









 本文介绍了JAVA中的StringTokenizer类,用于分隔字符串。它提供了三种构造方法,支持自定义分隔符,并能判断是否还有更多分隔符,获取下一个分隔符前的字符串。此外,还提到了分隔符的特殊处理情况。
本文介绍了JAVA中的StringTokenizer类,用于分隔字符串。它提供了三种构造方法,支持自定义分隔符,并能判断是否还有更多分隔符,获取下一个分隔符前的字符串。此外,还提到了分隔符的特殊处理情况。
String Tokenizer类是一个用来分隔String的应用类
StringTokenizer(String str):构造一个用来解析str的StringTokenizer对象。java默认的分隔符是“空格”、“制表符(‘\t’)”、“换行符(‘\n’)”、“回车符(‘\r’)”。
StringTokenizer(String str, String delim):构造一个用来解析str的StringTokenizer对象,并提供一个指定的分隔符。
StringTokenizer(String str, String delim, boolean returnDelims):构造一个用来解析str的StringTokenizer对象,并提供一个指定的分隔符,同时,指定是否返回分隔符。
boolean hasMoreTokens() :返回是否还有分隔符
boolean hasMoreElements() :返回是否还有分隔符
String nextToken():返回从当前位置到下一个分隔符的字符串
int countTokens():返回nextToken方法被调用的次数
下面是两种用法
