







 本文介绍如何通过Scrapy爬虫框架从天天基金网站抓取开放式基金的基础信息,包括代码、名称、手续费等,并分享了定位接口、数据解析和CSV存储过程。
本文介绍如何通过Scrapy爬虫框架从天天基金网站抓取开放式基金的基础信息,包括代码、名称、手续费等,并分享了定位接口、数据解析和CSV存储过程。
最近周围朋友很多都在研究基金,或者想买入,或者想通过综合研究基金的重仓股来指导其在股市的行为,暂且搁置这些投资指导方式是否正确和稳妥,笔者便趁着周末给写了个小爬虫,将基金相关数据爬取下来并存储到了本地MYSQL,便于后续使用,虽然很多开放数据平台(如AKShare、Tushare等)也已经提供现成接口直接拉取基金相关数据,但毕竟不是按照自己思路整理的,使用起来非常不便,尤其是Tushare,想使用一些高价值的数据,还必须要求积分额,于是乎,笔者自己亲自动手,用scrapy写个小爬虫,爬下来数据供自己和朋友后续使用。
本文章使用scrapy爬虫框架,不会在文章中介绍scrapy基础知识,如果不会可以自行学习,不过笔者会提供源码,后续只要知道如何创建scrapy项目,便可运行起来
本文内代码示例只展示如何通过天天基金爬取基金基本数据(code、名称、手续费等),其他延伸关联数据(重仓股、持股行业等等),可以自行分析天天基金网页结构和接口请求,毕竟是同一个网站,根本的处理逻辑是一致的。
另,本文爬取的数据,仅供个人用途使用,如想做其他用途,请三思。
一、准备工作
1.1 分析网站
首选分析下网站结构,主要看下该网站是否可以满足自己的数据需求(即数据是否足够全面),然后看下感兴趣的数据,在哪个页面能较为快捷的获取(一般是搜索、排行、信息列表页等),最后定位到具体网页后,看下该网页如何获取数据,是通过xpath+re即可提取,还是可能通过js代码加载的,需要通过某接口获取。
笔者通过以下路径,找到了每日开放基金列表页,该页面最适合进行数据抓取
天天基金首页→基金数据(更多)→开放式基金(更多),到达每日开放基金列表页,页面如下:
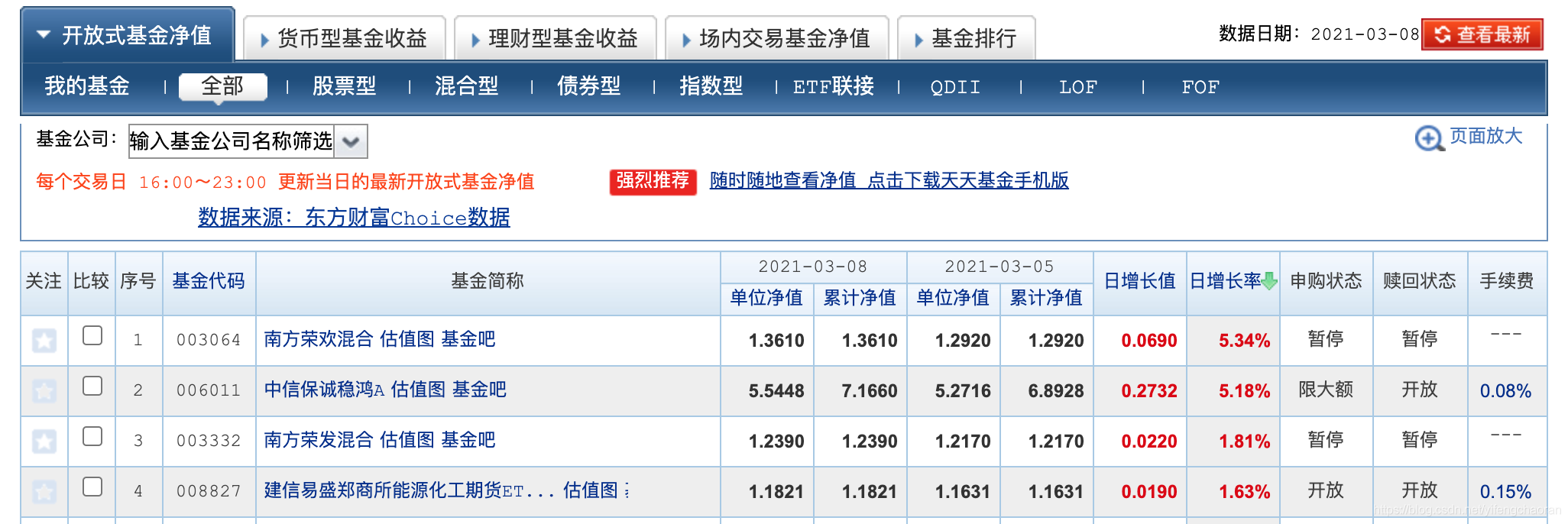
笔者只对开放式基金比较感兴趣,所以只抓取开放式基金数据,可以看到,该页面已经基本涵盖了感兴趣的数据,可以点击某基金,进入该基金的基金详情页(http://fund.eastmoney.com/008732.html):

可以发现,基金详情页是通过固定ulr和基金代码拼接而成,所以,只要获取到基金代码,便可以获取到基金详情页数据,在基金详情页内,又发现了该基金的成立时间、所属基金公司信息,这些信息可以直接通过xpath提取。
当然详情页还包含该基金的持股信息,笔者此处不会演示抓取持股信息,如感兴趣,可以自行抓取。
进一步分析列表页,该页面是分页加载,并且下一页的链接不是和其他网站一样,在next按钮或页数按钮内,而是动态加载的,所以该页面不用考虑使用xpath和re提取,只能去分析接口。
我们移步至定位接口
1.2 定位接口
打开chrome开发工具,network,js,点击下一页时,发现页面请求了一个接口,该接口返回了基金列表相关数据,如下:

比对下该接口返回的数据,与列表页内的数据完全一致,完美,笔者最喜欢使用接口提取数据,因为开发人员已经贴心的帮我们整理好了数据。
该接口为get方式,可以通过Header查看接口地址和需携带的params,笔者通过postman尝试并简化了该接口请求,如下:
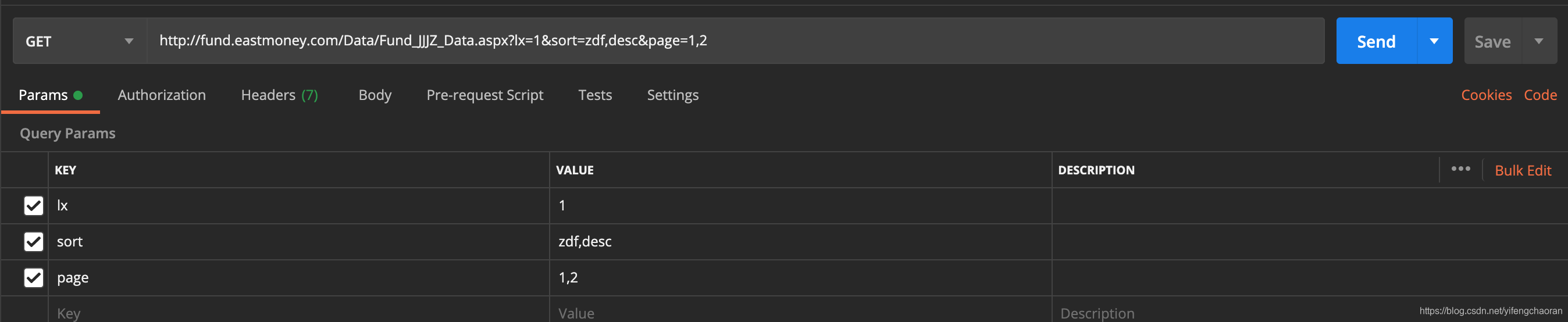
接口地址为:http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx
