







项目文件夹:
main_0HP.py、main_1HP.py、main_2HP.py和main_3HP.py是故障诊断主程序,分别对应不同负载的数据,这四个程序只有数据调取路径这行代码不一样,其它部分都相同,只是担心新手不会修改数据路径,因此分成了四个脚本。preprocess.py是数据预处理程序,将原始数据变成一个个样本,被主程序调用。
环境库要求:tensorflow>2.4.0即可运行
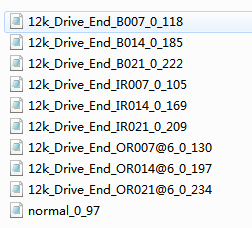
1.数据集介绍(凯斯西楚大学数据集,包含四种负载数据集)

以0hp为例进行展示,每种负载下包含10种类型(三种不同尺寸下的内圈/外圈/滚动体故障(3*3=9种),正常)
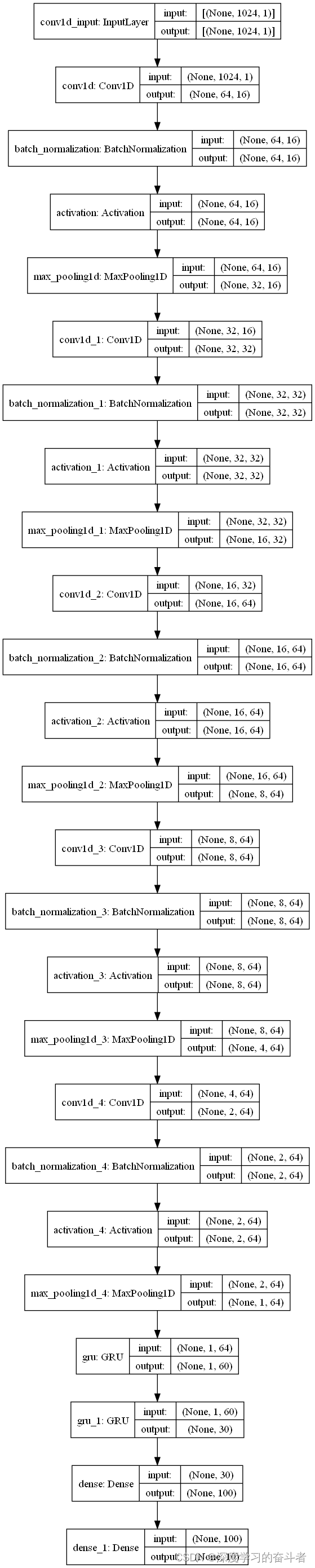
2.网络结构
3.效果图
每种负载下训练集、验证集与测试集个数均如下所示

