






1.首先得先登录网页版酷我音乐,然后在请求头找到自己的cookie,将其全部复制下来,并替换掉我源码中的cookie,
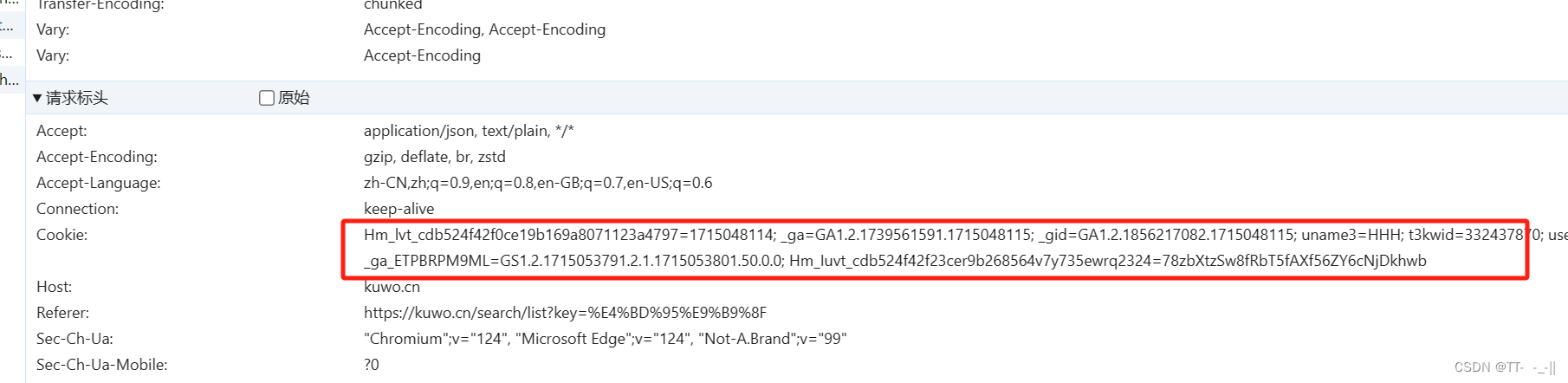
2.注意替换cookie时,有两处都得替换掉,headers中的cookie也得替换
3.运行之前需要提前创建好文件夹 例如我的 D:/ms/
源码
import os
import time
import requests
# cookies,登录账号后很容易在请求头中找到自己的cookies
cookies = "Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1715048114; _ga=GA1.2.1739561591.1715048115; _gid=GA1.2.1856217082.1715048115; uname3=HHH; t3kwid=332437870; userid=332437870; websid=169907409; pic3='http://q.qlogo.cn/qqapp/100243533/DB73BA2BF7E5054F51F97D77DF31FC5A/100'; t3=qq; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1715048152; _ga_ETPBRPM9ML=GS1.2.1715048115.1.1.1715049708.60.0.0; Hm_Iuvt_cdb524f42f23cer9b268564v7y735ewrq2324=G8B3aXZbcpANpQcciKB7zpXxK268TbTA"
# 构造请求头
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br, zstd',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1715048114; _ga=GA1.2.1739561591.1715048115; _gid=GA1.2.1856217082.1715048115; uname3=HHH; t3kwid=332437870; userid=332437870; websid=169907409; pic3="http://q.qlogo.cn/qqapp/100243533/DB73BA2BF7E5054F51F97D77DF31FC5A/100"; t3=qq; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1715048152; _ga_ETPBRPM9ML=GS1.2.1715048115.1.1.1715049708.60.0.0; Hm_Iuvt_cdb524f42f23cer9b268564v7y735ewrq2324=G8B3aXZbcpANpQcciKB7zpXxK268TbTA',
'Referer': 'https://kuwo.cn/',
'Host': 'kuwo.cn',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'Secret': '6468c991707f3249bd55e1df3bebd24e6184b3e04d8ac47f42b24da1d2e431cd03377e61',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0',
'sec-ch-ua': '"Chromium";v="124", "Microsoft Edge";v="124", "Not-A.Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
cookie_dict = {i.split("=", 1)[0]:i.split("=", 1)[-1] for i in cookies.split("; ")}
def download_music(url, filepath):
# 发送 GET 请求下载文件
response = requests.get(url, stream=True)
# 检查响应状态码是否为 200 (OK)
if response.status_code == 200:
# 打开本地文件,以二进制写入模式写入数据
with open(filepath, 'wb') as f:
# 逐步将响应内容写入文件
for chunk in response.iter_content(chunk_size=1024):
f.write(chunk)
print(f"下载完成:{filepath}")
else:
print(f"下载失败:{filepath}")
#keyword即为你搜索的歌曲关键词
def get_song_info(keyword):
# 请求时需要的参数
params2={
'vipver':1,
'client':'kt',
'ft':'music',
'cluster':0,
'strategy': 2012,
'encoding': 'utf8',
'rformat': 'json',
'mobi': 1,
'issubtitle': 1,
'show_copyright_off': 1,
'pn': 0,
'rn': 20,
'all': keyword
}
response = requests.get('https://kuwo.cn/search/searchMusicBykeyWord',
params=params2, cookies=cookie_dict, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
# 解析JSON响应
data = response.json()
for mid in data['abslist']:
params1 = {
'mid': mid['DC_TARGETID'],
'type': 'music',
'httpsStatus': '1',
'reqId': '47414720-0c1d-11ef-805a-8b343e888ff4',
'plat': 'web_www',
'from': '',
}
params3 = {
'mid': mid['DC_TARGETID'],
'httpsStatus': '1',
'reqId': '47414720-0c1d-11ef-805a-8b343e888ff4',
'plat': 'web_www',
'from': '',
}
# 获得歌曲基本信息
responseinfo = requests.get('https://kuwo.cn/api/www/music/musicInfo',
params=params3, cookies=cookie_dict, headers=headers)
datainfo =responseinfo.json()
# 获得歌曲播放地址
responseaddress = requests.get('https://kuwo.cn/api/v1/www/music/playUrl',
params=params1, cookies=cookie_dict, headers=headers)
dataaddress=responseaddress.json()
if 'data' not in dataaddress :
print('\033[91m' + datainfo['data']['name']+"-"+datainfo['data']['artist']+"歌曲付费,无法下载"+ '\033[0m')
continue
music_url=dataaddress['data']['url']
# 下载的歌曲的保存地址
download_dir = "D:/ms/"
filename = datainfo['data']['name']+"-"+datainfo['data']['artist']+".mp3"
filepath = os.path.join(download_dir, filename)
download_music(music_url, filepath)
# 睡眠一秒钟
time.sleep(1)
get_song_info("何鹏")
运行效果

仅供学习参考,禁止商业用途















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