接口需携带参数为lx、sort、page,其中page参数,代表第几页,以及该页请求的数据记录数量,后续可以通过改变这两个参数,自动实现翻页,为了不被网站发现,每页数量最好设置成和默认的一样,此处为200
但是详细看下接口返回的数据格式,会发现并不是我们最爱的json格式,而是一段js代码,在该代码内定义了db并将我们想要的数据赋值给了它,不怕,在下面具体写爬虫时,会介绍如何将这类数据转换成字典并直接使用。
1.3 创建scrapy项目
好了,页面和接口已经定位到,笔者创建一个fund项目,并创建一个basic爬虫,用来爬取基金的基本信息
#以下命令在终端内运行
scrapy startproject fund
cd fund
scrapy genspider basic fund.eastmoney.com好了,到此,所有前期分析准备工作,已经做完,接下来开始愉快的撸代码了。
二、项目代码敲起来
2.1 先写item
笔者首先爬取的是基金相关的基础数据,包括基金名称、代码、申购和赎回状态、手续费、类型、所属基金公司名称、所属基金公司编码、成立时间等信息,有了这些,便可以延伸性的爬取各个基金的详细信息了(天天基金的基金详情页是通过基金代码拼接而成),所以先在items文件内,创建好自己想要的item。
import scrapy
class FundItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
num=scrapy.Field()
code=scrapy.Field()
name=scrapy.Field()
fund_type=scrapy.Field()
shengou_status=scrapy.Field()
shuhui_status=scrapy.Field()
rate=scrapy.Field()
fund_time=scrapy.Field()
company_id=scrapy.Field()
company_name=scrapy.Field()
- 以上定义了笔者感兴趣的关于某个基金的基础信息
- 当然如果读者还对其他信息感兴趣,也可以创建进去,然后在spider里面进行提取
2.2 再写spider
最为核心的地方来了,我们要用basic小爬虫,通过以上分析出来的接口,获取一部分基金数据,同时通过详情页,获取到其他数据。
import scrapy,js2py
from fund.items import FundItem
#定义一个函数,专门使用js2py运行js代码并提取里面的对象数据
def parse_jsobj(response):
data=js2py.eval_js(response.text)
return data
class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['fund.eastmoney.com']
#如果只定义了start_urls不重载自己的start_requests函数,则scrapy会自动使用start_urls列表发起请求,并回调parse函数
start_urls=[
'http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?t=1&lx=1&letter=&gsid=&text=&sort=zdf,desc&page=1,1&dt=1615024389598&atfc=&onlySale=0',
]
def parse(self,response):
data=parse_jsobj(response)
