






TediGAN:文本引导的多样化人脸图像生成和操作 (CVPR 2021)

1 Task

2 Problems
分辨率低
3 Contributions
- 我们提出了一个统一的框架,可以在给定相同输入文本的情况下生成不同的图像,也可以将文本与图像一起进行操作,允许用户交互编辑不同属性的外观。
- 我们提出了一种将多模态信息映射到预训练样式的公共潜空间的GAN反转技术,在该潜空间中可以学习实例级的图像-文本对齐。
- 我们引入多模态CelebA HQ数据集,由多模态人脸图像和相应的文本描述组成,以方便大家使用。
4 Methods
4.1 StyleGAN Inversion Module
- 训练一个图像编码器,把真实的脸部图像映射到预训练的StyleGAN的潜在空间
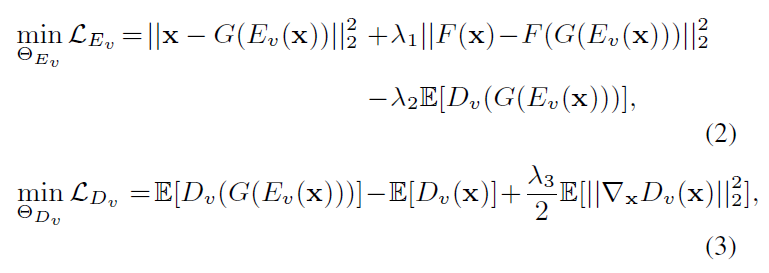
4.2 Visual-Linguistic Similarity Learning
学习视觉和语言之间的对应关系
- 左:同一对文本和图像映射到潜在空间的w应该尽可能相似
- 右:文本操作图像的过程
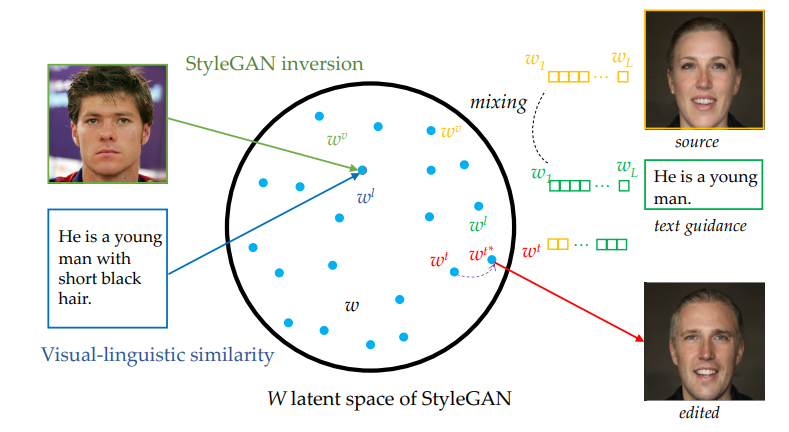
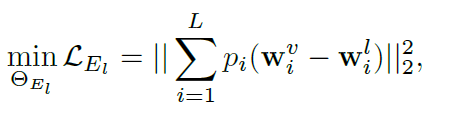
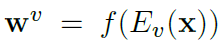
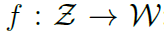
- 与DAMSM相比,轻量级,易训练
4.3 InstanceLevel Optimization
实例级优化模块,精确地操作与描述一致的所需属性,同时重构无关的属性
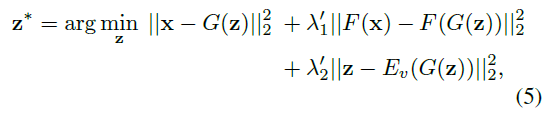
4.4 Control Mechanism
4.4.1 Attribute-Specific Selection
- 文本到图像生成和文本引导的图像操作统一到一个框架
- 不同层的w代表不同的属性,被输送到生成器的不同层
- 给定两个w( w c , w s w^c , w^s wc,ws ) 控制机制选择特定于属性的层,并通过部分替换 w c w^c wc的相应层来混合这些 w s w^s ws层
- 当 w s w^s ws 是随机采样的潜在编码时是文本到图像生成;当 w s w^s ws 是由图像得到的潜在编码时是文本引导的图像操作
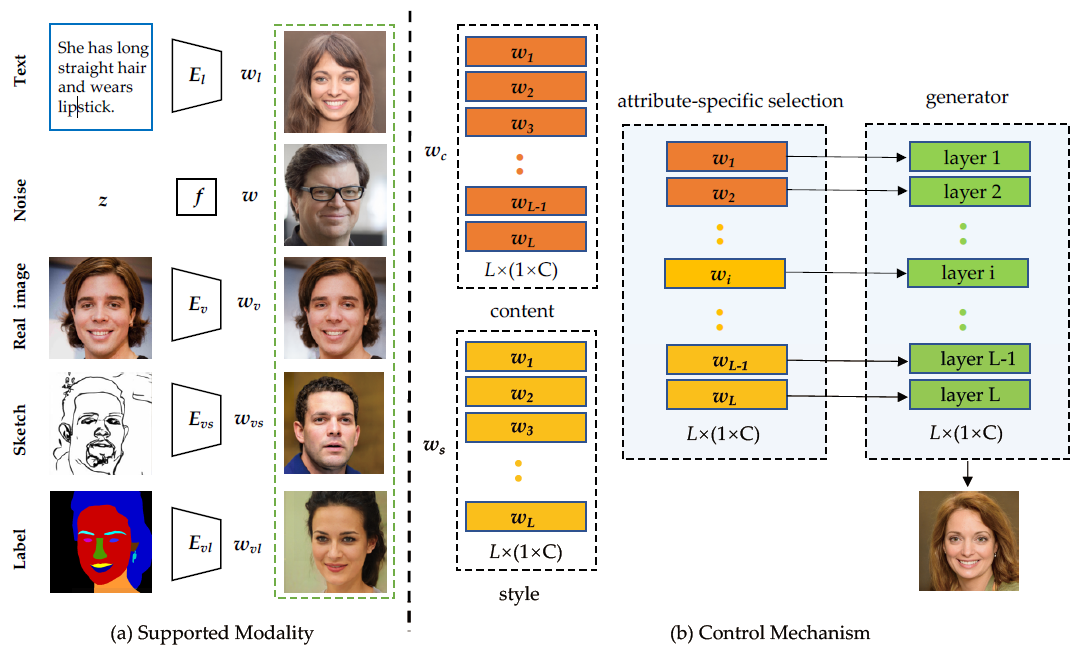
4.4.2 Supported Modality.
- w s , w c w^s,w^c ws,wc 可以是sketch, label, image和noise,便于灵活的多模态图像生成
- 控制机制为图像生成和操作提供了高可访问性、多样性、可控性和准确性
- 支持连续操作和草图或语义标签描述的多模态生成
4.4.3 Layerwise Analysis
- 较低分辨率的层( e . g . , 4 × 4 , 8 × 8 e.g.,4\times4,8\times8 e.g.,4×4,8×8)控制高级风格(如眼镜和头部姿态)
- 中间层( e . g . , 16 × 16 , 32 × 32 e.g.,16\times16,32\times32 e.g.,16×16,32×32)控制发型和面部表情
- 最后的层( e . g . , 64 × 64 到 1024 × 1024 e.g.,64\times64 到 1024\times1024 e.g.,64×64到1024×1024)控制配色方案和细粒度的细节
- 11- 14层代表微特征或精细结构,如胡茬、雀斑或皮肤毛孔等,可视为随机变化

