







[论文笔记]ACL-2021-Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning
作者利用外部上下文检索和合作学习改进命名实体识别
命名实体识别(NER)的最新进展表明,利用文档级的文本信息可以提升实体识别效果,但在很多应用场景下并没有可用文档的信息。
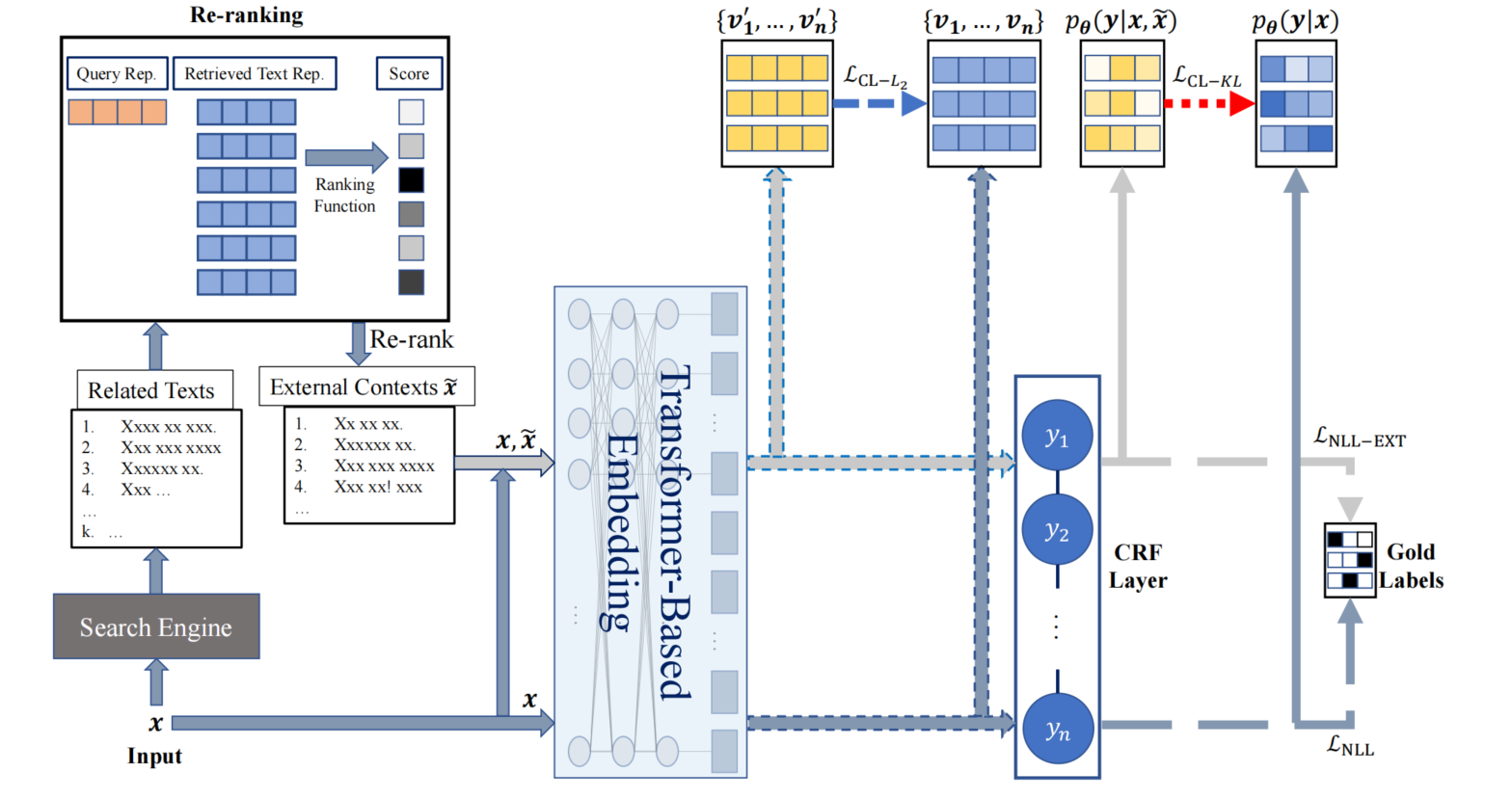
针对此问题,作者提出利用搜索引擎检索和选择一组语义相关的文本,以原始句子作为查询,来查找句子的外部上下文,接着使用Re-ranking模块对检索到的外部文本进行排序,筛选出topk个文本作为额外的文本,原始文本作为一种输入视图,原始文本拼接筛选出的额外文本作为另一种视图放入BERT模型中,利用合作学习以鼓励两个输入视图产生相似上下文表示或输出标签分布,可以显著提高性能
有博客提到:“最后连同原始文本一起输入Encoder模型进行多任务学习,包括NER学习和样本分布学习,从而提高NER识别效果。” ,那么多任务是指,使用同一BERT模型共享参数吗
实验表明,作者的方法可以在5个领域的8个NER数据集上实现最新的性能。

方法
思路
-
把一个n-tokens句子 x = { x 1 , ⋯ , x n } \boldsymbol{x}=\left\{x_{1}, \cdots, x_{n}\right\} x={x1,⋯,xn}当做查询句,送进Google搜索引擎
-
返回前k个相关的文本 { x ^ 1 , ⋯ , x ^ k } \left\{\hat{\boldsymbol{x}}_{1}, \cdots, \hat{\boldsymbol{x}}_{k}\right\} {x^1,⋯,x^k},送进
Re-Ranking模型 -
按照输入句子和检索文本相关性进行重新排名,返回F1分数前 l l l名的文本连结的结果 x ~ = [ s e p − t o k e n ; x ^ 1 ; ⋯ ; x ^ l ] \tilde{\boldsymbol{x}}=\left[sep _{-}\right.token \left.; \hat{\boldsymbol{x}}_{1} ; \cdots ; \hat{\boldsymbol{x}}_{l}\right] x~=[sep−token;x^1;⋯;x^l]
-
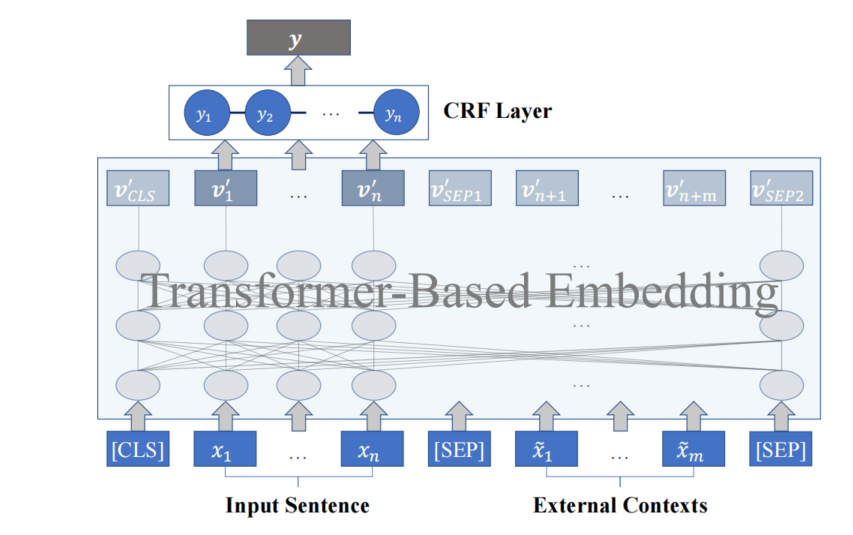
将 [ x ~ ; x ] [\tilde{\boldsymbol{x}};\boldsymbol{x}] [x~;x]和 [ x ] [\boldsymbol{x}] [x]视为两种不同视图,送进一个基于Transformer的预训练的上下文语境模型(如BERT)中,以获得Token表示
