







 本文深入解析贝叶斯公式,从条件概率出发,讲解贝叶斯定理的应用,包括全概率公式、贝叶斯推断及贝叶斯分类。通过实例,详细阐述如何使用贝叶斯公式进行概率估计和分类。
本文深入解析贝叶斯公式,从条件概率出发,讲解贝叶斯定理的应用,包括全概率公式、贝叶斯推断及贝叶斯分类。通过实例,详细阐述如何使用贝叶斯公式进行概率估计和分类。
贝叶斯公式理解
条件概率公式
要理解贝叶斯推断,必须先理解贝叶斯定理。后者实际上就是计算"条件概率"的公式。
所谓条件概率,就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示
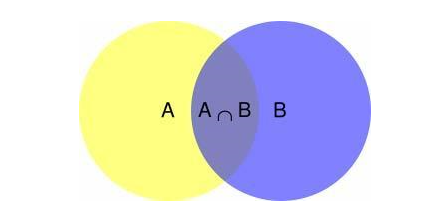
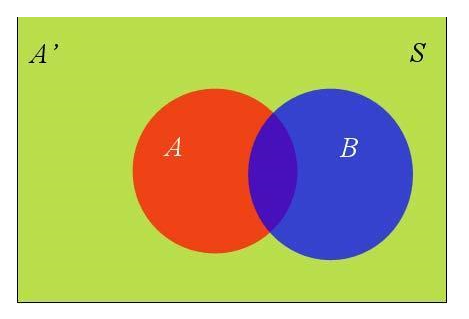
根据韦恩图,可以很容易理解 在事件B发生的情况下(右边紫色区域),事件A也发生(事件A能发生,就只能是中间交集区域)的概率就是P(A∩B)除以P(B),即得在B的条件下A的概率公式为:
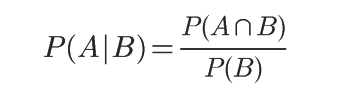
因此可得出 P(A∩B) = P(A|B)P(B)
同理可得 P(A∩B) = P(B|A)P(A),即得乘法公式
P(A∩B) = P(AB) = P(A|B)P(B) = P(B|A)P(A)
可得条件概率另一种写法为:
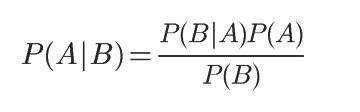
全概率公式
假定样本空间S,是两个事件A与A’的和。
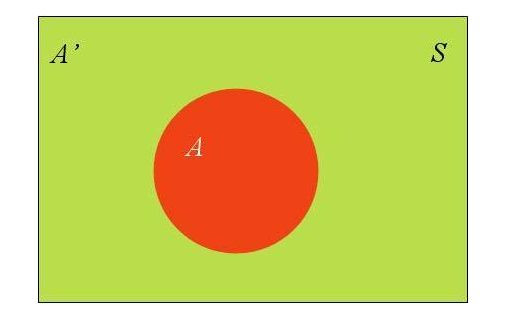
上图中,红色部分是事件A,绿色部分是事件A’,它们共同构成了样本空间S。
在这种情况下,事件B可以划分成两个部分
P(B) = P(A∩B) + P(A’∩B) 同时有条件概率的乘法公式 P(A∩B) = P(AB) = P(A|B)P(B) = P(B|A)P(A) ,可得全概率公式
P(B) = P(B|A)P(A) + P(B|A’)P(A’)
它的含义是,如果A和A’构成样本空间的一个划分,那么事件B的概率,就等于A和A’的概率分别乘以在这两个事件下B的条件概率之和。
同时也得到了条件概率的另一种写法为:
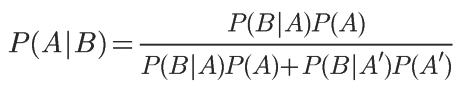
若事件推广到n,
-
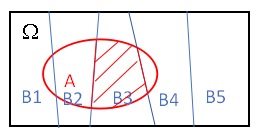
如果事件组B1,B2,… 满足
-
B1,B2…两两互斥,即 Bi ∩ Bj = ∅ ,i≠j , i,j=1,2,…,且P(Bi)>0,i=1,2,…;
-
B1∪B2∪…=Ω ,则称事件组 B1,B2,…是样本空间Ω的一个划分
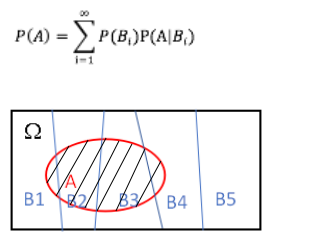
设 B1,B2,…是样本空间Ω的一个划分,A为任一事件,则全概率公式为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KmEdxYt9-1579162544420)(C:\Users\chengt1\Documents\Typora-images\微信截图_20200115163013.png)] -
它的含义是,如果B1,B2,,,Bi构成样本空间的一个划分,那么事件A的概率,就等于B1,B2,,,Bi的概率分别乘以在这些事件下A的条件概率之和。
假设A,B都是样本,那么 A的样本数目可以通过与Bi的交集来获得,也即=(A∩B1的样本数)+(A∩B2的样本数)+····+(A∩Bn的样本数)
贝叶斯公式
对条件概率公式进行变形,可以得到如下形式:
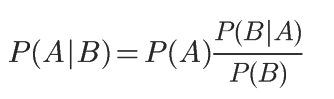
把P(A)称为先验概率,即在B事件发生之前,我们对A事件概率的一个判断。P(A|B)称为后验概率,即在B事件发生之后,我们对A事件概率的重新评估。P(B|A)/P(B)称为"可能性函数“,这是一个调整因子,使得预估概率更接近真实概率。
后验概率 = 先验概率 x 调整因子
这就是贝叶斯推断的含义。我们先预估一个先验概率,然后加入实验结果,看这个实验到底是增强还是削弱了先验概率,由此得到更接近事实的后验概率。
若事件推广到n, 设B1,B2,…是样本空间Ω的一个划分,则对任一事件A(P(A)>0),有
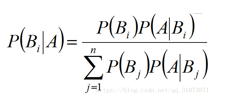
公式中Bi 常被视为导致试验结果A发生的”原因“,P(Bi)(i=1,2,…)表示各种原因发生的可能性大小,故称先验概率;P(Bi|A)(i=1,2…)则反映当试验产生了结果A之后,再对各种原因概率的新认识,故称后验概率。
贝叶斯公式是建立在条件概率的基础上(指的是公式的分子部分)寻找事件发生的原因(即大事件A已经发生的条件下,分割中的小事件Bi的概率)
可看出贝叶斯公式就是条件概率,乘法公式,全概率公式的组合,分子是条件概率的乘法公式,分母是全概率公式
网上的一个例子来在加深理解
两个一模一样的碗,一号碗有30颗水果糖和10颗巧克力糖,二号碗有水果糖和巧克力糖各20颗。现在随机选择一个碗,从中摸出一颗糖,发现是水果糖。请问这颗水果糖来自一号碗的概率有多大?
我们假定,H1表示一号碗,H2表示二号碗。由于这两个碗是一样的,所以P(H1)=P(H2),也就是说,在取出水果糖之前,这两个碗被选中的概率相同。因此,P(H1)=0.5,我们把这个概率就叫做"先验概率",即没有做实验之前,来自一号碗的概率是0.5。
再假定,E表示水果糖,所以问题就变成了在已知E的情况下,来自一号碗的概率有多大,即求P(H1|E)。我们把这个概率叫做"后验概率",即在E事件发生之后,对P(H1)的修正。
根据条件概率公式,得到