0HP数据集
训练集准确率曲线
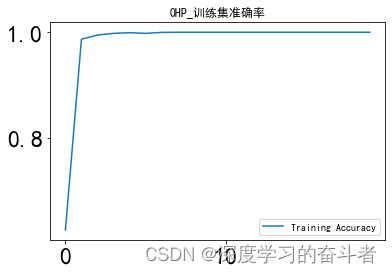
验证集准确率曲线
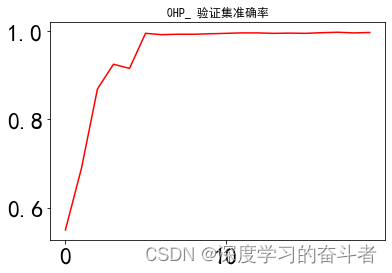
测试集准确率
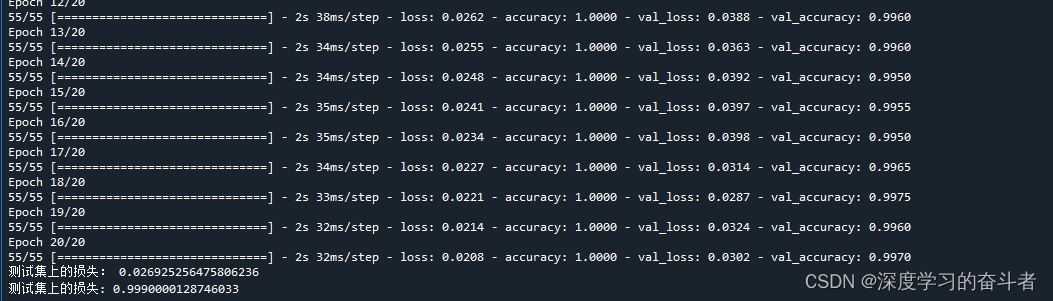
验证集的混淆矩阵
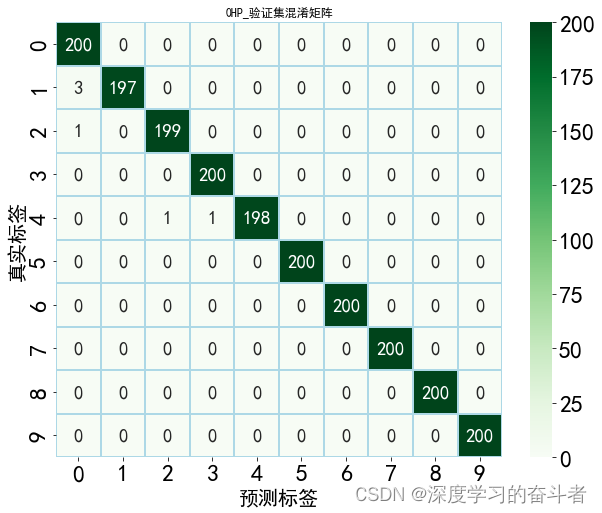
验证集的特征可视化
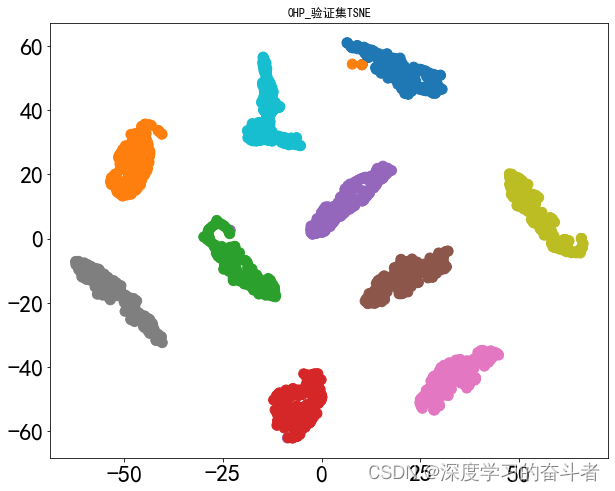
测试集的混淆矩阵

