







文章目录
什么是Hadoop
Hadoop是一个适合海量数据的分布式存储和分布式计算的框架。
- 分布式存储,可以简单理解为存储数据的时候,数据不只存在一台机器上面,它会存在多台机器上面。
- 分布式计算简单理解,就是由很多台机器并行处理数据,咱们在写java程序的时候,写的一般都是单机的程序,只在一台机器上运行,这样程序的处理能力是有限的。
Hadoop的作者是Doug Cutting,他在给这个框架起名字的时候是很偶然的,作者的孩子有一个毛绒象玩具,他孩子总是对着这个玩具叫 Hadoop、Hadoop、所以,作者就以此来命名了。
Hadoop发行版介绍
目前Hadoop发行版非常的多,有华为发行版、Intel发行版、Cloudera发行版CDH、Hortonworks
发行版HDP,这些发行版都是基于Apache Hadoop衍生出来的
- Apache是一个IT领域的公益组织,类似于红十字会,Apache这个组织里面的软件都是开源的,大家可以随便使用,随便修改,我们后面学习的99%的大数据技术框架都是Apache开源的
- Cloudera Hadoop(CDH)CDH是一个商业版本,它对官方版本做了一些优化,提供收费技术支持,提供界面操作,方便集群运维管理CDH目前在企业中使用的还是比较多的,虽然CDH是收费的,但是CDH中的一些基本功能是不收费的,可以一直使用,高级功能是需要收费才能使用的,如果不想付费,也能凑合着使用
- HortonWorks(HDP)是开源的,也提供的有界面操作,方便运维管理,一般互联网公司偏向于使用这个注意了,再爆一个料,最新消息,目前HDP已经被CDH收购,都是属于一个公司的产品,后期HDP是否会合并到CDH中,还不得而知,具体还要看这个公司的运营策略了
Hadoop版本演变历史
hadoop1.x:HDFS+MapReduce
hadoop2.x:HDFS+YARN+MapReduce
hadoop3.x:HDFS+YARN+MapReduce

从Hadoop1.x升级到Hadoop2.x,架构发生了比较大的变化,这里面的HDFS是分布式存储,MapRecue是分布式计算,咱们前面说了Hadoop解决了分布式存储和分布式计算的问题,对应的就是这两个模块在Hadoop2.x的架构中,多了一个模块 YARN,这个是一个负责资源管理的模块。
Hadoop的这一步棋走的是最好的,这样自己摇身一变就变成了一个公共的平台,由于它起步早,占有的市场份额也多,后期其它新兴起的计算框架一般都会支持在YARN上面运行,这样Hadoop就保证了自己的地位。
咱们后面要学的Spark、Flink等计算框架都是支持在YARN上面执行的,并且在实际工作中也都是在YARN上面执行。Hadoop3.x的架构并没有发生什么变化,但是它在其他细节方面做了很多优化
Hadoop3.x的细节优化
- 1:最低Java版本要求从Java7变为Java8
- 2:在Hadoop 3中,HDFS支持纠删码,纠删码是一种比副本存储更节省存储空间的数据持久化存储方法,使用这种方法,相同容错的情况下可以比之前节省一半的存储空间
- 3: Hadoop 2中的HDFS最多支持两个NameNode,一主一备,而Hadoop 3中的HDFS支持多个NameNode,一主多备
- 4:MapReduce任务级本地优化,MapReduce添加了映射输出收集器的本地化实现的支持。对于密集型的洗牌操作(shuffle-intensive)jobs,可以带来30%的性能提升
- 5:修改了多重服务的默认端口,Hadoop2中一些服务的端口和Hadoop3中是不一样的
Hadoop三大核心组件介绍
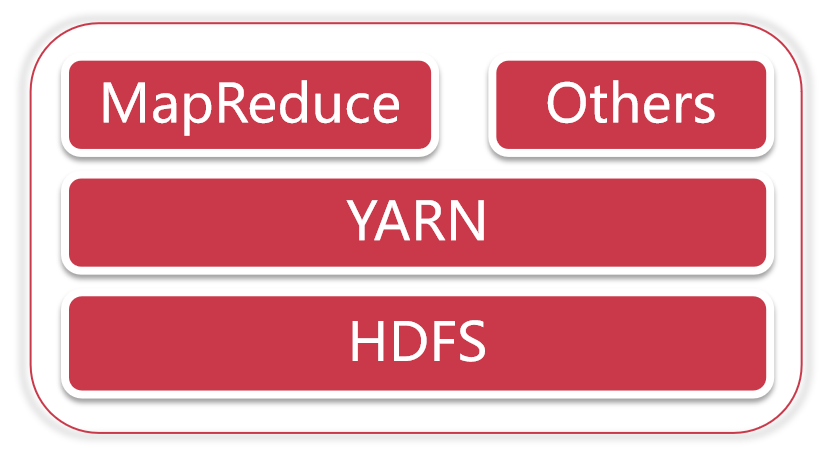
Hadoop主要包含三大组件:HDFS+MapReduce+YARN
- HDFS负责海量数据的分布式存储
- MapReduce是一个计算模型,负责海量数据的分布式计算
- YARN主要负责集群资源的管理和调度
HDFS体系结构
HDFS支持主从结构,主节点称为 NameNode ,是因为主节点上运行的有NameNode进程,
NameNode支持多个,目前我们的集群中只配置了一个
从节点称为 DataNode ,是因为从节点上面运行的有DataNode进程,DataNode支持多个,目前我们的集群中有两个
HDFS中还包含一个 SecondaryNameNode 进程,这个进程从字面意思上看像是第二个NameNode的意思,其实不是

NameNode介绍
NameNode是整个文件系统的管理节点
它主要维护着整个文件系统的文件目录树,文件/目录的信息 和 每个文件对应的数据块列表,并且还负责接收用户的操作请求
- 文件/目录的信息:表示文件/目录的的一些基本信息,所有者 属组 修改时间 文件大小等信息
- 每个文件对应的数据块列表:如果一个文件太大,那么在集群中存储的时候会对文件进行切割,这个时候就类似于会给文件分成一块一块的,存储到不同机器上面。所以HDFS还要记录一下一个文件到底被分了多少块,每一块都在什么地方存储着
- 接收用户的操作请求:其实我们在命令行使用hdfs操作的时候,是需要先和namenode通信 才能开始去操作数据的。
我们可以到集群的9870界面查看一下,随便找一个文件看一下,点击文件名称,可以看到Block information 但是文件太小,只有一个块 叫Block 0

NameNode主要包括以下文件:

这些文件所在的路径是由hdfs-default.xml的dfs.namenode.name.dir属性控制的
hdfs-default.xml文件在哪呢?
