









一、前言
本文实现的listwise loss目前应用于基于ListwWise的召回模型中,在召回中,一般分为用户侧和item侧,模型最终分别输出user_vector和item_vector,在pointwise模型中,这两个vector的shape都为(batch_size,dim),直接求两者的内积或余弦,然后过sigmoid,最后采用交叉熵获得loss进行反向传播。而在listwise模型中,item_vector的shape变为(batch_size,list_size,dim)其中,list_size 为序的长度。这样,在listwise模型中,user_vector与item_vector求内积后,得到的结果的shape为(batch_size,list_size),而输入的label也是(batch_size,list_size),所以有了输出结果与label,据此可以设计listwise loss。
二、ListWise Loss
1.KL 散度 loss
分别对模型输出结果与label,进行softmax就可以分别得到rank_logits(也就是该item排在当前位置的概率)与lable_logits(也就是真实该item排在当前位置的概率),举例:
为了方便batch_size设为1
lable=[5,4,3,1] (对应:下单,加车,点击与曝光的得分)
label_logits=tf.softmax(label)
pred=[a,b,c,d,e]
rank_logits=tf.softmax(pred)
这样我们得到两个概率,衡量两个概率分布差别,自然会想到KL散度。
kl散度代码实现:
def kl_loss(label_prob,pred_prob):
"""
:param label_prob: 真实概率分布
:param pred_prob: 预测概率分布
:return:
"""
p_q = label_prob/tf.clip_by_value(pred_prob,1e-8,1)
kl_loss=tf.reduce_sum(label_prob * tf.log(p_q), axis=-1)
with tf.Session() as sess:
kl_loss=sess.run(kl_loss)
return kl_loss- kl散度用作loss的局限性:
1、lk散度是用来衡量两个概率的分布的差别,而真实的推荐场景中,其实只要满足rank_logits 的顺序与label_logits相同,它的loss就应该为0,并不需要强调概率接近。
2、计算kl loss 需要提前设计一个真实的排序得分,比如:下单,加车,点击与曝光分别为5,4,3,1分。然后使预测的rank_logits尽量与这个分布相近。然而这个分布是人为定义的,不是真实的分布。
- kl散度用作loss的优势:
1、实现简单,计算速度快
2、设计不同的得分,相当于设计不同的样本权重,当需要提高转化率,则可以把下单的分数设置高一点
2.ListMLE loss
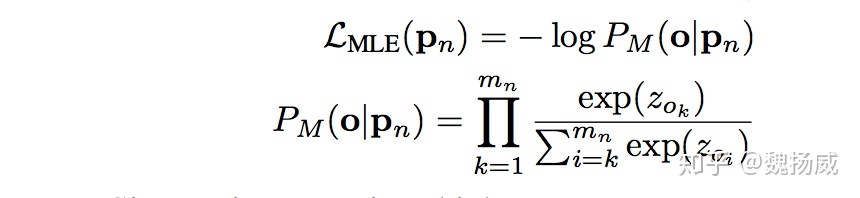
o= [o1, o2, · · · , omn ]表示答案中的正确序列,k=1时,表示o1被正确放在第1位的概率;k=2时,表示o2在除去o1的剩下候选中,被选做第2位的概率;依次类推,最后概率乘起来;因为概率乘可能会导致数值过小,所以在第一个公式中套上log。可不太好理解,举个例子:
label=[2,5,3,1]
logits=[0.7,1.1,2.1,0.5]
先给label 排序 [5,3,2,1],按照label的排序方式,给logits排序则变成[1.1,2.1,0.7,0.5](可以理解为把label与logits看成两列,按label那列由大到小排序)
然后套公式计算:
o1放首位的概率 po1=1.1/(1.1+2.1+0.7+0.5)\
去掉o1,o2放首位的概率po2=2.1/(2.1+0.7+0.5),依次类推
最后loss=-log(po1*po2...*pon)
MLELoss代码实现:
# 参考:https://zhuanlan.zhihu.com/p/66514492
import tensorflow as tf
def mle_loss(true_scores,rank_scores):
'''
:param true_scores: 真实得分(分值不重要,能确定先后顺序就行),shape (bt,list_size)
:param rank_scores: 预测得分, shape (bt,list_size)
:return:
'''
# batch_size=4
list_size=3 #list 不一定为真实的,也可以指定任意值(mle 可以理解为该item排在首位的概率的联乘)
index = tf.argsort(true_scores, direction='DESCENDING')
# print(index)[1,2,0] [1,0,2]
#按真实得分对rank_scores排序
S_predict=tf.batch_gather(rank_scores, index)
# S_predict=tf.gather(rank_scores, index,axis=-1,batch_dims=0)
#分子
initm_up=tf.constant([[1.0]]) #shape 为 1,1
for i in range(list_size):#3为 list_size
# index=tf.constant([[i]]*batch_size,dtype=tf.int32) #shape 为 bt,1
# a=tf.batch_gather(S_predict,index)
a=tf.slice(S_predict,[0,i],[-1,1]) #shape 为 bt,1
initm_up=initm_up*a #bt,1
#分母
initm_down=tf.constant([[1.0]]) #shape 为 1,1
for i in range(list_size):
b=tf.reduce_sum(tf.slice(S_predict, [0, i], [-1, list_size - i]), axis=-1,keep_dims=True) # bt
initm_down*=b
loss=tf.log(tf.divide(initm_up,initm_down))
mleloss=-tf.reduce_mean(loss)
return mleloss3、ListNet Loss
- ListNet损失,同样先构造答案序列中每个item的得分,如[y1, y2, y3] = [0, 0.5, 1]
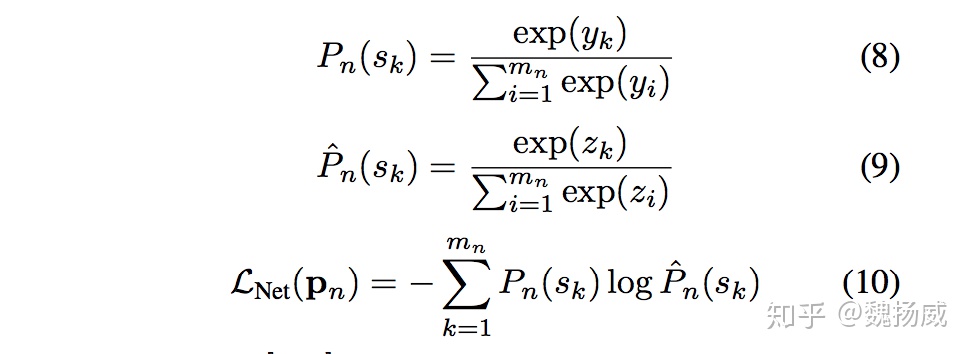
第一个公式计算答案中每个item被当成首个item的概率;
第二个公式计算预测结果中每个item被当成首个item的概率;
第三个公式是前面两个概率分布的交叉熵


















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