record_count=int(data['record'])
per_page=200
page_count=round(record_count/per_page)
#定义page参数,即列表页每页请求数据记录数量,还有当前请求页数,然后不断发起请求
for i in range(page_count):
url='http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?lx=1&sort=zdf,desc&page={},{}'.format(i+1,per_page)
yield scrapy.Request(url=url,callback=self.list_parse)
#处理列表页,提取一部分数据,并传入Request的meta数据内,便于在下一个parse函数内使用并组装
def list_parse(self,response):
funds=parse_jsobj(response)['datas']
base_url='http://fund.eastmoney.com/{}.html'
for fund in funds:
print(fund)
fund_info={}
fund_info['num']=fund[0]
fund_info['code']=fund[2]
fund_info['name']=fund[1]
fund_info['shengou_status']=fund[9]
fund_info['shuhui_status']=fund[10]
fund_info['rate']='' if len(fund[18])==0 else float(fund[18].replace('%',''))
url=base_url.format(fund_info['num'])
yield scrapy.Request(url=url,callback=self.detail_parse,meta=fund_info)
#提取详情页数据,并通过Request.meta接受上一步处理的数据,最终组成成一个item
def detail_parse(self,response):
fund_info=response.meta
item=FundItem()
item['num']=fund_info['num']
item['code']=fund_info['code']
item['name']=fund_info['name']
td_selec=response.xpath("//div[@class='infoOfFund']//td")
item['fund_type']=td_selec[0].xpath("a/text()").get()
item['shengou_status']=fund_info['shengou_status']
item['shuhui_status']=fund_info['shuhui_status']
item['rate']=fund_info['rate']
item['fund_time']=td_selec[3].xpath('text()').get().replace(':','')
item['company_id']=td_selec[4].xpath('a/@href').re('company/(.+).html')[0]
item['company_name']=td_selec[4].xpath('a/text()').get()
#以上代码也可以使用ItemLoader来简化语法
