




简介
模型压缩主要有量化、剪枝、蒸馏和二值化四种方法,旨在减少模型大小、加快训练速度和保持模型精度。

模型压缩在推理过程中的作用,如下图所示:

本文主要介绍离线优化压缩方法之一:低比特量化。
一、低比特量化
1、量化基础
将浮点数计算转换成低比特定点计算,有效降低模型计算量、参数量和内存消耗量,但往往会带来一定的精度损失。尤其是在极低比特(<4bit)、二值网络(1bit)、甚至是将梯度进行量化。

混合精度是fp16和fp32的表示。
2、模型量化优点
保持精度、加速运算、节省内存、节能和减少芯片面积。
3、量化挑战
(1)精度:线性量化对数据分布的描述不准确;从16bits到4bits比特数越低,精度损失越大;分类、检测和分割任务越复杂,精度损失越达;模型越小,精度越小。
(2)硬件支持:不同硬件支持的低比特指令不同;不同硬件提供不同的低比特指令计算方式不同(PF16、HF32);不同硬件体系结构kernel优化方式不同。

(3)软件算法是否支持加速
混合比特量化需要进行量化和反向量化,插入cast算子影响kernel的执行性能;降低运行内存的占用,与降低模型参数量的差异;模型参数量小,压缩比高,不代表运行内存占用少。

4、量化方法
(1)量化训练(Quant Aware Training, QAT):模型训练让模型感知量化运算对模型精度带来的影响,通过微调(finetune)训练降低量化误差。
(2)静态离线量化(Post Training Quantization Static, PTQ Static):静态离线量化使用少量无标签校准数据,采用KL散度等方法计算量化比例因子。
(3)动态离线量化(Post Training Quantization Dynamic, PTQ Dynamic):动态离线量化仅将模型中特定算子的权重从FP32类型映射成INT8/16类型。

| 量化方法 | 功能 | 使用场景 | 使用条件 | 易用性 | 精度损失 | 效果 |
|---|---|---|---|---|---|---|
| QAT | 通过微调训练将模型量化误差降到最小 | 对量化敏感的场景,如图像目标检测、分割、OCR等 | 有大量标签数据 | 好 | 极小 | 减少存续空间4x,降低计算内存 |
| PTQ Static | 通过少量校准数据得到量化模型 | 对量化不敏感的场景,如图像分类 | 有少量标签数据 | 较好 | 较小 | 减少存续空间4x,降低计算内存 |
| PTQ Dynamic | 仅量化模型的可学习权重 | 模型体积大,访存开销大,如BERT模型 | 无 | 一般 | 一般 | 减少存续空间2/4x,降低计算内存 |
5、量化原理
建立一种从浮点到定点的有效数据映射关系,使得以较小的精度损失代价获得更好的收益。

浮点和定点数据的转换公式如下:
Q = R / S + Z Q = R / S + Z Q=R/S+Z,
R = ( Q − Z ) ∗ S R = (Q- Z) * S R=(Q−Z)∗S,
其中,R代表输入的浮点数据;Q代表量化后的定点数据;Z代表零点(zero point)的数据;S代表缩放因子(scale)的数值。
举例一种线性量化的求解方法(Min-Max):
S = ( R m a x − R m i n ) / ( Q m a x − Q m i n ) S = (R_{max} - R_{min}) / (Q_{max} - Q_{min}) S=(Rmax−Rmin)/(Qmax−Qmin),
Z = Q m a x − R m a x / S Z = Q_{max} - R_{max} / S Z=Qmax−Rmax/S,
其中, R m a x R_{max} Rmax代表输入浮点数据中的最大值; R m i n R_{min} Rmin代表输入浮点数据中的最小值; Q m a x Q_{max} Qmax代表最大的定点值(127/255); Q m i n Q_{min} Qmin代表最小的定点值(-128/0)。
6、量化类型
线性量化可分为对称量化(以0为中心)和非对称量化。左边以0为中心对称,映射后的数据一般使用int类型(-127到127);右边非中心对称,映射后的数据一般使用uint类型(0到255)。

