







原文链接 https://blog.csdn.net/sjyttkl/article/details/107746928
k means k均值聚类是一种基于中心的聚类算法,通过迭代,将样本分到k个类中,使每个样本与所属类中心的距离之和最小。
假设我们有一个数据集{x1, x2,..., xN},每个样本的特征维度是m维,我们的目标是将数据集划分为K个类别。
假定K值已经给定,第k个类别的中心定义为μk,k=1,2,..., K,μk是一个m维的特征向量。
我们需要找到每个样本所属的类别,以及一组向量{μk},使每个样本与其所属类别的中心μk的距离之和最小。
聚类需要根据样本之间的相似度,对样本集合进行划分,将相似度较高的样本归为一类。
可以通过计算样本之间的欧氏距离、马氏距离、余弦距离或相关系数,来衡量样本之间的相似度。
而K-means是用欧氏距离的平方来度量样本之间的相似度。欧式距离的平方公式如下:
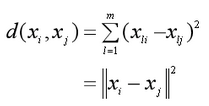



















 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









