







获取基金排行数据(Python)
目录
一、分析网站
1. 确定要获取的数据
# URL
https://fund.eastmoney.com/
点击<基金排行>

此页数据是要获取的
2. 确定数据来源
打开网页开发者工具
# 快捷键
F12 或 Ctrl + Shift + i
点击 < Network >
这里将看到数据的来源
刷新网页
# 快捷键
F5
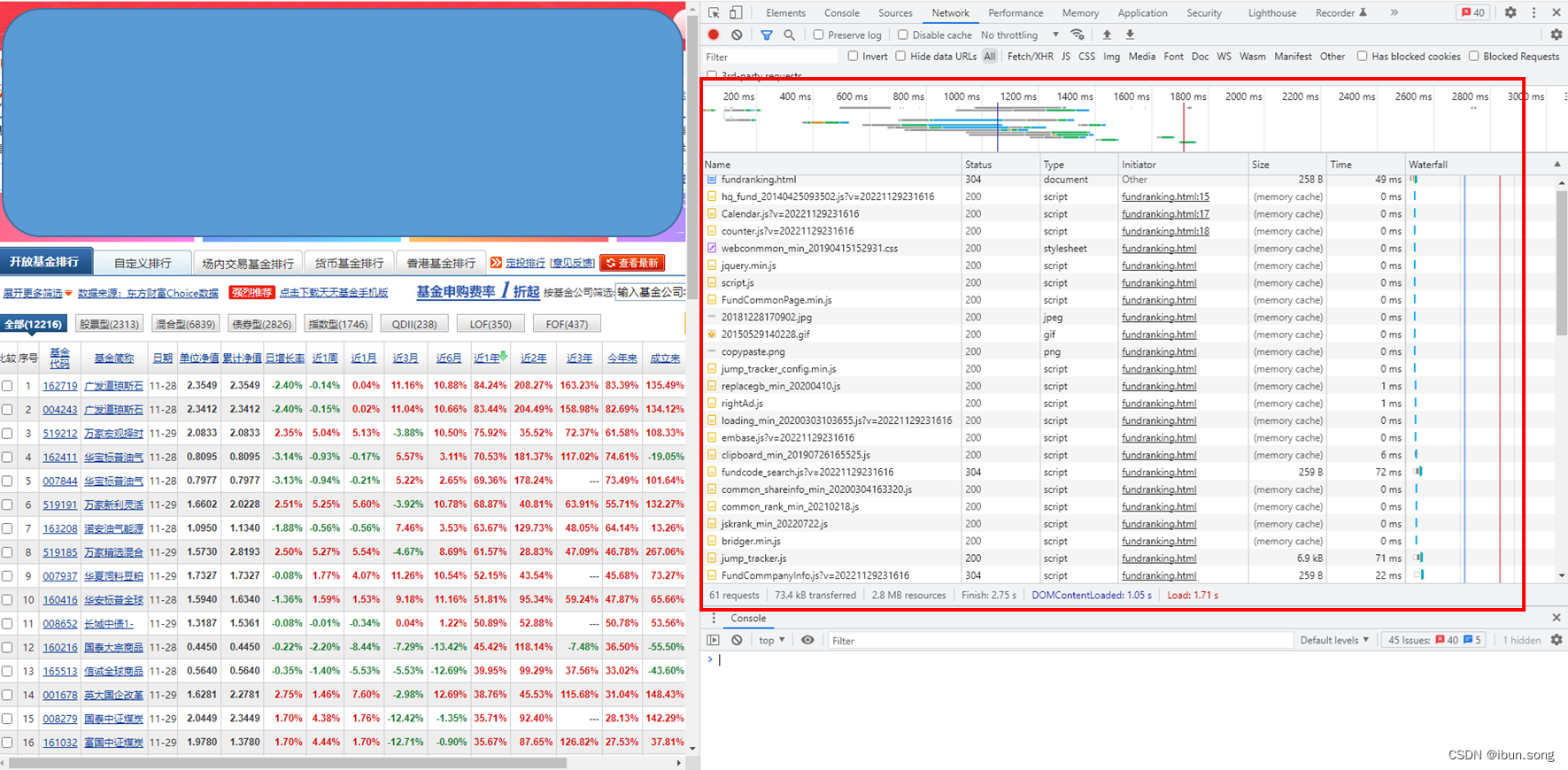
这里可以看到刷新网页后,获取到的网络资源
多而杂,无法找到我们想要的数据的api
利用网页的分页功能筛选网络资源
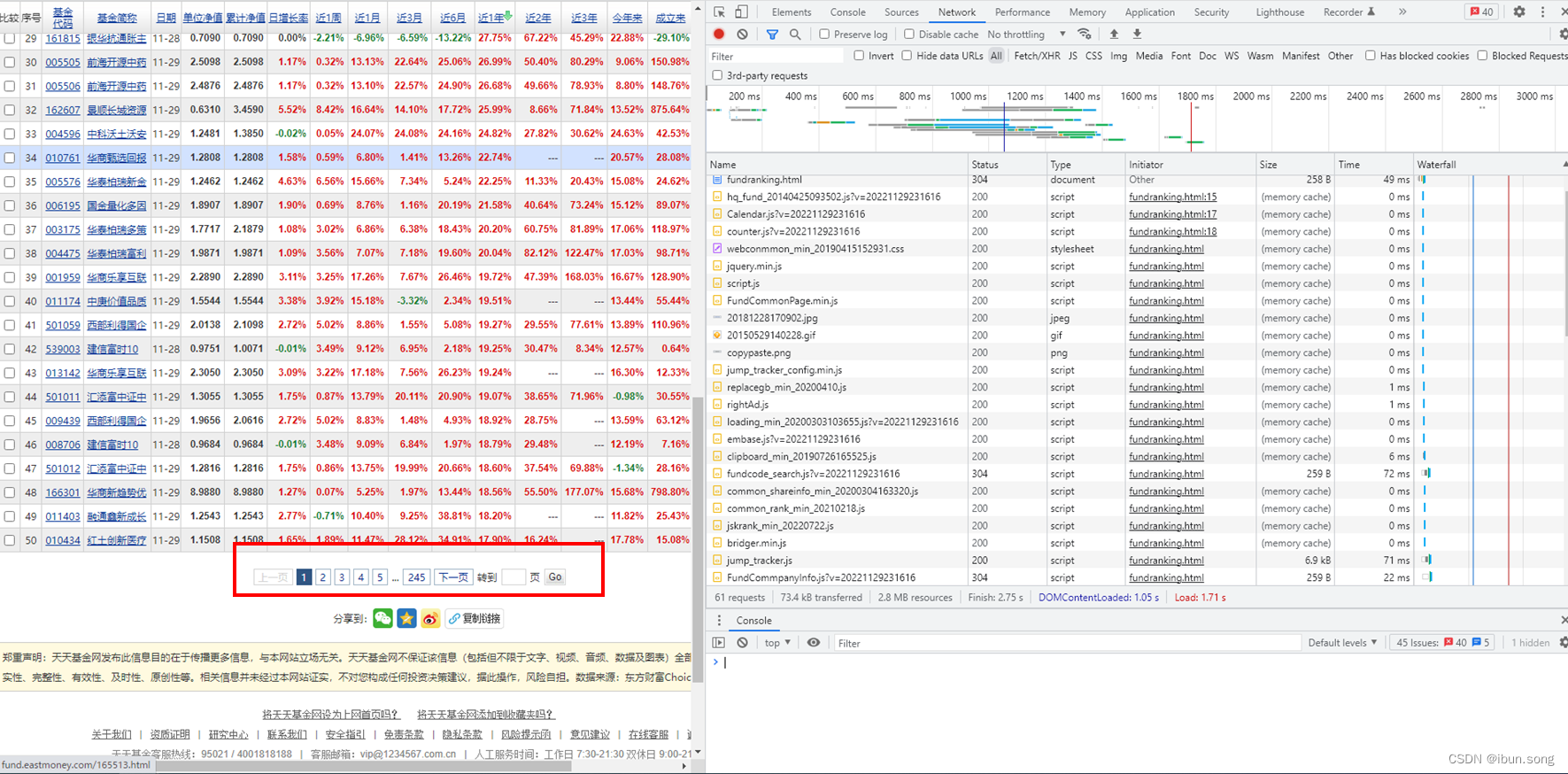
关闭开发者工具并重新打开
# 快捷键
F12 F12
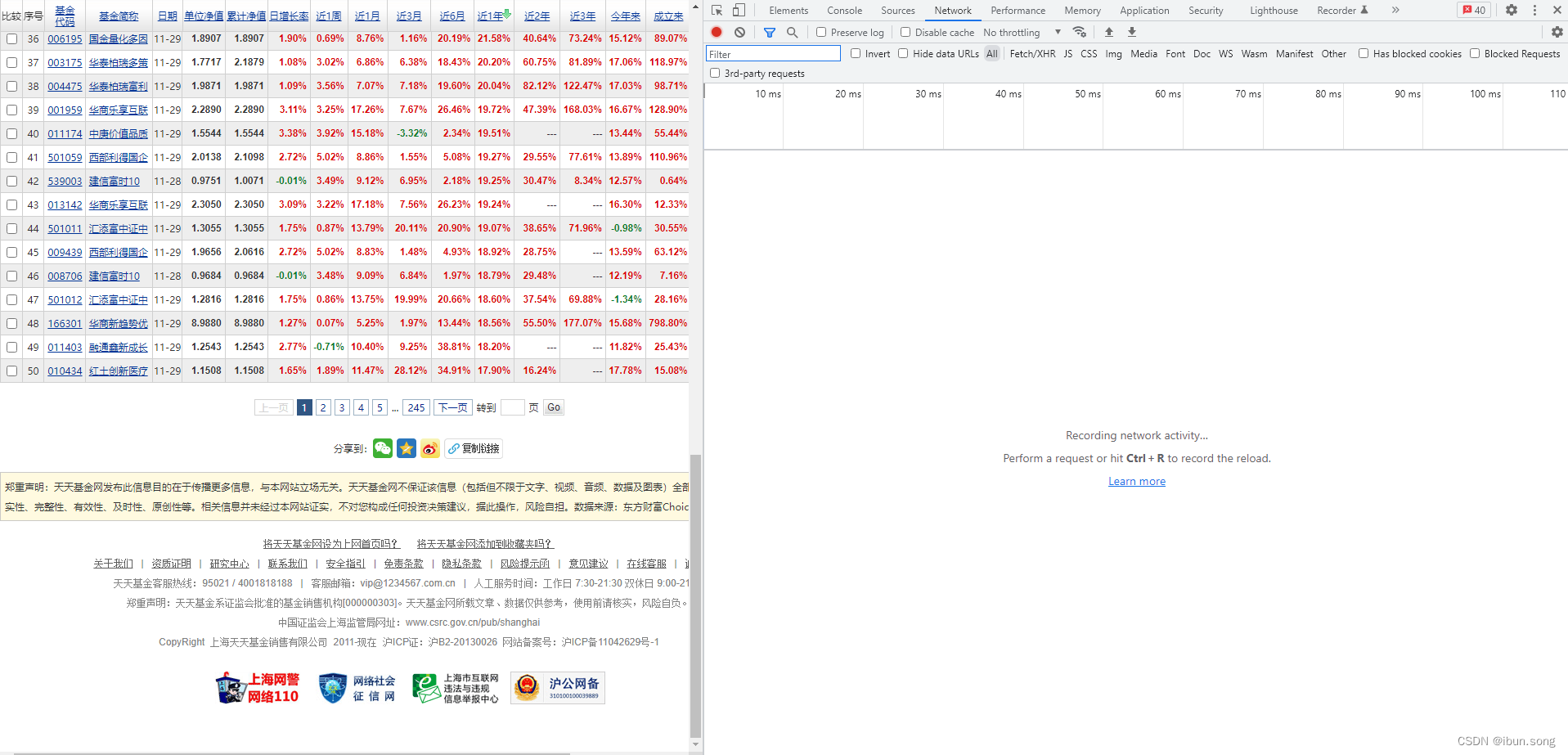
Network部分是空白的
点击 < 2 >
打开第二页数据

这个是数据来源的api
点击查看详细信息
