







使用Kafka表引擎作为数据管道用途的示意图
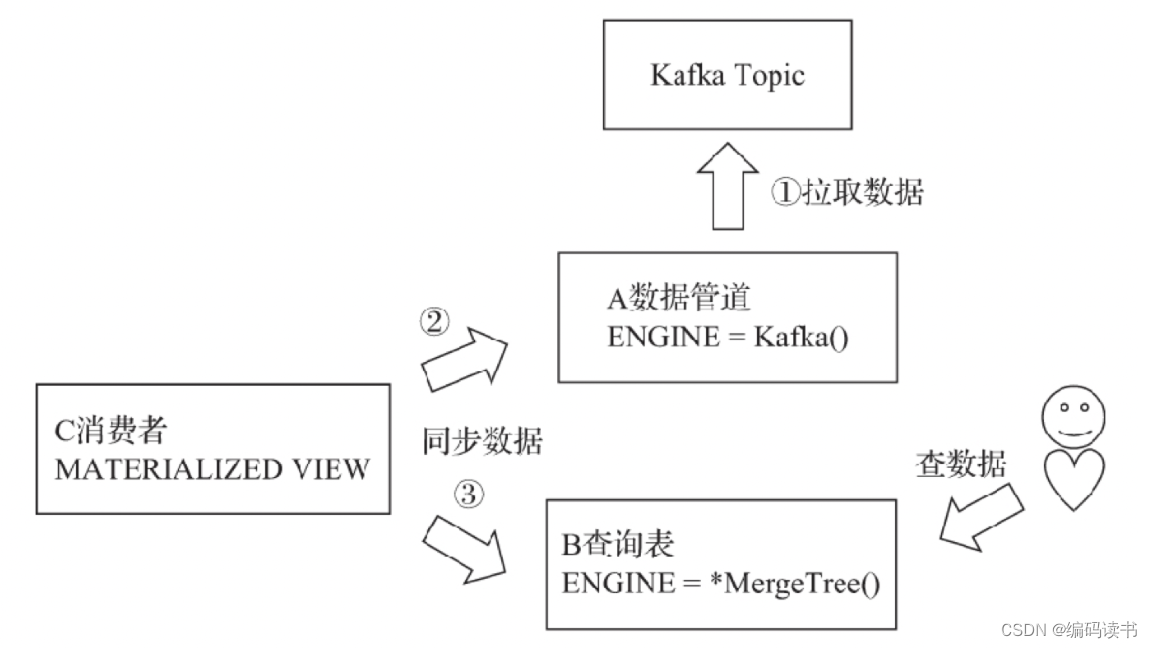
在上图中,整个拓扑分为三类角色:
- 首先是Kafka数据表A,它充当的角色是一条数据管道,负责拉取Kafka中的数据。
- 接着是另外一张任意引擎的数据表B,它充当的角色是面向终端用户的查询表,在生产环境中通常是MergeTree系列。
- 最后,是一张物化视图C,它负责将表A的数据实时同步到表B。
现在用一个示例演示使用方法
-
数据库规划
queue_beijing_bs --数据管道数据库 query_beijing_bs --终端用户的查询数据库 view_beijing_bs --同步数据物化视图库 -
创建数据库
create database queue_beijing_bs on cluster ck_cluster create database query_beijing_bs on cluster ck_cluster create database view_beijing_bs on cluster ck_cluster -
创建表
-
建Kafka引擎表
首先新建一张Kafka引擎的表,让其充当数据管道
CREATE TABLE queue_beijing_bs.kafka_queue on cluster ck_cluster( id String, name String, age String, date String )ENGINE = Kafka() SETTINGS kafka_broker_list = 'server01:9092,server02:9092,server03:9092',--Broker服务的地址列表 kafka_topic_list = 'WAYBILL',--订阅消息主题的名称列表 kafka_group_name = 'chgroup',--消费组的名称 kafka_format = 'JSONEachRow',--解析消息的数据格式 kafka_skip_broken_messages = 100 --表引擎按照预定格式解析数据出现错误时,允许跳过失败的数据行数 -
建本地查询表
新建一张面向终端用户的本地查询表,这里使用ReplicatedMergeTree表引擎
CREATE TABLE query_beijing_bs.waybill_local on cluster ck_cluster( id Int32, name String, age Int16, date date )ENGINE = ReplicatedMergeTree('/clickhouse/tables/{uuid}/waybill', '{replica}') PARTITION BY date ORDER BY id -
建分布式查询表
CREATE TABLE query_beijing_bs.waybill_all ON CLUSTER ck_cluster( id Int32, name String, age Int16, date date )ENGINE = Distributed( ck_cluster, --clickhouse集群名称 query_beijing_bs, --数据库 waybill_local,--表 rand() --分片键 ) -
建物化视图表
CREATE MATERIALIZED VIEW view_beijing_bs.waybill_kafka_consumer ON CLUSTER ck_cluster TO query_beijing_bs.waybill_all AS SELECT toInt32(id) id, name, toInt16(age), toDate(`date`) FROM queue_beijing_bs.kafka_queue
-















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









