







前言
最近在学习python爬虫,拿kg音乐练练手。本文章不贴js逆向分析了,不会的可以看我QQ音乐那偏文章。
接口分析
先随便点首音乐,抓到URl地址

接着搜索找到请求接口
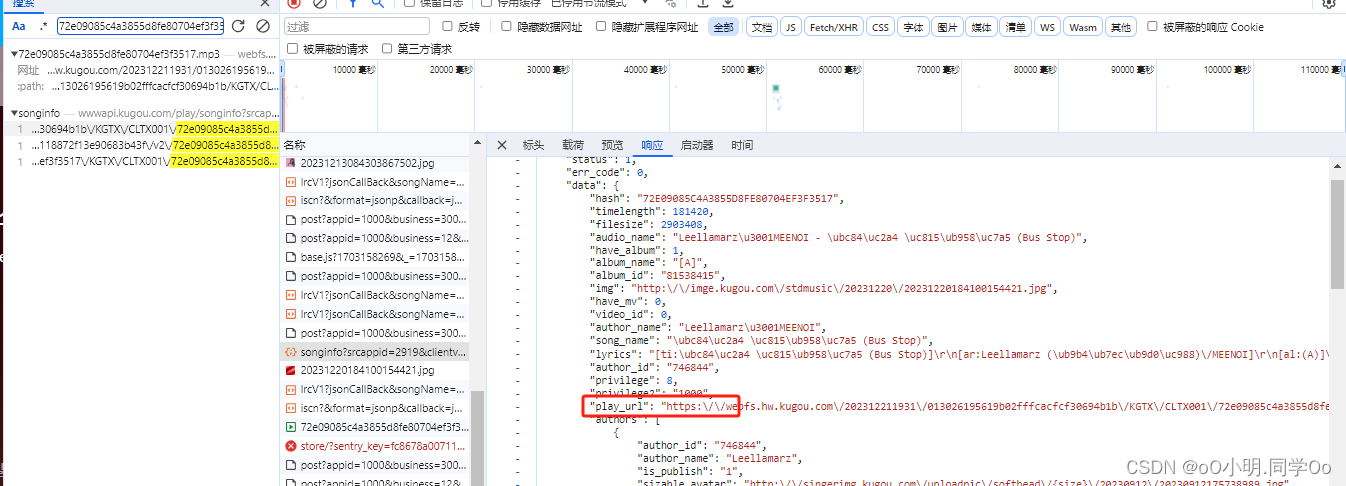
查看接口参数encode_album_audio_id音乐ID,clienttime时间戳,mid,uuid,dfid,signature,这四个参数不知道是什么,其他的应该是固定的
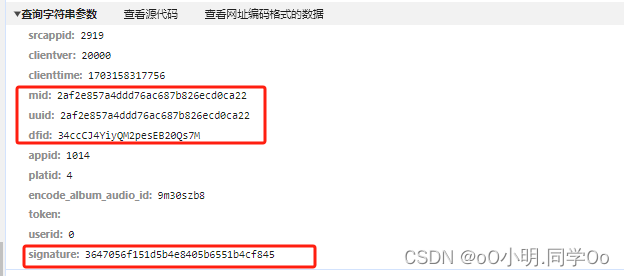
搜索查看位置,查看第一层参数是怎么获取的
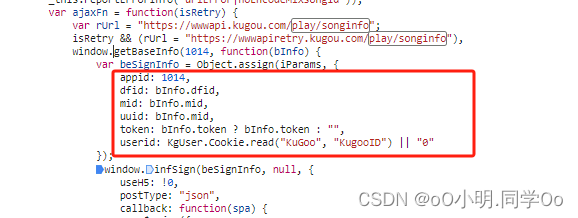
断点查看参数
dfid是通过 e.Cookie.read("kg_dfid") || "-",
mid和uuid都是通过e.getKgMid()获取的
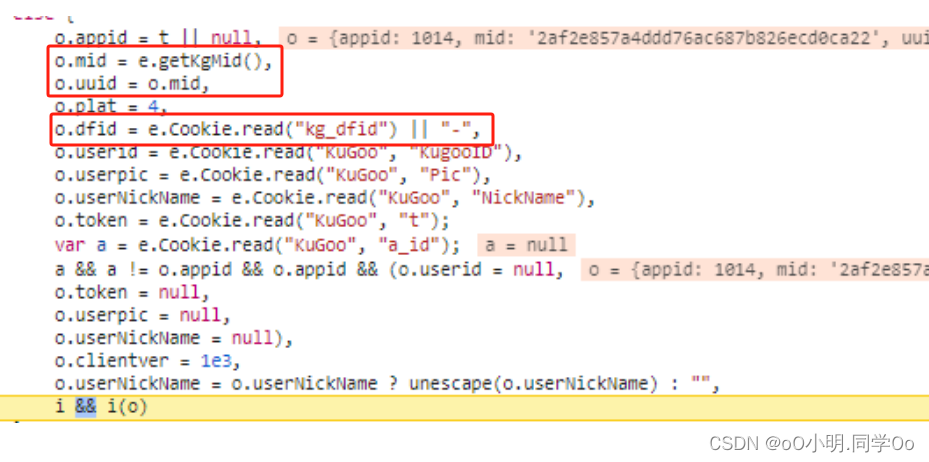
继续看getKgMid(),可以发现先获取e.Cookie.read("kg_mid"),如果是空的就获取e.Guid();

