







这篇博客主要记录这段时间学习长尾学习的内容,主要介绍长尾学习的概念,数据集和一些基础方法介绍。主要内容来源于2023年颜水成老师团队在PAMI上的综述文章,该文章主要介绍到2021年中旬的长尾学习方法。(文中的文献索引均来自《Deep Long-Tailed Learning: A Survey》)
一、长尾学习
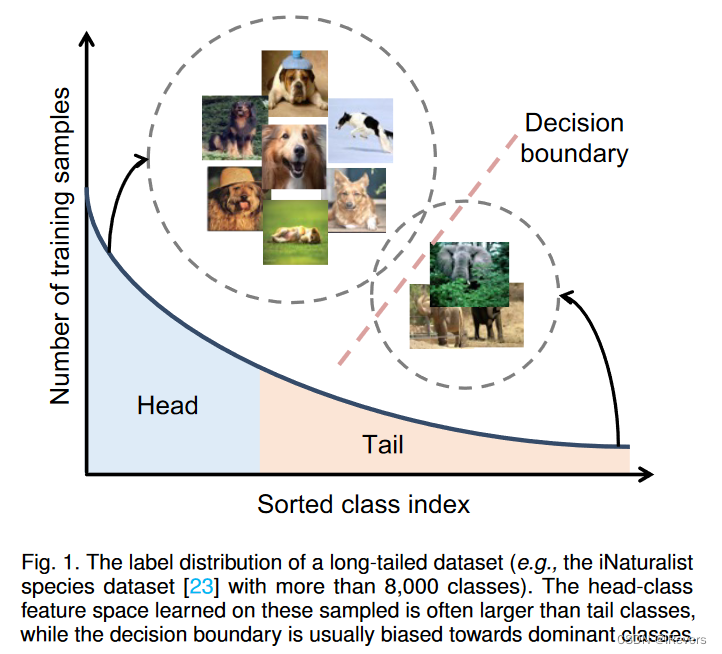
针对类别数量多,尾类样本少的情况。在类不平衡学习中,少数类样本的数量在绝对意义上不一定很小。
长尾学习与其他任务的区别:
-
类不平衡学习[5],[72]也试图从类不平衡样本中训练模型。从这个意义上说,长尾学习可以看作是班级不平衡学习的一个具有挑战性的子任务。主要的区别在于,长尾学习的类别遵循长尾类别分布,这对于班级不平衡的学习来说不是必需的。
-
小样本学习[73]、[74]、[75]、[76]旨在从每个类有限数量的标记样本(例如,1或5个)中训练模型。小样本学习可以看作是长尾学习的一个子任务,其中尾类的样本数量一般很少。
-
域外泛化[77],[78]表示一类任务,其中训练分布与未知测试分布不一致。这种不一致包括不一致的数据边际分布(例如,领域适应[79],[80],[81],[82],[83],[84]和领域泛化[85],[86]),不一致的类分布(例如,长尾学习[15],[28],[32],开放集学习[87],[88]),以及前两种情况的组合。长尾学习可以看作是域外泛化中的一项特定任务。
二、数学定义

三、数据集
长尾学习数据集主要包含图像识别、目标检测与分割、视频等。
Image classification:
| 数据集名称 | ImageNet-LT | Pleces-LT | iNaturalist 2018 | CIFAR100-LT |
|---|---|---|---|---|
| 不平衡率 | 256 | 996 | 500 | 10,50,100 |
Object detection and instance segmentation
| LVIS | VOC-LT | COCO-LT |
|---|
Video: VIdeoLT
四、方法介绍(一)
现主要针对这段时间学习的方法进行一部分介,其中包括非深度学习的方法和深度学习的方法,主要针对重采样方法(模型训练的策略修正)进行介绍。
1、非深度长尾学习方法
-
regularize kernel machine algorithm [65]
-
Pitman-Yor Processes (PYP)
-
Scale Invariant Feature Transform (SIFT)
-
Histogram of Gradient Orientation (HOG)
-
RGB color histogram
2、经典方法
Re-sampling已经探索了重采样 [126], [127], [128], [129] 通过调整每个样本批次中每个类别的样本数量来重新平衡类以进行模型训练。
(1) 针对模型训练的方法
随机过采样(ROS)[44]:重复对数量少的类别(尾类)的样本进行采样,容易对尾类过拟合。
随机欠采样(RUS)[44]:丢弃多样本类别的样本(头类),容易导致对头类识别性能的降低。
Decoupling [32]:评价random sampling, class-balanced sampling, squareroot sampling and progressively-balanced sampling四种方法:
-
random sampling:一般的随机采样方法,不考虑任何因素;
-
class-balanced sampling:每个类别都以一定的概率进行采样;
-
square root sampling [130]:每个类的采样概率与相应类中样本量的平方根有关;
-
progressively-balanced sampling [32]:在随机抽样和类平衡抽样之间逐步插值。
从Decoupling的结论上看,squareroot sampling和progressively-balanced sampling表现更好,但它们需要提前知道不同类的训练采样频率,这在实际应用中可能不可用。
Dynamic Curriculum Learning(DCL)[93]:随着训练的进行,对一个类的样本进行采样的次数越多,该类在后期阶段被采样的概率就越低。
Long-tailed Object Detector with Classification Equilibrium(LOCE)[33]:提出通过平均分类预测分数(即运行预测概率)来监测不同类别的模型训练,并利用该分数来指导不同类别的采样率。
VideoLT [38] :专注于长尾视频识别,引入了一种新的 FrameStack 方法,该方法在训练过程中根据运行模型的性能动态调整不同类的采样率,从而可以从尾类中采样更多的视频帧(通常运行性能较低)。
(2) 针对元学习[131]的方法
Balanced Meta-softmax [97]:开发了一种基于元学习的抽样方法,用于估计长尾学习不同类别的最佳采样率。具体地,通过优化平衡元验证集上的模型分类性能来学习最佳样本分布参数。
Feature Augmentation and Sampling Adaptation (FASA)[58]:探索了平衡元验证集上的模型分类损失作为分数,用于调整不同类别的采样率,以便可以对代表性不足的尾类进行更多采样。
Simple Calibration (SimCal)[34]:提出了一种新的双级类平衡采样策略,该策略结合了图像级和实例级重采样,以实现类重平衡。
五、总结
重采样方法旨在解决样本水平的类不平衡问题。当先验地知道不同类别的标签频率时,建议采用渐进平衡采样[32]。否则,使用模型训练的统计量来指导重采样[33]是实际应用的首选解决方案。对于基于元学习的重采样,在真实场景中构建元验证集可能很困难。请注意,如果一种重采样策略已经很好地解决了类不平衡问题,那么进一步使用其他重采样方法可能不会带来额外的好处。此外,如果实际应用中存在多个层次的不平衡,这些重采样方法的高级思想可以应用于设计多级重采样策略。
六、参考文献
http://arxiv.org/abs/2110.04596



















 4137
4137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











