







NSGA-II
非支配排序遗传算法II(nondominated sorting genetic algorithm,NSGA-II)是一种多目标优化算法,它通过改进的精英策略和快速非支配排序方法来解决多目标优化问题。该算法自2002年提出以来,在多个领域得到了广泛的应用和研究。
主要特点
- 高效的计算复杂度,NSGA-II通过引入一种快速非支配排序方法,将计算复杂度从 O ( M N 3 ) O(MN^3) O(MN3)降低到 O ( M N 2 ) O(MN^2) O(MN2),其中M是目标数量,N是种群大小;

- 良好的收敛性,NSGA-II采用精英策略,即在选择操作中将当前最优个体保留下来,加速收敛;

- 多样性,NSGA-II还引入了拥挤距离的概念来维护种群的多样性,确保不同个体之间的均匀分布。
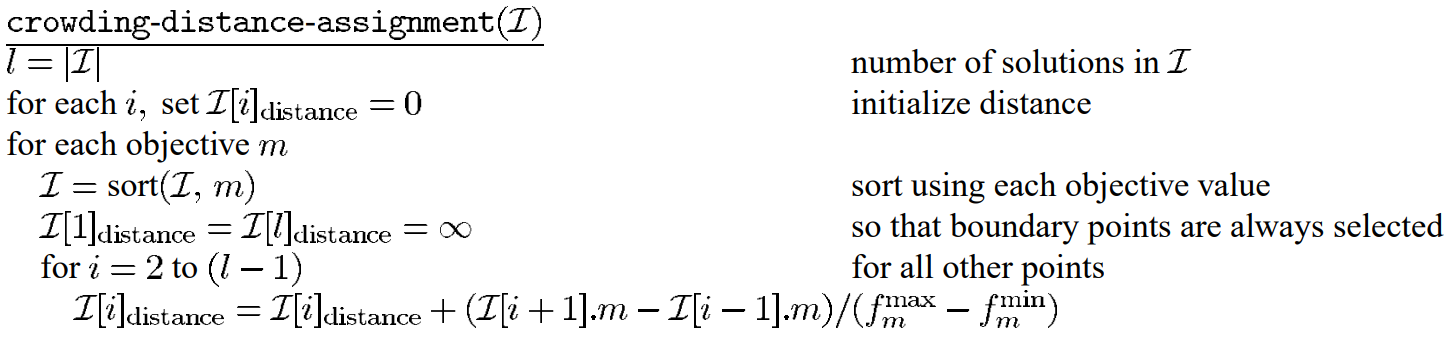
NSGA-II算法相关概念
-
非劣解(Nondominated Solution),对于多目标问题,如果一个解在所有目标函数上都不被其他解所支配,则称为非劣解。
-
帕累托前沿(Pareto Front),帕累托前沿是指所有非劣解构成的集合,表示问题的最优解集。
-
遗传操作(Genetic Operations),NSGA-II算法使用选择、交叉和变异等遗传操作来生成新的解,并通过非支配排序策略筛选出非劣解。
算法流程
NSGA-II算法的主要步骤如下:
(1)初始化种群:随机生成一组初始解作为种群,并计算每个解在目标函数上的适应度值。
(2)非劣解排序:对种群中的解进行非劣解排序,将它们分为不同的等级,确保较好的解获得更高的等级。
(3)计算拥挤度距离:在每个等级内,计算每个解的拥挤度距离,用于衡量解在目标空间中的分布密度。
(4)选择操作:根据非劣解等级和拥挤度距离,选择一组优秀的解作为父代,用于生成下一代解。
(5)交叉和变异操作:对选择的父代解进行交叉和变异操作,生成新的解。
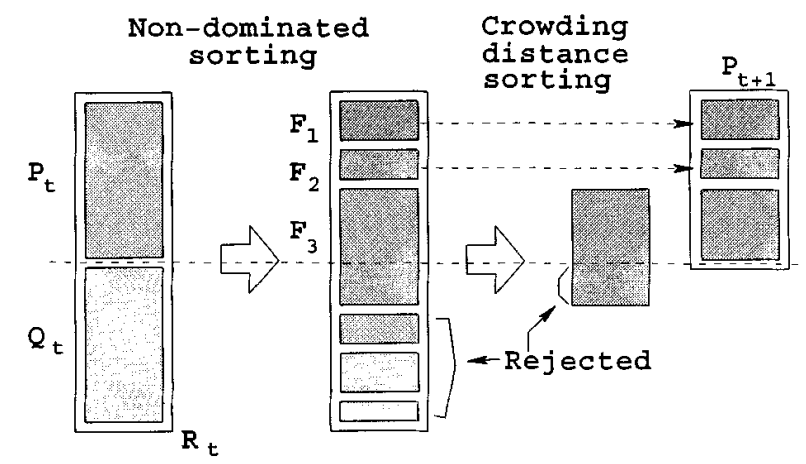
(6)更新种群:将父代解和新生成的解组合成一个新的种群,并截断到原始种群大小的规模。
(7)重复迭代:重复执行上述步骤,直到达到预定的迭代次数或满足终止条件。
(8)输出结果:最终输出帕累托前沿,即非劣解集合。
实验
实验选取ZDT1函数,函数的表达式入下。
m i n f 1 ( x ) m i n f 2 ( x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