它在hadoop-3.2.0\share\hadoop\hdfs\hadoop-hdfs-3.2.0.jar中,这个文件中包含了HDFS相关的所有默认参数,咱们在配置集群的时候会修改一个hdfs-site.xml文件,hdfs-site.xml文件属于hdfs-default.xml的一个扩展,它可以覆盖掉hdfs-default.xml中同名的参数。
看一下这个文件中的dfs.namenode.name.dir属性:
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
<description>Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list
of directories then the name table is replicated in all of the
directories, for redundancy. </description>
</property>
这个属性的值是由hadoop.tmp.dir属性控制的,这个属性的值默认在core-default.xml文件中。
里面有edits文件 和fsimage文件:
fsimage文件有两个文件名相同的,有一个后缀是md5 md5是一种加密算法,这个其实主要是为了做md5校验的,为了保证文件传输的过程中不出问题,相同内容的md5是一样的,所以后期如果我把这个fsimage和对应fsimage.md5发给你 然后你根据md5对fsimage的内容进行加密,获取一个值 和fsimage.md5中的内容进行比较,如果一样,说明你接收到的文件就是完整的。
在这里可以把fsimage 拆开 fs 是文件系统 filesystem image是镜像说明是文件系统镜像,就是给文件照了一个像,把文件的当前信息记录下来我们可以看一下这个文件,这个文件需要使用特殊的命令进行查看-i 输入文件 -o 输出文件
里面最外层是一个fsimage标签,看里面的inode标签,这个inode表示是hdfs中的每一个目录或者文件信息
分析生成的edits.xml文件,这个地方注意,可能有的edits文件生成的edits.xml为空,需要多试几个。
这个edits.xml中可以大致看一下,里面有很多record。每一个record代表不同的操作
我们所有对hdfs的增删改操作都会在edits文件中留下信息,那么fsimage文件中的内容是从哪来的?
其实是这样的,edits文件会定期合并到fsimage文件中。
secondarynamenode
这个进程就是负责定期的把edits中的内容合并到fsimage中。他只做一件事,这是一个单独的进程,在实际工作中部署的时候,也需要部署到一个单独的节点上面
总结
- fsimage: 元数据镜像文件,存储某一时刻NameNode内存中的元数据信息,就类似是定时做了一个快照操作。【这里的元数据信息是指文件目录树、文件/目录的信息、每个文件对应的数据块列表】
- edits: 操作日志文件【事务文件】,这里面会实时记录用户的所有操作
- seen_txid: 是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,顺序从头跑edits_0000001~到seen_txid的数字。如果根据对应的seen_txid无法加载到对应的文件,NameNode进程将不会完成启动以保护数据一致性。
- VERSION:保存了集群的版本信息
SecondaryNameNode介绍
SecondaryNameNode主要负责定期的把edits文件中的内容合并到fsimage中
这个合并操作称为checkpoint,在合并的时候会对edits中的内容进行转换,生成新的内容保存到fsimage文件中。
注意:在NameNode的HA架构中没有SecondaryNameNode进程,文件合并操作会由standby NameNode负责实现
所以在Hadoop集群中,SecondaryNameNode进程并不是必须的。
DataNode介绍
DataNode是提供真实文件数据的存储服务
针对datanode主要掌握两个概念,一个是block,一个是replication
首先是block
- HDFS会按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block,HDFS默认Block大小是 128MB
- Blokc块是HDFS读写数据的基本单位,不管你的文件是文本文件 还是视频 或者音频文件,针对hdfs而言都是字节。
我们之前上传的一个user.txt文件,他的block信息可以在fsimage文件中看到,也可以在hdfs webui上面看到, 里面有block的id信息,并且也会显示这个数据在哪个节点上面

这里显示在bigdata02和bigdata03上面都有,那我们过去看一下,datanode中数据的具体存储位置是由dfs.datanode.data.dir来控制的,通过查询hdfs-default.xml可以知道。注意:这个block中的内容可能只是文件的一部分,如果你的文件较大的话,就会分为多个block存储,默认 hadoop3中一个block的大小为128M。根据字节进行截取,截取到128M就是一个block。如果文件大小没有默认的block块大,那最终就只有一个block。
假设我们上传了两个10M的文件 又上传了一个200M的文件
问1:会产生多少个block块? 4个
问2:在hdfs中会显示几个文件?3个
下面看一下副本,副本表示数据有多少个备份
我们现在的集群有两个从节点,所以最多可以有2个备份,这个是在hdfs-site.xml中进行配置的,
dfs.replication 默认这个参数的配置是3。表示会有3个副本。副本只有一个作用就是保证数据安全
DataNode总结
block块存放在哪些datanode上,只有datanode自己知道,当集群启动的时候,datanode会扫描自己节点上面的所有block块信息,然后把节点和这个节点上的所有block块信息告诉给namenode。这个关系是每次重启集群都会动态加载的【这个其实就是集群为什么数据越多,启动越慢的原因】
咱们之前说的fsimage(edits)文件中保存的有文件和block块之间的信息。
这里说的是block块和节点之间的关系,这两块关联在一起之后,就可以根据文件找到对应的block块,再根据block块找到对应的datanode节点,这样就真正找到了数据。
所以说 其实namenode中不仅维护了文件和block块的信息 还维护了block块和所在的datanode节点的信息。
可以理解为namenode维护了两份关系:
- 第一份关系:file 与block list的关系,对应的关系信息存储在fsimage和edits文件中,当NameNode启动的时候会把文件中的元数据信息加载到内存中
- 第二份关系:datanode与block的关系,对应的关系主要在集群启动的时候保存在内存中,当DataNode启动时会把当前节点上的Block信息和节点信息上报给NameNode
注意:
我们说了NameNode启动的时候会把文件中的元数据信息加载到内存中,然后每一个文件的元数据信息会占用150字节的内存空间,这个是恒定的,和文件大小没有关系,咱们前面在介绍HDFS的时候说过,HDFS不适合存储小文件,其实主要原因就在这里,不管是大文件还是小文件,一个文件的元数据信息在NameNode中都会占用150字节,NameNode节点的内存是有限的,所以它的存储能力也是有限的,如果我们存储了一堆都是几KB的小文件,最后发现NameNode的内存占满了,确实存储了很多文件,但是文件的总体大小却很小,这样就失去了HDFS存在的价值。
我们前面说了namenode不要随便格式化,因为格式化了以后VERSION里面的clusterID会变,但是datanode的VERSION中的clusterID并没有变,所以就对应不上了。
咱们之前说过如果确实要重新格式化的话需要把/data/hadoop_repo数据目录下的内容都清空,全部都重新生成是可以的。
HDFS主要是负责存储海量数据的,如果只是把数据存储起来,除了浪费磁盘空间,是没有任何意义的,我们把数据存储起来之后是希望能从这些海量数据中分析出来一些有价值的内容,这个时候就需要有一个比较厉害的计算框架,来快速计算这一批海量数据,所以MapReduce应运而生了。
MapReduce介绍
举个栗子
计算扑克牌中的黑桃个数?
