range(end // 2 - 1, -1, -1): # 构造堆序。
siftdown(alist, i, end)
for i in range((end - 1), 0, -1): # 进行堆排序.i最后一个值为1,不需要到0
alist[i],alist[0] = alist[0],alist[i] # 交换堆顶与最后一个元素
siftdown(alist, 0, i)
return alist
if __name__ == "__main__":
alist = [4,10,3,5,1]
print(alist)
heap_sort(alist)
print(alist)
public static int[] heapSort(int[] array) {
//这里元素的索引是从0开始的,最后一个非叶子结点array.length/2 - 1
//1、建堆
for (int i = array.length / 2 - 1; i >= 0; i--) {
adjustHeap(array, i, array.length); //调整堆
}
// 2、排序
for (int j = array.length - 1; j > 0; j--) {
// 把大顶堆的“顶”,放到数组的最后,即最终位置,无需再考虑
swap(array, 0, j);
// 剩下元素重新建堆
adjustHeap(array, 0, j);
}
return array;
}
// i 起始节点,length堆的长度
public static void adjustHeap(int[] array, int i, int length) {
// 先把当前元素取出来,因为当前元素可能要一直移动
int temp = array[i];
//2*i+1为左子树i的左子树(因为i是从0开始的),2*k+1为k的左子树
for (int k = 2 * i + 1; k < length; k = 2 * k + 1) {
// 让k先指向子节点中最大的节点
//如果有右子树,并且右子树大于左子树
if (k + 1 < length && array[k] < array[k + 1]) {
k++;
}
//如果发现结点(左右子结点)大于根结点,则进行值的交换
if (array[k] > temp) {
swap(array, i, k);
// 如果子节点更换了,那么,以子节点为根的子树会受到影响,所以,循环对子节点所在的树继续进行判断
i = k;
} else { //不用交换,直接终止循环
break;
}
}
}
public static void swap(int[] arr, int a, int b) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
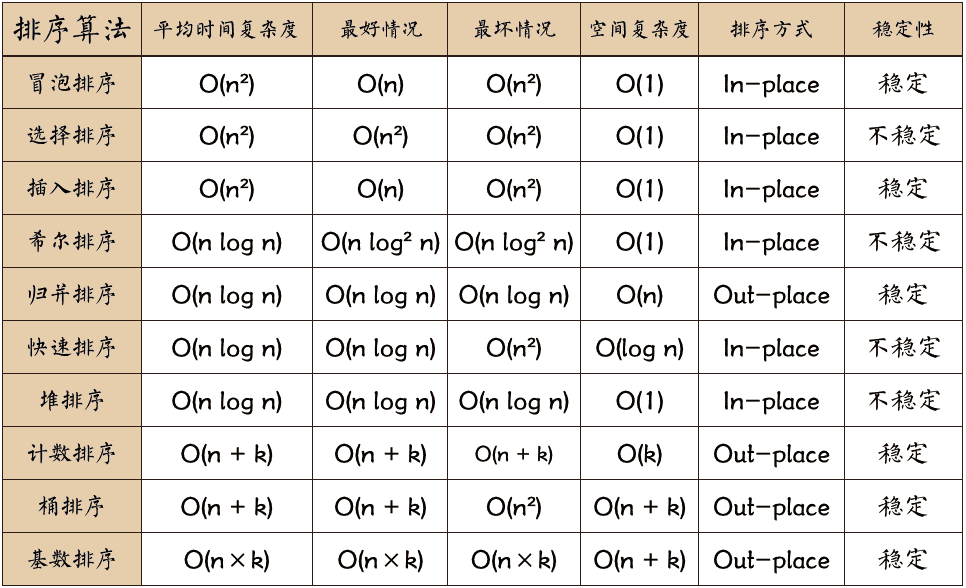
总结
class Solution {
public int[] sortArray(int[] nums) {
if(nums.length <=1)return nums;
//qSort(nums,0,nums.length-1);
//selectSort(nums);
// insertSort(nums);
// shellSort(nums);
// bucketSort(nums);
// countSort(nums);
// mergeSort(nums,0,nums.length-1);
heapSort(nums);
return nums;
}
/**
快速排序
**/
void qSort(int[] arr,int s,int e){
int l = s, r = e;
if(l < r){
int temp = arr[l];
while(l < r){
while(l < r && arr[r] >= temp) r--;
if(l < r) arr[l] = arr[r];
while(l < r && arr[l] < temp) l++;
if(l < r) arr[r] = arr[l];
}
arr[l] = temp;
qSort(arr,s,l);
qSort(arr,l + 1, e);
}
}
/**
选择排序
**/
void selectSort(int[] arr){
int min;
for(int i = 0;i<arr.length;i++){
min = i;
for(int j = i;j<arr.length;j++){
if(arr[j] < arr[min]){
min = j;
}
}
if(min != i) {
int temp = arr[i];
arr[i] = arr[min];
arr[min] = temp;
}
}
}
/**
*
* 插入排序:数列前面部分看为有序,依次将后面的无序数列元素插入到前面的有序数列中,初始状态有序数列仅有一个元素,即首元素。在将无序数列元素插入有序数列的过程中,采用了逆序遍历有序数列,相较于顺序遍历会稍显繁琐,但当数列本身已近排序状态效率会更高。
*
* 时间复杂度:O(N2) 稳定性:稳定
* @param arr
*/
public void insertSort(int arr[]){
for(int i = 1; i < arr.length; i++){
int rt = arr[i];
for(int j = i - 1; j >= 0; j--){
if(rt < arr[j]){
arr[j + 1] = arr[j];
arr[j] = rt;
}else{
break;
}
}
}
}
/**
* 希尔排序 - 插入排序的改进版。为了减少数据的移动次数,在初始序列较大时取较大的步长,通常取序列长度的一半,此时只有两个元素比较,交换一次;之后步长依次减半直至步长为1,即为插入排序,由于此时序列已接近有序,故插入元素时数据移动的次数会相对较少,效率得到了提高。
*
* 时间复杂度:通常认为是O(N3/2) ,未验证 稳定性:不稳定
* @param arr
*/
void shellSort(int arr[]){
int d = arr.length >> 1;
while(d >= 1){
for(int i = d; i < arr.length; i++){
int rt = arr[i];
for(int j = i - d; j >= 0; j -= d){
if(rt < arr[j]){
arr[j + d] = arr[j];
arr[j] = rt;
}else break;