{ v 1 ′ , ⋯ , v n ′ , ⋯ } = embed ( [ x ; x ~ ] ) , \left\{\boldsymbol{v}_{1}^{\prime}, \cdots, \boldsymbol{v}_{n}^{\prime}, \cdots\right\}=\operatorname{embed}([\boldsymbol{x} ; \tilde{\boldsymbol{x}}]), {v1′,⋯,vn′,⋯}=embed([x;x~]), { v 1 , ⋯ , v n } = embed ( [ x ] ) \left\{\boldsymbol{v}_{1}, \cdots, \boldsymbol{v}_{n}\right\}=\operatorname{embed}([\boldsymbol{x} ]) {v1,⋯,vn}=embed([x]) -
**[可选]**对两个视图输获得的Token表示使用L2正则化,强制使得两个视图的token表示相似
L C L − L 2 ( θ ) = ∑ i = 1 n ∥ v i ′ − v i ∥ 2 2 \mathcal{L}_{\mathrm{CL}-L_{2}}(\theta)=\sum_{i=1}^{n}\left\|\boldsymbol{v}_{i}^{\prime}-\boldsymbol{v}_{i}\right\|_{2}^{2} LCL−L2(θ)=i=1∑n∥vi′−vi∥22 -
两个视图的Token表示送入到CRF层,获得标签预测结果
-
对两个视图的标签预测结果与真实标签使用负对数似然损失函数,分别为
L N L L − E X T ( θ ) = − log p θ ( y ∗ ∣ x , x ~ ) \mathcal{L}_{\mathrm{NLL}-\mathrm{EXT}}(\theta)=-\log p_{\theta}\left(\boldsymbol{y}^{*} \mid \boldsymbol{x}, \tilde{\boldsymbol{x}}\right) LNLL−EXT(θ)=−logpθ(y∗∣x,x~) , L N L L ( θ ) = − log p θ ( y ∗ ∣ x ) \mathcal{L}_{\mathrm{NLL}}(\theta)=-\log p_{\theta}\left(\boldsymbol{y}^{*} \mid \boldsymbol{x}\right) LNLL(θ)=−logpθ(y∗∣x)
-
