







论文地址:YOLOv12: Attention-Centric Real-Time Object Detectors
代码地址:https://github.com/sunsmarterjie/yolov12
提升YOLO框架的网络架构一直至关重要,尽管注意力机制在建模能力方面已被证明具有优越性,但长期以来一直专注于基于CNN的改进。这是因为基于注意力的模型无法与基于CNN的模型的速度相匹配。本文提出了一种以注意力为中心的YOLO框架,即YOLOv12,该框架在匹配先前基于CNN的模型速度的同时,利用了注意力机制的性能优势。
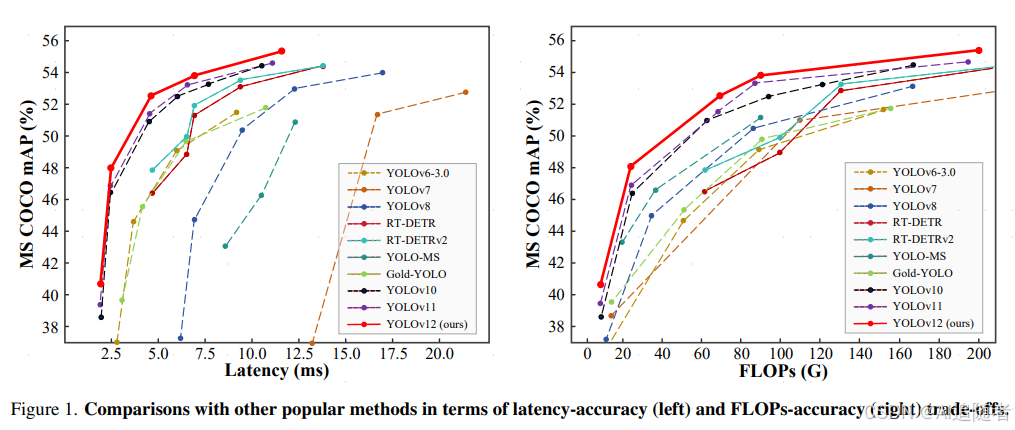
YOLOv12在准确率上超越了所有流行的实时目标检测器,同时保持了有竞争力的速度。例如,YOLOv12-N在T4 GPU上实现了1.64ms的推理延迟,达到40.6%的mAP,比先进的YOLOv10-N/YOLOv11-N分别高出2.1%/1.2%的mAP,且速度相当。这一优势也扩展到其他模型规模。YOLOv12还超越了改进DETR的端到端实时检测器,如RT-DETR/RTDETRv2:YOLOv12-S在运行速度上快42%,仅使用36%的计算资源和45%的参数,就击败了RT-DETR-R18/RT-DETRv2-R18。
1 引言
实时目标检测因其低延迟特性一直受到广泛关注,这些特性提供了巨大的实用性。其中,YOLO系列在延迟和准确率之间取得了有效的平衡,从而主导了该领域。尽管YOLO的改进主要集中在损失函数、标签分配和网络架构设计等方面,但网络架构设计仍然是关键的研究优先事项。尽管以注意力为中心的视觉Transformer(ViT)架构已被证明即使在小型模型中也具有更强的建模能力,但大多数架构设计仍然主要关注CNN。
这种情况的主要原因在于注意力机制的效率低下,这主要源于两个因素:注意力机制的二次计算复杂性和不高效的内存访问操作(后者是FlashAttention解决的主要问题)。因此,在类似的计算预算下,基于CNN的架构比基于注意力的架构性能高出约,这显著限制了注意力机制在YOLO系统中(在高推理速度至关重要的系统中)的应用。
本文旨在解决这些挑战,并进一步构建一个以注意力为中心的YOLO框架,即YOLOv12。作者提出了三个关键改进:
- 首先,提出了一种简单而高效的区域注意力模块(A2),它通过非常简单的方式减少了注意力计算复杂性,同时保持了较大的感受野,从而提高了速度。
- 其次,引入了残差高效层聚合网络(R-ELAN)来解决注意力(主要是大规模模型)引入的优化挑战。R-ELAN基于原始ELAN 引入了两个改进:
1)基于缩放技术的块级残差设计;
2)重新设计的特征聚合方法。
- 最后,对传统的注意力中心架构进行了某些架构改进,以适应YOLO系统。作者升级了传统的注意力中心架构,包括:引入FlashAttention以克服注意力的内存访问问题,移除如位置编码等设计以使模型快速且简洁,调整MLP比例从4到1.2以平衡注意力和 FFN 之间的计算,减少堆叠块的深度以促进优化,尽可能多地使用卷积算子以利用其计算效率。
基于上述设计,作者开发了一组具有5个模型尺度的实时检测器:YOLOv12-N、S、M、L和X。作者在遵循YOLOv11 的标准目标检测基准上进行了广泛的实验,没有使用任何额外的技巧,证明了YOLOv12在这些尺度上提供了显著的改进,无论是在延迟-精度还是FLOPs-精度权衡方面,如图1所示。
例如,YOLOv12-N实现了40.6%的mAP,比YOLOv10-N高出2.1%的mAP,同时保持了更快的推理速度,比YOLOv11-N高出1.2%的mAP,速度相当。这种优势在其他-Scale模型中也保持一致。与RT-DETR-R18 / RT-DETRv2-R18相比,YOLOv12-S在mAP上分别提高了1.5%/0.1%,同时报告了42%/42%的更快延迟速度,只需要他们36%/36%的计算量和45%/45%的参数量。
总结来说,YOLOv12的贡献有两方面:
- 该方法建立了一个以注意力为中心的、简单而高效的YOLO框架,通过方法创新和架构改进,打破了CNN模型在YOLO系列中的主导地位
- 不依赖预训练等额外技术,YOLOv12实现了快速推理速度和更高的检测精度,达到了最先进的水平,展示了其潜力。
2 相关工作
实时目标检测器。实时目标检测器由于其显著的实际价值,一直受
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











