







【图像超分】
[NeurIPS 2024] Taming Diffusion Prior for Image Super-Resolution with Domain Shift SDEs
论文链接:https://arxiv.org/abs/2409.17778
代码链接:https://github.com/QinpengCui/DoSSR
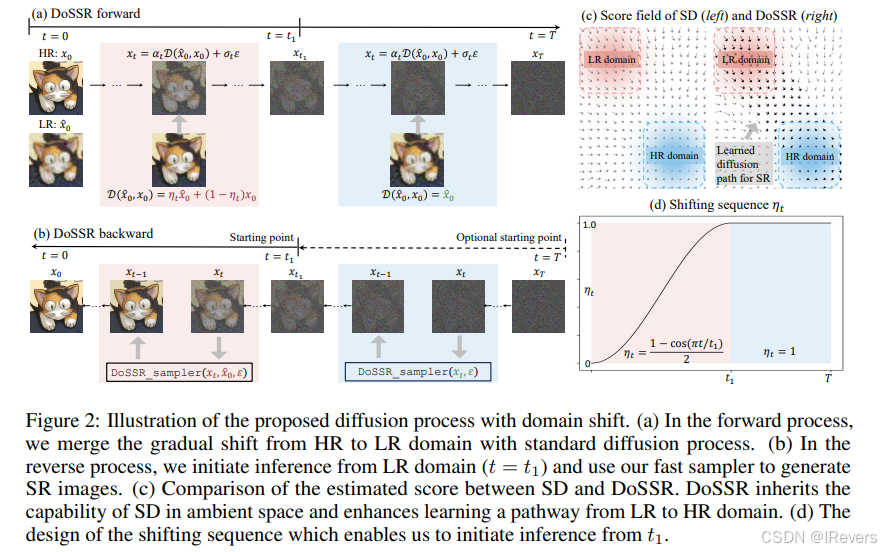
基于扩散的图像超分辨率(SR)模型因其强大的图像恢复能力而引起了广泛关注。然而,现有的扩散模型往往难以在效率和性能之间找到最佳平衡。通常,它们要么忽视了利用现有广泛预训练模型的潜力,限制了其生成能力,要么需要从随机噪声开始进行多次前向传播,从而降低了推理效率。本文提出了DoSSR,一种基于域转移的扩散型SR模型,它利用预训练扩散模型的生成能力,同时通过从低分辨率(LR)图像开始扩散过程显著提高效率。所提方法的核心是一个与现有扩散模型无缝集成的域转移方程。这种集成不仅改善了扩散先验的使用,还提升了推理效率。此外,通过将离散转移过程过渡到连续形式化,即所谓的DoS-SDEs,进一步改进了所提方法。这一进展导致了快速且定制化的求解器,进一步提高了采样效率。实证结果表明,提出的方法在合成和真实世界数据集上均达到了最先进的性能,同时仅需5个采样步骤。与之前的基于扩散先验的方法相比,所提方法实现了5-7倍的显著加速,展示了其卓越的效率。
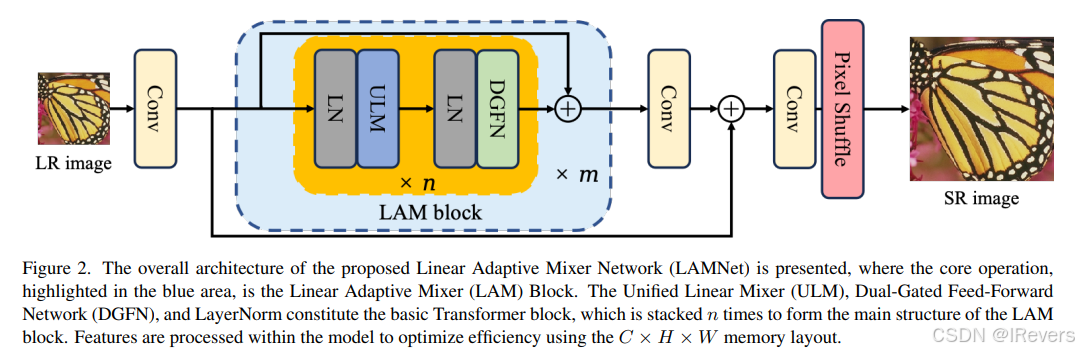
[2024 LAMNet ] Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution
论文链接:https://arxiv.org/pdf/2409.17597
代码链接:https://github.com/zononhzy/LAMNet
基于窗口的Transformer在超分辨率任务中表现出色,这归功于其通过局部自注意力(SA)实现的自适应建模能力。然而,与卷积神经网络相比,它们表现出更高的计算复杂度和推理延迟。本文指出,Transformer的适应性源自其自适应空间聚合和高级结构设计,而其高延迟则源于与局部 SA 相关的计算成本和内存布局转换。为了模拟这种聚合方法,作者提出了一种有效的基于卷积的线性焦点可分离注意力(FSA),允许以线性复杂度进行长距离动态建模。