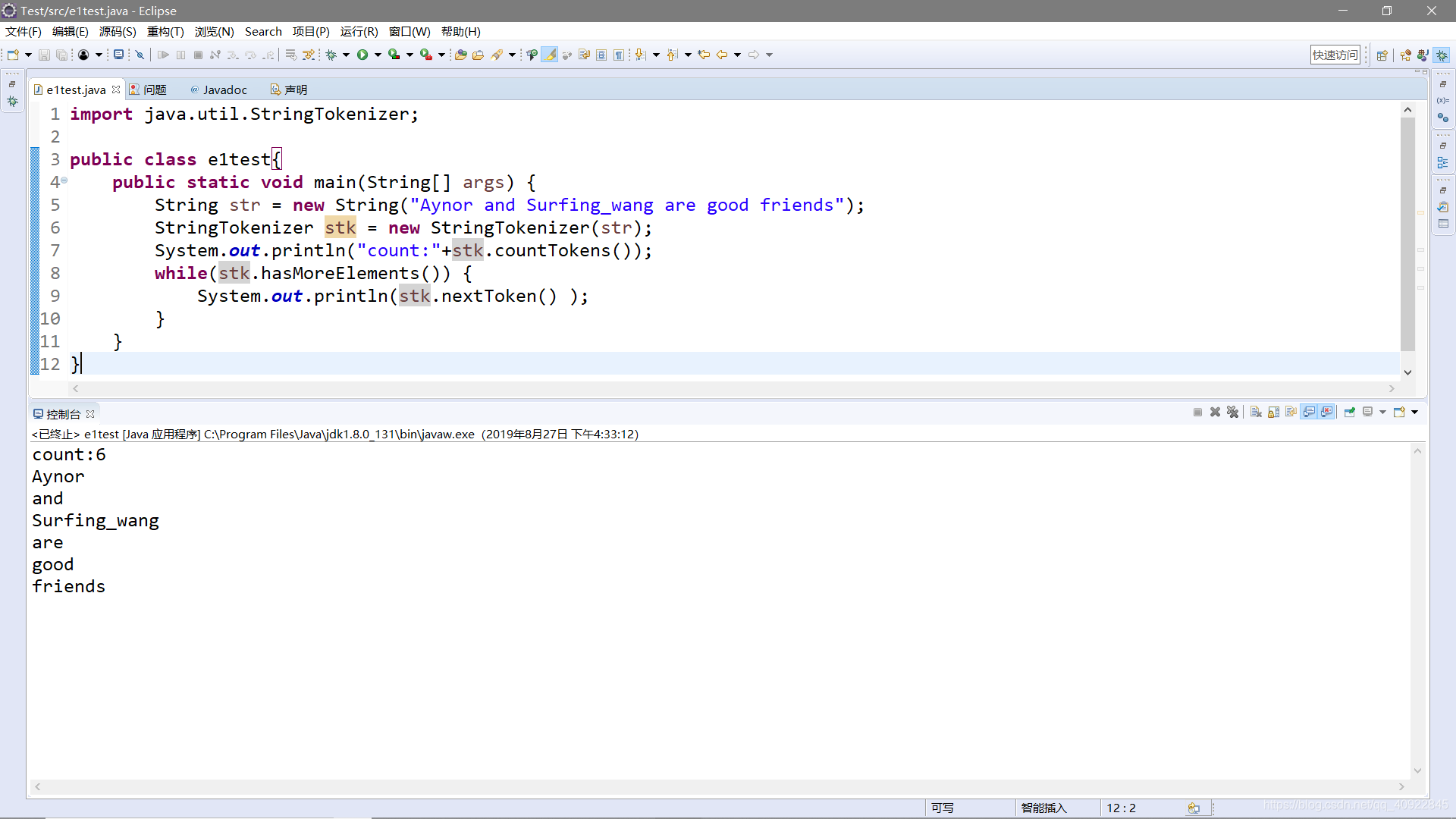
import java.util.StringTokenizer;
public class e1test{
public static void main(String[] args) {
String str = new String("Aynor and Surfing_wang are good friends");
StringTokenizer stk = new StringTokenizer(str);
System.out.println("count:"+stk.countTokens());
while(stk.hasMoreElements()) {
System.out.println(stk.nextToken() );
}
}
}
import java.util.StringTokenizer;
public class e1test{
public static void main(String[] args) {
String str = new String("Aynor and Surfing_wang are good friends");
String str2 = new String("Aynor=and=Surfing_wang=are=good=friends");
StringTokenizer stk = new StringTokenizer(str);
StringTokenizer stk2 = new StringTokenizer(str2,"=",true);
System.out.println("count:"+stk.countTokens());
