







全面理解LSTM网络及输入,输出,hidden_size等参数
LSTM结构(右图)与普通RNN(左图)的主要输入输出区别如下所示
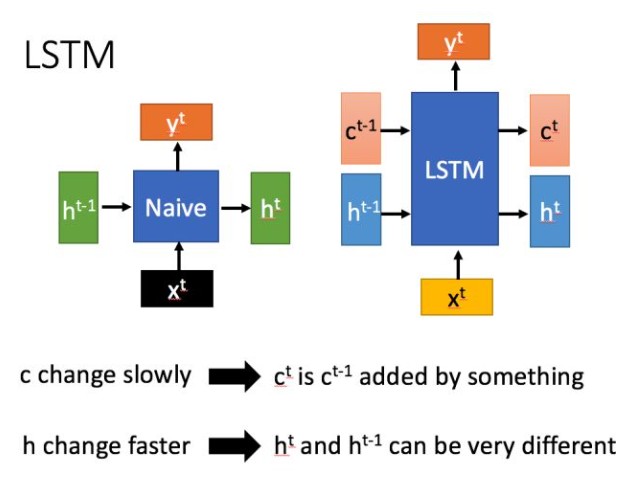
相比RNN只有一个传递状态h^t, LSTM有两个状态,一个c^t(cell state)理解为长时期记忆,和一个h^t(hidden state)理解为短时强记忆。
其中对于传递下去的c^t 改变得很慢,通常输出的c^t 是上一个状态传过来的c^(t-1)加上一些数值。主要是用来保存节点传递下来的数据的,每次传递会对某些维度进行“忘记”并且会加入当前节点所包含的内容,总的来说还是用来保存节点的信息,改变相对较小。 而h^t 则主要是为了和当前输入组合来获得门控信号,对于不同的当前输入,传递给下一个状态的h^t区别也会较大。
深入LSTM结构
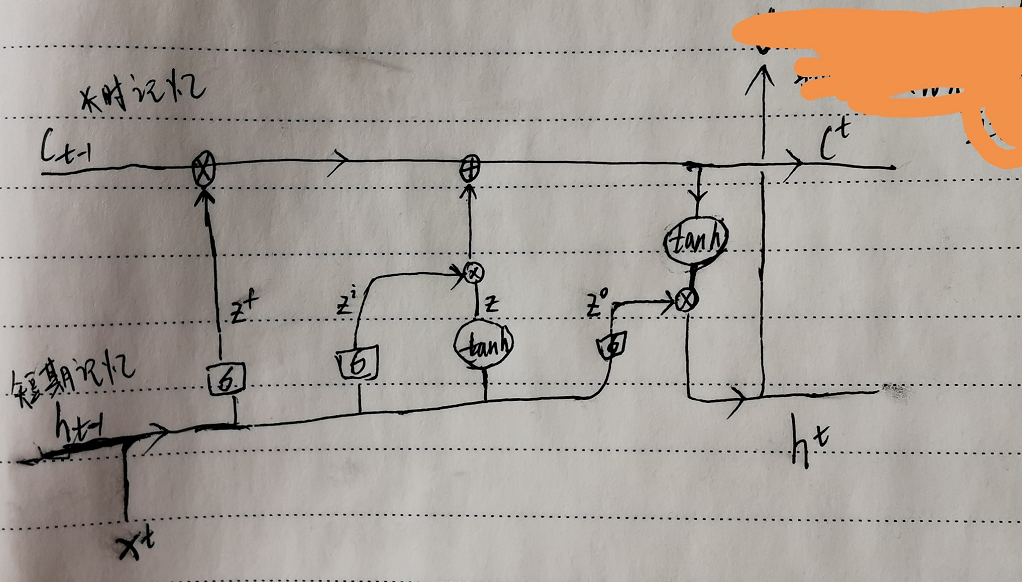
首先使用LSTM的当前输入x^t 和上一个状态传递下来的h^(h-1)拼接训练得到四个状态值
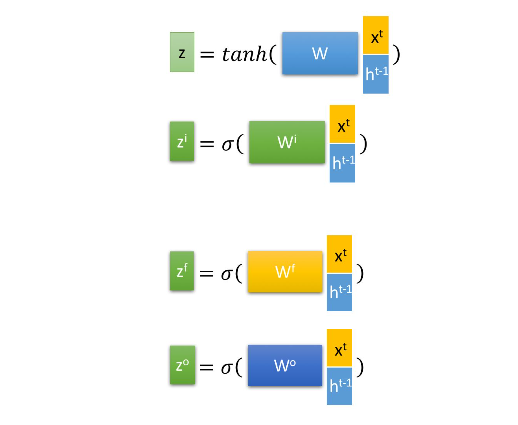
对应上面手画草图理解,通过将输入x^t 和上个时刻隐状态h^(t-1)拼接后乘以权重参数,再通过sigmoid激活函数转换到0到1间的数值,来作为一种门控状态值。而 z, 则是将结果通过一个 tanh激活函数将转换成-1到1之间的值。其中W, W^i, W^f, W^o 就是模型要学习的权重参数,x^t的维度自定义,在NLP中即就是词向量的维度,每一列代表一个词向量,维度自定义。矩阵的列数为一个句子的token个数,也是time_step length。每个sentence的每个token的embedding(词向量)对应了每个时序 t 的输入。如output, (hn, cn) = lstm(input, (h0, c0)),time_step=1时,input为第一个词的词向量,词向量中的每一个元素对应输入层的每个节点(每个神经元),常看到hidden_size就是我们的隐藏节点(神经元),根据上面公式可看出input_size+hidden_size肯定等于权重参数的列数。
LSTM网络cell的输出
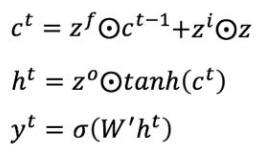
-
忘记阶段,遗忘门z^f, 主要对上一个时刻cell状态c^(t-1) 进行选择性遗忘,即将不重要的忘记。
-
记忆阶段,输入门z^i, 主要是对当前这个阶段的输入进行‘记忆’,当前的输入内容由前面计算得到的z来表示,输入门控由z^i来表示。
将上面两步得到的结果相加,即可得到传输给下个状态的长时记忆c^t, 也就是上面公式的第一个公式
-
输出阶段,输出门z*o, 主要是决定哪些c^t 将会被当成当前隐状态的输出,通过输出门z^o 来进行控制。并且还需要对c^t进行缩放(通过一个tanh激活函数进行变化)
这一步就是上面公式的第二个公式
-
对于分类任务,输出y^t 往往最终通过h^t变化得到,其实就是分类器。
其中c^t 可理解为长期记忆,h^t 可理解为短期记忆。zi、zf、z^o 为通过输入x^t 以及上一次的短期记忆h^{t-1} 产生的门控信息,而z可理解为短期记忆的加工沉淀,可理解为期望输入。长期记忆的更新 c{t}=z{f} \odot c{t-1}+z{i} \odot z,则可理解为两部分的信息叠加。第一部分z^{f} \odot c^{t-1} 是对上一次长期记忆c^{t-1} 经过遗忘门z^f 做一定衰减;第二部分是本次短期记忆沉淀z经过输入门z^i 加入到长期记忆中。
短期记忆输出h^t 则是使用tanh函数对长期记忆的处理后经过输出门z^o得到。
多层LSTM网络结构