此外,还引入了一种有效的双分支结构,结合一个超轻量级信息交换模块(IEM),以增强 Token Mixer 的信息聚合能力。最后,结构方面通过引入自门机制改进了现有的基于空间门的前馈神经网络,以保留高维通道信息,从而能够建模更复杂的关系。凭借这些进步,构建了一个名为**线性自适应混合网络(LAMNet)**的基于卷积的Transformer框架。广泛的实验表明,LAMNet 在性能上超越了现有的基于 SA 的Transformer方法,同时保持了卷积神经网络的计算效率,可以将推理时间提速3倍。
【人脸识别】
[NeurIPS 2024] ID^{3}: Identity-Preserving-yet-Diversified Diffusion Models for Synthetic Face Recognition
论文链接:https://arxiv.org/pdf/2409.17576
代码链接:无
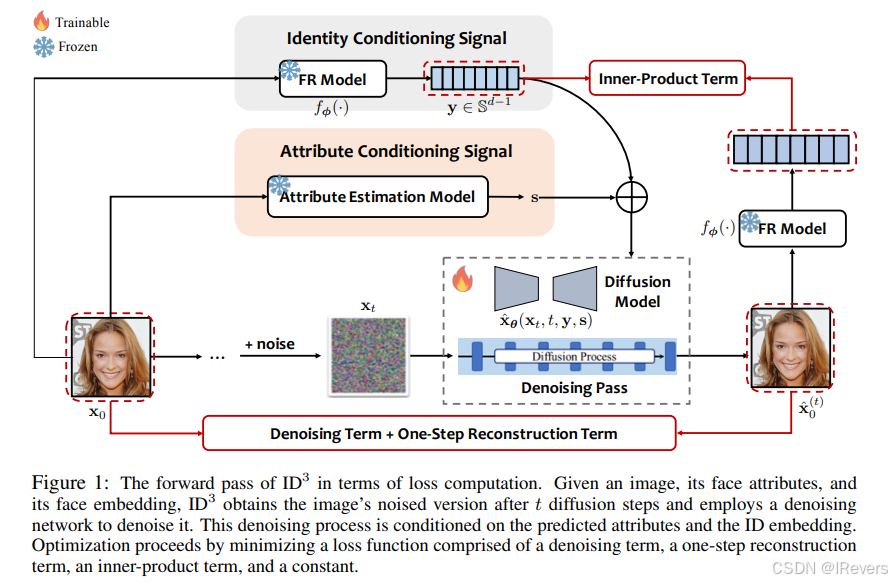
合成人脸识别(SFR)旨在生成模仿真实人脸数据分布的合成人脸数据集,从而允许以保护隐私的方式训练人脸识别模型。尽管扩散模型在图像生成方面具有显著潜力,但现有的基于扩散的 SFR 模型在泛化到真实世界人脸上存在困难。为了解决这一限制,作者概述了 SFR 的三个关键目标:(1)促进不同身份之间的多样性(类间多样性),(2)通过注入各种面部属性确保每个身份内的多样性(类内多样性),以及(3)在每个身份组内保持身份一致性(类内身份保留)。受这些目标的启发,作者引入了一种称为
I
D
3
ID^{3}
ID3 的扩散驱动的 SFR 模型。
I
D
3
ID^{3}
ID3采用一种 ID 保留损失来生成多样化且身份一致的面部外观。理论证明最小化这个损失等价于最大化调整后的条件对数似然的下界,该条件适用于保留 ID 的数据。这种等价性激发了一种 ID 保留采样算法,该算法在调整后的梯度向量场上操作,使得生成的伪造人脸识别数据集能够近似真实世界人脸的分布。在五个具有挑战性的基准测试上的广泛实验验证了 ID3 的优势。


















 9505
9505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