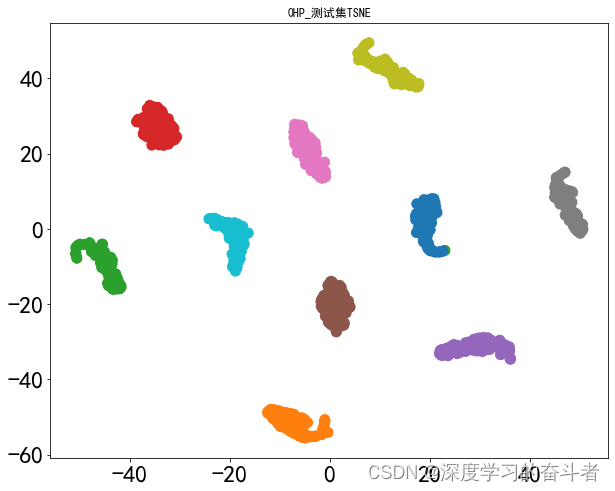
测试集的特征可视化
1HP数据集
训练集准确率曲线
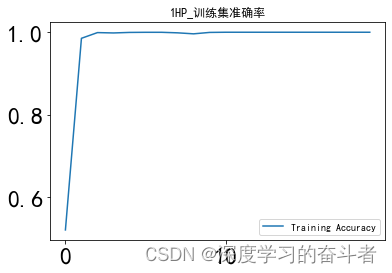
验证集准确率曲线
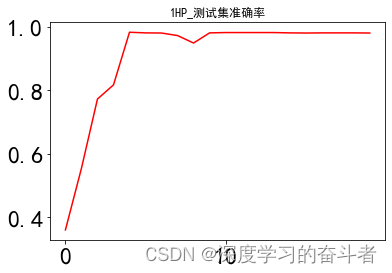
测试集准确率
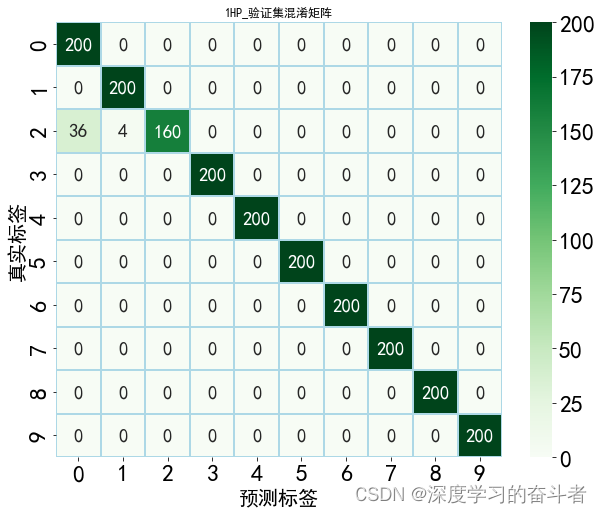
验证集的混淆矩阵
验证集的特征可视化
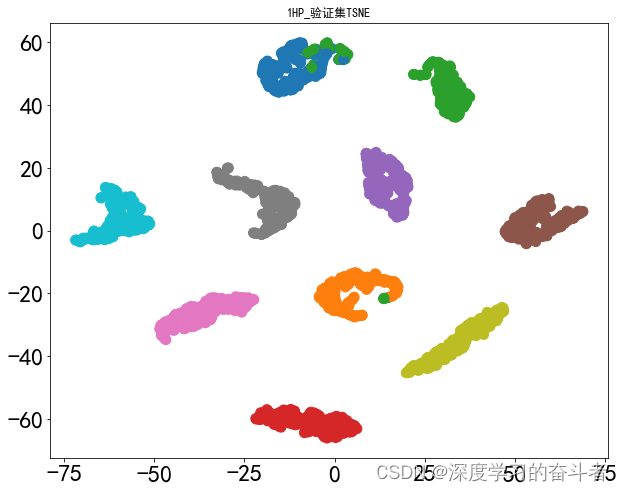
测试集的混淆矩阵

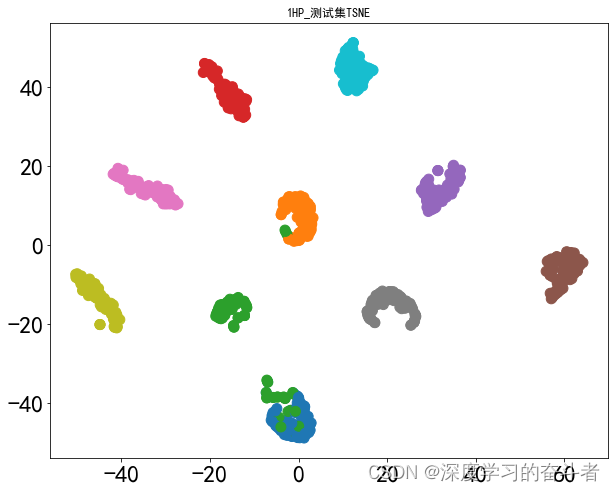
测试集的特征可视化
2HP数据集
训练集准确率曲线
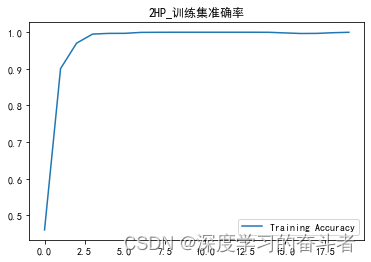
验证集准确率曲线

