







导读
对于一些同学来说Batch Size只是一个可以随便调节以适应不同显存环境的参数,事实真是如此吗。本文将结合一些理论知识,通过大量实验,探讨Batch Size的大小对训练模型及模型性能的影响,希望对大家有所帮助。
1 什么是Batch Size?
训练神经网络以最小化以下形式的损失函数:
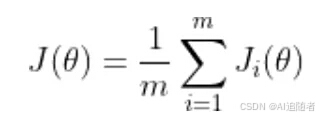
-
theta 代表模型参数
-
m 是训练数据样本的数量
-
i 的每个值代表一个单一的训练数据样本
-
J_i 表示应用于单个训练样本的损失函数
通常,这是使用梯度下降来完成的,它计算损失函数相对于参数的梯度,并在该方向上迈出一步。随机梯度下降计算训练数据子集 B_k 上的梯度,而不是整个训练数据集。
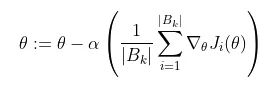
2 为什么Batch Size很重要?
Keskar 等人指出,随机梯度下降是连续的,且使用小批量,因此不容易并行化 。使用更大的批量大小可以让我们在更大程度上并行计算,因为我们可以在不同的工作节点之间拆分训练示例。这反过来可以显着加快模型训练。
然而,较大的批大小虽然能够达到与较小的批大小相似的训练误差,但往往对测试数据的泛化效果更差 。训练误差和测试误差之间的差距被称为“泛化差距”。因此,“holy grail”是使用大批量实现与小批量相同的测试误差。这将使我们能够在不牺牲模型准确性的情况下显着加快训练速度。
2.1 实验是如何设置的?
我们将使用不同的批量大小训练神经网络并比较它们的性能。
数据集:我们使用 Cats and Dogs 数据集,该数据集包含 23,262 张猫和狗的图像,在两个类之间的比例约为 50/50。由于图像大小不同,我们将它们全部调整为相同大小。我们使用 20% 的数据集作为验证数据,其余作为训练数据。
评估指标:我们使用验证数据上的二元交叉熵损失作为衡量模型性能的主要指标。

来自 Cats vs Dogs 数据集的示例图像
基础模型:定义了一个受 VGG16 启发的基础模型,在其中重复应用 (convolution ->max-pool) 操作,使用 ReLU 作为卷积的激活函数。然后,将输出量展平并将其送入两个完全连接的层,最后是一个带有 sigmoid 激活的单神经元层,产生一个介于 0 和 1 之间的输出,它表明模型是预测猫(0)还是 狗 (1).
训练:使用学习率为 0.01 的 SGD。一直训练到验证损失在 100 次迭代中都没有改善为止。
2.2 Batch Size如何影响训练?
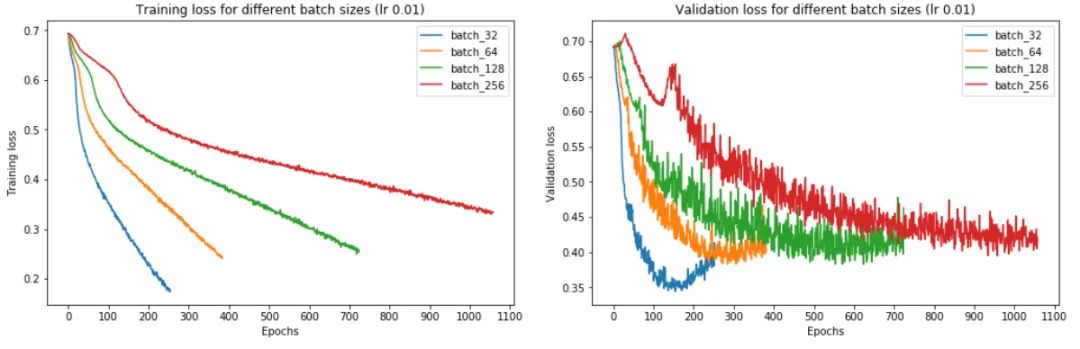
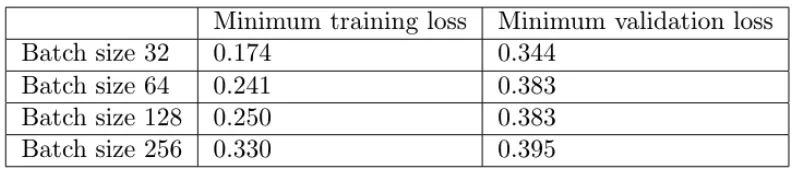
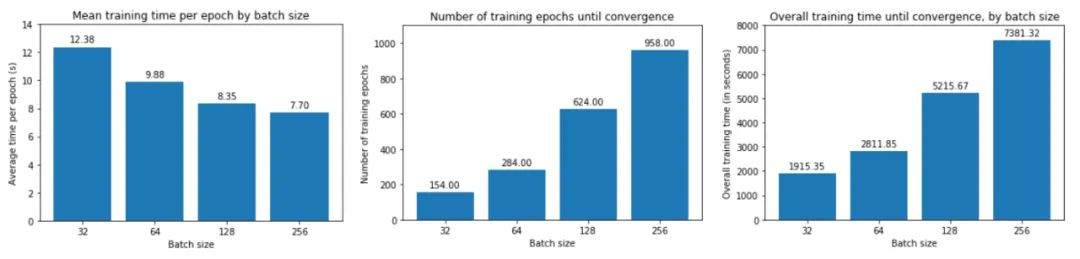
从上图中,我们可以得出结论,batch size越大:
-
训练损失减少的越慢。
-
最小验证损失越高。
-
每个时期训练所需的时间越少。
-
收敛到最小验证损失所需的 epoch 越多。
让我们一一了解这些。首先,在大批量训练中,训练损失下降得更慢,如红线(批量大小 256)和蓝线(批量大小 32)之间的斜率差异所示。
其次,大批量训练比小批量训练实现更糟糕的最小验证损失。例如,批量大小为 256 的最小验证损失为 0.395,而批量大小为 32 时为 0.344。
第三,大批量训练的每个 epoch 花费的时间略少——批量大小 256 为 7.7 秒,而批量大小 256 为 12.4 秒,这反映了与加载少量大批量相关的开销较低,而不是许多小批量依次。如果我们使用多个 GPU 进行并行训练,这种时间差异会更加明显。
然而,大批量训练需要更多的 epoch 才能收敛到最小值——
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











