







2021-ACL-Template-Based Named Entity Recognition Using BART
文章目录
0 写在前面
基于距离的NER方法
比如原型网络的方法,确实能够在很大程度上减少领域适应性成本,特别是在目标域数量较多的情况下.但是,目标域的标记实例被用来寻找启发式近邻算法的最佳超参数设置而不是更新NER模型中的参数,过度依赖源域和目标域之间的相似文本模式
最佳超参数设置或者说是一个阈值,阈值决定分类的结果
Motivation
- 现有的few-shot NER使用基于相似度的度量,不能充分利用NER模型参数中的知识迁移
- 基于微调的NER模型,进行领域迁移时,需要对输出层进行调整,必须使用源域和目标域再次训练,代价昂贵
- 目标领域的实体集合可能和源领域有很大差别,例如,新闻领域里提及一个人,类别往往是‘PERSON’,但是在电影领域,他的类别可能就是“CHARACTER”
提出一种基于模板的NER方法,将NER任务视为一个在seq2seq框架下的语言模型排名问题
在富资源任务,CoNNL03数据集上,取得了92.55%的F1得分.在低资源任务,the MIT Movie和the MIT Restaurant and the ATIS分别取得10.88%,15.34%,11.73%,显著的高于基于BERT的微调模型
contribution
- 第一个采用生成式预训练语言模型来解决少样本NER的序列标注问题
- 在富资源NER任务上,达到和SoTa相当的效果,在低资源NER上显著优于SoTa模型
Method
符号定义
传统的序列标注方法
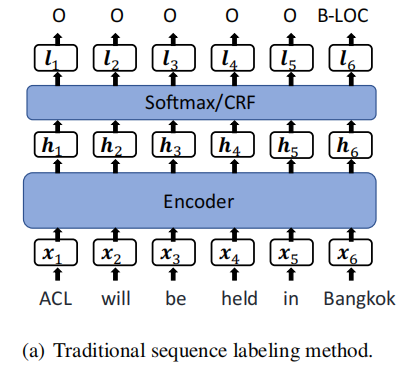
模型
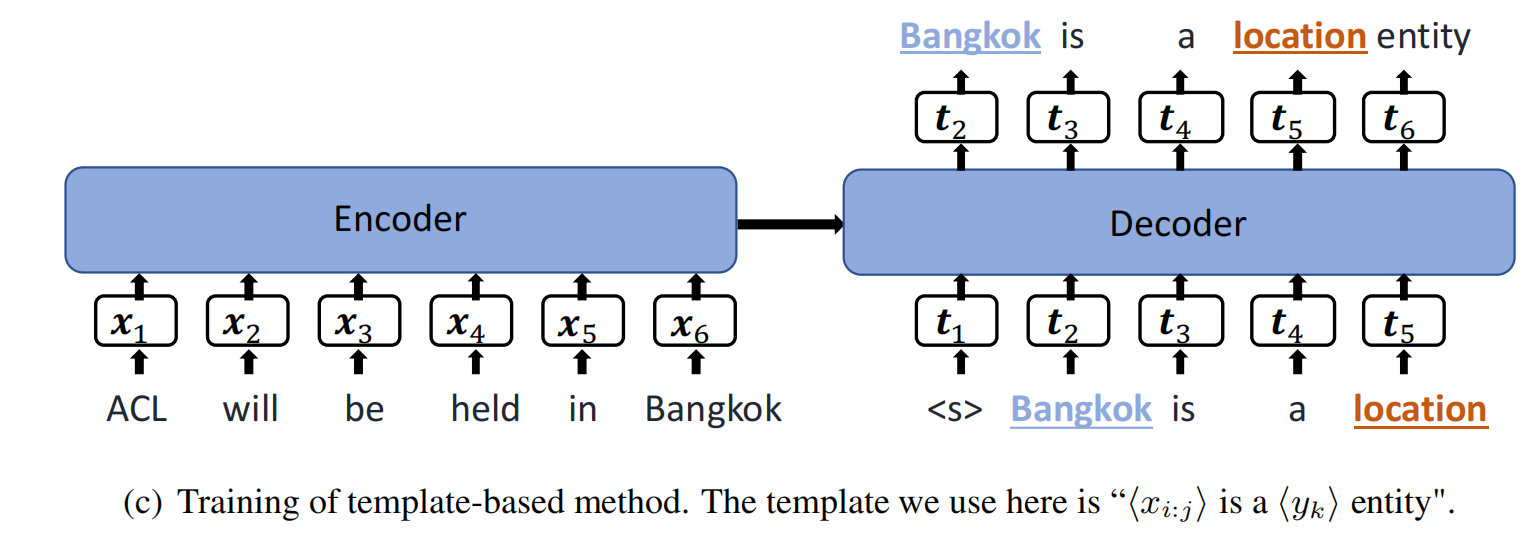
结构:
定义输入的text为 X = { x 1 , … , x n } X=\left\{x_{1}, \ldots, x_{n}\right\} X={x1,…,xn},模板为 T y k , x i : j = { t 1 , … , t m } \mathbf{T}_{y_{k}, x_{i: j}}=\left\{t_{1}, \ldots, t_{m}\right\} Tyk,xi:j={t1,…,tm}
过程:
- 手动创建模板 如: T y k , x i : j + T_{yk,x_{i:j}}^{+} Tyk,xi:j+ ** : <candidate_span>( x i : j x_{i:j} xi:j) is <entity_type>( y k y_k yk) entity** , <candidate_span> is not a named entity
- 枚举一句话中所有可能的span,从1-gram 到 8-gram ,枚举出8n个span 填充到模板中,
- 使用经过微调的预训练生成语言模型, 对每个span,对于每个entity label 计算一个分数 f ( T y k , x i : j ) = ∑ c = 1 m log p ( t c ∣ t 1 : c − 1 , X ) f(T_{yk,x_{i:j}}) = \sum_{c=1}^m \log{p(t_c|t_{1:c-1},X)} f(Tyk,xi:j)=∑c=1mlogp(tc∣t1:c−1,X),对于non-entity也计算一个分数 f ( T x i , j − ) f(T^-_{x_{i,j}}) f(Txi,j−),选出分数最大的作为这个span 的预测结果
p ( t c ∣ t 1 : c − 1 , X ) p(t_c|t_{1:c-1},X) p(tc∣t1:c−1,X) 意思是 t c t_c tc是通过 t 1 : c − 1 t_{1:c-1} t1:c−1和Encoder的输入 X : { x 1 , x 2 , x 3 . . . } X:\{x_1,x_2,x_3...\} X:{x1,x2,x3...}得到的