# loader=ItemLoader(item=FundItem(),response=response)
# loader.('num','xpath')
yield item
- 以上,主要是先通过parse函数,提取出每页列表页数据的接口请求地址,生成对应Request并扔给调度器,调度器下载完毕数据后(接口返回数据),会调用list_parse进行列表页数据提取
- 然后通过list_parse提取出来一部分数据,传给Request的meta,供下一个parse使用,同时产生对基金详情页的请求,并回调detail_parse函数
- detail_parse会对详情页进行xpath提取,提取出来基金其他信息,并与再list_parse内提取的数据组装成item,然后扔出去,调度器会自动扔给我们下面要写的pipelines进行加工处理。
- 一般情况下,一个parse函数会yield出两个东西给到scrapy调度器,或者是item或者是Request,调度器会将item扔给pipelines,Request扔给下载器,下载器下载后,回调对应parse函数,反复循环
- parse函数都需要使用yield返回数据,即所有parse函数都是一个Python生成器,这样处理在于不会因为url队列太大,占用太多内存空间,甚至造成内存溢出。
- 其中,parse_jsobj函数,是使用js2py库,在Python中运行js脚本,并返回对应运行结果,该函数即直接提取接口返回的js代码,并转化为python字典,供后续使用。js2py详细介绍,异步到《python运行js代码解决方案之js2py库》
2.3 再搞pipelines
pipelines主要是用来接收scrapy调度引擎扔过来的item,也即spider提取出来的item,一般是对item进行进一步清洗保存,为了减少数据存储的延迟及撸代码的数量,本文是先把数据保存到本地的csv文件内,然后再手动导入MYSQL
from itemadapter import ItemAdapter
from fund.spiders.basic import BasicSpider
class FundPipeline:
title=False
count=0
def __init__(self):
#记得将下面的filepath替换为自己的文件地址
self.f=open(filepath,'a+')
if not self.__class__.title:
self.f.write('num,code,name,fund_type,shengou_status,shuhui_status,rate,fund_time,company_id,company_name\n')
self.__class__.title=True
def process_item(self, item, spider):
if isinstance(spider,BasicSpider):
data_str='{},{},{},{},{},{},{},{},{},{}\n'
data_str=data_str.format(item['num'],item['code'],item['name'],item['fund_type'],item['shengou_status'],item['shuhui_status'],item['rate'],item['fund_time'],item['company_id'],item['company_name'])
self.f.write(data_str)
FundPipeline.count+=1
return item
def close_spider(self,spider):