// while(stk.hasMoreElements()) {
// System.out.println(stk.nextToken() );
// }
while(stk.hasMoreElements()) {
System.out.println(stk2.nextToken() );
}
}
}
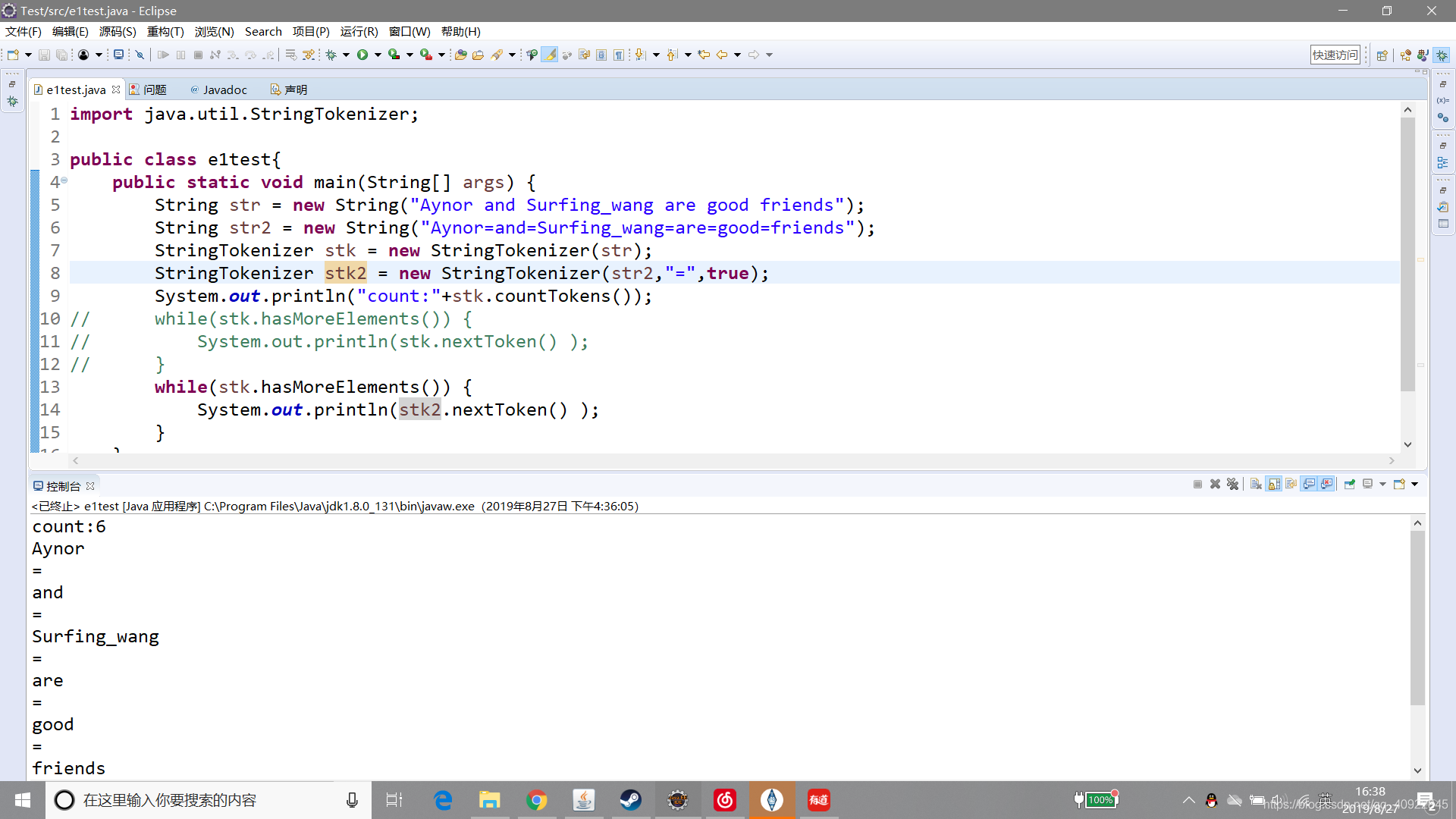
另外如果用12作为分隔符的话,1、2、12、21都会被认为是分隔符
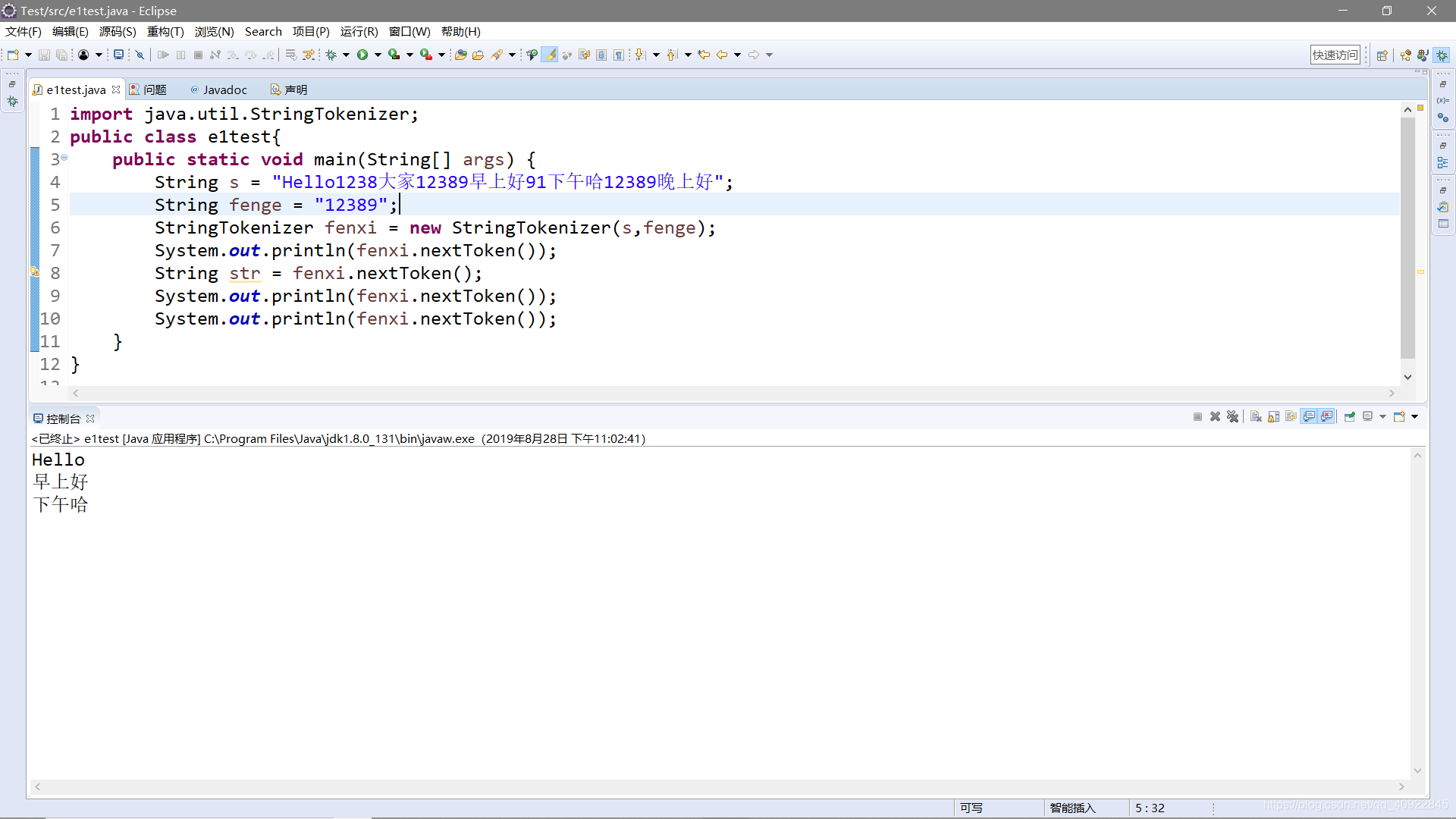
import java.util.StringTokenizer;
public class e1test{
public static void main(String[] args) {
String s = "Hello1238大家12389早上好91下午哈12389晚上好";
String fenge = "12389";
StringTokenizer fenxi = new StringTokenizer(s,fenge);
System.out.println(fenxi.nextToken());
String str = fenxi.nextToken();
System.out.println(fenxi.nextToken());
System.out.println(fenxi.nextToken());
}
}

















 4374
4374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