就是我们平时打牌时用的扑克牌,现在呢,有一摞牌,我想知道这摞牌中有多少张黑桃
最直接的方式是一张一张检查并且统计出有多少张是黑桃,但是这种方式的效率比较低,如果说这一摞牌
只有几十张也就无所谓了,如果这一摞拍有上千张呢?你一张一张去检查还不疯了?
这个时候我们可以使用MapReduce的计算方法
- 第一步:把这摞牌分配给在座的所有玩家
- 第二步:让每个玩家查一下自己手中的牌有多少张是黑桃,然后把这个数目汇报给你
- 第三步:你把所有玩家告诉你的数字加起来,得到最终的结果
之前是一张一张的串行计算,现在使用mapreduce是把数据分配给多个人,并行计算,每一个人获得一个局部聚合的临时结果,最终再统一汇总一下。
这样就可以快速得到答案了,这其实就是MapReduce的计算思想。
分布式计算介绍
移动数据是传统的计算方式,现在的一种新思路是移动计算。

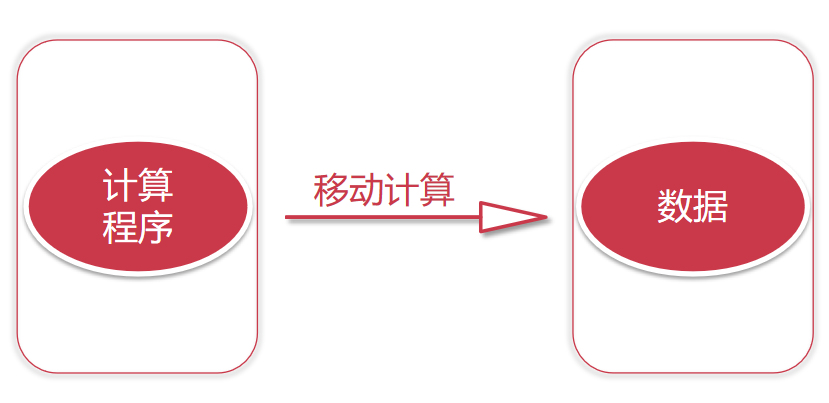
如果我们数据量很大的话,我们的数据肯定是由很多个节点存储的,这个时候我们就可以把我们的程序代码拷贝到对应的节点上面去执行,程序代码都是很小的,一般也就几十KB或者几百KB,加上外部依赖包,最大也就几兆 ,甚至几十兆,但是我们需要计算的数据动辄都是几十G、几百G,他们两个之间的差距不是一星半点.
这样我们的代码就可以在每个数据节点上面执行了,但是这个代码只能计算当前节点上的数据的,如果我们想要统计数据的总行数,这里每个数据节点上的代码只能计算当前节点上数据的行数,所以还的有一个汇总程序,这样每个数据节点上面计算的临时结果就可以通过汇总程序得到最终的结果了。此时汇总程序需要传递的数据量就很小了,只需要接收一个数字即可。这个计算过程就是分布式计算,这个步骤分为两步。
- 第一步:对每个节点上面的数据进行局部计算
- 第二步:对每个节点上面计算的局部结果进行最终全局汇总

MapReduce原理剖析
MapReduce是一种分布式计算模型,是Google提出来的,主要用于搜索领域,解决海量数据的计算问题.
MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,
- Map阶段是一个独立的程序,在很多个节点同时运行,每个节点处理一部分数据。
- Reduce阶段也是一个独立的程序,可以在一个或者多个节点同时运行,每个节点处理一部分数据【在这我们先把reduce理解为一个单独的聚合程序即可】。
在这map就是对数据进行局部汇总,reduce就是对局部数据进行最终汇总。
结合到我们前面分析的统计黑桃的例子中,这里的map阶段就是指每个人统计自己手里的黑桃的个数,reduce就是对每个人统计的黑桃个数进行最终汇总

这是一个Hadoop集群,一共5个节点
一个主节点,四个从节点
这里面我们只列出来了HDFS相关的进程信息
假设我们有一个512M的文件,这个文件会产生4个block块,假设这4个block块正好分别存储到了集群的4个节点上,我们的计算程序会被分发到每一个数据所在的节点,然后开始执行计算,在map阶段,针对每一个block块对应的数据都会产生一个map任务(这个map任务其实就是执行这个计算程序的),在这里也就意味着会产生4个map任务并行执行,4个map阶段都执行完毕以后,会执行reduce阶段,在reduce阶段中会对这4个map任务的输出数据进行汇总统计,得到最终的结果。
下面看一个官方的mapreduce原理图

左下角是一个文件,文件最下面是几个block块,说明这个文件被切分成了这几个block块,文件上面是一些split,注意,咱们前面说的每个block产生一个map任务,其实这是不严谨的,其实严谨一点来说的话应该是一个split产生一个map任务。
那这里的block和split之间有什么关系吗?
