









 本文介绍了Opacus库,这是一个用于PyTorch的差分隐私库,支持多种模型并提供实时隐私预算监控。通过一个MNIST数据集的示例,展示了如何创建和训练一个具有差分隐私的神经网络模型,同时提到了可能遇到的错误及其解决方案。
本文介绍了Opacus库,这是一个用于PyTorch的差分隐私库,支持多种模型并提供实时隐私预算监控。通过一个MNIST数据集的示例,展示了如何创建和训练一个具有差分隐私的神经网络模型,同时提到了可能遇到的错误及其解决方案。
以下代码是Opacus库中的样例代码。
链接:Github-Opacus
OpenMined的一篇博客:blog
1、Opacus库简介:
差分隐私(Differential Privacy ,简称DP)是保护数据集隐私的重要工具。在此之前,谷歌、微软等也陆续开源了其核心产品使用的差分隐私库。
不同的是,与现有方法相比,Opacus具有可扩展性,支持大多数类型的PyTorch模型,并且只需对神经网络进行最少的代码更改。同时它允许客户端实时监控任何给定时间花费的隐私预算(Privacy Budget,DP中的核心数学概念)。
2、代码:
此处给出的代码是OpenMined中给出示例代码,我觉得这个代码比较清晰好懂。
# Step 1: Importing PyTorch and Opacus
import torch
from torchvision import datasets, transforms
import numpy as np
from opacus import PrivacyEngine
from tqdm import tqdm
# Step 2: Loading MNIST Data
train_loader = torch.utils.data.DataLoader(datasets.MNIST('../mnist', train=True, download=True,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),
(0.3081,)),]),), batch_size=64, shuffle=True, num_workers=1, pin_memory=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../mnist', train=False,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),
(0.3081,)),]),), batch_size=1024, shuffle=True, num_workers=1, pin_memory=True)
# Step 3: Creating a PyTorch Neural Network Classification Model and Optimizer
model = torch.nn.Sequential(torch.nn.Conv2d(1, 16, 8, 2, padding=3), torch.nn.ReLU(), torch.nn.MaxPool2d(2, 1),
torch.nn.Conv2d(16, 32, 4, 2), torch.nn.ReLU(), torch.nn.MaxPool2d(2, 1), torch.nn.Flatten(),
torch.nn.Linear(32 * 4 * 4, 32), torch.nn.ReLU(), torch.nn.Linear(32, 10))
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
# Step 4: Attaching a Differential Privacy Engine to the Optimizer
privacy_engine = PrivacyEngine(model, batch_size=64, sample_size=60000, alphas=range(2,32),
noise_multiplier=1.3, max_grad_norm=1.0,)
privacy_engine.attach(optimizer)
# Step 5: Training the private model over multiple epochs
def train(model, train_loader, optimizer, epoch, device, delta):
model.train()
criterion = torch.nn.CrossEntropyLoss()
losses = []
for _batch_idx, (data, target) in enumerate(tqdm(train_loader)):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
epsilon, best_alpha = optimizer.privacy_engine.get_privacy_spent(delta)
print(
f"Train Epoch: {epoch} \t"
f"Loss: {np.mean(losses):.6f} "
f"(ε = {epsilon:.2f}, δ = {delta}) for α = {best_alpha}")
for epoch in range(1, 11):
train(model, train_loader, optimizer, epoch, device="cpu", delta=1e-5)
3、99%可能的报错:
3.1 TypeError: _init_() got an unexpected keyword argument 'batch_size'
这个报错很可能会遇到,因为这个是版本问题导致的,我安装的时候默认安装的是最新版本 1.1.1。可以安装 0.13.0的版本来解决这个问题。或者也可以对代码进行更改,改成1.1.1版本要求的格式。

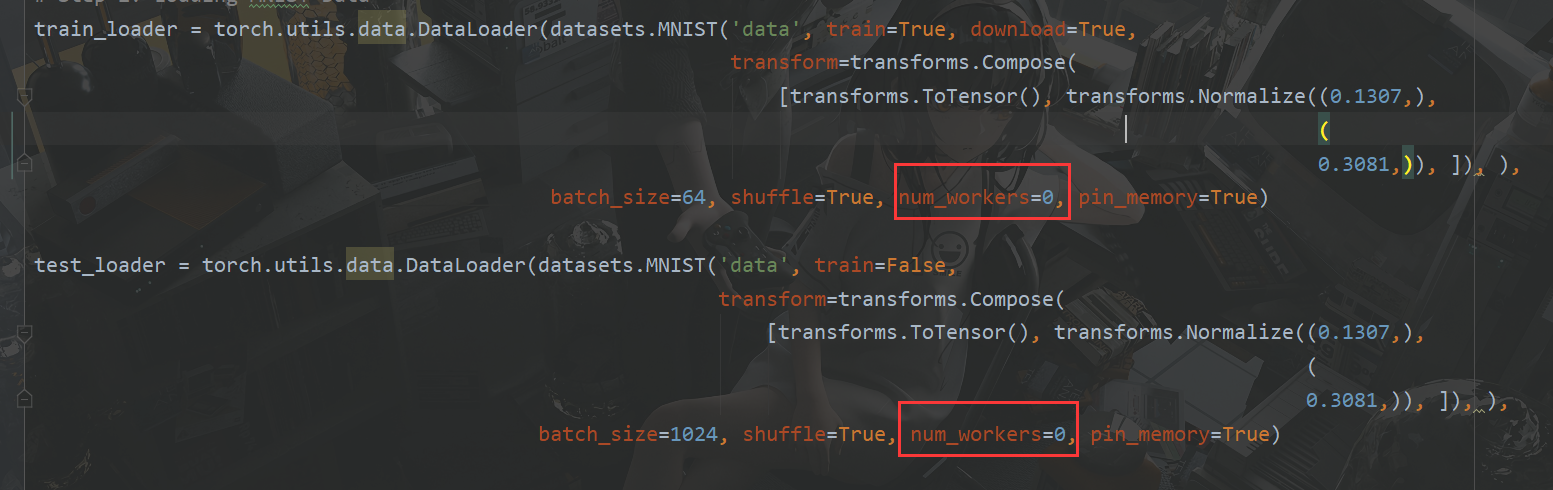
3.2 RuntimeError: DataLoader worker (pid(s) 33408) exited unexpectedly
这个报错是因为下图的参数设置导致的,将num_workers设置为0,成功解决。
num_workers是用来指定开多进程的数量,默认值为0,表示不启用多进程。
将num_workers改为0即可,0是默认值。

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