5 Experiment Results
5.1 Multi-Modal CelebA-HQ dataset
- 30000高分辨率脸部图像
- 每个都有一个高质量的分割掩码,草图和描述性文本。
5.2 Baseline Models
- image generation:AttnGAN, ControlGAN, DM-GAN, DFGAN
- image manipulation: ManiGAN
5.3 Evaluation Metric
- image quality: FID
- image diversity: Learned Perceptual Image Patch Similarity (LPIPS)
- accuracy
- image generation:文本和图像的相似性
- image manipulation: 通过对合成图像修改后的视觉属性是否与给定的描述保持一致以及是否保留与文本无关的内容
- accuracy and realism使用user study评估,用户判断哪个更真实,哪个与文本更一致
5.4 Comparison with State-of-he-Art Methods
5.4.1 Text-to-Image Generation
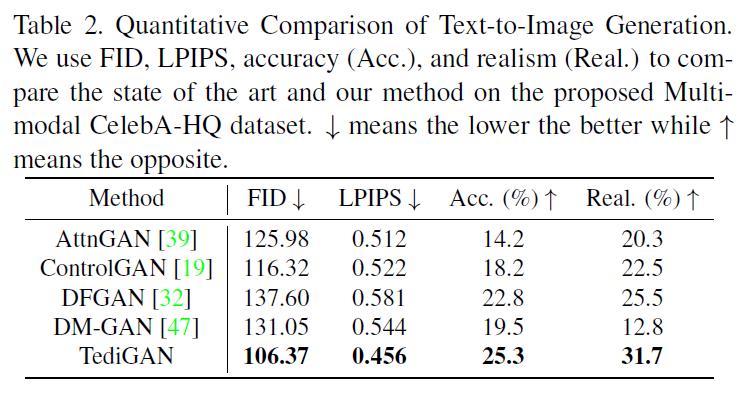
- 定量比较
- 定性比较
- 文本中包含的一些属性并没有出现在生成的图像中,生成的图像看起来像无特征的绘画,缺乏细节。对多阶段生成高分辨率图像影响很大
- 大多数现有解决方案的输出多样性有限,即使提供的条件包含不同的含义。例如,"has a beard"的胡子在长短颜色上都可能不同。

