







总览
这篇论文研究如何通过无监督的方法操纵隐变量来改变生成图像。
有监督方法
现存的大多数方法都是有监督的,一般的流程为:
- 通过训练好的GAN合成大量的图像
- 对合成图像进行手工标注(如人脸向左还是向右、汽车的大小)
- 通过标签训练一个线性分类器,调整隐变量,使其沿着垂直于分类边界的方向移动
有监督的方法需要清晰定义目标属性(比如发型就很难以二值来定义,也就无法训练线性分类器)并且需要手工标注,因此难以拓展。这是一篇有监督方法的论文解读:论文解读:InterFaceGAN(cvpr2020)
无监督方法
生成器可看做从隐变量到输出图像的多次投影,与隐变量直接相关的是第一次投影,对这次投影的参数进行分解可以获得操纵方向。
原理
生成器的输入是隐变量z,经过多次投影(多层神经网络)后得到图像X,把第一次投影记为G1(·),第一次投影的输出记为y。
我们知道每层神经网络其实相当于一个仿射变换,所以得到以下公式(A是生成器第一层神经网络的参数):
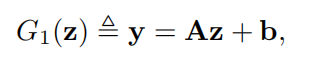
假设隐变量沿n方向移动后,生成图像会发生人类可理解的变化(比如生成的人脸眼睛会变大)。
n作用在隐变量z上,并经过第一次投影G1(·)后,和原来相差了αAn,所以改变的信息都在αAn中。
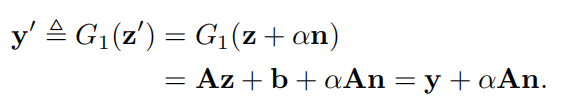
如果αAn=0,那么生成的图像不会有任何改变,所以希望αAn越大越好,这样生成的图像才有可能有变化。
nTn=1是对n进行单位向量化。
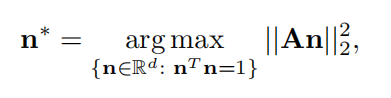
上面是找单个最大改变方向的,如果要找多个改变方向,需使用下面的公式
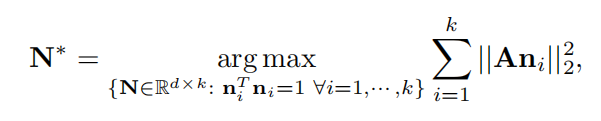
通过拉格朗日乘子法,得到:

对n求偏导得到:
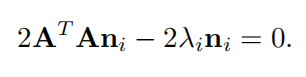
这其实是在求ATA的特征向量,也就是最大的k个特征值对应的特征向量。
实验
StyleGAN的隐变量是输入到每一层的,对不同层的投影进行分解,操纵的类型也不同:对底层的参数分解可操纵脸的方向,中层可操纵眼睛的大小,顶层的可改变图像的风格。

真实图片通过GAN反演后,可得到它对应的隐变量,从而可以对真实图片进行编辑。
















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