测试集准确率

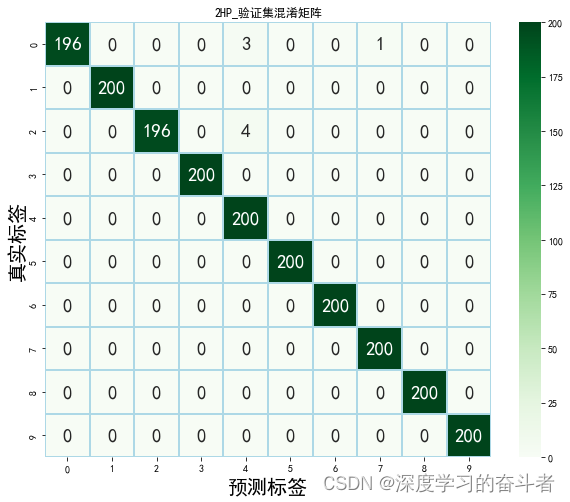
验证集的混淆矩阵
验证集的特征可视化
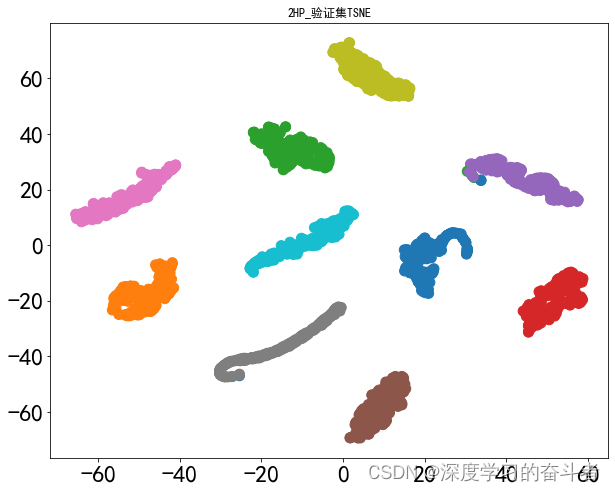
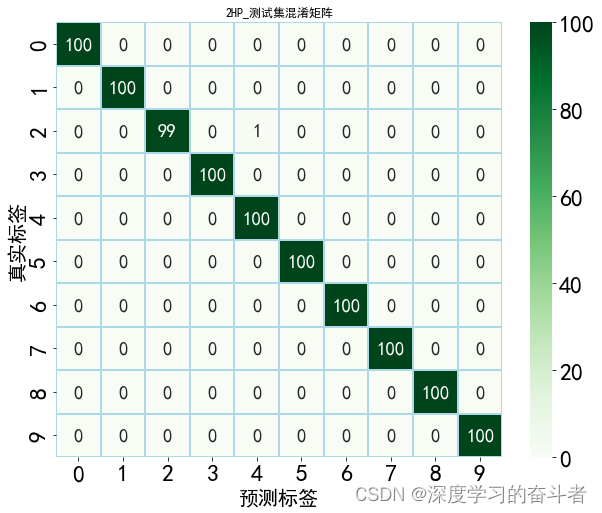
测试集的混淆矩阵
测试集的特征可视化