**[可选]**对两个视图的标签预测结果之间使用KL散度,约束模型预测的标签分布于两个输入视图相似
L C L − K L ( θ ) = − ∑ i = 1 n ∑ y i = 1 t q θ ( y i ∣ x , x ~ ) log q θ ( y i ∣ x ) \mathcal{L}_{\mathrm{CL}-\mathrm{KL}}(\theta)=-\sum_{i=1}^{n} \sum_{y_{i}=1}^{t} q_{\theta}\left(y_{i} \mid \boldsymbol{x}, \tilde{\boldsymbol{x}}\right) \log q_{\theta}\left(y_{i} \mid \boldsymbol{x}\right) LCL−KL(θ)=−i=1∑nyi=1∑tqθ(yi∣x,x~)logqθ(yi∣x) -
总损失函数如下,其中 L C L ( θ ) \mathcal{L}_{\mathrm{CL}}(\theta) LCL(θ)既可以为 L C L − K L ( θ ) \mathcal{L}_{\mathrm{CL}-\mathrm{KL}}(\theta) LCL−KL(θ)、 L C L − L 2 ( θ ) \mathcal{L}_{\mathrm{CL}-L_{2}}(\theta) LCL−L2(θ)二者之和,也可为二者之一
L ( θ ) = L N L L ( θ ) + L N L L − E X T ( θ ) + L C L ( θ ) \mathcal{L}(\theta)=\mathcal{L}_{\mathrm{NLL}}(\theta)+\mathcal{L}_{\mathrm{NLL}-\mathrm{EXT}}(\theta)+\mathcal{L}_{\mathrm{CL}}(\theta) L(θ)=LNLL(θ)+LNLL−EXT(θ)+LCL(θ)
模块
Re-Ranking
动机:
搜索引擎进行了高度优化,首先是保证检索速度,相关性不一定得到保障,但NER任务更看重相关文本与输入句子之间的相似性
解决方案
作者通过对比三种方法,BERTScore效果最好
过程
-
给出输入句子x相应的预规范化Token表示 { r 1 , ⋯ , r n } \left\{\mathbf{r}_{1}, \cdots, \mathbf{r}_{n}\right\} {r1,⋯,rn}和某一检索的文本 x ^ \hat{\boldsymbol{x}} x^的预规范化token表示 { r ^ 1 , ⋯ , r ^ m } \left\{\hat{\mathbf{r}}_{1}, \cdots, \hat{\mathbf{r}}_{m}\right\} {r^1,⋯,r^m}
-
BERTScore的精确度和召回率衡量彼此之间的语义相似度,其中
