








Prototypical Networks for Few-shot Learning
)
Abstract
本文提出的原型网络,其中分类器可以很好地泛化到其他没有在训练集中出现过的新类别上,每种新出现的类别,只给少量样本。原型网络学习一个度量空间,在该空间中,可以通过计算到每个类的原型表示的距离来执行分类。与其他小样本相比,本方法反映了一种更简单的归纳偏差,有利于在有限的数据范围内使用。
Introduction
小样本是一种任务,分类器必须进行调整以适应没有见过的类。可以在未知的数据集上分类未见过的类,如果在新数据集上重新训练模型,就会导致过拟合。
匹配网:在有标签数据集(support set)的已经学到的嵌入上 使用注意力机制 去预测未标注的点(query set)。匹配网可以解释为应用于嵌入空间中的加权最邻近分类器。Ravi 和 Larochelle进一步利用了Episodes训练的想法并提出了一种元学习的方法用于小样本学习。他们的方法包括在一个给定Eisode的情况下训练一个LSTM去去更新一个分类器,这样就会很好的推广到测试集。在这里,LSTM元学习不是在多个Episodes上训练单个模型,而是学习为每一个Episode训练一个个性化的模型。
解决问题:小样本过拟合。
方法:原型网络,是基于存在embedding的想法,这些点围绕每个类的单个原型表示(prototype representation)进行聚集。为了做到这点,我们学习了一个非线性的映射,利用神经网络将输入映射到一个embedding space,并且在embedding space中将支持集中每个类别的平均值作为类的原型。然后通过简单的查找最近的类原型对嵌入的查询点进行分类。利用同样的方法处理零样本学习,在这里,每个类都带有给出类高度描述(high-level description)的元数据,而不是少量的标记数据。因此我们学习将元数据嵌入到共享空间中,作为每个类的原型。
完成的工作:在这篇论文中,我们给few-shot和 zero-shot settings制定了原型网络。我们还与one-shot setting中的匹配网络建立联系,并且分析下层距离函数在模型中的应用。特别的,我们将原型网络与聚类联系起来,,以证明当使用Bregman散度(如平方欧氏距离)计算距离时,类平均值作为原型的使用是正确的。我们从经验上发现,距离的选择是至关重要的,因为欧几里德距离大大优于更常用的余弦相似度。
结论:在几项核心任务中,我们实现了最先进的性能。原型网络比最近的元学习算法更简单、更有效,使其成为一种小样本学习和零样本学习方法
Prototypical Networks
Model
原型网络计算一个M维的表示(或原型)
c
k
∈
R
M
c_{k}\in\mathbb{R}^{M}
ck∈RM,每个类通过一个嵌入函数
f
ϕ
f_{\phi}
fϕ(
ϕ
\phi
ϕ参数可学习)。每个原型是该类的嵌入支持点的向量的均值:
c
k
=
1
∣
S
k
∣
∑
(
x
i
,
y
i
∈
S
k
)
f
ϕ
(
x
i
)
(
1
)
c_{k}= \frac{1}{\left| S_{k} \right|}\sum_{\left(x_{i},y_{i}\in S_{k} \right)}f_{\phi}\left(x_{i} \right)(1)
ck=∣Sk∣1(xi,yi∈Sk)∑fϕ(xi)(1)
原型网络在嵌入空间上对每个查询点在每个类上生成一个基于softmax在距离上的分布:
p
ϕ
(
y
=
k
∣
x
)
=
e
x
p
(
−
d
(
f
ϕ
(
x
)
,
c
k
)
)
∑
k
′
e
x
p
(
−
d
(
f
ϕ
(
x
)
,
c
k
′
)
)
(
2
)
p_{\phi}\left(y=k|x \right)= \frac{exp\left(-d\left(f_{\phi} \left( x \right) ,c_{k}\right) \right)}{\sum_{{k}'} exp\left(-d\left(f_{\phi} \left( x \right) ,c_{{k}'}\right) \right)} (2)
pϕ(y=k∣x)=∑k′exp(−d(fϕ(x),ck′))exp(−d(fϕ(x),ck))(2)
通过SGD来最小化所属真实类别x的负log概率
J
(
ϕ
)
=
−
l
o
g
p
ϕ
(
y
=
k
∣
x
)
J\left(\phi \right)=-log p_{\phi}\left(y=k |x \right)
J(ϕ)=−logpϕ(y=k∣x) 来进行学习过程。训练集是通过从训练集中随机选择一个类的子集,然后在每个类中选择一个示例子集作为支持集,其余的子集作为查询点而形成的。在训练过程中计算损失的伪代码如下:

N:训练集中样例的数量
K:训练集中类的数量
NC:每个Episode中类别的数量
NS:每个类中支持样例的数量
NQ:每个类中查询样例的数量
RandomSample(S,N):denotes a set of N elements chosen uniformly at random from set S, without replacement.