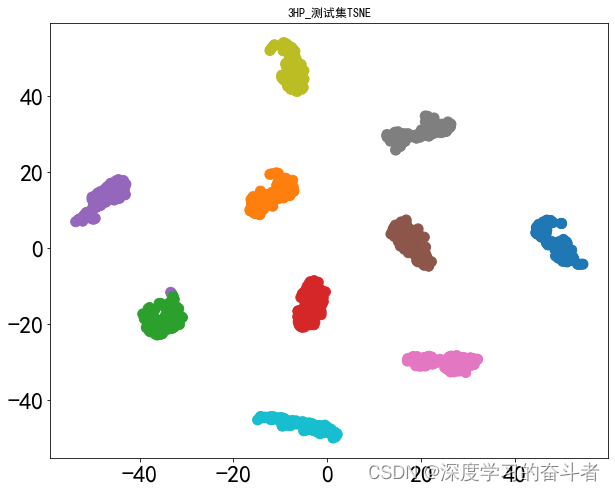
3HP数据集
训练集准确率曲线
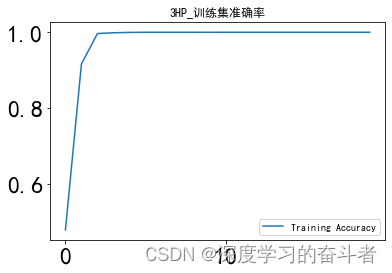
验证集准确率曲线
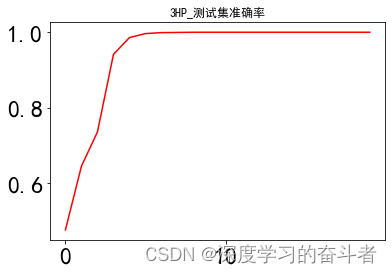
测试集准确率
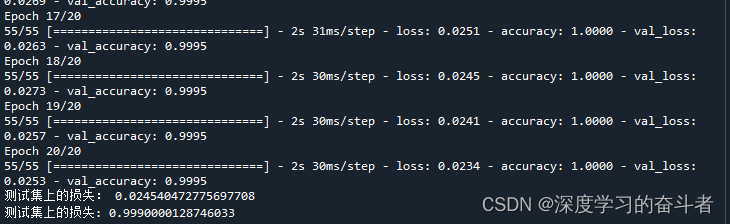
验证集的混淆矩阵
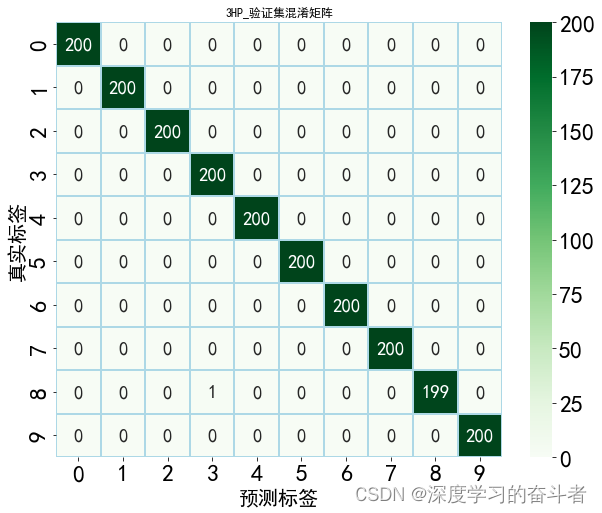
验证集的特征可视化
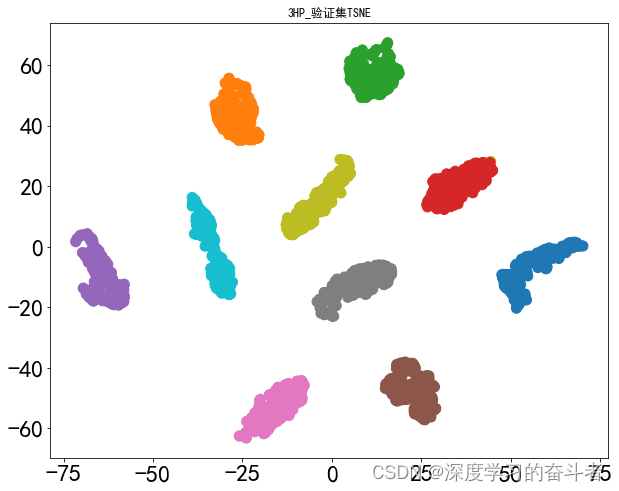
测试集的混淆矩阵
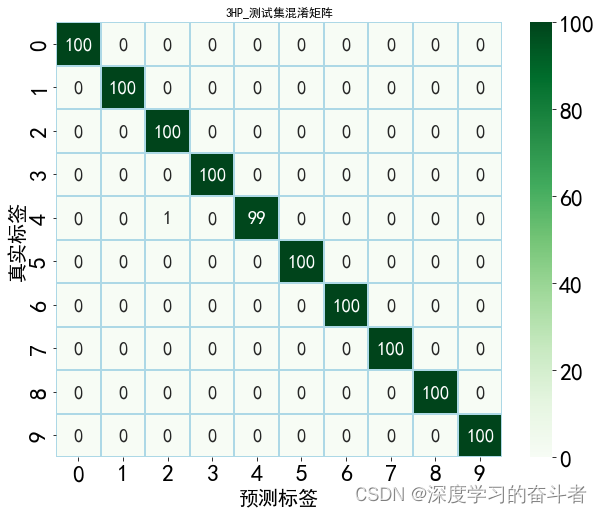
测试集的特征可视化
对项目感兴趣的,可以关注最后一行
from keras.layers import Conv1D, Dense, Dropout, BatchNormalization, MaxPooling1D, Activation, Flatten,GRU
from keras.models import Sequential
from keras.utils import plot_model
from keras.regularizers import l2
import preprocess
from keras.callbacks import TensorBoard
import numpy as np
#代码和数据集压缩包:https://mbd.pub/o/bread/mbd-ZJeXl5dt














 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