R = 1 n ∑ x i ∈ x max x ^ j ∈ x ^ r i ⊤ r ^ j ; P = 1 m ∑ x ^ j ∈ x ^ max x i ∈ x r i ⊤ r ^ j \mathbf{R}=\frac{1}{n} \sum_{x_{i} \in \boldsymbol{x}} \max _{\hat{x}_{j} \in \hat{\boldsymbol{x}}} \mathbf{r}_{i}^{\top} \hat{\mathbf{r}}_{j} ; \quad \mathbf{P}=\frac{1}{m} \sum_{\hat{x}_{j} \in \hat{\boldsymbol{x}}} \max _{x_{i} \in \boldsymbol{x}} \mathbf{r}_{i}^{\top} \hat{\mathbf{r}}_{j} R=n1xi∈x∑x^j∈x^maxri⊤r^j;P=m1x^j∈x^∑xi∈xmaxri⊤r^j -
对检索到的句子,按 F 1 = 2 P ⋅ R P + R \mathrm{F} 1=2 \frac{\mathrm{P} \cdot \mathrm{R}}{\mathrm{P}+\mathrm{R}} F1=2P+RP⋅R,进行重新排名
-
将F1得分的前 l l l名串联起来,作为外部语境 x ~ = [ s e p − t o k e n ; x ^ 1 ; ⋯ ; x ^ l ] \tilde{\boldsymbol{x}}=\left[sep _{-}\right.token \left.; \hat{\boldsymbol{x}}_{1} ; \cdots ; \hat{\boldsymbol{x}}_{l}\right] x~=[sep−token;x^1;⋯;x^l],其中
sep_token作为一个句子的分隔符
合作学习
动机
- 由于使用搜索引擎,会存在延迟,难以满足NER模型在线服务对预测速度的要求
- 搜索得到的外部语境通常会很长,这也会大大降低模型的预测速度
目标
**笼统的说:**使用基于检索的输入视图来帮助模型提高准确性
**具体的说:**在两个输入视图之间增加了内部表征或者输出分布的约束,以强制要求两个视图的预测结果应该接近
数学描述:
L
C
L
(
θ
)
=
D
(
h
(
[
x
;
x
~
]
)
,
h
(
[
x
]
)
)
\mathcal{L}_{\mathrm{CL}}(\theta)=D(h([\boldsymbol{x} ; \tilde{\boldsymbol{x}}]), h([\boldsymbol{x}]))
LCL(θ)=D(h([x;x~]),h([x]))
其中,D是一个具有不同输入的函数h之间的距离函数,(衡量他们两者之间距离或者相似性的函数)