print('共记录{}个item'.format(FundPipeline.count))
self.f.close()- 因为fund项目后续不仅包含basic爬虫,用来爬取基本信息,还有其他持股信息、基金公司信息等,所以此处的pipelines在处理item时(对应process_item),会判断下spider的类型,并针对性的做处理。
- 笔者此处只是做数据存储工作,因为前期的数据清洗已经在spider中完成了,当然,根据自己喜好,放到此处进行清洗也无妨。
- 笔者将爬取的数据存储到本地的csv文件,然后再将该文件导入MYSQL(尤其是爬取数据量很大的时候,为了避免因频繁写入数据库造成问题,一般会先存放到本地文件再导入数据库)
2.4 配置相关参数
最后,在运行爬虫之前,还需要对setting文件做一些配置修改,主要是设置下默认的UA(反爬)、header、爬取速度并开启我们的pipelines,具体如下:
#将下面的语句加入settings文件顶部
from faker import Faker
ua=Faker()
#更改默认配置项
USER_AGENT = ua.user_agent()
CONCURRENT_REQUESTS = 10 #同时发起的请求数量,设置的小点,反正时间足够
DOWNLOAD_DELAY = 0.5 #默认是0,设置个0.5秒,还是反爬,反正时间足够,如果着急,可以设置成比如0.1
#设置默认的请求头
DEFAULT_REQUEST_HEADERS ={
'Content-Type':'text/html; charset=utf-8',
'Host':'fund.eastmoney.com',
'Referer':'http://fund.eastmoney.com/fund.html',
}
#开启我们的pipelines
ITEM_PIPELINES = {
'fund.pipelines.FundPipeline': 300,
}三、运行并保存数据
3.1 运行并爬取
打开自己的终端,cd到fund项目根目录,然后使用scrapy crawl basic 运行爬虫
cd fund
scrapy crawl basic好了,此时应该会在终端窗口内看到scrapy已经启动并开始工作,并会把提取的每一个item打印出来,运行完毕之后,会告诉我们此次共发起多少请求,提取了多少个item。
3.2 保存处理至MYSQL
不再赘述,读者可以在自己电脑上安装个本地MYSQL,然后自行研究导入的方法。
四、写在最后
笔者总抓取了10400个基金数据,按照基金类型聚合,结果如下:
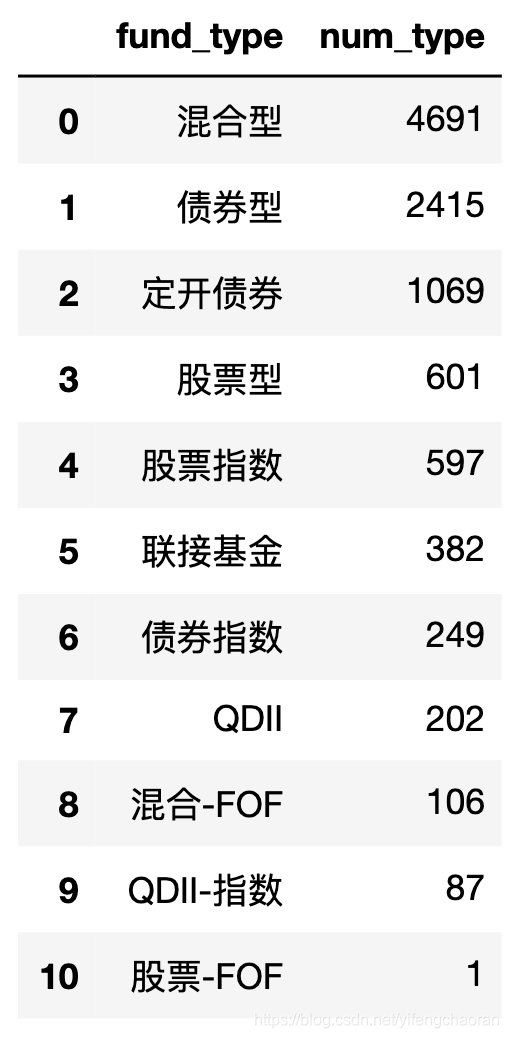
单纯从每种基金类型的基金数量来看,市场对基金的投资,还是偏中性,混合型和债券型占据了大半,其次是股票型。
所以,基民的投资倾向,还是比较温和的。
以上,笔者发现天天基金网站上所有数据,基本可以通过xpath或者接口+js2py组合提取出来,所以,可以按照自己的兴趣,基于以上数据,进一步提取比如主力基金(按照基金规模排序)都重仓了哪些股票,总持仓占某股票总市值百分比等,然后指导自己的选股策略,毕竟基金经理熬光了头,才选出这些股票。
最后,读者也可以将爬虫部署到自己的服务器,定时爬取更新,并追踪主力基金重仓股动向,如果有大量持仓或减仓某股票的倾向,便可以预判某股票的短期走势,当然只是构想,不作为严肃的投资策略建议,读者盈亏自负,后果自负。


















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