我们来分析一下,block块是文件的物理切分,在磁盘上是真实存在的。是对文件的真正切分
而split是逻辑划分,不是对文件真正的切分,默认情况下我们可以认为一个split的大小和一个block的大小是一样的,所以实际上是一个split会产生一个map task
这里面的map Task就是咱们前面说的map任务,看后面有一个reduce Task,reduce会把结果数据输出到hdfs上,有几个reduce任务就会产生几个文件,这里有三个reduce任务,就产生了3个文件,咱们前面分析的案例中只有一个reduce任务做全局汇总
注意看map的输入 输出 reduce的输入 输出map的输入是k1,v1 输出是k2,v2
reduce的输入是k2,v2 输出是k3,v3 都是键值对的形式。
在这注意一下,为什么在这是1,2,3呢? 这个主要是为了区分数据,方便理解,没有其它含义,这是我们人为定义的。
MapReduce之Map阶段
mapreduce主要分为两大步骤 map和reduce,map和reduce在代码层面对应的就是两个类,map对应的是mapper类,reduce对应的是reducer类,下面我们就来根据一个案例具体分析一下这两个步骤
假设我们有一个文件,文件里面有两行内容
第一行是hello you
第二行是hello me
我们想统计文件中每个单词出现的总次数
首先是map阶段
1)第一步:框架会把输入文件(夹)划分为很多InputSplit,这里的inputsplit就是前面我们所说的split【对文件进行逻辑划分产生的】,默认情况下,每个HDFS的Block对应一个InputSplit。再通过RecordReader类,把每个InputSplit解析成一个一个的<k1,v1>。默认情况下,每一行数据,都会被解析成一个<k1,v1>
这里的k1是指每一行的起始偏移量,v1代表的是那一行内容,所以,针对文件中的数据,经过map处理之后的结果是这样的
<0,hello you>
<10,hello me>
注意:map第一次执行会产生<0,hello you>,第二次执行会产生<10,hello me>,并不是执行一次就获取到这两行结果了,因为每次只会读取一行数据,我在这里只是把这两行执行的最终结果都列出来了
2)第二步:框架调用Mapper类中的map(…)函数,map函数的输入是<k1,v1>,输出是<k2,v2>。一个InputSplit对应一个map task。程序员需要自己覆盖Mapper类中的map函数,实现具体的业务逻辑。
因为我们需要统计文件中每个单词出现的总次数,所以需要先把每一行内容中的单词切开,然后记录出现次数为1,这个逻辑就需要我们在map函数中实现了。那针对<0,hello you>执行这个逻辑之后的结果就是
<hello,1>
<you,1>
针对<10,hello me>执行这个逻辑之后的结果是
<hello,1>
<me,1>
3)第三步:框架对map函数输出的<k2,v2>进行分区。不同分区中的<k2,v2>由不同的reduce task处理,默认只有1个分区,所以所有的数据都在一个分区,最后只会产生一个reduce task。
经过这个步骤之后,数据没什么变化,如果有多个分区的话,需要把这些数据根据分区规则分开,在这里默认只有1个分区。
<hello,1>
<you,1>
<hello,1>
<me,1>
咱们在这所说的单词计数,其实就是把每个单词出现的次数进行汇总即可,需要进行全局的汇总,不需要进行分区,所以一个redeuce任务就可以搞定,
如果你的业务逻辑比较复杂,需要进行分区,那么就会产生多个reduce任务了,
那么这个时候,map任务输出的数据到底给哪个reduce使用?这个就需要划分一下,要不然就乱套了。假设有两个reduce,map的输出到底给哪个reduce,如何分配,这是一个问题。
这个问题,由分区来完成。map输出的那些数据到底给哪个reduce使用,这个就是分区干的事了。
4)第四步:框架对每个分区中的数据,都会按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。先按照k2排序
<hello,1>
<hello,1>
<me,1>
<you,1>
然后按照k2进行分组,把相同k2的v2分成一个组
<hello,{1,1}>
<me,{1}>
<you,{1}>
5)第五步:在map阶段,框架可以选择执行Combiner过程
Combiner可以翻译为规约,规约是什么意思呢? 在刚才的例子中,咱们最终是要在reduce端计算单词出现的总次数的,所以其实是可以在map端提前执行reduce的计算逻辑,先对在map端对单词出现的次数进行局部求和操作,这样就可以减少map端到reduce端数据传输的大小,这就是规约的好处,当然了,并不是所有场景都可以使用规约,针对求平均值之类的操作就不能使用规约了,否则最终计算的结果就不准确了。Combiner一个可选步骤,默认这个步骤是不执行的。
6)第六步:框架会把map task输出的<k2,v2>写入到linux 的磁盘文件中
<hello,{1,1}>
<me,{1}>
<you,{1}>
至此,整个map阶段执行结束
最后注意一点:
MapReduce程序是由map和reduce这两个阶段组成的,但是reduce阶段不是必须的,也就是说有的
mapreduce任务只有map阶段,为什么会有这种任务呢?
是这样的,咱们前面说过,其实reduce主要是做最终聚合的,如果我们这个需求是不需要聚合操作,直接对数据做过滤处理就行了,那也就意味着数据经过map阶段处理完就结束了,所以如果reduce阶段不存在的话,map的结果是可以直接保存到HDFS中的
注意,如果没有reduce阶段,其实map阶段只需要执行到第二步就可以,第二步执行完成以后,结果就可以直接输出到HDFS了。
MapReduce之Reduce阶段
1)第一步:框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程称作shuffle
针对我们这个需求,只有一个分区,所以把数据拷贝到reduce端之后还是老样子
<hello,{1,1}>
<me,{1}>
<you,{1}>
2)第二步:框架对reduce端接收的相同分区的<k2,v2>数据进行合并、排序、分组。
reduce端接收到的是多个map的输出,对多个map任务中相同分区的数据进行合并 排序 分组
注意,之前在map中已经做了排序 分组,这边也做这些操作 重复吗?
不重复,因为map端是局部的操作 reduce端是全局的操作
之前是每个map任务内进行排序,是有序的,但是多个map任务之间就是无序的了。
不过针对我们这个需求只有一个map任务一个分区,所以最终的结果还是老样子
<hello,{1,1}>
<me,{1}>
<you,{1}>
3) 第三步:框架调用Reducer类中的reduce方法,reduce方法的输入是<k2,{v2}>,输出是<k3,v3>。一个<k2,{v2}>调用一次reduce函数。程序员需要覆盖reduce函数,实现具体的业务逻辑。
那我们在这里就需要在reduce函数中实现最终的聚合计算操作了,将相同k2的{v2}累加求和,然后再转化为k3,v3写出去,在这里最终会调用三次reduce函数
<hello,2>
<me,1>
<you,1>