其实上面讲解的就是LSTM中的cell。即下图的A
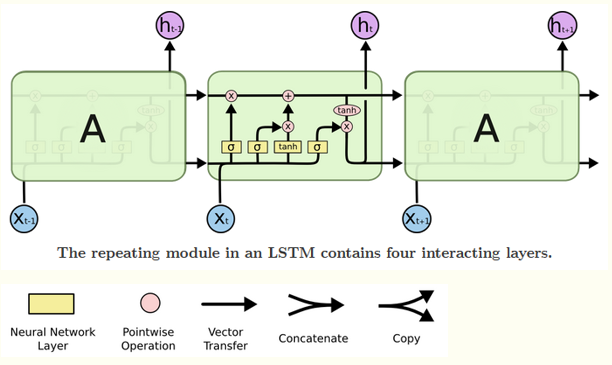
上图A就是cell,从空间上讲,cell是同一个,但是时间上,cell_1表示输入x(1),隐状态h_1,cell_2表示输入x(2),隐状态h_2。所以就知道cell的数量是有序列或time_step决定,每个cell里神经元的个数就是hidden_size(或者叫num_units也行),因为通过上面分析的公式可知,有hidden_size和input_size超参数的设置,就确定了权重参数的大小,就确定了输出output大小,这与CNN的全连接是一样的,
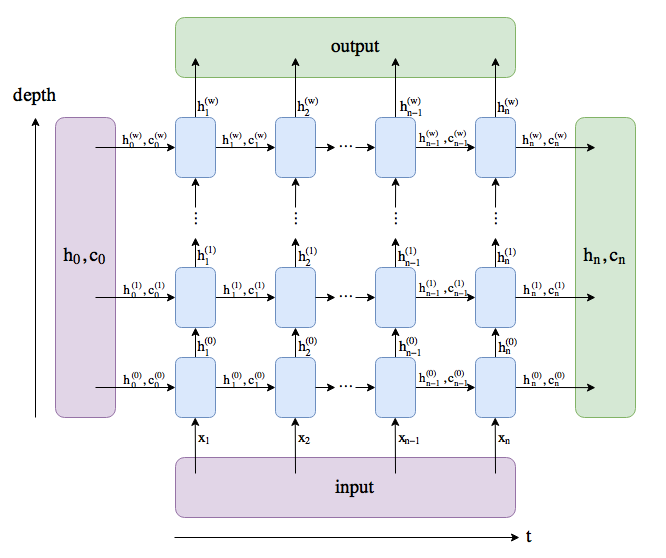
output: 如果num_layer为3,则output只记录最后一层(即,第三层)的输出,shape为(time_step, batch, hidden_size * num_directions), 包含每一个时刻的输出特征,与多少层无关。所以整体LSTM的输出是在最后一个time_step时才能得到,才是最完整的最终结果,output最后一个时步的输出output[-1,:,:]。
*class torch.nn.LSTM(*args, *kwargs)
Parameters
input_size 输入特征维数:(特征向量的长度,如2048)
hidden_size 隐层状态的维数:(每个LSTM单元或者时间步的输出的ht的维度,单元内部有权重与偏差计算)
num_layers RNN层的个数:(在竖直方向堆叠的多个相同个数单元的层数)
bias 隐层状态是否带bias,默认为true
batch_first 是否输入输出的第一维为batchsize
dropout 是否在除最后一个RNN层外的RNN层后面加dropout层
bidirectional 是否是双向RNN,默认为false
output, (hn, cn) = lstm(input, (h0, c0))
lstm输入是input, (h_0, c_0)
input (seq_len, batch, input_size) 时间步数或序列长度,batch数,输入特征维度。如果设置了batch_first,则batch为第一维。
(h_0, c_0) 隐层状态
h0 shape:(num_layers * num_directions, batch, hidden_size) 根据上面多层lstm网络图理解
c0 shape:(num_layers * num_directions, batch, hidden_size)
lstm输出是output, (h_n, c_n)
output (seq_len, batch, hidden_size * num_directions) 包含每一个时刻的输出特征,如果设置了batch_first,则batch为第一维
(h_n, c_n) 隐层状态 各个层的最后一个时步的隐含状态,所以与序列长度seq_len是没有关系的
h_n shape: (num_layers * num_directions, batch, hidden_size)
c_n shape: (num_layers * num_directions, batch, hidden_size)
对于单层单向的LSTM, 其h_n最后一层输出h_n[-1,:,:],和output最后一个时步的输出output[-1,:,:]相等。如果是分类任务的话,就可以把output[-1, :, :]或者output送到一个分类器分类。
比如:在做文字识别中,先对文本行图片提取feature,如shape为(B, 512, 1, 16)其中512是channel 维度,1是height,16是width,tensor处理为(B, 16, 512)或(16, B, 512)因为lstm要求输入是3D的,CNN的feature是4D的。