输入:训练集D,Dk代表类别k的子集
输出:随机产生的训练Episode的损失J
计算过程:为Episode选择类别 --> 选择支持集 --> 选择训练集–>计算支持集的原型–> 初始化损失–> 更新损失
PrototypicalNetworksasMixtureDensityEstimation
对于一类特殊的距离函数,如我们所知道的正则Bregman散度,原型函数相当于对具有指数族密度的支持集进行混合密度估计。
任何具有参数和积累量的正则指数分布都可以用唯一正确的正则Bregman散度表示,对未标记点z的分布赋值y的推断用正则Bregman散度表示。 p ( y = k ∣ z ) = π k e x p ( − d φ ( z , μ ( θ k ) ) ) ∑ k ′ π k ′ e x p ( − d φ ( z , μ ( θ k ) ) ) p\left(y=k|z \right)=\frac{\pi_{k} exp\left(-d_{\varphi } \left(z,\mu \left (\theta_{k} \right) \right) \right)}{\sum_{{k}'}\pi_{{k}'}exp\left(-d_{\varphi }\left(z,\mu\left (\theta_{k} \right) \right) \right)} p(y=k∣z)=∑k′πk′exp(−dφ(z,μ(θk)))πkexp(−dφ(z,μ(θk)))
原型网络有效地执行了混合密度估计,其指数分布用 d φ d_{\varphi } dφ确定。因此,距离的选择指定了关于嵌入空间中类条件数据分布的建模假设。
ReinterpretationasaLinearModel
当使用欧氏距离
d
(
z
,
z
′
)
=
∥
z
−
z
′
∥
2
d\left( z,{z}'\right)={\left \| z-{z}'\right \|}^{2}
d(z,z′)=∥z−z′∥2(2)的模型就能用线性模型表达出来。
我们主要关注平方欧式距离(对应于高斯距离)。结果表明,尽管欧氏距离与线性模型等价但是它是一种有效的选择。我们假设这是因为所有需要的非线性都可以在嵌入函数中学习。实际上,这是现代神经网络分类系统目前使用的方法。
Comparison to Matching Networks
相同点:在one-shot情景下等价。ck=xk,因为每个类只有一个支持点,两者变得等价
不同点:当使用平方欧氏距离时,原型网产生一个线性分类器。对于给定的支持集,匹配网产生一个加权最近邻分类器。
一个自然的问题是每个类使用多个原型而不是一个是否有意义。如果每个类的原型固定而且大于1,那么这将需要一个分区方案去进一步集群每一个类中的支持点。Mensinket al. and Rippel et al 等人已经提出过,但是这两种方法都需要一个独立的分区阶段,该阶段与权重更新分离,而我们的方法使用普通的梯度下降方法很容易学习。
Vinyals等人提出了一些扩展,包括分离支持点和查询点的嵌入函数,使用第二级的完全条件嵌入(FCE),它考虑到每一Episode的特定点。它们同样可以被纳入到原型网络中,但是它们增加了可学习参数的数量,并且FCE使用双向LSTM对支持集施加任意顺序。相反,我们展示了使用简单的设计选择来实现相同级别的性能是可能的,下面我们将概述这一点。
Design Choices