第四步:框架把reduce的输出结果保存到HDFS中。
hello 2
me 1
you 1
至此,整个reduce阶段结束。
实战WordCount分析
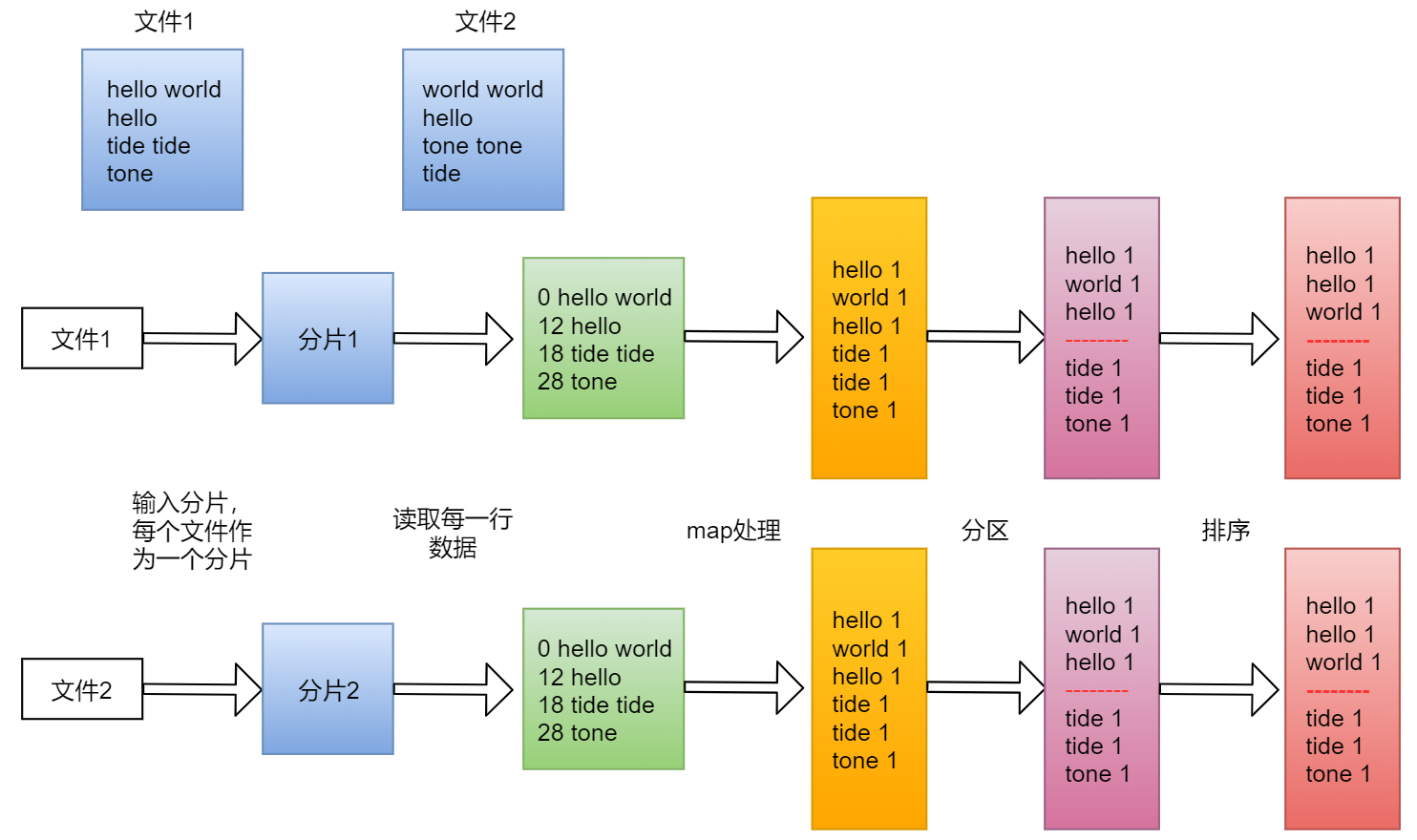
重新梳理一下单词计数的执行流程

上面的是单个文件的执行流程,有一些现象看起来还是不明显
下面我们来看一个两个文件的执行流程

实战:WordCount案例开发
前面我们通过理论层面详细分析了单词计数的执行流程,下面我们就来实际上手操作一下。
大致流程如下:
- 第一步:开发Map阶段代码
- 第二步:开发Reduce阶段代码
- 第三步:组装Job
在idea中创建WordCountJob类
添加注释,梳理一下需求:
需求:读取hdfs上的hello.txt文件,计算文件中每个单词出现的总次数
hello.txt文件内容如下:
hello you
hello me
最终需要的结果形式如下:
hello 2
me 1
you 1
先创建map阶段的代码,在这里需要自定义一个mapper类,继承框架中的Mapper类
/**
* 创建自定义mapper类
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWr
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// k1代表的是每一行的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word:words) {
// 把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
// 把<k2,v2>写出去
context.write(k2,v2);
}
}
然后是reduce阶段的代码,需要自定义一个reducer类,继承框架中的reducer。
/**
* 创建自定义的reducer类
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongW
/**
* 针对v2s的数据进行累加求和 并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context co
throws IOException, InterruptedException {
// 创建一个sum变量,保存v2s的和
long sum = 0L;
for (LongWritable v2 : v2s) {
sum += v2.get();
}
// 组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
// 把结果写出去
context.write(k3,v3);
}
}
最终组装job,job等于map+reduce
public class WordCountJob {
/**
* 组装job=map+reduce
* @param args
*/
public static void main(String[] args) {
try {
if(args.length!=2){
// 如果传递的参数不够,程序直接退出
System.exit(100);
}
// job需要的配置参数
Configuration conf = new Configuration();
// 创建一个job
Job job = Job.getInstance(conf);
// 注意:这一行必须设置,否则在集群中执行的是找不到WordCountJob这个类
job.setJarByClass(WordCountJob.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 指定map相关的代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
// 指定reduce相关的代码
job.setReducerClass(MyReducer.class);
// 指定k3的类型
job.setOutputKeyClass(Text.class);
// 指定v3的类型
job.setOutputValueClass(LongWritable.class);
// 提交job
job.waitForCompletion(true);
}catch (Exception e){
e.printStackTrace();
}
}
}
现在代码开发完毕了,现在我们是把自定义的mapper类和reducer类都放到了这个WordCountJob类
中,主要是为了在学习阶段看起来清晰一些,所有的代码都在一个类中,好找,其实我们完全可以把自定义的mapper类和reducer类单独提出去,定义为单独的类,是没有什么区别的。
ok,那代码开发好了以后想要执行,我们需要打jar包上传到集群上去执行,这个时候需要在pom文件中添加maven的编译打包插件。
<build>
<plugins>
<!-- compiler插件, 设定JDK版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
注意了,这些添加完以后还有一个地方需要修改,需要在pom中的hadoop-client和log4j依赖中增加
scope属性,值为provided,表示只在编译的时候使用这个依赖,在执行以及打包的时候都不使用,因为hadoop-client和log4j依赖在集群中都是有的,所以在打jar包的时候就不需要打进去了,如果我们使用到了集群中没有的第三方依赖包就不需要增加这个provided属性了,不增加provided就可以把对应的第三方依赖打进jar包里面了。
接下来就可以向集群提交MapReduce任务了
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCount
- hadoop:表示使用hadoop脚本提交任务,其实在这里使用yarn脚本也是可以的,从hadoop2开始支持使用yarn,不过也兼容hadoop1,也继续支持使用hadoop脚本,所以在这里使用哪个都可以,具体就看你个人的喜好了,我是习惯于使用hadoop脚本
- jar:表示执行jar包
- db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar:指定具体的jar包路径信息
- com.imooc.mr.WordCountJob:指定要执行的mapreduce代码的全路径
- /test/hello.txt:指定mapreduce接收到的第一个参数,代表的是输入路径,这里的输入路径可以直接指定hello.txt的路径,也可以直接指定它的父目录,因为它的父目录里面也没有其它无关的文件,如果指定目录的话就意味着hdfs会读取这个目录下所有的文件,所以后期如果我们需要处理一批文件,那就可以把他们放到同一个目录里面,直接指定目录即可。
- /out:指定mapreduce接收到的第二个参数,代表的是输出目录,这里的输出目录必须是不存在的,MapReduce程序在执行之前会检测这个输出目录,如果存在会报错,因为它每次执行任务都需要一个新的输出目录来存储结果数据
MapReduce任务日志查看
如果想要查看mapreduce任务执行过程产生的日志信息怎么办呢?