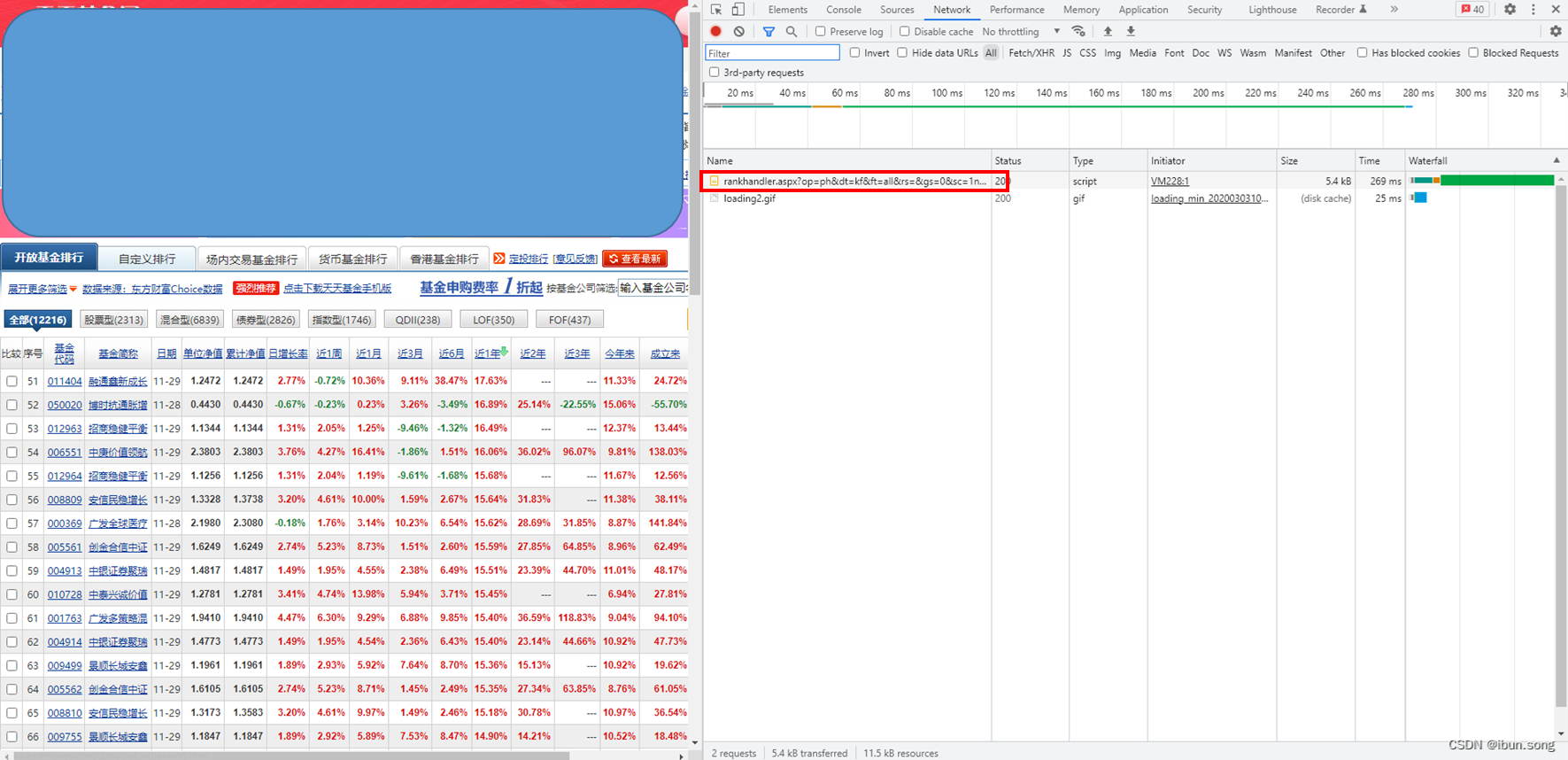
可以看到有我们需要的请求数据的URL和请求方式
还有请求头部
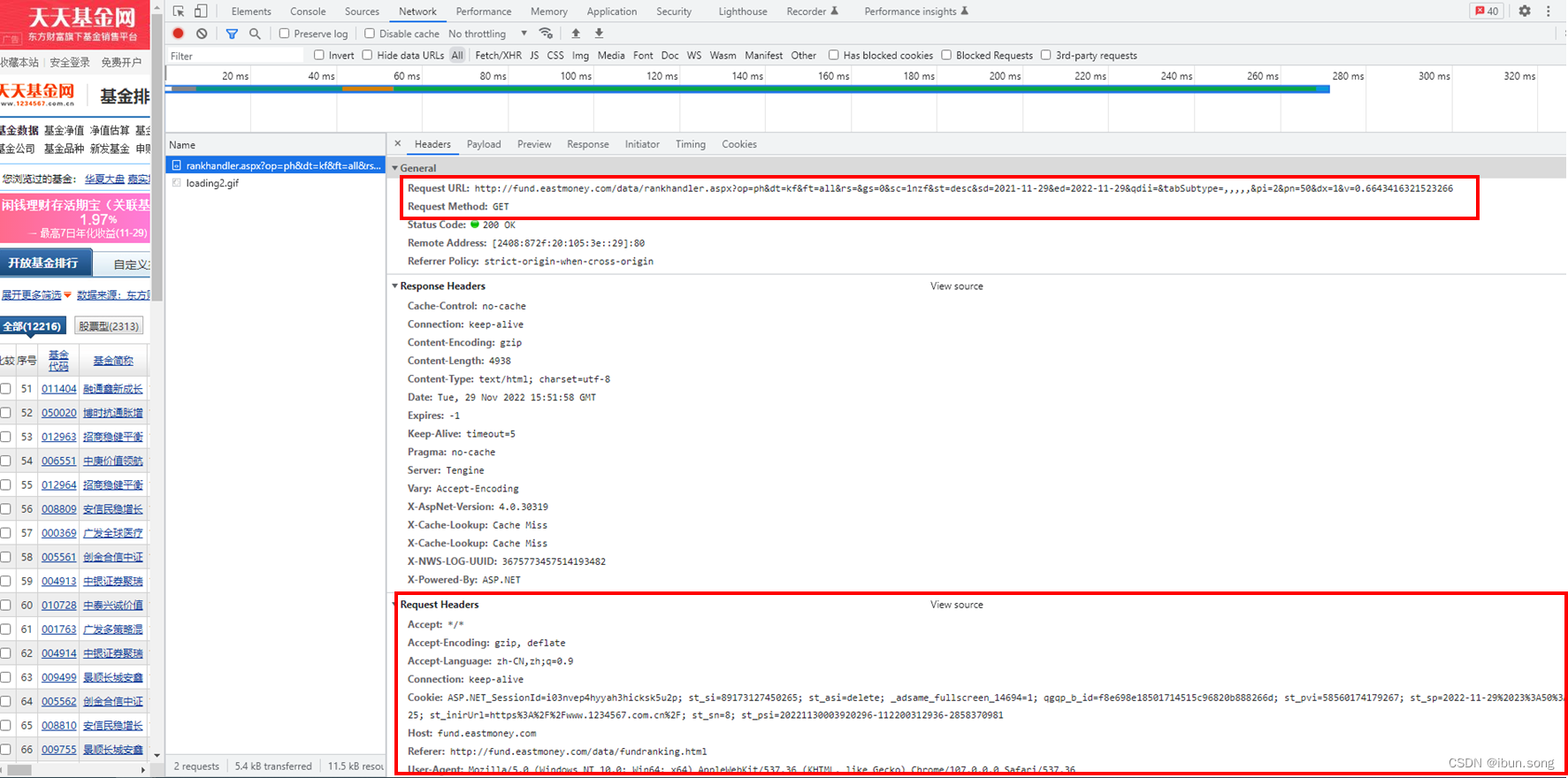
得到数据来源
Request URL: http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=1nzf&st=desc&sd=2021-11-29&ed=2022-11-29&qdii=&tabSubtype=,,,,,&pi=2&pn=50&dx=1&v=0.6643416321523266
Request Method: GET
Accept: */*
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
Cookie: ASP.NET_SessionId=i03nvep4hyyah3hicksk5u2p; st_si=89173127450265; st_asi=delete; _adsame_fullscreen_14694=1; qgqp_b_id=f8e698e18501714515c96820b888266d; st_pvi=58560174179267; st_sp=2022-11-29%2023%3A50%3A25; st_inirUrl=https%3A%2F%2Fwww.1234567.com.cn%2F; st_sn=8; st_psi=20221130003920296-112200312936-2858370981
Host: fund.eastmoney.com
Referer: http://fund.eastmoney.com/data/fundranking.html
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36
因为数据是分页的,还需要知道其他页数据的获取方式
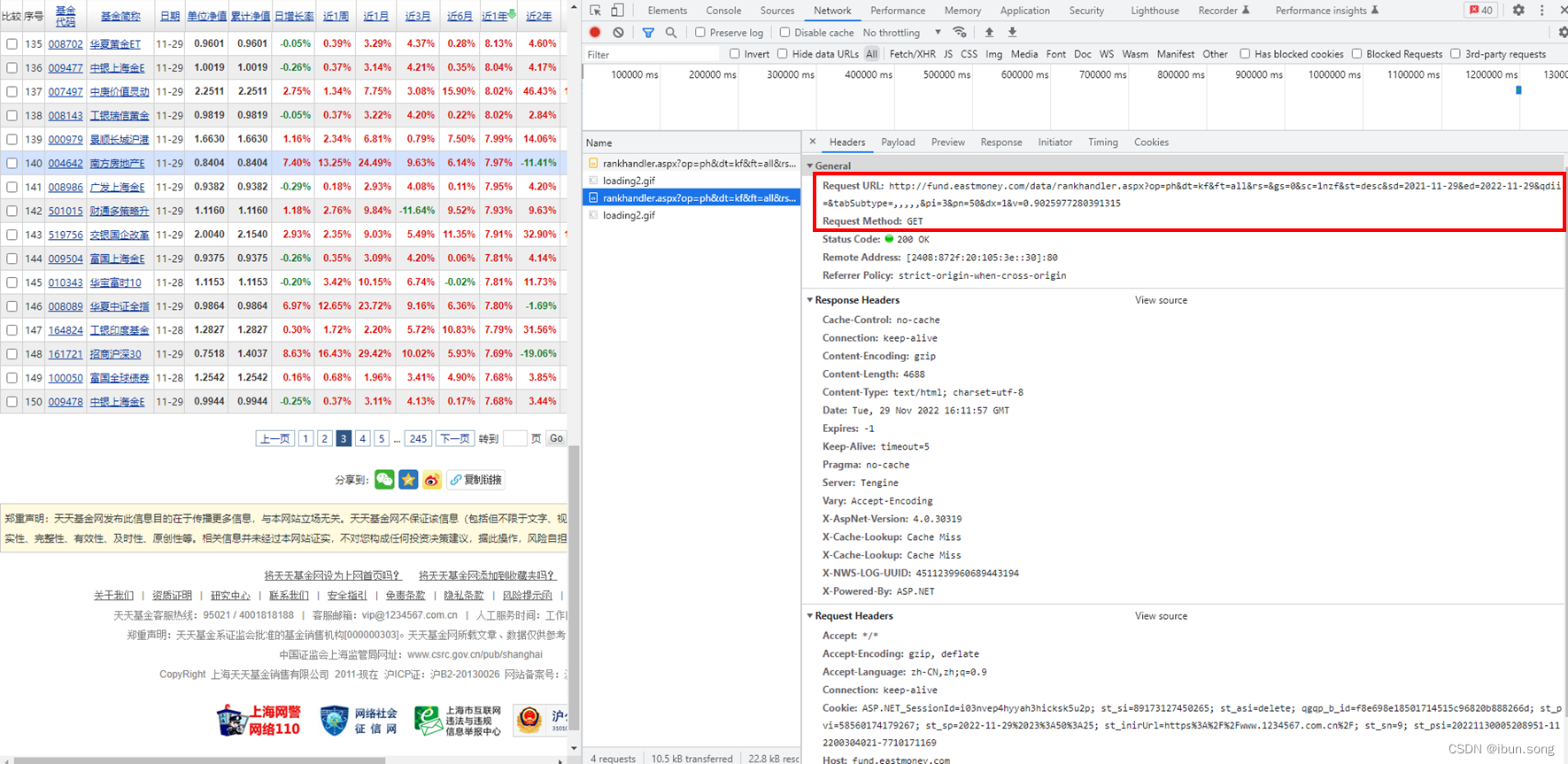
点击< 3 >