下面以非对称量化为例进行介绍:
量化算法原始浮点精度数据与量化后的int8数据的转换如下:
f l o a t = s c a l e ( S ) ∗ ( u i n t + o f f s e t ( Z ) ) , float = scale(S) * (uint + offset(Z)), float=scale(S)∗(uint+offset(Z)),
确定后通过原始float32高精度数据计算得到uint8数据的转换即为如下公式:
u i n t 8 = r o u n d ( f l o a t / s c a l e ) − o f f s e t , uint8 = round(float / scale) - offset, uint8=round(float/scale)−offset,
若待量化数据的取值范围为[ x m i n x_{min} xmin, x m a x x_{max} xmax],则scale的计算公式如下:
s c a l e = ( x m a x − x m i n ) / ( Q m a x − Q m i n ) . scale = (x_{max} - x_{min}) / (Q_{max} - Q_{min}). scale=(xmax−xmin)/(Qmax−Qmin).
offset的计算方式如下:
o f f s e t = Q m i n − r o u n d ( x m i n / s c a l e ) offset = Q_{min} - round(x_{min} / scale) offset=Qmin−round(xmin/scale)
对于权值和数据的量化,都采用上述方式进行量化,x_min和x_max为待量化参数的最小值和最大值, Q m a x = 2 n Q_{max} = 2^{n} Qmax=2n, Q m i n = 0 Q_{min} = 0 Qmin=0。
二、感知量化QAT
感知量化训练(Aware Quantization Training)模型中插入伪量化节点fake quant来模拟量化引入的误差,端侧推理时折叠伪量化(fake quant)节点中的属性到tensor,推理时直接使用tensor中带有的量化属性参数。