是不是在提交任务的时候直接在这个控制台上就能看到了?先不要着急,我们先在代码中增加一些日志信息,在实际工作中做调试的时候这个也是很有必要的
在自定义mapper类的map函数中增加一个输出,将k1,v1的值打印出来
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
// k1代表的是每一行的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word:words) {
// 把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
System.out.println("k2:"+word+"...v2:1");
// 把<k2,v2>写出去
context.write(k2,v2);
}
}
在自定义reducer类中的reduce方法中增加一个输出,将k2,v2和k3,v3的值打印出来
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
// 创建一个sum变量,保存v2s的和
long sum = 0L;
for (LongWritable v2 : v2s) {
//输出k2,v2的值
System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
// 组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把结果写出去
context.write(k3,v3);
}
重新在windows机器上打jar包,并把新的jar包上传到bigdata01机器的/data/soft/hadoop-3.2.0目录中重新向集群提交任务,注意,针对输出目录,要么换一个新的不存在的目录,要么把之前的out目录删掉
等待任务执行结束,我们发现在控制台上是看不到任务中的日志信息的,为什么呢?因为我们在这相当于是通过一个客户端把任务提交到集群里面去执行了,所以日志是存在在集群里面的。想要查看需要需要到一个特殊的地方查看这些日志信息
先进入到yarn的web界面,访问8088端口,点击对应任务的history链接
http://bigdata01:8088/
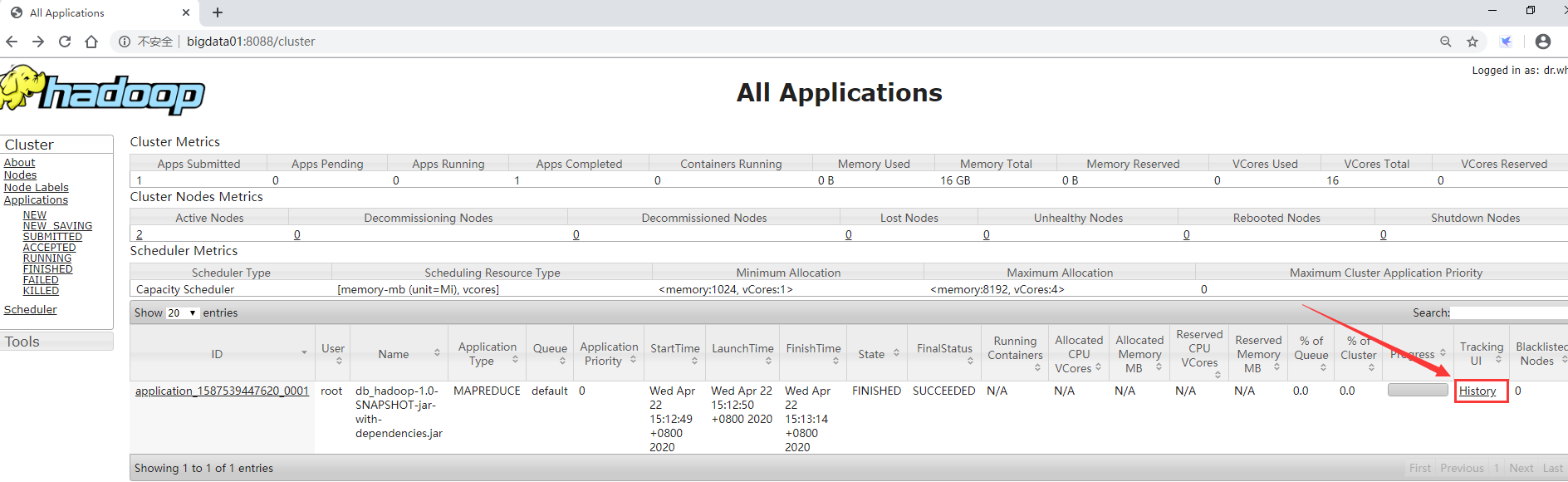
在这里我们发现这个链接是打不来的,
这里有两个原因,第一个原因是没有windows的hosts文件中没有配置bigdata02和bigdata03这两个主机名和ip的映射关系,先去把这两个主机名配置到hosts文件里面,之前的bigdata01已经配置进去了。
第二个原因就是这里必须要启动historyserver进程才可以,并且还要开启日志聚合功能,才能在web界面上直接查看任务对应的日志信息,因为默认情况下任务的日志是散落在nodemanager节点上的,想要查看需要找到对应的nodemanager节点上去查看,这样就很不方便,通过日志聚合功能我们可以把之前本来散落在nodemanager节点上的日志统一收集到hdfs上的指定目录中,这样就可以在yarn的web界面中直接查看了.
那我们就来开启日志聚合功能。开启日志聚合功能需要修改yarn-site.xml的配置,增加
yarn.log-aggregation-enable和yarn.log.server.url这两个参数
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistory/logs/</value>
</property>
注意:修改这个配置想要生效需要重启集群。
启动historyserver进程,需要在集群的所有节点上都启动这个进程
[root@bigdata01 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigdata01 hadoop-3.2.0]# jps
4232 SecondaryNameNode
5192 JobHistoryServer
4473 ResourceManager
3966 NameNode
5231 Jps
[root@bigdata02 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigdata02 hadoop-3.2.0]# jps
2904 Jps
2523 NodeManager
2844 JobHistoryServer
2415 DataNode
[root@bigdata03 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigdata03 hadoop-3.2.0]# jps
3138 JobHistoryServer
2678 NodeManager
2570 DataNode
3198 Jps
重新再提交mapreduce任务
此时再进入yarn的8088界面,点击任务对应的history链接就可以打开了
停止Hadoop集群中的任务
如果一个mapreduce任务处理的数据量比较大的话,这个任务会执行很长时间,可能几十分钟或者几个小时都有可能,假设一个场景,任务执行了一半了我们发现我们的代码写的有问题,需要修改代码重新提交执行,这个时候之前的任务就没有必要再执行了,没有任何意义了,最终的结果肯定是错误的,所以我们就想把它停掉,要不然会额外浪费集群的资源,如何停止呢?
我在提交任务的窗口中按ctrl+c是不是就可以停止?
注意了,不是这样的,我们前面说过,这个任务是提交到集群执行的,你在提交任务的窗口中执行ctrl+c 对已经提交到集群中的任务是没有任何影响的。
我们可以验证一下,执行ctrl+c之后你再到yarn的8088界面查看,会发现任务依然存在。
所以需要使用hadoop集群的命令去停止正在运行的任务
使用yarn application -kill命令,后面指定任务id即可
[root@bigdata01 hadoop-3.2.0]# yarn application -kill application_15877135678
MapReduce程序扩展
MapReduce任务是由map阶段和reduce阶段组成的
但是我们也说过,reduce阶段不是必须的,那也就意味着MapReduce程序可以只包含map阶段。
什么场景下会只需要map阶段呢?