# 文本在线比较
https://www.osgeo.cn/app/sb134
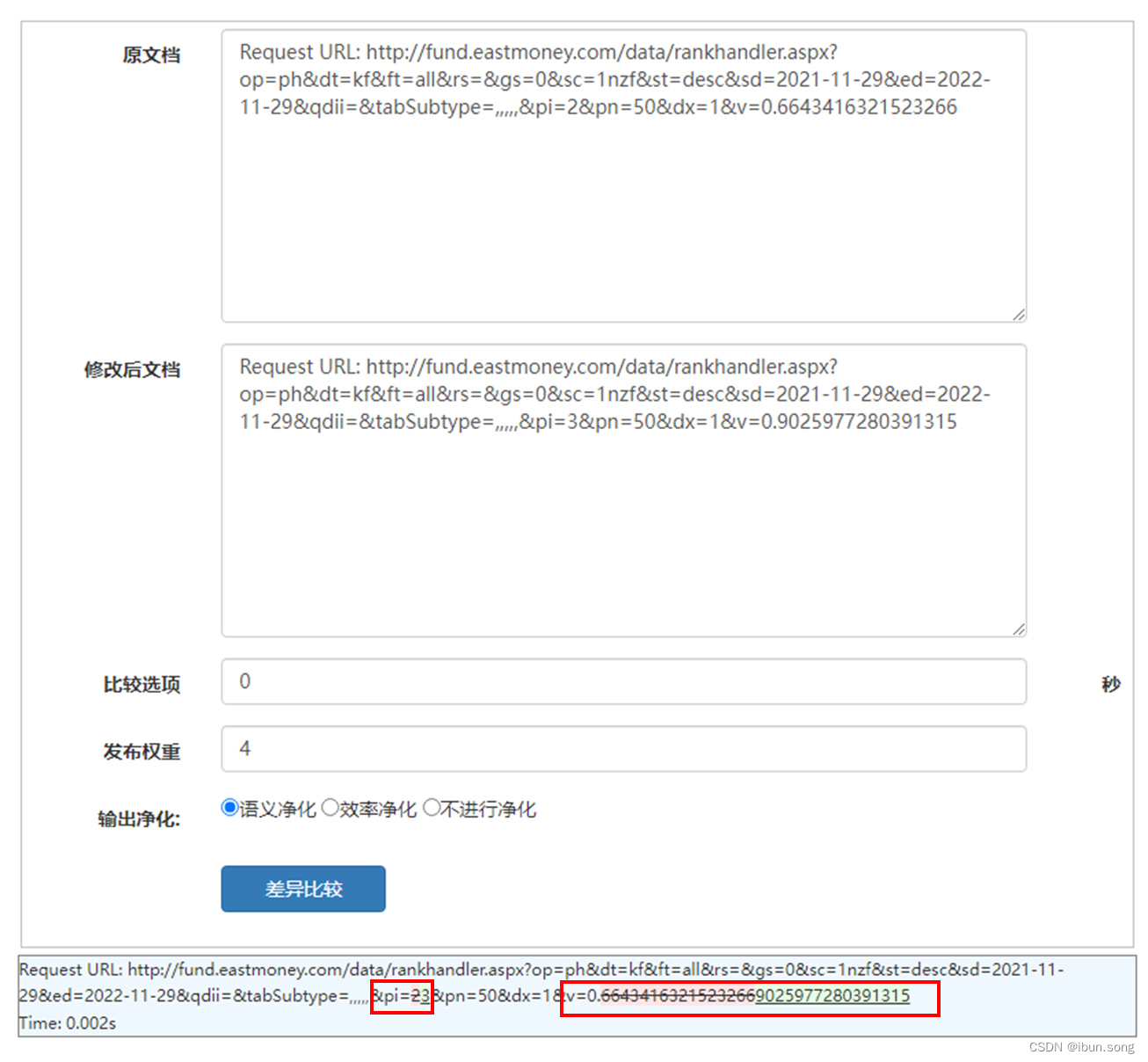
可以看到url中有两个参数的值不一样 pi 和 v
v参数可以忽略
pi的值 第2页是2, 第3页是3
确定请求多页数据的api
# {page} 是个参数,代表第page页数据
http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=1nzf&st=desc&sd=2021-11-29&ed=2022-11-29&qdii=&tabSubtype=,,,,,&pi={page}&pn=50&dx=1
3. 示例代码
"""
[课 题]: Python爬取天天基金股票信息
[知识点]:
requests发送请求
开发者工具的使用
json类型数据解析
正则表达式的使用
[模块安装]: 按住键盘 win + r, 输入cmd回车 打开命令行窗口, 在里面输入 pip install 模块名