显然, h ( [ x ; x ~ ] ) h([\boldsymbol{x} ; \tilde{\boldsymbol{x}}]) h([x;x~])代表的基于检索的视图,其内部表征和标签预测更接近真实结果,所以不对其进行反向传播,
所以在最小化D时,会使得 h ( [ x ] ) h([\boldsymbol{x}]) h([x])越来越接近 h ( [ x ; x ~ ] ) h([\boldsymbol{x} ; \tilde{\boldsymbol{x}}]) h([x;x~])的内部表征或者标签预测结果
两种方法
- 内部表征
健壮的内部表征通常能使任务的准确性提升
-
标签分布
CL强制要求两个输入视图的标签预测是相似的,那么最直接的办法就是直接约束模型预测的标签分布与两个输入视图相似
实验
符号定义
LUKE:CoNNL-03上的SoTa模型
w / o c o n t e x t w/o context w/ocontext: 使用外部语境训练NER,只用了 L N L L − E X T \mathcal{L}_{\mathrm{NLL}-\mathrm{EXT}} LNLL−EXT
w / c o n t e x t w/ context w/context: BaseLine,就是BERT-CRF,只用了 L N L L \mathcal{L}_{\mathrm{NLL}} LNLL,
C L − L 2 CL-L_2 CL−L2: 使用 L N L L ( θ ) + L N L L − E X T ( θ ) + L C L − L 2 ( θ ) \mathcal{L}_{\mathrm{NLL}}(\theta)+\mathcal{L}_{\mathrm{NLL}-\mathrm{EXT}}(\theta)+\mathcal{L}_{{\mathrm{CL}}-L_{2}}(\theta) LNLL(θ)+LNLL−EXT(θ)+LCL−L2(θ)
C L − K L CL-KL CL−KL:使用 L N L L ( θ ) + L N L L − E X T ( θ ) + L C L − K L ( θ ) \mathcal{L}_{\mathrm{NLL}}(\theta)+\mathcal{L}_{\mathrm{NLL}-\mathrm{EXT}}(\theta)+\mathcal{L}_{{\mathrm{CL}}-KL}(\theta) LNLL(θ)+LNLL−EXT(θ)+LCL−KL(θ)
对比SoTa模型
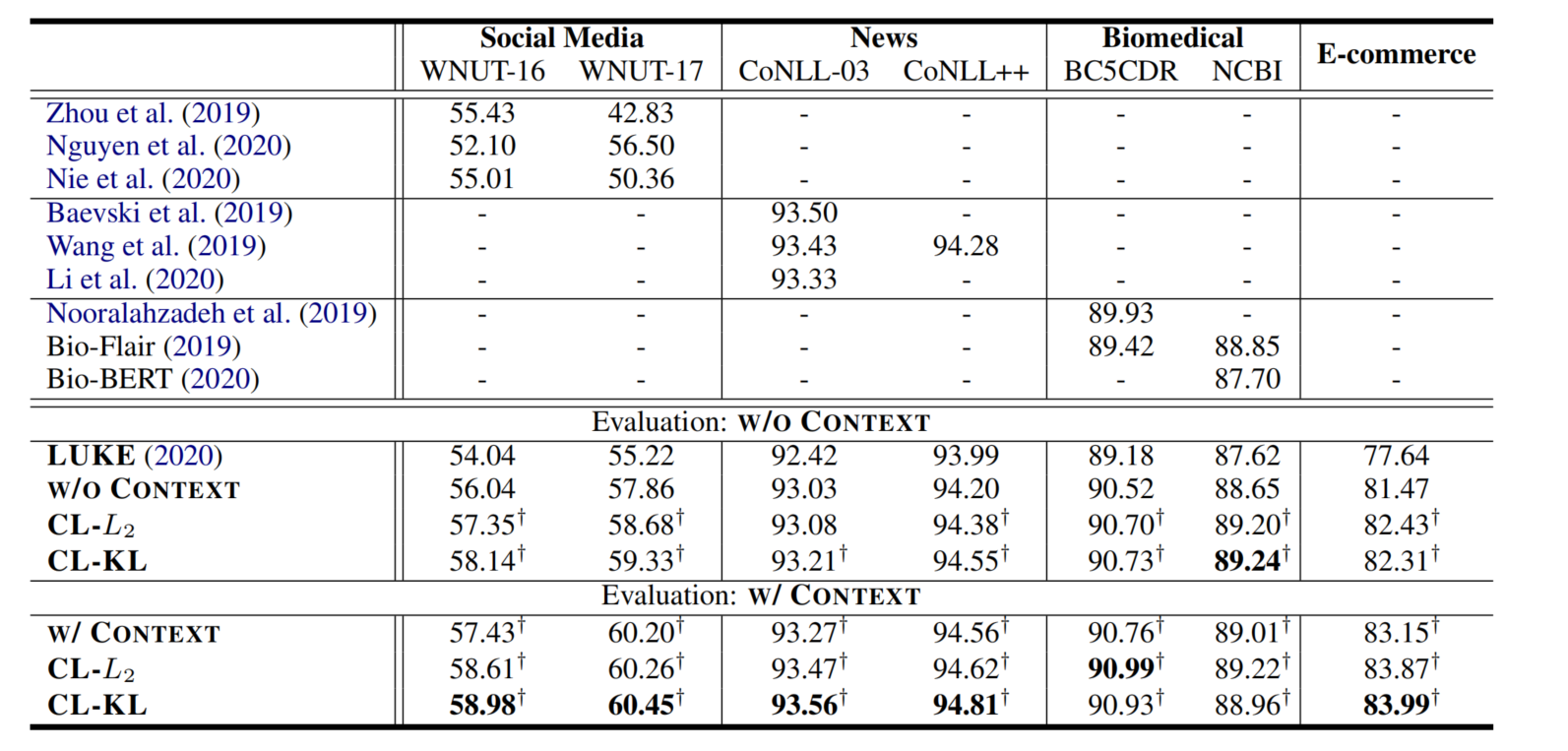
CL-KL在w/o context情况下评估,应该是指,在有外部语境的情况下训练,无外部语境的情况下测试