训练
-
训练时使用gold entities构建正模板,随机采样non-entity的span构建负模板,负模板的数量是正模板的1.5倍,训练是最小化交叉熵损失 L = − ∑ c = 1 m log p ( t c ∣ t 1 , c − 1 , X ) \mathcal{L}=-\sum_{c=1}^{m} \log p\left(t_{c} \mid t_{1, c-1}, \mathbf{X}\right) L=−∑c=1mlogp(tc∣t1,c−1,X)
-
给定一个序列对(X,T), 把X喂给Encoder的input
即 h e n c = E n c o d e r ( x 1 : n ) h^{enc} = Encoder(x_{1:n}) henc=Encoder(x1:n)
- 在Decoder的第c步中, h e n c h^{enc} henc和 t 1 : c − 1 t_{1:c-1} t1:c−1作为Decoder的输入,产生一个使用注意力机制的表示
即 h c d e c = D e c o d e r ( h e n c , t 1 : c − 1 ) h^{dec}_c = Decoder(h^{enc},t_{1:c-1}) hcdec=Decoder(henc,t1:c−1)
- 得到字 t c t_c tc的条件概率
即 p ( t c ∣ t 1 , c − 1 , X ) = S o f t m a x ( h c d e c W l m + b l m ) p\left(t_{c} \mid t_{1, c-1}, \mathbf{X}\right) = Softmax(h^{dec}_cW_{lm}+b_{lm}) p(tc∣t1,c−1,X)=Softmax(hcdecWlm+blm)
h c d e c W l m + b l m h^{dec}_cW_{lm}+b_{lm} hcdecWlm+blm理解为全连接层,对BART词表中所有词进行打分
-
解码器输出和原始模板之间的交叉熵被用作损失函数: L = − ∑ c = 1 m log p ( t c ∣ t 1 , c − 1 , X ) L = -\sum_{c=1}^m \log{p(t_c \mid t_{1,c-1},X)} L=−∑c=1mlogp(tc∣t1,c−1,X)
2022年3月9日15:46:43 好像理解一点了,在 t c t_c tc是一个确定的值,就是模板的第c个word,所以,
希望在知道原句X的语义信息和模板的前 c − 1 c-1 c−1个word时,使得 p ( t c ∣ t 1 , c − 1 , X ) p(t_c \mid t_{1,c-1},X) p(tc∣t1,c−1,X)
QA
- 损失函数没看明白 理解一点了
迁移学习
给定一个少样本实例的新领域P,标签集为 L P L^P LP(可能包含与已经训练的NER模型不同的实体类型)
- 用新的标签集填充模板,得到少量的的( X P , T P X^P,T^P XP,TP) 序列对
- 对在富样本下训练的NER模型进行微调
输出的是一个自然句子,而不是一个标签,不管是富资源数据集,还是低资源数据集,标签都是在预训练模型中的子集
模型学到了很多相关性信息,比如原来学习过实体类型的city,那么少样本情况下,有一个实体类型location,city的相关性,能够提升跨领域学习效果
实验
CoNNL03作为富数据集
MIT Movie Review,MIT Restaurant Review,ATIS作为少样本跨领域的数据集
探究不同模板的影响