或 打开终端 输入命令: pip install 模块名
eg: pip install requests
[开发环境]:
版 本:python 3.9
编辑器:pycharm 2022.1.4
"""
import requests # 发送请求 第三模块
import re
import csv
# 伪装: 请求头
# re 替换
# 1. 选中我们要替换内容
# 2. 按住键盘 ctrl + r
# 3. 在第一个框中 填写 (.*?): (.*)
# 4. 在第二个框中 填写 "$1": "$2",
# 5. 点亮星星 全部替换
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Cookie": "ASP.NET_SessionId=i03nvep4hyyah3hicksk5u2p; st_si=89173127450265; st_asi=delete; _adsame_fullscreen_14694=1; qgqp_b_id=f8e698e18501714515c96820b888266d; st_pvi=58560174179267; st_sp=2022-11-29%2023%3A50%3A25; st_inirUrl=https%3A%2F%2Fwww.1234567.com.cn%2F; st_sn=8; st_psi=20221130003920296-112200312936-2858370981",
"Host": "fund.eastmoney.com",
"Referer": "http://fund.eastmoney.com/data/fundranking.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36}"
}
# 爬取1~5页的数据
for page in range(1, 6):
print(f'-------------------------正在爬取第{page}页内容-----------------------')
# 后台实现接口逻辑有问题可能会导致我们爬取数据有很多重复值
url = f'http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=1nzf&st=desc&sd=2021-11-29&ed=2022-11-29&qdii=&tabSubtype=,,,,,&pi={page}&pn=50&dx=1'
# 1. 发送请求
# <Response [200]>: 发送请求成功结果
response = requests.get(url=url, headers=headers)
# 2. 获取数据
data = response.text
# 3. 解析数据 筛选数据 re
# 第一个是我们正则表达式语法 第二个就是我们需要在哪里匹配
data_str = re.findall('\[(.*?)\]', data)[0]
# 4. 保存数据
# 表格当中
# 数据转型
# 列表 元组
# eval 可以帮助我们把字符串转变为 列表/字典/元组/整数类型/boolean/浮点类型...
tuple_data = eval(data_str)