这表明,来自一号碗的概率是0.6。也就是说,取出水果糖之后,H1事件的可能性得到了增强(将先验概率0.5提高到后验概率0.6)。
贝叶斯分类
利用贝叶斯判定准则来进行分类,首先要获得后验概率P(c|x),有了后验概率,表示某事发生了,并且它属于某一类别的概率,所以我们就可以对样本进行分类。若后验概率越大,说明某事物属于这个类别的可能性越大,我们越有理由把它归到这个类别下。
机器学习要实现的是基于有限的训练样本集尽可能准确的估计出后验概率P(c|x)。主要有两种模型:一是“判别式模型”:通过直接建模P(c|x)来预测,其中决策树,BP神经网络,支持向量机都属于判别式模型。另外一种是“生成式模型”:通过对联合概率模型P(x,c)进行建模,然后再获得P(c|x)。对于生成模型来说:
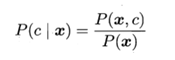
基于贝叶斯定理,可写为下式
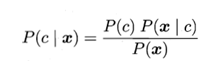
通俗的理解:

其中公式中 P©是类先验概率,P(x|c)是样本x相对于类标记c的类条件概率,或称似然。p(x)是用于归一化的“证据因子“,对于给定样本x,证据因子p(x)与类标记无关。于是,估计p(c|x)的问题变为基于训练数据来估计p©和p(x|c),对于条件概率p(x|c)来说,它涉及x所有属性的联合概率。
-
先验概率p© 的估计较简单,1、每个样本所属的自然状态都是已知的(有监督学习);2、依靠经验;3、用训练样本中各类出现的频率估计。
-
类条件概率的估计(非常难),原因包括:概率密度函数包含了一个随机变量的全部信息;样本数据可能不多;特征向量x的维度可能很大等等。解决的办法就是,把估计完全未知的概率密度p(c|x)转化为估计参数,极大似然估计就是一种参数估计方法
假设p(x|c))具有确定的形式并且被参数向量唯一确定,则我们的任务是利用训练集估计参数θc,将P(x|c)记为P(x|θc)。令Dc表示训练集D第c类样本的集合,假设样本独立同分布,则参数θc对于数据集Dc的似然是
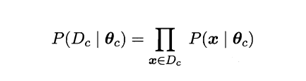
对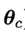 进行极大似然估计,就是去寻找能最大化P(Dc|θc)的参数值
进行极大似然估计,就是去寻找能最大化P(Dc|θc)的参数值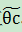 。直观上看,极大似然估计是试图在θc所有可能的取值中,找到一个能使数据出现的“可能性”最大的值。
。直观上看,极大似然估计是试图在θc所有可能的取值中,找到一个能使数据出现的“可能性”最大的值。

也就是说,通过极大似然法得到的正态分布均值就是样本均值,方差就是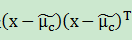 的均值。假定
的均值。假定 类样本在第i个属性上取值的均值和方差,通过正态分布概率密度函数可计算出p(xi|c)
类样本在第i个属性上取值的均值和方差,通过正态分布概率密度函数可计算出p(xi|c)
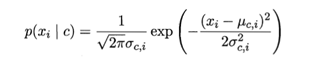
对于离散属性而言,Dc,xi表示在第i个属性上取值为xi的样本组成的集合,则条件概率p(xi|c) 估计为
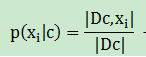
推荐看看此篇文章对极大似然估计的详解https://blog.csdn.net/qq_39355550/article/details/81809467

















 3518
3518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