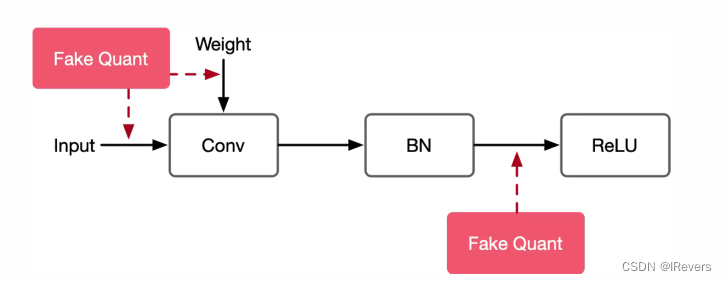
1、伪量化节点
(1)找到输入参数的分布,即找到最大值和最小值;
(2)模拟量化到低比特操作时(如float32到int8)的精度损失,把该损失作用到模型中,传递给损失函数,让优化器在训练过程中优化该损失值。
伪量化节点的正向传播forward:
为了求得模型中tensor数据的最大值和最小值,在模型训练时插入为量化节点来模拟引入的误差,得到数据的分布。对于每个算子,量化参数通过如下公式得到(旨在保持数据在最大值和最小值之间):
c l a m p ( x , x m i n , x m a x ) : = m i n ( m a x ( x , x m i n ) , x m a x ) clamp(x, x_{min}, x_{max}) := min(max(x, x_{min}), x_{max}) clamp(x,xmin,xmax):=min(max(x,xmin),xmax)
伪量化节点的反向传播backward:
按照正向传播的公式,反向传播时对其求导会导致权重为零,使用下述公式代替:
d e l t a o u t = d e l t a i n ( 当 x m i n < = x < = x m a x ) delta_{out} = delta_{in} (当x_{min} <= x <= x_{max}) deltaout=deltain(当xmin<=x<=xmax), 其他情况则保持恒定值。
伪量化算子更新最大值和最小值:
为量化节点主要是根据找到的最大值和最小值进行伪量化操作,更新最大值和最小值的方式类似于BatchNorm更新beta和gamma算子。
2、应用
卷积等密集计算算子、激活算子、网络输入和输出等地方插入伪量化节点。
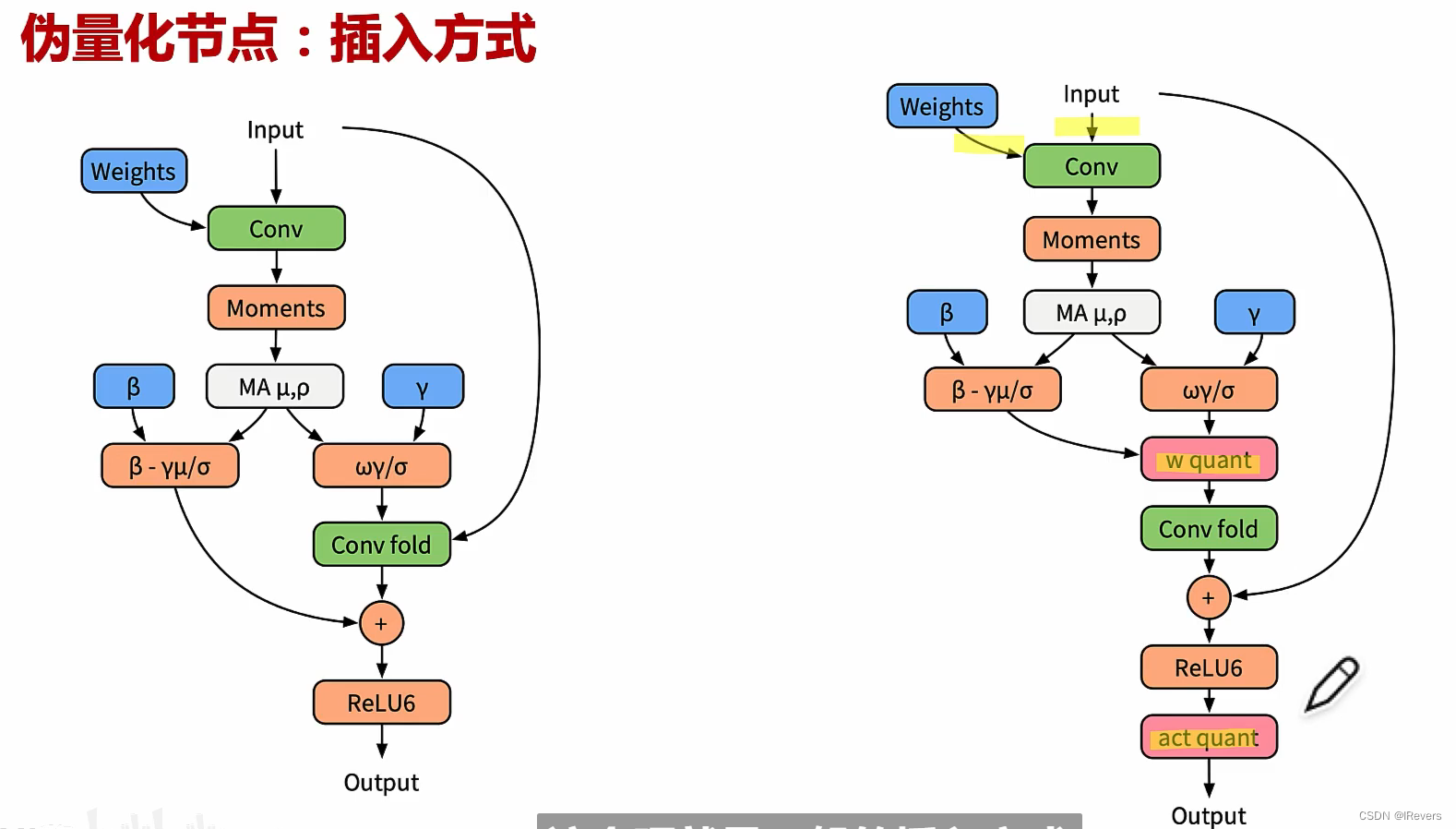
3、伪量化算子插入
示例(左边是原始网络,右边标黄色的位置为伪量化节点插入的位置),同时,在实际的推理过程中还会将伪量化节点和BatchNorm等操作进行精简 :
4、QAT工作流程
如下图所示:

三、训练后量化(PTQ)
训练后的量化主要分为动态离线量化和静态离线量化,下面分别对它们进行介绍:
1、PTQ动态
动态离线量化:仅将模型中特定算子的权重从fp32类型映射成int8/16类型;主要可以减少模型大小,对特定加载权重费时的模型可以起到一定的加速效果;但对不同输入值,其缩放因子是动态计算,因此动态量化是几种量化方法中性能最差的。
权重量化成int16类型,模型精度不受影响,模型大小为原来的1/2;
权重量化成int8类型,模型精度会受影响,模型大小为原来的1/4。
2、PTQ静态(校正量化)
也称为校正量化或数据集量化,使用少量无标签校准数据,核心是计算量化算子的比例因子scale。使用静态量化后的模型进行预测,在此过程中,量化模型的缩放因子会根据输入数据的分布进行调整:
u i n t 8 = r o u n d ( f l o a t / s c a l e ) − o f f s e t , uint8 = round(float / scale) - offset, uint8=round(float/scale)−offset,
静态离线量化的目标是求取量化比例因子,主要通过对称量化、非对称量化方式进行求解,而找最大值或阈值的方法又有MinMax、KLD、ADMM、EQ等方法。下面介绍其中的KL校正方法。

KL散度校正法的算法流程:
(1)选取验证数据集中一部分具有代表性的数据作为校准数据集(小批量);
(2)对校正数据进行fp32的推理,对每一层,先收集每层输出的分布直方图;使用不同的阈值来生成一定数量的量化后的数据;计算量化后数据的分布与fp32数据分布的KL散度(相对熵),并选取使KL最小的阈值最为稳定后的阈值。
Nvidia的Tensor RT中基于KL散度的静态离线量化方法伪代码:

四、量化部署
端侧量化推理的模块结构方式主要有三种,分别是下图(a)fp32输入fp32输出;(b)fp32输入int8输出;(c)int8输入int32输出。
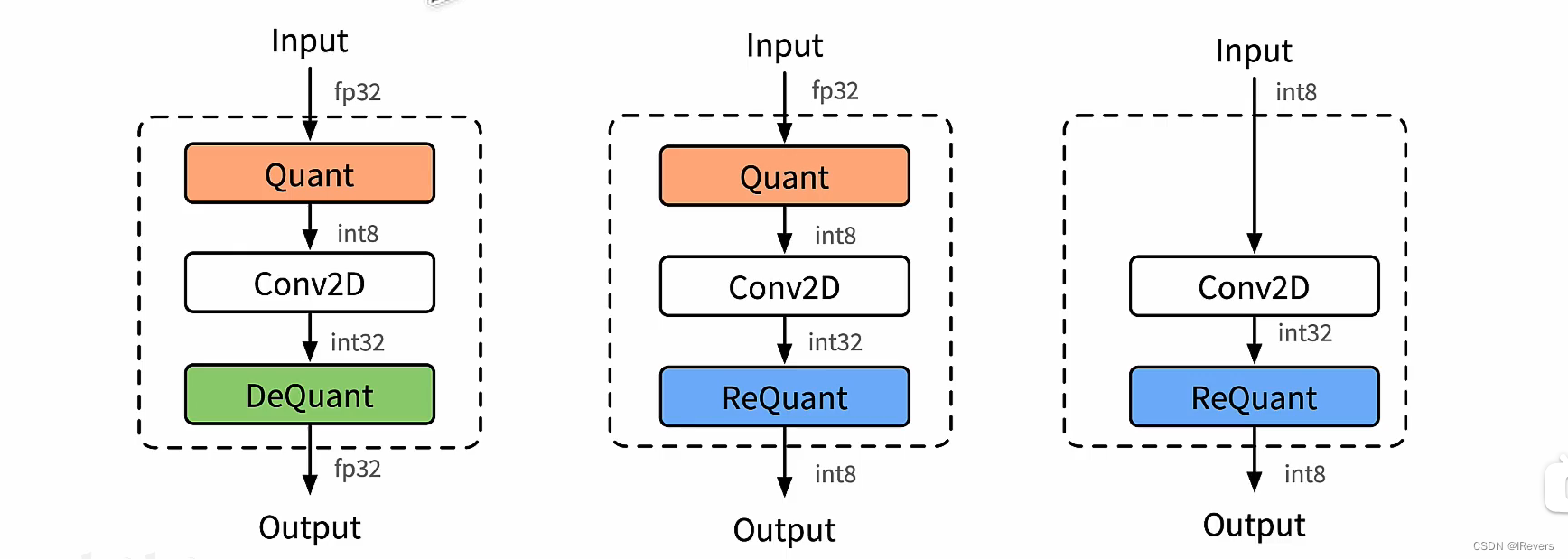
下面以int8卷积进行举例,里面混合着三种不同的模式,不同的卷积通过不同的方式进行拼接。使用int8进行推理时,由于数据是实时的,因此数据需要在线量化,量化的流程如下图所示,其中数据量化涉及量化Quantize、反量化Dequantize和重量化Requantize三种操作。
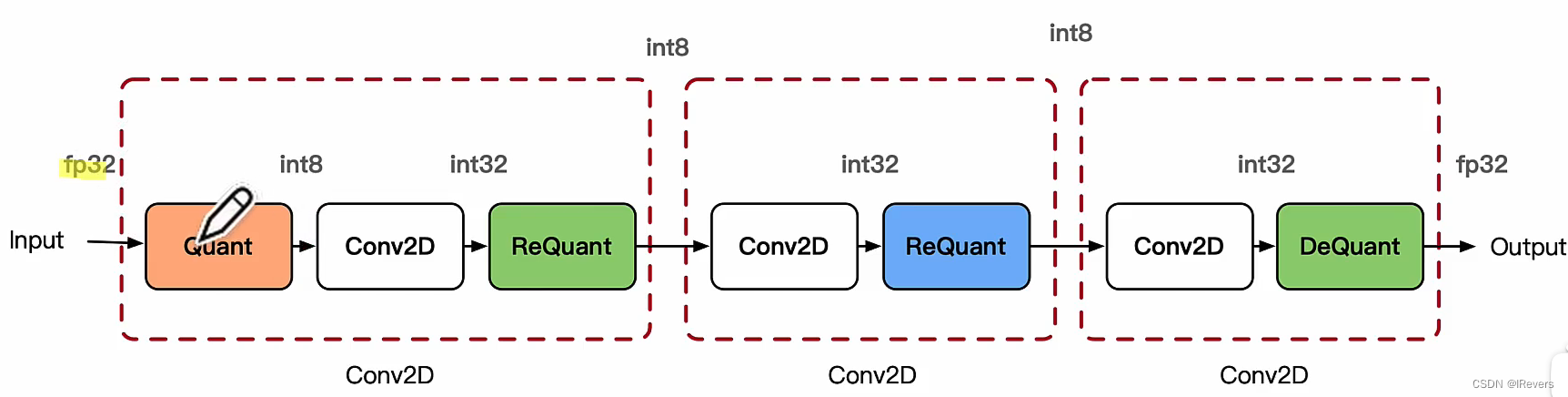
下面分别介绍三种操作的具体计算流程:
- 量化操作:

- 反量化操作:

- 重量化操作:

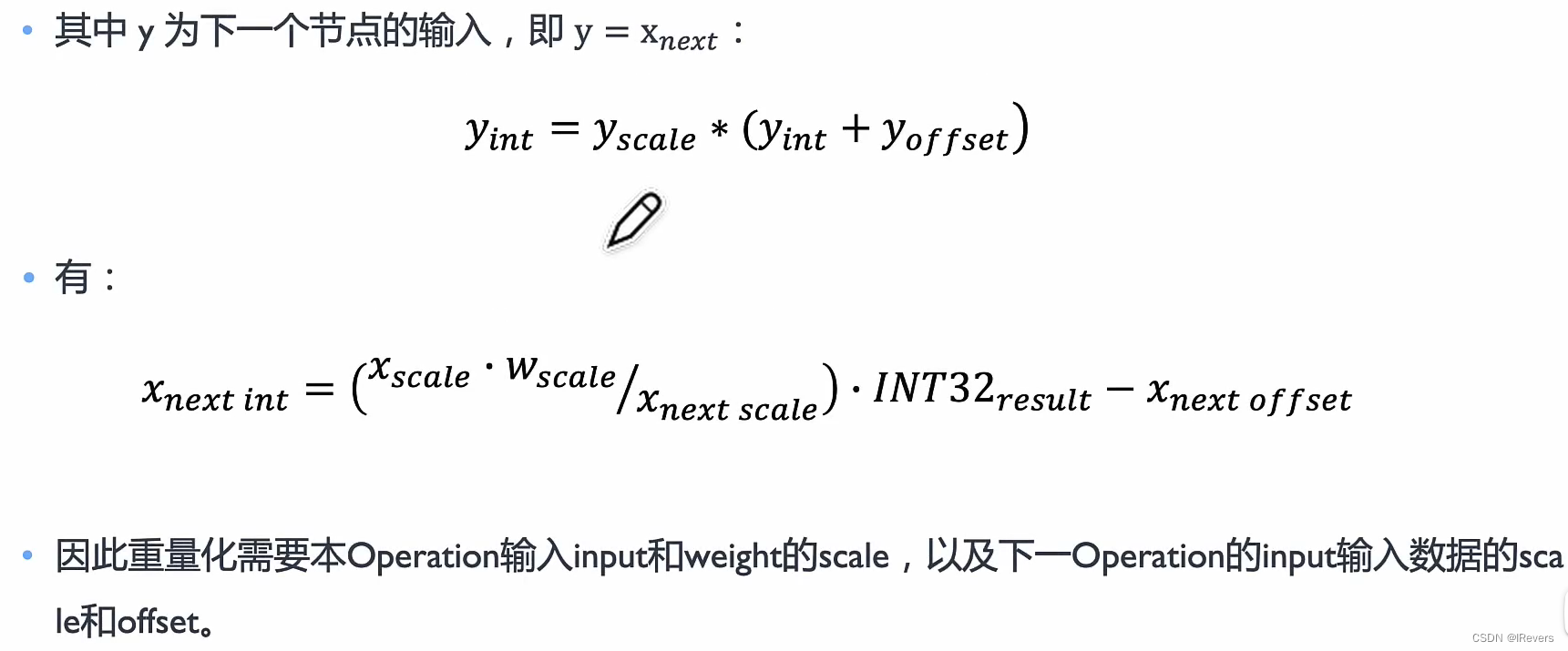
五、总结
模型量化方法可以提高模型推理的速度和资源的利用率,主要是将低比特量化操作应用到训练时的感知量化(插入伪量化节点)和训练后动态量化和训练后静态量化(校正量化)。
六、参考
[1] https://zhuanlan.zhihu.com/p/453992336?utm_medium=social&utm_oi=919687111576289280
[2] https://www.bilibili.com/video/BV1HD4y1n7E1/?p=4&spm_id_from=pageDriver



















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