那这样,512就是input_size, 16就是seq_len
import torch
import torch.nn as nn
# 数据向量维数10, 隐藏元维度20, 2个lstm层串联(如果是1,可以省略,默认为1)
lstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=2)
# 序列长度seq_len=5, batch_size=3, 数据向量维数=10
input = torch.randn(5, 3, 10)
# 初始化的隐藏元和记忆元,通常它们的维度是一样的
# 2个lstm层,batch_size=3,隐藏元维度20
h0 = torch.randn(2, 3, 20)
c0 = torch.randn(2, 3, 20)
# 这里有2层lstm,output是最后一层lstm的每个词向量对应隐藏层的输出,其与层数无关,只与序列长度相关
# hn,cn是所有层最后一个隐藏元和记忆元的输出
output, (hn,cn) = lstm(input, (h0,c0))
print(output.size(),hn.size(),cn.size()) # 分别是:torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
# 查看一下那几个重要的属性:
print("------------输入--》隐藏------------------------------")
print(lstm.weight_ih_l0.size()) # (4*hidden_size, input_size) for `k = 0` 要学习的是四个权重参数
print(lstm.weight_ih_l1.size()) # (4*hidden_size, num_directions * hidden_size) for k!=0
print(lstm.bias_ih_l0.size())
print(lstm.bias_ih_l1.size())
print("------------隐藏--》隐藏------------------------------")
print(lstm.weight_hh_l0.size()) # (4*hidden_size, hidden_size)
print(lstm.weight_hh_l1.size())
print(lstm.bias_hh_l0.size())
print(lstm.bias_hh_l1.size())
print(output[-1:,:,:].equal(hn[-1:,:,:]),'=======')
'''输出结果为:
torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
------------输入--》隐藏------------------------------
torch.Size([80, 10])
torch.Size([80, 20])
torch.Size([80])
torch.Size([80])
------------隐藏--》隐藏------------------------------
torch.Size([80, 20])
torch.Size([80, 20])
torch.Size([80])
torch.Size([80])
True =======
'''














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









