







# _*_ coding:utf-8 _*_
# 开发工具:PyCharm
# 公众号:小宇教程
import urllib.parse
from urllib.request import urlopen
import json
import time
import sys
import os
def Time_1():
for i in range(1, 51):
sys.stdout.write('\r')
sys.stdout.write('{0}% |{1}'.format(int(i % 51) * 2, int(i % 51) * '■'))
sys.stdout.flush()
time.sleep(0.125)
sys.stdout.write('\n')
def KuGou_music():
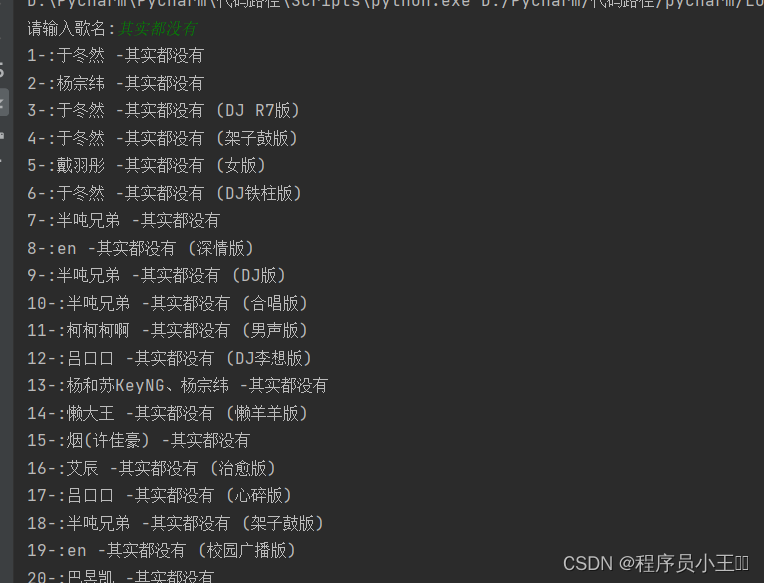
keyword = urllib.parse.urlencode({'keyword': input('请输入歌名:')})
keyword = keyword[keyword.find('=') + 1:]
url = 'https://songsearch.kugou.com/song_search_v2?callback=jQuery1124042761514747027074_1580194546707&keyword=' + keyword + '&page=1&pagesize=30&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1580194546709'
content = urlopen(url=url)
content = content.read().decode('utf-8')
str_1 = content[content.find('(') + 1:-2]
str_2 = json.loads(str_1)
Music_Hash = {}
Music_id = {}
for dict_1 in str_2['data']['lists']:
Music_Hash[dict_1['FileName']] = dict_1['FileHash']
Music_id[dict_1['FileName']] = dict_1['AlbumID']
list_music_1 = [music for music in Music_Hash]
list_music = [music for music in Music_Hash]
for i in range(len(list_music)):
if '- <em>' in list_music[i]:
list_music[i] = list_music[i].replace('- <em>', '-')
if '</em>' in list_music[i]:
list_music[i] = list_music[i].replace('</em>', '')
if '<em>' in list_music[i]:
list_music[i] = list_music[i].replace('<em>', '')
for i in range(len(list_music)):
print("{}-:{}".format(i + 1, list_music[i]))
music_id_1 = int(input('请输入你想下载的歌曲序号:'))
url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=' + Music_Hash[
list_music_1[music_id_1 - 1]] + '&album_id=' + Music_id[list_music_1[
music_id_1 - 1]] + '&dfid=2SSV0x4LWcsx0iylej1F6w7P&mid=44328d3dc4bfce21cf2b95cf9e76b968&platid=4'
js_content = urlopen(url=url)
str_3 = js_content.read().decode('utf-8')
dict_2 = json.loads(str_3)
try:
music_href = dict_2['data']['play_backup_url']
music_content = urlopen(url=music_href).read()
try:
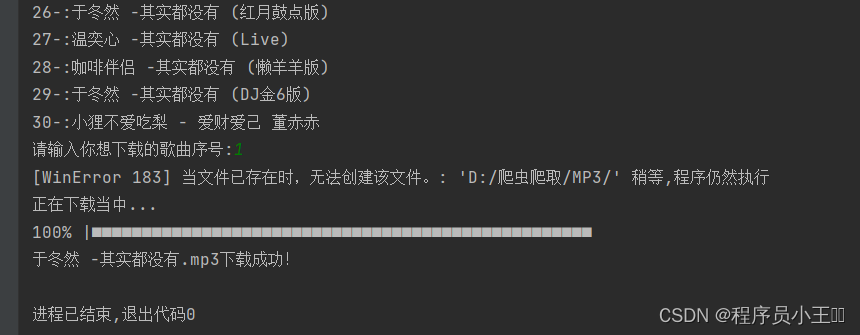
os.mkdir('D:/爬虫爬取/MP3/')
except Exception as e:
print(e, '稍等,程序仍然执行')
finally:
music_path = 'D:/爬虫爬取/MP3/' + list_music[music_id_1 - 1] + '.mp3' # 歌曲下载路径
with open(music_path, 'wb') as f:
print('正在下载当中...')
f.write(music_content)
Time_1()
print('{}.mp3下载成功!'.format(list_music[music_id_1 - 1]))
except:
print('对不起,没有该歌曲的版权!')
if __name__ == '__main__':
KuGou_music()
















 4915
4915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