当数据只需要进行普通的过滤、解析等操作,不需要进行聚合,这个时候就不需要使用reduce阶段了
在代码层面该如何设置呢?
很简单,在组装Job的时候设置reduce的task数目为0就可以了。并且Reduce代码也不需要写了。
package com.imooc.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 只有Map阶段,不包含Reduce阶段
*/
public class WordCountJobNoReduce {
/**
* 创建自定义mapper类
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWr
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
// k1代表的是每一行的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word:words) {
// 把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
// 把<k2,v2>写出去
context.write(k2,v2);
}
}
}
public static void main(String[] args) {
try {
if(args.length!=2){
// 如果传递的参数不够,程序直接退出
System.exit(100);
}
// job需要的配置参数
Configuration conf = new Configuration();
// 创建一个job
Job job = Job.getInstance(conf);
// 注意:这一行必须设置,否则在集群中执行的是找不到WordCountJob这个类
job.setJarByClass(WordCountJobNoReduce.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 指定map相关的代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//禁用reduce阶段
job.setNumReduceTasks(0);
// 提交job
job.waitForCompletion(true);
}catch (Exception e){
e.printStackTrace();
}
}
}
重新编译,打包,上传到bigdata01机器上
然后将最新的任务提交到集群上面,注意修改入口类全类名
[root@bigdata01 hadoop-3.2.0]# hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dep
2020-04-25 00:24:06,939 INFO mapreduce.Job: map 0% reduce 0%
2020-04-25 00:24:15,107 INFO mapreduce.Job: map 100% reduce 0%
2020-04-25 00:24:15,120 INFO mapreduce.Job: Job job_1587745397573_0001 complet
这里发现map执行到100%以后任务就执行成功了,reduce还是0%,因为就没有reduce阶段了。
Shuffle过程详解
shuffer是一个网络拷贝的过程,是指通过网络把数据从map端拷贝到reduce端的过程,下面我们来详细分析一下这个过程。

首先看map阶段,最左边有一个inputsplit,最终会产生一个map任务,map任务在执行的时候会把
k1,v1转化为k2,v2,这些数据会先临时存储到一个内存缓冲区中,这个内存缓冲区的大小默认是100M(io.sort.mb属性),当达到内存缓冲区大小的80%(io.sort.spill.percent)也就是80M的时候,会把内存中的数据溢写到本地磁盘中(mapred.local.dir),一直到map把所有的数据都计算完,最后会把内存缓冲区中的数据一次性全部刷新到本地磁盘文件中,在这个图里面表示产生了3个临时文件,每个临时文件中有3个分区,这是由于map阶段中对数据做了分区,所以数据在存储的时候,在每个临时文件中也划分为了3块,最后需要对这些临时文件进行合并,合并为一个大文件,因为一个map任务最终只会产生一个文件,这个合并之后的文件也是有3个分区的,这3个分区的数据会被shuffle线程分别拷贝到三个不同的reduce节点,图里面只显示了一个reduce节点,下面还有两个没有显示。不同map任务中的相同分区的数据会在同一个reduce节点进行合并,合并以后会执行reduce的功能,最终产生结果数据。
在这里shuffle其实是横跨map端和reduce端的,它主要是负责把map端产生的数据通过网络拷贝到
reduce阶段进行统一聚合计算。
Hadoop中序列化机制
在开发MapReduce程序的时候使用到了LongWritable和Text这些数据类型,这些数据类型对应的是Java中的Long和String,那MapReduce为什么不直接使用Java中的这些数据类型呢?那肯定是嫌弃
Java中的这些数据类型使用起来不爽,那具体不爽在什么地方呢?
这个其实就涉及到序列化这个知识点了,下面我们来分析一下,来看这张图,
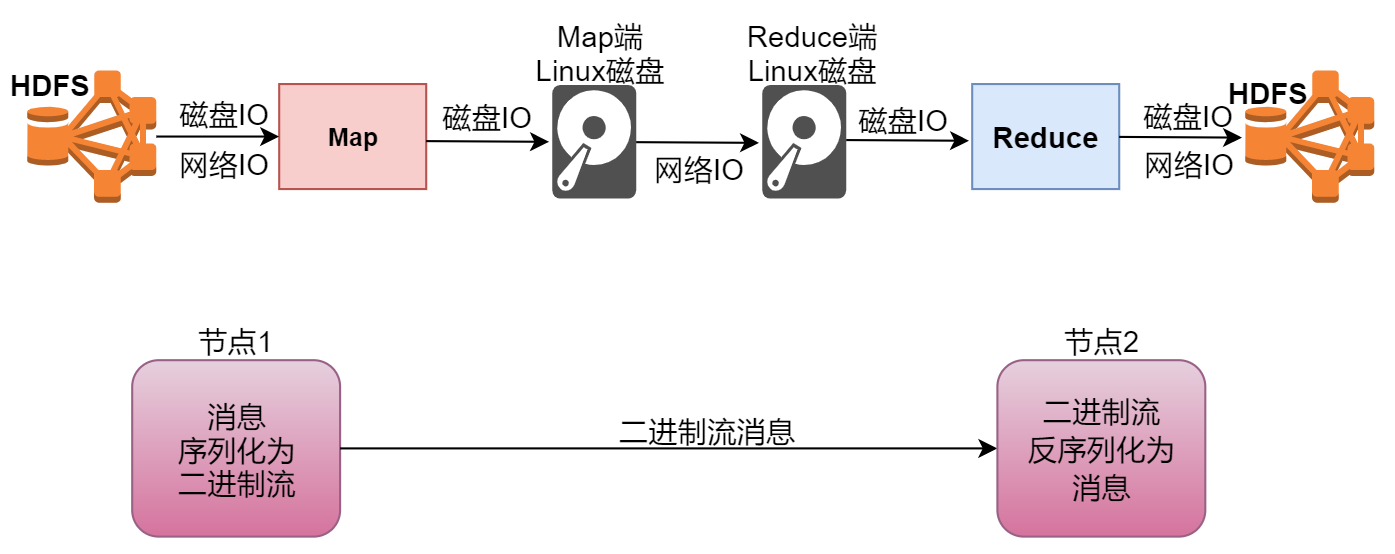
我们的map阶段在读取数据的是需要从hdfs中读取的,这里面需要经过磁盘IO和网络IO,不过正常情况下map任务会执行本地计算,也就是map任务会被分发到数据所在的节点进行计算,这个时候,网络io几乎就没有了,就剩下了磁盘io,再往后面看,map阶段执行完了以后,数据会被写入到本地磁盘文件,这个时候也需要经过磁盘io,后面的shuffle拷贝数据其实也需要先经过磁盘io把数据从本地磁盘读出来再通过网络发送到reduce节点,再写入reduce节点的本地磁盘,然后reduce阶段在执行的时候会经过磁盘io读取本地文件中的数据,计算完成以后还会经过磁盘io和网络io把数据写入到hdfs中。
经过我们刚才的分析,其实在这里面占得比重最高的是磁盘io,所以说影响mapreduce任务执行效率的主要原因就是磁盘io,如果想要提高任务执行效率,就需要从这方面着手分析。
当程序在向磁盘中写数据以及从磁盘中读取数据的时候会对数据进行序列化和反序列化,磁盘io这些步骤我们省略不了,但是我们可以从序列化和反序列化这一块来着手做一些优化,
首先我们分析一下序列化和反序列化,看这个图,当我们想把内存中的数据写入到文件中的时候,会对数据序列化,然后再写入,这个序列化其实就是把内存中的对象信息转成二进制的形式,方便存储到文件中,默认java中的序列化会把对象及其父类、超类的整个继承体系信息都保存下来,这样存储的信息太大了,就会导致写入文件的信息过大,这样写入是会额外消耗性能的。
反序列化也是一样,reduce端想把文件中的对象信息加载到内存中,如果文件很大,在加载的时候也会额外消耗很多性能,所以如果我们把对象存储的信息尽量精简,那么就可以提高数据写入和读取消耗的性能。
基于此,hadoop官方实现了自己的序列化和反序列化机制,没有使用java中的序列化机制,所以
hadoop中的数据类型没有沿用java中的数据类型,而是自己单独设计了一些writable的实现了,例如、longwritable、text等