- 有了外部语境,作者的模型在大多数数据集上都超过了以前最先进的方法
- 有外部语境的结果明显优于没有外部语境的结果,且只有一个例外
- 完爆SoTa模型LUKE
对于作者的方法
-
CL在两个输入视图上的准确性都得到了提升,这说明CL能够有助于模型更好的利用原始信息
以CL-KL为例,CL-KL在w/o context情况下评估测试的, 就是对原始输入视图的准确性进行测试
CL-KL在w/ context情况下评估测试的, 就是对基于检索的输入视图的准确性进行测试
跨领域迁移
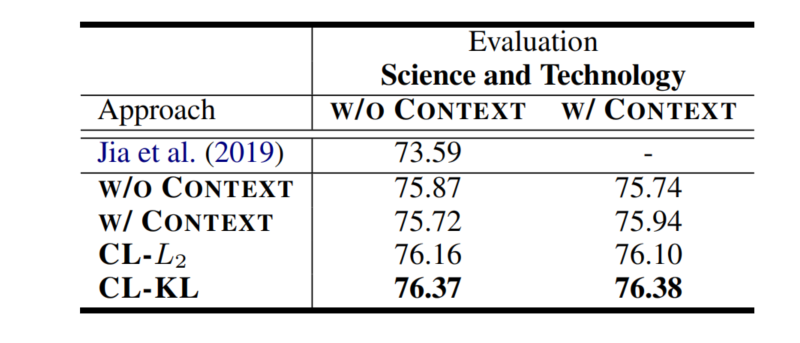
在CoNNL-03上训练模型,在CBS SciTech News dataset上评估准确性
-
测试时,外部语境可以提升已使用外部语境训练的模型的准确性
-
CL方法中两种视图之间的差距被缩小了,这说明CL能够提升两个视图的跨域转移的准确性
-
左右两列可以看作同一模型的两种视图下的结果
-
CL不仅能够提升原始输入视图的效果,还能提升基于检索的视图的效果
老师去教学生,想提高学生水平,在教学生同时,老师水平也提升了
-
半监督的合作学习
合作学习可以利用大量的无标签文本进一步改进。在训练中,联合训练有标签数据和无标签数据,形成一种半监督的训练方式。
在训练过程中,交替使用标注数据的总损失函数和未标注数据的CL损失 L C L ( θ ) = D ( h ( [ x ; x ~ ] ) , h ( [ x ] ) ) \mathcal{L}_{\mathrm{CL}}(\theta)=D(h([\boldsymbol{x} ; \tilde{\boldsymbol{x}}]), h([\boldsymbol{x}])) LCL(θ)=D(h([x;x~]),h([x]))
文中未说明具体怎么训练,猜测一下,应该是先使用标注数据训练,(或者在原来模型基础上),再使用未标注数据训练,用 h [ x u n l a b e l ] h[x^{unlabel}] h[xunlabel]取代 h ( [ x ; x ~ ] ) h([\boldsymbol{x} ; \tilde{\boldsymbol{x}}]) h([x;x~])
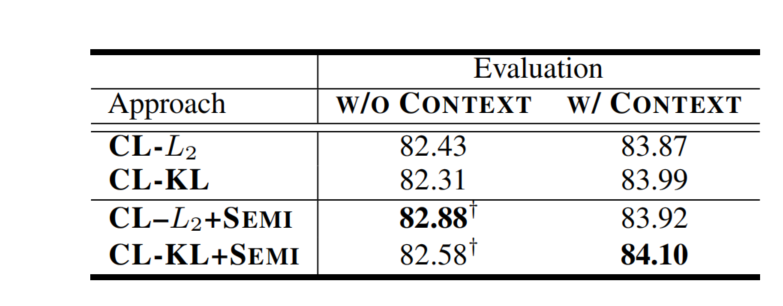
两种视图的准确性都提升了,特别是对于没有外部语境的原始输入视图,这显示了半监督学习在CL中的有效性
消融实验
为验证CL的有效性,设计了三组消融研究
-
用一种视图训练,用另一种视图预测 L N L L ( θ ) 或 L N L L − E X T ( θ ) \mathcal{L}_{\mathrm{NLL}}(\theta)或\mathcal{L}_{\mathrm{NLL}-\mathrm{EXT}}(\theta) LNLL(θ)或LNLL−EXT(θ)