for td in tuple_data:
# 把td 变成列表
td_list = td.split(',')
# 4. 保存数据到 data.csv 中, 会在当前文件夹下自动新建data.csv,mode='a'属性决定如果文件存在则继续写入数据
with open('data.csv', mode='a', encoding='utf-8', newline='') as f:
csv_write = csv.writer(f)
csv_write.writerow(td_list)
print(td)
4. 执行结果
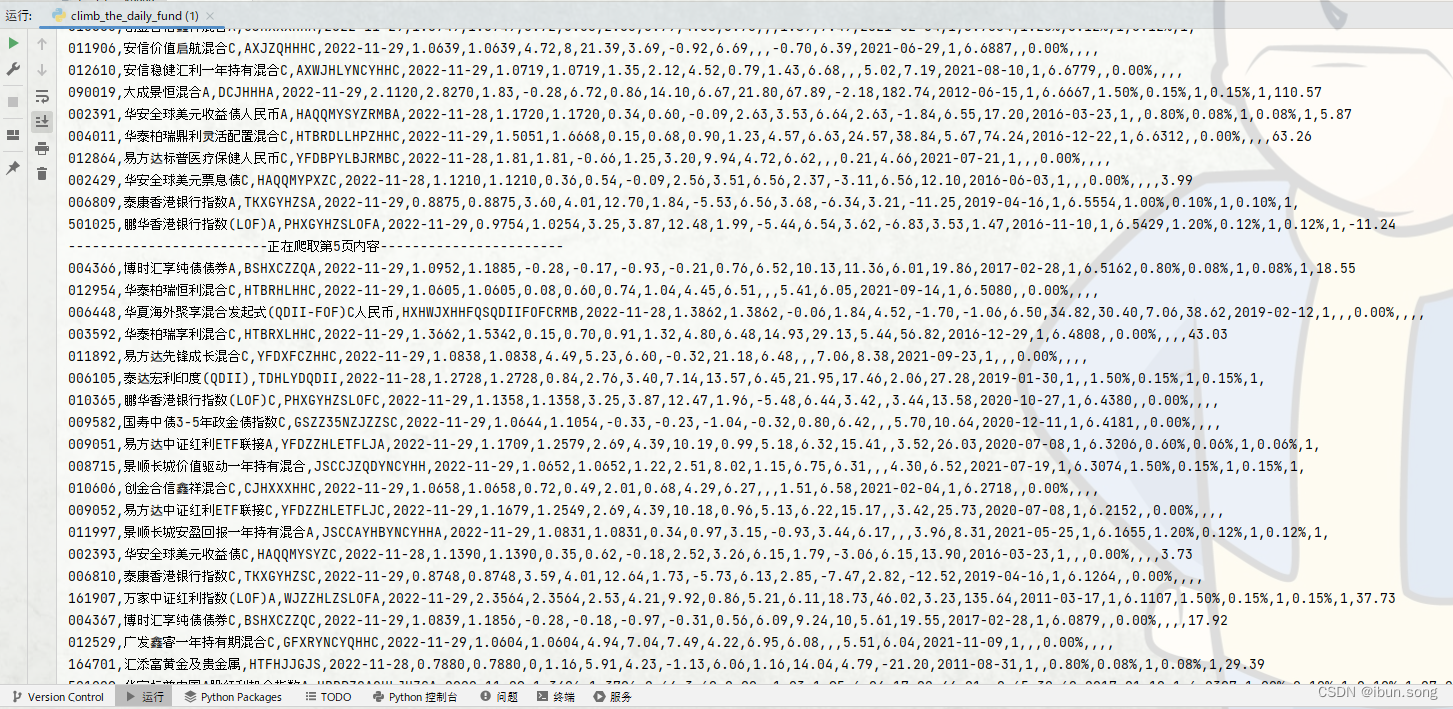
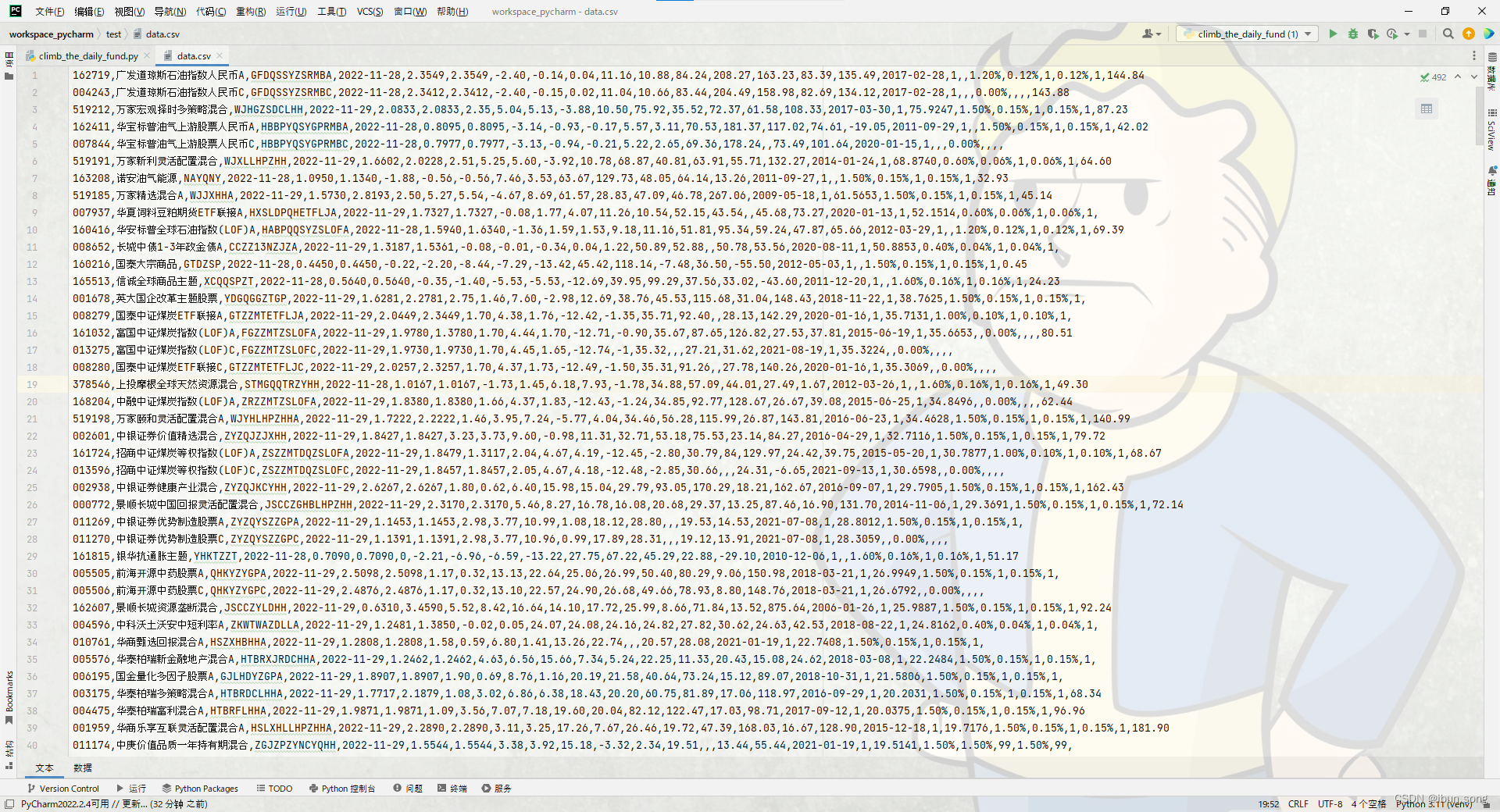
















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











