





reference:https://github.com/rafaelpadilla/Object-Detection-Metrics
计算mAP的github:https://github.com/Cartucho/mAP
基础概念
1.IoU
就是交并比,衡量bounding-box和ground Truth的重合程度。

2.TP、TN、FP、FN
True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
在目标检测中:
TP:预选框检测检测正确,即IoU>=0.5的预选框
FP:预选框检测检测错误,即IoU<0.5的预选框
FN:未被检测到的ground Truth
TN:不使用。这将代表纠正错误检测。在目标检测任务中,有许多可能的边界框在图像中不应被检测到。因此,TN将是所有可能未被检测到的边界框(图像中有如此多的可能框),这就是指标不使用它的原因。
3.Precision&Recall
两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式:

精度 :![]()
召回率:![]()
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率:

4.Precision-Recall curve
根据预测的结果对样例进行排序,本文使用置信度confidence作为预测结果,排在前面的是模型认为”最可能“是正例的样本,排在最后的则是模型认为”最不可能”是正例的样本。按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的精度和召回率。以精度为纵轴,以召回率为横轴,就可以获得“P-R曲线”。
P-R曲线是评估对象检测器性能的好方法,因为通过绘制每个对象类的曲线可以改变置信度。如果一个特定类别的物体探测器的精度随着召回的增加而保持高水平,则被认为是好的,这意味着如果改变置信度阈值,精度和召回率仍然很高。
5.Average Precision
mAP是为解决P,R,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线:

可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。
从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。
更加具体的,曲线与坐标轴之间的面积应当越大。
最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP其规范的定义如下:(其中P,R分别为准确率与召回率)
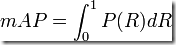 即map实质上指的是pr曲线下的围成的面积大小。
即map实质上指的是pr曲线下的围成的面积大小。
AP是在0和1之间的所有召回值的平均精度。就是P-R曲线的曲线下面积。
由于曲线难以计算,所以我们采用11点插值法来求得,2012年后采用8点对应的Percision最大值,求取曲线面积即为AP值。
11点插值试图通过平均一组11个等间距召回级别[0,0.1,0.2,...,1]的精度来总结Precision x Recall曲线的形状:

其中:![]() 就是Percision对应点的最大值。
就是Percision对应点的最大值。
面积计算方法见下文。
选择mAP原因:

按置信度从大到小的顺序逐个把样本作为整理进行预测,则每次可以计算出当前的查全率、查准率。
以P(查准率)为纵轴,R(查全率)为横轴作图,就得到了P-R曲线P-R图直观的显示出学习器在样本总体上的查全率、查准率。
在进行比较时,若一个学习器的P-R曲线被另一个完全包住,则可断言后者优于前者,如上图,A优于C;
如果两个学习器的P-R曲线发生了交叉,如A和B,则难以一般性的断言两者孰优孰劣,只能在具体的P或R条件下进行比较。然而,在很多情形下,人们往往仍希望把学习器A和B比个高低,这时一个比较合理的判断依据是比较曲线下面积的大小,它在一定程度上表征了学习器在P和R上取得相对“双高”的比例。
mAP计算

有7个图像,其中15个ground-Truth由绿色边界框表示,24个预选框由红色边界框表示。每个检测到的对象都具有置信水平,并由字母(A,B,...,Y)标识。
1.计算出bounding-box与ground-Truth的IoU的值,利用阈值把预选框分为TP&FP
如果IOU>=30%,则考虑TP ,否则为FP。在一些图像中,存在多于一个与地面实况重叠的检测(图像2,3,4,5,6和7)。对于这些情况,采用具有最高IOU的检测,丢弃其他检测。“例如,单个对象的5个检测(TP)被计为1个正确检测和4个错误检测。

2.计算累计精度和召回率
这里:按置信度的从小到大,逐个把样本作为正例进行预测,则每次可以计算出当前的精度和召回率。
ground-Truth=15

3.绘制P-R曲线图
可以发现随着选定的样本越多,召回率一定会越高,而精度则呈下降趋势。如果一个特定类别的物体探测器的精度随着召回的增加而保持高水平,则被认为是好的。

4.计算AP值
11点插值平均精度的想法是在一组11个召回级别(0,0.1,...,1)处平均精度。插值精度值是通过采用其召回值大于其当前调用值的最大精度获得的,如下所示。即Recall=[0,0.1,0.2,...,0.9,1]的11处Percision的最大值:[1,0.6666,0.4285,0.4285,0.4285,0,0,0,0,0,0]。


面积法:
平均精度(AP)可以解释为P-R曲线的近似AUC(面积)。
Recall=[0,0.0666,0.1333,0.2,0.2666,0.3333,0.4,0.4666],选取Percision对应点的最大值:[1,1,0.6666,0.4285,0.4285,0.4285,0.4285,0.3043],然后求曲线的面积。

看一下上图,我们可以将AUC划分为4个区域(A1,A2,A3和A4):

计算总面积,我们有AP:

5.计算mAP
AP衡量的是对一个类检测好坏,mAP就是对多个类的检测好坏。就是简单粗暴的把所有类的AP值取平均就好了。比如有两类,类A的AP值是0.5,类B的AP值是0.3,那么mAP=(0.5+0.3)/2=0.4
总结:
1.根据IOU计算TP、FP
2.按照置信度大小进行排序
3.在不同置信度阈值下获得Precision和Recall,也就是通过累计TP和FP计算精度和召回率
4.绘制P-R曲线并计算AP值
5.计算mAP值















 2897
2897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









