






爬取基金排行榜上的基金信息
1、首先我们通过天天基金网首页进入基金排行榜,其URL=http://fund.eastmoney.com/data/fundranking.html,页面内容写如下:
开放基金排行榜下分为股票型、混合型、债券型、指数型、QDII、LOF和FOF六种类型的基金排行以及全部基金共同的一个排行。上图表示全部基金在2020-07-28到2021-07-28一年中按照近6月的收益率降序排列的结果。下面我们以全部为例分析怎么爬取排行榜中的基金信息。
2、通过按键F12进入网页开发者模式

3、通过以上三步找到存储基金表格排行榜中信息的资源名称和其对应的Headers
4、在Headers中我们可以得到Request URL:
选择全部时URL=http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=6yzf&st=desc&sd=2020-07-28&ed=2021-07-28&qdii=&tabSubtype=,&pi=1&pn=50&dx=1&v=0.052543555167660294
| 条件 | 含义 |
|---|---|
| ft=all | 选择的是全部基金的排行榜 |
| sc=6y | 以近6月的收益率为依据排行(默认) |
| st=desc | 降序(默认) |
| sd=2020-07-28 | 开始时间 |
| ed=2021-07-28 | 结束时间 |
| pi=1 | 表格第一页 |
| pn=50 | 该页表格包含50条数据 |
5、构造URL
URL = 'http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=6yzf&st=desc&sd=2020-07-28&ed=2021-07-28&qdii=&tabSubtype=,,,,,&pi=1&pn=50&dx=1'
6、构造请求头
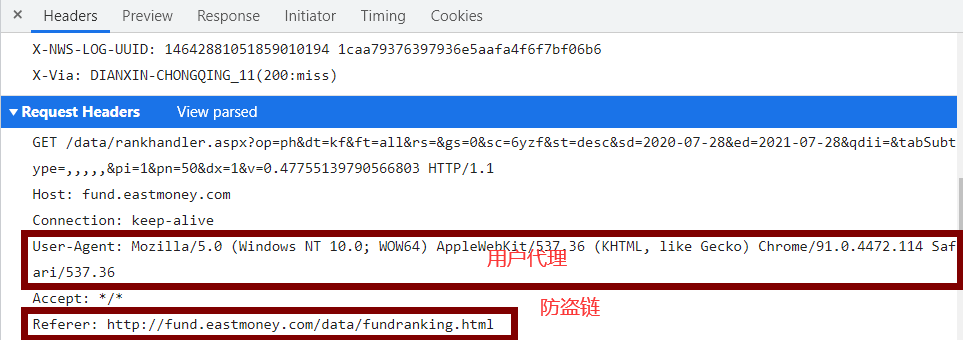
这里的请求头中只需要包含用户代理和防盗链即可。
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'Referer':'http://fund.eastmoney.com/data/fundranking.html'
}
7、当网络地址和请求头构造好之后我们可以使用request模块中的get方法获取表格中的数据,部分代码如下:
def get_oprank_fund(self):
'''
获取排行榜上基金的代码和名称
'''
end_time = time.strftime('%Y-%m-%d') #结束时间
year = int(time.strftime('%Y')) - 1 #开始时间
start_time = str(year) + time.strftime('-%m-%d')
code_url = 'http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=%s&rs=&gs=0&sc=6yzf&st=desc&sd=%s&ed=%s&qdii=&tabSubtype=,,,,,&pi=1&pn=%s&dx=1'%(self.fundtype,start_time,end_time,self.fundnum)
#访问基金代码的请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'Referer':'http://fund.eastmoney.com/data/fundranking.html'
}
code_resp = requests.get(url=code_url,headers=headers)
if code_resp:
jz = [] #存储基金信息
result = re.findall(r'[0-9]{6},.*?,',code_resp.text)
for item in result:
fundcode = item.split(',')[0]
fundname = item.split(',')[1]
self.get_data(fundname,fundcode)
jz.append(self.get_data(fundname,fundcode))
# print([jz])
self.insert_data(jz) #将爬取的数据存入数据库中
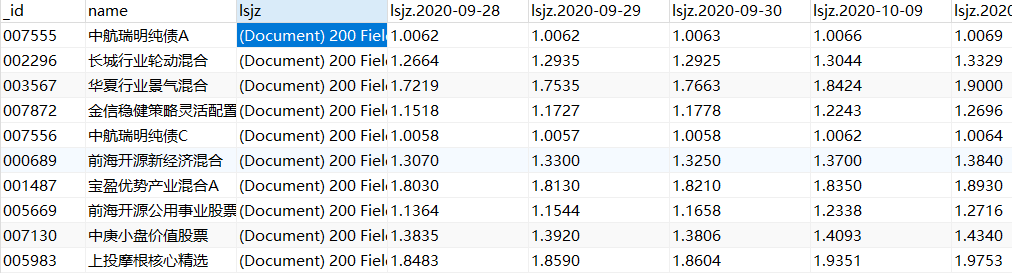
8、爬取结果示例:
如需获取完整代码关注微信公众号即可。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