那我们来看一下Hadoop中提供的常用的基本数据类型的序列化类
Java基本类型 Writable 序列化大小(字节)
布尔型(boolean) BooleanWritable 1
字节型(byte) ByteWritable 1
整型(int) IntWritable 4
VIntWritable 1~5
浮点型(float) FloatWritable 4
长整型(long) LongWritable 8
VLongWritable 1~9
双精度浮点型(double) DoubleWritable 8
在这需要注意一下
Text等价于java.lang.String的Writable,针对UTF-8序列NullWritable是单例,获取实例使用NullWritable.get()
那下面我们来总结一下hadoop自己实现的序列化有什么特点
- 紧凑: 高效使用存储空间
- 快速: 读写数据的额外开销小
- 可扩展: 可透明地读取老格式的数据
- 互操作: 支持多语言的交互
对应的我们也对java中序列化的不足之后做了一个总结
- 不精简,附加信息多,不太适合随机访问
- 存储空间大,递归地输出类的超类描述直到不再有超类
Java中的序列化和Hadoop中的序列化,其实最主要的区别就是针对相同的数据,Java中的序列化会占用较大的存储空间,而Hadoop中的序列化可以节省很多存储空间,这样在海量数据计算的场景下,可以减少数据传输的大小,极大的提高计算效率。
InputFormat分析
Hadoop中有一个抽象类是InputFormat,InputFormat抽象类是MapReduce输入数据的顶层基类,这个抽象类中只定义了两个方法
- 一个是getSplits方法
- 另一个是createRecordReader方法
这个抽象类下面有三个子继承类,
- DBInputFormat是操作数据库的,
- FileInputFormat是操作文件类型数据的,
- DelegatingInputFormat是用在处理多个输入时使用的
这里面比较常见的也就是FileInputFormat了,FileInputFormat是所有以文件作为数据源的基类,
FileInputFormat保存job输入的所有文件,并实现了对输入文件计算splits的方法,至于获得文件中数据的方法是由子类实现的。
FileInputFormat下面还有一些子类:
- CombineFileInputFormat:处理小文件问题的,后面我们再详细分析
- TextInputFormat:是默认的处理类,处理普通文本文件,他会把文件中每一行作为一个记录,将每一行的起始偏移量作为key,每一行的内容作为value,这里的key和value就是我们之前所说的k1,v1它默认以换行符或回车键作为一行记录
- NLineInputFormat:可以动态指定一次读取多少行数据
这里面的TextInputFormat是我们处理文本数据的默认处理类,TextInputFormat的顶层基类是InputFormat,下面我们先来看一下这个抽象类的源码
面试题
看几个面试题?
- 一个1G的文件,会产生多少个map任务?
Block块默认是128M,所以1G的文件会产生8个Block块
默认情况下InputSplit的大小和Block块的大小一致,每一个InputSplit会产生一个map任务
所以:1024/128=8个map任务 - 1000个文件,每个文件100KB,会产生多少个map任务?
一个文件,不管再小,都会占用一个block,所以这1000个小文件会产生1000个Block,
那最终会产生1000个InputSplit,也就对应着会产生1000个map任务 - 一个140M的文件,会产生多少个map任务?
根据前面的分析
140M的文件会产生2个Block,那对应的就会产生2个InputSplit了?
注意:这个有点特殊,140M/128M=1.09375<1.1
所以,这个文件只会产生一个InputSplit,也最终也就只会产生1个map 任务。
这个文件其实再稍微大1M就可以产生2个map 任务了。
OutputFormat分析
OutputFormat,顾名思义,这个是控制MapReduce输出的。
- OutputFormat是输出数据的顶层基类
- FileOutputFormat:文件数据处理基类
- TextOutputFormat:默认文本文件处理类
这几个其实和InputFormat中的那几个文本处理类是对应着的,当然了针对输出数据还有其它类型的处理类,我们在这先分析最常见的文本文件处理类,其他类型的等我们遇到具体场景再具体分析。
我们来看一下OutputFormat的源码,这个类主要由三个方法
getRecordWriter
checkOutputSpecs
getOutputCommitter
先看一下getRecordWriter这个方法的具体实现,在TextOutputFormat中
public RecordWriter<K, V>
getRecordWriter(TaskAttemptContext job
) throws IOException, InterruptedException {
Configuration conf = job.getConfiguration();
//任务的输出数据是否需要压缩,默认为false,也就是不压缩
boolean isCompressed = getCompressOutput(job);
//获取输出的key(k3)和value(v3)之间的分隔符,默认为\t
String keyValueSeparator= conf.get(SEPARATOR, "\t");
CompressionCodec codec = null;
String extension = "";
if (isCompressed) {
Class<? extends CompressionCodec> codecClass =
getOutputCompressorClass(job, GzipCodec.class);
codec = ReflectionUtils.newInstance(codecClass, conf);
extension = codec.getDefaultExtension();
}
//获取输出文件路径信息
Path file = getDefaultWorkFile(job, extension);
FileSystem fs = file.getFileSystem(conf);
//获取文件输出流
FSDataOutputStream fileOut = fs.create(file, false);
if (isCompressed) {
return new LineRecordWriter<>(
new DataOutputStream(codec.createOutputStream(fileOut)),
keyValueSeparator);
} else {
//创建行书写器
return new LineRecordWriter<>(fileOut, keyValueSeparator);
}
}
















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