继续断点,发现是随机生成的,mid和uuid找到了

然后发现还是缺少signature,继续断点,找到signature位置,然后分析发现是请求参数进行key排序,然后前后拼接NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt,然后进行MD5加密
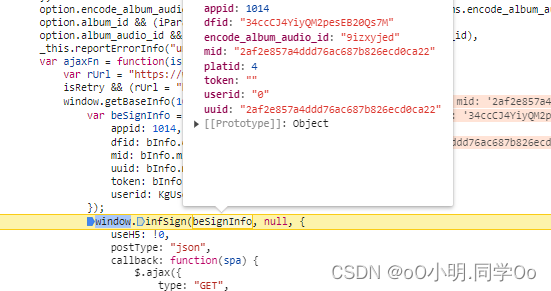
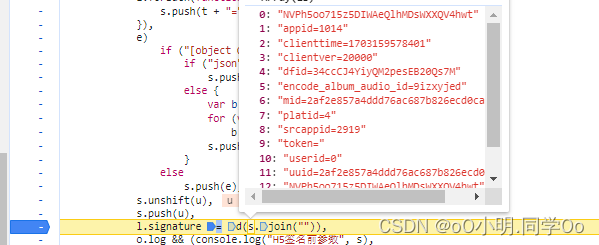
最后去python环境跑一下,获取成功
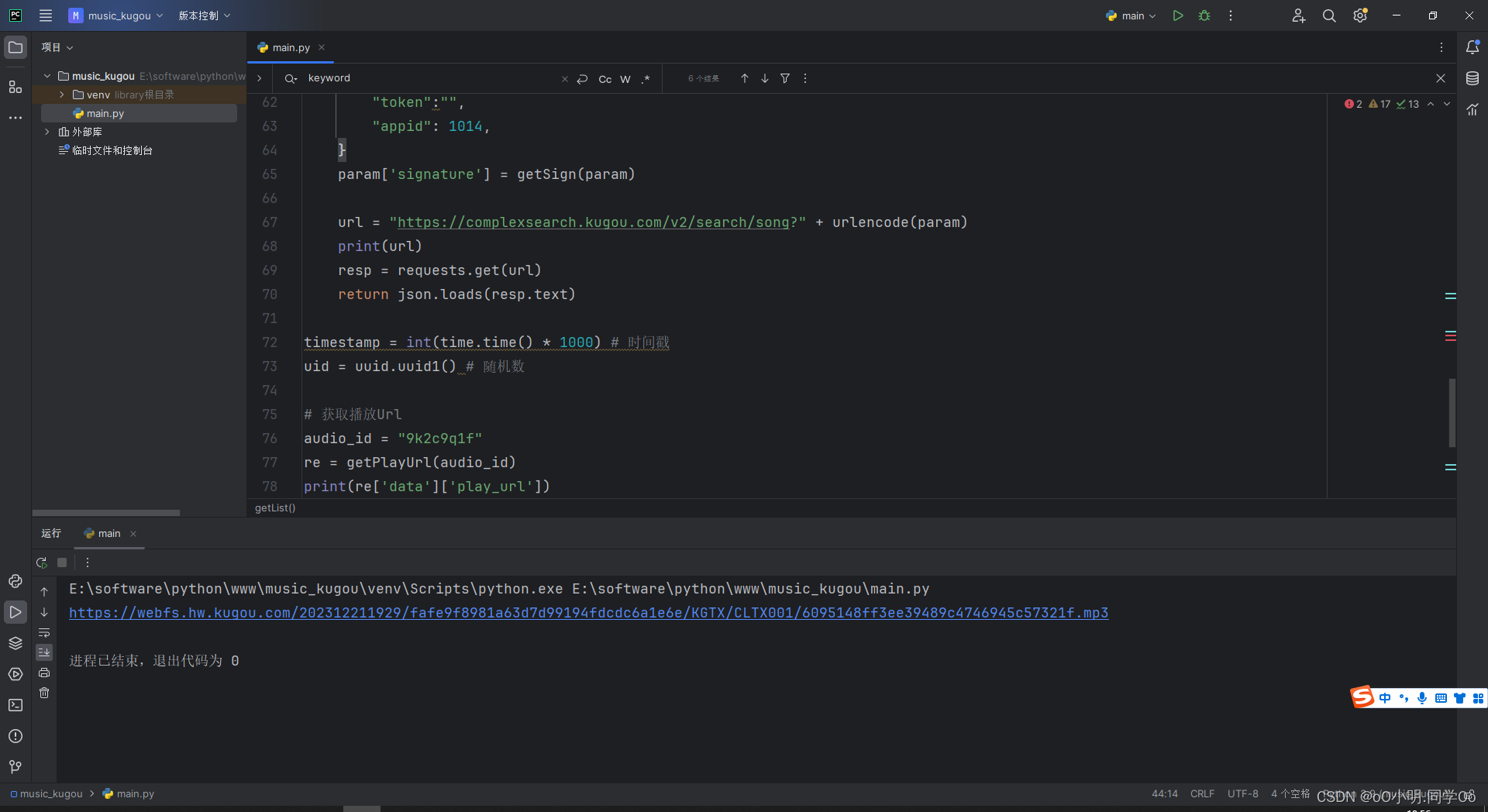
整理python代码
import json
import time
from urllib.parse import urlencode
import uuid
import hashlib
import requests
def getSign(param):
keySort = sorted(param) # 排序
u = "NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt" # 拼接字段
signature = ""
for i in keySort:
signature += i + "=" + str(param[i])
signature = u + signature + u
signature = hashlib.md5(signature.encode(encoding='UTF-8')).hexdigest() # md5加密
return signature
# 获取kg音乐播放Url
# audio_id kgID
def getPlayUrl(audio_id) :
param = {
"appid": 1014,
"clienttime": timestamp,
"clientver": 2000,
"dfid": "-",
"encode_album_audio_id": audio_id,
"mid": uid,
"platid": 4,
"srcappid": 2919,
"token": "",
"userid": 0,
"uuid": uid,
}
param['signature'] = getSign(param)
