







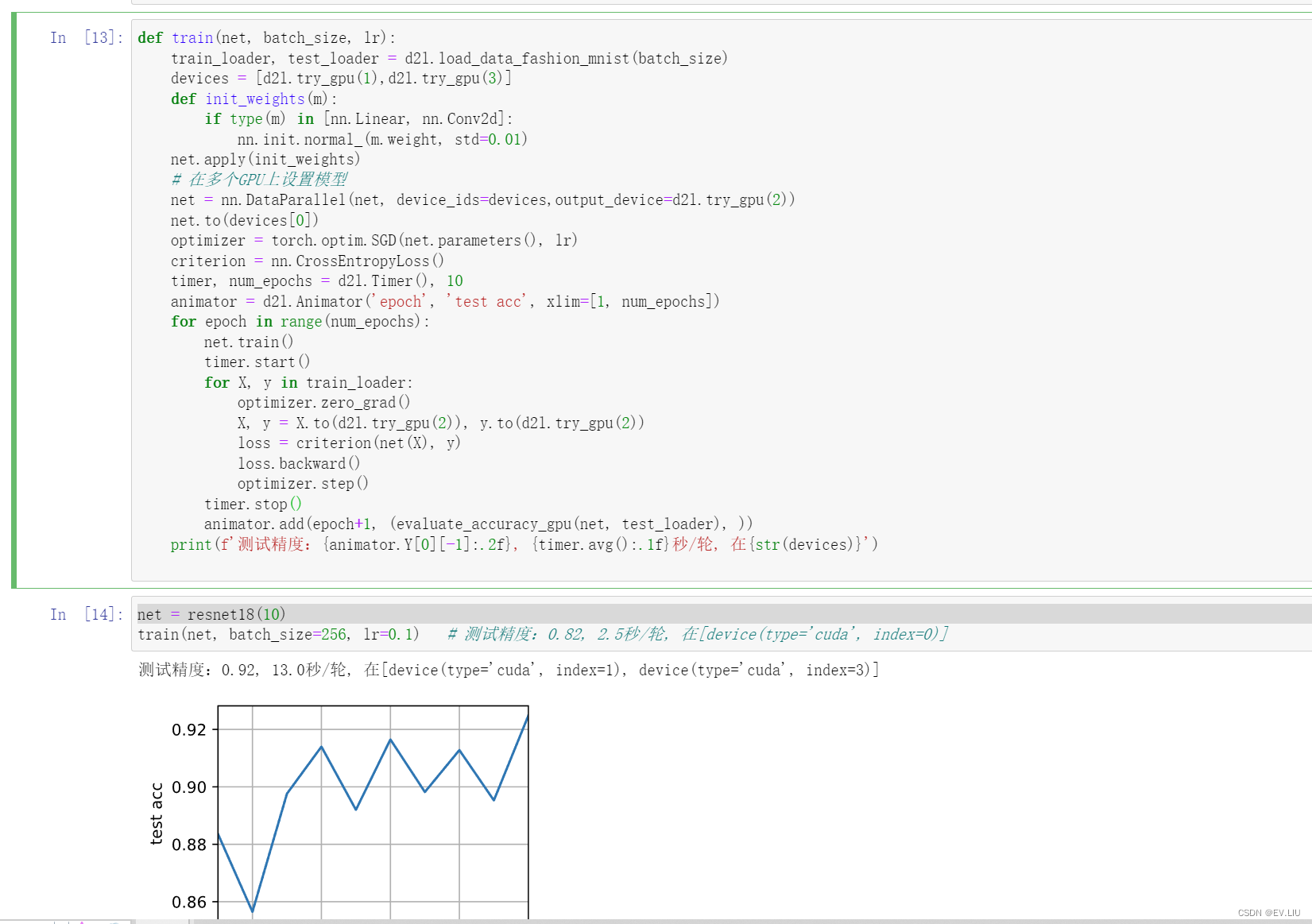
最近学习torch框架,发现大部分开发人员习惯上使用DataParallel训练时会首先把data放入主卡,然后由框架本身自带的功能去把它分发到其他卡中,输出设备默认为主卡,这样后续操作堪称无脑,能够有效提高并行能力,但是这里有一个问题就在于主卡作为输出设备和数据分发设备,但是主卡一定比子卡多更多的存储数据,而主卡和子卡显存使用差就是子卡的浪费空间,开的卡越多越明显。通过读源码我发现torch支持数据从任意设备传输,在forward时候对数据进行分配,那我们可以将数据首先不放入主卡中,另外就是输出设备可以改变位置,那么我也可以将输出设备拿出来,我将数据和输出数据放在了单独一张卡,这样做的好处是计算损失函数、精确度会很简单,负责计算的GPU不会因为某张卡有更多的数据而限制其他卡的使用空间.但是他的坏处是由于loss在数据卡上,loss.backward并不会占用太多的计算机量,所以大部分时间数据卡的利用率为0。这种方法适合数据比较大,还想通过gpu加速的场景,GPU越多平均利用率损耗月低,不适用于一般的场景


















 1116
1116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