}
}
d >>= 1;
}
}
/**
* 桶排序 - 实现线性排序,但当元素间值得大小有较大差距时会带来内存空间的较大浪费。首先,找出待排序列中得最大元素max,申请内存大小为max + 1的桶(数组)并初始化为0;然后,遍历排序数列,并依次将每个元素作为下标的桶元素值自增1;
* 最后,遍历桶元素,并依次将值非0的元素下标值载入排序数列(桶元素>1表明有值大小相等的元素,此时依次将他们载入排序数列),遍历完成,排序数列便为有序数列。
*
* 时间复杂度:O(x*N) 稳定性:稳定
* @param arr
*/
void bucketSort(int[] arr){
int[] bk = new int[50000 * 2 + 1];
for(int i = 0; i < arr.length; i++){
bk[arr[i] + 50000] += 1;
}
int ar = 0;
for(int i = 0; i < bk.length; i++){
for(int j = bk[i]; j > 0; j--){
arr[ar++] = i - 50000;
}
}
}
/**
* 基数排序 - 桶排序的改进版,桶的大小固定为10,减少了内存空间的开销。首先,找出待排序列中得最大元素max,并依次按max的低位到高位对所有元素排序;
* 桶元素10个元素的大小即为待排序数列元素对应数值为相等元素的个数,即每次遍历待排序数列,桶将其按对应数值位大小分为了10个层级,桶内元素值得和为待排序数列元素个数。
* @param arr
*/
void countSort(int[] arr){
int[] bk = new int[19];
Integer max = Integer.MIN_VALUE;
for(int i = 0; i < arr.length; i++){
if(max < Math.abs(arr[i])) max = arr[i];
}
if(max < 0) max = -max;
max = max.toString().length();
int [][] bd = new int[19][arr.length];
for(int k = 0; k < max; k++) {
for (int i = 0; i < arr.length; i++) {
int value = (int)(arr[i] / (Math.pow(10,k)) % 10);
bd[value+9][bk[value+9]++] = arr[i];
}
int fl = 0;
for(int l = 0; l < 19; l++){
if(bk[l] != 0){
for(int s = 0; s < bk[l]; s++){
arr[fl++] = bd[l][s];
}
}
}
bk = new int[19];
fl = 0;
}
}
/**
* 归并排序 - 采用了分治和递归的思想,递归&分治-排序整个数列如同排序两个有序数列,依次执行这个过程直至排序末端的两个元素,再依次向上层输送排序好的两个子列进行排序直至整个数列有序(类比二叉树的思想,from down to up)。
*
* 时间复杂度:O(NlogN) 稳定性:稳定
* @param arr
*/
void mergeSortInOrder(int[] arr,int bgn,int mid, int end){
int l = bgn, m = mid +1, e = end;
int[] arrs = new int[end - bgn + 1];
int k = 0;
while(l <= mid && m <= e){
if(arr[l] < arr[m]){
arrs[k++] = arr[l++];
}else{
arrs[k++] = arr[m++];
}
}
while(l <= mid){
arrs[k++] = arr[l++];
}
while(m <= e){
arrs[k++] = arr[m++];
}
for(int i = 0; i < arrs.length; i++){
arr[i + bgn] = arrs[i];
}
}
void mergeSort(int[] arr, int bgn, int end)
{
if(bgn >= end){
return;
}
int mid = (bgn + end) >> 1;
mergeSort(arr,bgn,mid);
mergeSort(arr,mid + 1, end);
mergeSortInOrder(arr,bgn,mid,end);
}
/**
* 堆排序 - 堆排序的思想借助于二叉堆中的最大堆得以实现。首先,将待排序数列抽象为二叉树,并构造出最大堆;然后,依次将最大元素(即根节点元素)与待排序数列的最后一个元素交换(即二叉树最深层最右边的叶子结点元素);
* 每次遍历,刷新最后一个元素的位置(自减1),直至其与首元素相交,即完成排序。
*
* 时间复杂度:O(NlogN) 稳定性:不稳定
*
* @param arr
*/
void heapSort(int[] nums) {
int size = nums.length;
for (int i = size/2-1; i >=0; i--) {
adjust(nums, size, i);
}
for (int i = size - 1; i >= 1; i--) {
int temp = nums[0];
nums[0] = nums[i];
nums[i] = temp;
adjust(nums, i, 0);
}
}
void adjust(int []nums, int len, int index) {
int l = 2 * index + 1;
int r = 2 * index + 2;
int maxIndex = index;
if (l<len&&nums[l]>nums[maxIndex])maxIndex = l;
if (r<len&&nums[r]>nums[maxIndex])maxIndex = r;
if (maxIndex != index) {
int temp = nums[maxIndex];
nums[maxIndex] = nums[index];
nums[index] = temp;
adjust(nums, len, maxIndex);
}
}
}















 3016
3016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