url = "https://wwwapi.kugou.com/play/songinfo?" + urlencode(param)
resp = requests.get(url)
return json.loads(resp.text)
# 获取kg音乐列表
# keyword 搜索关键字
def getList(keyword) :
param = {
"srcappid": 2919,
"clientver": 1000,
"clienttime": timestamp,
"mid": uid,
"uuid": uid,
"dfid": "-", # 随便个字符串就可以
"keyword": keyword,
"page": page,
"pagesize": pagesize,
"bitrate": 0,
"isfuzzy": 0,
"inputtype": 0,
"platform": "WebFilter",
"userid": 0,
"iscorrection": 1,
"privilege_filter": 0,
"filter": 10,
"token":"",
"appid": 1014,
}
param['signature'] = getSign(param)
url = "https://complexsearch.kugou.com/v2/search/song?" + urlencode(param)
print(url)
resp = requests.get(url)
return json.loads(resp.text)
timestamp = int(time.time() * 1000) # 时间戳
uid = uuid.uuid1() # 随机数
# 获取播放Url
audio_id = "9k2c9q1f"
re = getPlayUrl(audio_id)
print(re['data']['play_url'])
# 获取搜索列表
# page = 1
# pagesize = 30
# keyword = "周杰伦"
# re = getList(keyword)
# print(re)














 6475
6475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