- 第一行:关键的视觉属性(女性、黑色长发、耳环和微笑)被保留,而其他属性,如发型、妆容、脸型和头部姿势,则表现出很大程度的多样性
- 第二行图像说明了更精确的控制能力。保持代表脸型和头部姿势的层不变,并改变其他层

- 多样的高分辨率结果

5.4.2 Text-Guided Image Manipulation
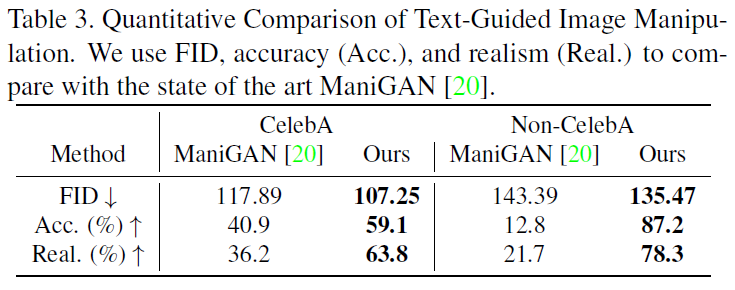
- 定量比较,高质量,与文本描述更一致,保留文本无关内容
- 定性比较
- 添加耳环,改变女性的脸型和发型,我们的方法完成了这个困难的案例,而ManiGAN并没有产生所需的属性。
- 最后两列来自其他数据集,说明TediGAN在其他图像上也能生成很好的效果

5.5 Ablation Study
5.5.1 Instance-Level Optimization
-
b 尽管两者都保留了identity,但可选的实例级优化提供了一种不确定的方法来相应地优化最终结果
-
c 保留了原始图像的所有属性,足够进行文本到图像生成,因为没有保留identity
-
d 根据文本操作图像,不应该改变无关属性尤其是一个人的identity

5.5.2 Visual-Linguistic Similarity
有时可能导致属性解纠缠不足和图像-文本对齐不匹配

5.5.3 Potential Issue with StyleGAN
- 文本操作图像时,无关属性可能改变。一些面部属性在W空间依然纠缠在一起
- StyleGAN的另一个固有缺陷是,它的一些属性,如帽子、项链、耳环,在潜在空间中没有很好地体现出来。















 1404
1404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