距离度量:对于原型网络和匹配网络,任何距离都是允许的,并且我们发现使用平方欧几里德距离可以极大地改善这两者的结果。我们推测这主要是由于余弦距离不是Bregman散度,因此第2.3节中讨论的混合密度估计的等价性不成立。
Episode composition :一种简单的构造Episodes的方法,是每个类选择Nc类和Ns支持点,以便在测试时匹配预期的情况。也就是说,如果我们期望在测试时执行一个5个类一个样本的学习,训练episodes可以用Nc=5,Ns=1组成。然而,我们发现,使用比测试时更高的Nc或“way”进行训练是非常有益的。在我们的实验中,我们调整训练Nc在一个保持有消极上。另一个考虑因素是在训练和测试时间是匹配Ns还是‘shot’。对于原型网络,我们发现最好的是使用相同的‘shot’进行训练和测试。
Zero-Shot Learning
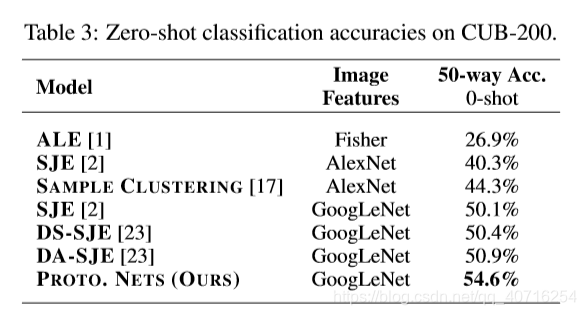
Zero-shot与few-shot的不同之处在于,在没有给出训练点的支持集的情况下,我们给出了每个类的类元数据vk。这些可以实现确定,也可以从原始文本中学习。修改原型网络去处理zero-shot问题是很简单那的,我们定义为元数据向量的单独嵌入。图一显示了zero-shot,few-shot以及原型网络。由于元数据向量和查询点来自不同的输入域,我们发现将原型嵌入g固定为单位长度是有帮助的,但是我们不限制查询嵌入f。
Experiments
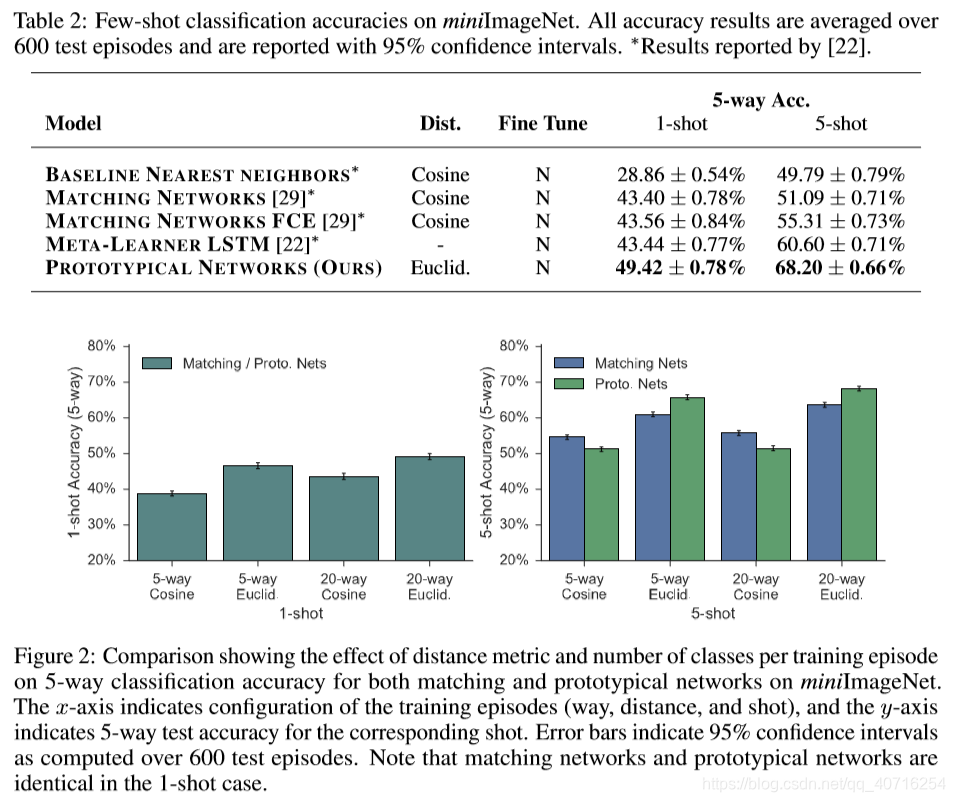
Conclusion
我们提出了一种简单的few-shot学习的方法称作原型网络,其基本思想是,在一个由神经网络学习的表示空间中用样例的平均值来表示每一类。我们通过使用episode训练使得神经网络在few-shot学习中表现的特别好。这种方法比元学习简单并且更有效,即便没有匹配网络进行复杂的拓展也能产生最新的结果(尽管这些方法也可以应用于原型网络)。我们展示了如何通过仔细考虑所选择的距离度量,并通过修改Episode学习过程来大大提高性能。我们进一步展示了如何将原型网络推广到zero-shot setting,并且在CUB-200数据集上实现了最新的结果。未来工作的一个自然方向是利用Bregman发散,而不是平方欧氏距离,对应于超越球面高斯的类条件分布。我们对此进行了初步的探索,包括为一个类学习每个维度的方差。这并没有导致任何经验收益,这表明嵌入网络本身具有足够的灵活性,而不需要每个类的附加拟合参数。总的来说,原型网络的简单性和有效性使其成为一种有前途的few-shot学习方法。
My Thinking
优点:通过嵌入空间对每个类的原型取平均然后计算预测点到原型的距离来预测类别。
改进方向:
①分类模型方向:除了平方欧式距离(与线性分类模型等价却比线性好),是否还有其他度量方式可以提高准确率?
②嵌入空间方向:是否有其他数据增强的方式对输入特征进行高度抽象提取,使得聚类后,对未知类别的效果更好?
相关译文:https://blog.csdn.net/Smiler_/article/details/103133876?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control

















 7173
7173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