-
没有CL损失情况下,联合训练模型 L N L L ( θ ) + L N L L − E X T ( θ ) \mathcal{L}_{\mathrm{NLL}}(\theta)+\mathcal{L}_{\mathrm{NLL}-\mathrm{EXT}}(\theta) LNLL(θ)+LNLL−EXT(θ)
-
使用两种CL损失之和训练模型 L N L L ( θ ) + L N L L − E X T ( θ ) + L C L − L 2 ( θ ) + L C L − K L ( θ ) \mathcal{L}_{\mathrm{NLL}}(\theta)+\mathcal{L}_{\mathrm{NLL}-\mathrm{EXT}}(\theta)+\mathcal{L}_{{\mathrm{CL}}-L_{2}}(\theta)+\mathcal{L}_{{\mathrm{CL}}-KL}(\theta) LNLL(θ)+LNLL−EXT(θ)+LCL−L2(θ)+LCL−KL(θ)
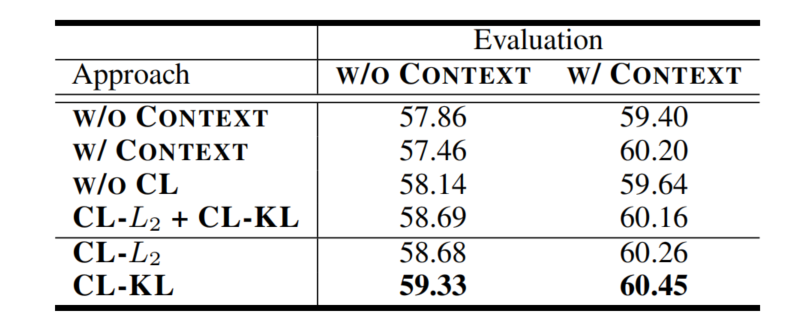
-
即使训练时候没有使用外部语境,预测时使用外部语境也可以提升准确率
-
训练时使用外部语境,但是预测时不使用外部语境,甚至准确率相比baseline还会下降,如果预测时也使用外部语境,符合预期的不错结果
-
不使用CL损失的联合训练,对于预测时没有外部语境的情况下,略有提升,但是如果有外部语境反而下降了
-
两个CL损失函数同时用相比单一CL损失函数,效果并没有提升
可以明显感受到,CL的重要性
总结与思考
总结
-
通过从搜索引擎检索相关语境作为外部语境来提升NER模型的准确性
-
通过合作学习的方法来提升没有外部语境时模型的鲁棒性
贡献
-
提出了一种简单而直接的方法,通过使用搜索引擎检索相关文本来改进输入句子的上下文表示。将检索到的文本与输入的句子一起作为一个新的基于检索的视图。
-
提出合作学习,在统一模型中共同提高两个输入视图的准确性。
-
在5个领域的多个NER数据集中展示了方法的有效性,达到了最先进的精度。通过利用大量未标记的数据,可以进一步提高性能。
思考
作者通过搜索引擎获取外部语境信息的方法,很容易理解其有效性但是最大的收获是合作学习,合作学习的方法不仅能够提升原始输入的准确率,可以提升自身的准确率。本来以为作者是要对模型蒸馏,以提升预测速度,没想到可以使得使用外部语境进行预测时的准确率更高。
















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