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ui5hraGe-1649129418999)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220310184249215.png)]
可以选用不同的模板来表达同一个意思,但实验结果表明,模板的选择也是影响最终性能表现的一个关键因素
故后续实验默认选择表现最好的模板: <candidate_span> is a <entity_type> entity
CoNNL03结果
标准NER设置
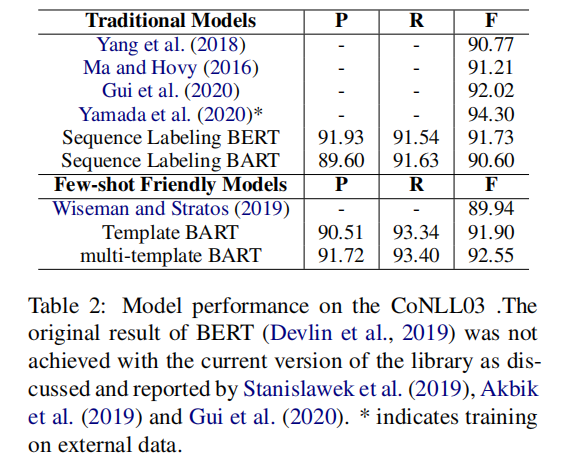
探究方法在标准NER设置的表现
评价
-
基于序列标注的BERT模型给出了一个起点很高的基线
-
即使基于模板的BART模型是被设计用作少样本NER,但是,在富样本设置下,表现得同样有竞争力…其中,召回率比基于序列标注的BERT模型高1.8%这表明这个方法确实能够提高识别实体的能力
召回率说明的是查的全,很少把正确的预测成错误的,
-
通过对比基于序列标注的BART模型和基于模板的BART模型,可以发现,虽然都是使用BART Decoder,但是基于模板的方法效果明显更好,证明了基于模板方法的有效性
-
BART序列分类做的不好可能原因是基于seq2seq的denoising autoencoder training
疑问:
-
denoising autoencoder training
denoising autoencoder(DAE),BART就是DAE模型的一种
接受部分损坏的输入,并以恢复这些未失真的原始输入为目标。这类任务会使用标准 Transformer 等模型来重建原始文本,它与 MLM 的不同之处在于,DAE 会给输入额外加一些噪声。
探究模板之间是否有互补性
实验方法
- 使用前三个模板训练三个模型
- 采用实体级投票的方法对三个模型进行组合
结果
F1 score 达到92.55%,超过最佳模型的92.27%
领域内少样本NER
设置
-
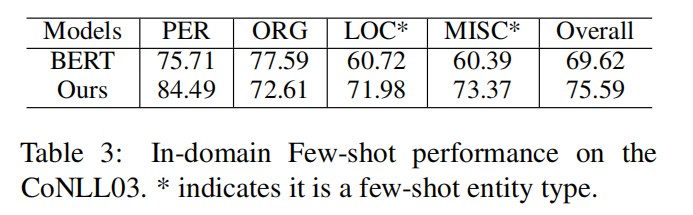
设定"MISC"和"ORG"为富样本实体,"LOC"和"PER"为少样本实体
-
从CONNL03中下采样3806个训练样本,其中包含3925个"ORG",1423个"MMISRC",50个"LOC",50个"PER"
结果
-
富样本实体类别识别中,和基于序列标注的BERT表现得一样好
-
少样本实体类别识别中,F1 分数显著的领先于BERT模型 , "LOC"和"MISC"分别高11.26,12.98
富样本类别识别一个高一个低,就两个实体类别,感觉不能得出表现相似的结果
跨领域少样本NER
设置
-
从大的训练集中随机抽取训练实例作为目标域的训练数据,其中每个实体类型随机抽取固定数量的实例
-
使用不同数量的实例进行训练
结果

从头开始训练时
少样本时,显著优于BERT模型
探究多少知识能够从CONNL03中迁移
或者说从新闻领域的迁移
设定
使用CONNL03训练
结果
-
当训练实例较少时,基于模板的BART方法明显优于基于序列标注的BERT和BART方法
-
BERT和作者的方法都比从头训练结果好,表明了能够从CONNL03中学习到知识,比BERT好,证明了模型能够利用词汇知识,学习不同实体类型标签的相关性,而BERT模型,则将输出视为离散的类别标签从而无法实现
Conclusions
本文以BART为骨干网络,研究基于模板的少样本NER
- 当出现新的实体类别时,可以直接针对目标领域进行微调,这比基于序列标注的NER模型更强大
- 在富资源任务上,取得了有竞争力的结果;在低资源跨领域NER任务上,明显优于序列标注和基于距离的方法
















 2037
2037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











