







激活函数
之前使用的激活函数都是Sigmoid函数,它能把得分压缩到(0,1)。Sigmoid函数曾经也很流行,但是Sigmoid函数有三个问题:
- 它是饱和神经元,会使梯度消失
- 它的输出全是正的,导致有些梯度不能直接更新
- 指数操作需要更多的计算量(神经网络整体计算量本来就很大了,指数操作会消耗更多的资源)

当z=-10时,Sigmoid(-10)≈0,Sigmoid对W求导(也就是W的梯度)约等于0,梯度消失;
当z=10时,Sigmoid(10)≈1,Sigmoid对W求导约等于0,梯度消失;
只有当z=0附近时,Sigmoid对W求导才不会等于0,梯度也不会消失;
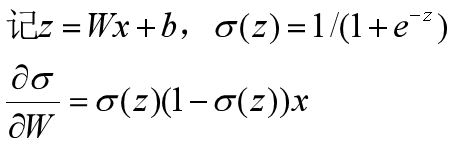

如果一个神经元的输入全是正的,那么W的梯度不是全为正,就是全为负(就算激活函数不是Sigmoid函数也有这种情况,所以希望输入数据都是以零为中心的)。

假设一个二维W的负梯度方向在一三象限,那么可以直接向负梯度方向更新(右上角的绿色区域);
但是,如果负梯度方向在二四象限,由于W的梯度全为正或者全为负,更新的过程就比较曲折。

tanh函数的输出是以零为中心的,解决了梯度更新方向的问题,但是依旧没有解决梯度消失的问题。

ReLu函数的优点:
- 在正区域,梯度不会消失
- 相对于sigmoid和tanh,计算量较小
- 在生物学上,比sigmoid更加合理
但是它的输出不是以零为中心的,会导致梯度更新方向的问题。

在输入x小于等于0时,梯度会消失;在x大于零时,梯度才不会消失。

如果所有的输入都是负的,那么这个模型就不会再进行更新了,我们把它叫做死的ReLU。
所以有些人会把ReLU神经元的偏置设为较小的正数,减缓梯度消失的情况。但是这种方法有的人说有用,有的人又说没用。
下图中灰色的代表所有的输入数据,线代表决策边界,箭头方向代表得分为正。
对于红色的决策边界,现在所有输入都在得分为负的一边,所以ReLU不再更新。而对于绿色的决策边界,输入数据的得分有正有负,所以它还会继续更新。

Leaky ReLU和PReLU保留了ReLU的优点,而且它们在输入为负数时也不会梯度消失。

ELU保留了ReLU的优点,并改进了ReLU的输出中心不为零的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









