







日期2022.3.28
目录
2、Python实现一天打卡(需手动下载数据,并解压重命名)
3、Python实现连续多天打卡检测(需手动下载数据,并解压重命名)
5、改进Python实现连续多天打卡检测(仅需手动下载数据,然后运行)
1、从腾讯问卷导出CSV数据
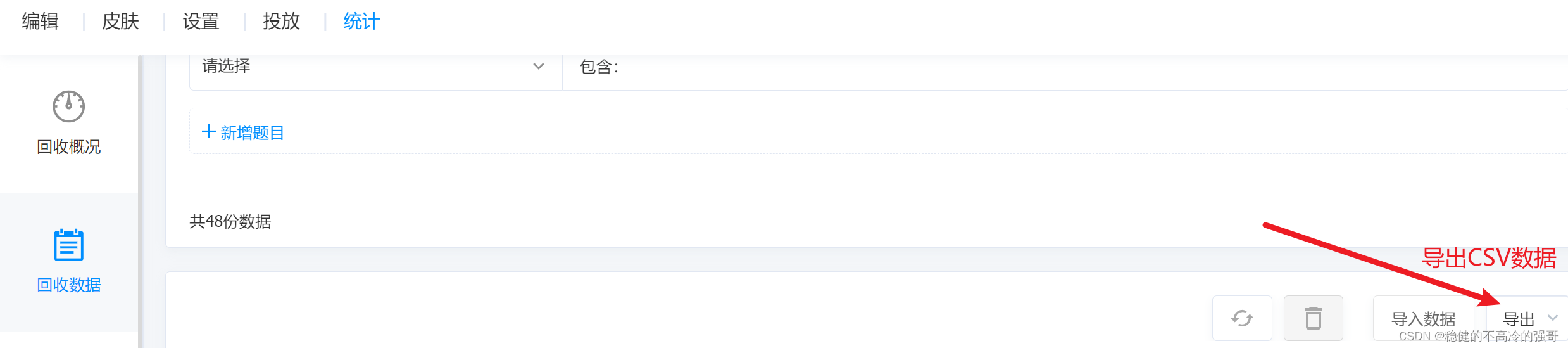 将全部打卡人数的信息,放入benkeshen文件夹,一行一个名字
将全部打卡人数的信息,放入benkeshen文件夹,一行一个名字
运行python程序,得出结果
2、Python实现一天打卡(需手动下载数据,并解压重命名)
import csv
time = r"2022/3/22"
# 读取第一个文件name
with open(r'C:\Users\14193\Desktop\benkesheng.txt', 'r', encoding='utf-8') as f1:
name = f1.read()
# 将字符串name 切片成 list
name = name.split()
print(f"人数:\t{len(name)}")
# 读取第二个文件
with open(r'C:\Users\14193\Desktop\1.csv', 'r', encoding='utf-8') as f2:
reader = csv.reader(f2)
# 略过第一行
next(reader)
# 逐行遍历剩下的每行数据
for row in reader:
# 对比所需找的日期 将出现的name删除
if time in row[2] and row[11] in name:
name.remove(row[11])
# 直接在控制台输出结果
print(f"未打卡:\t{name}")
# 将结果输出到文件中
with open(r'C:\Users\14193\Desktop\result.txt', 'w', encoding='utf-8') as f3:
# 逐行遍历name
for row in name:
f3.write(row)
f3.write("\n")3、Python实现连续多天打卡检测(需手动下载数据,并解压重命名)
import os
root = os.getcwd()#获取当前文件执行路径
import csv
from datetime import datetime, timedelta
# 开始日期的前一天
start = datetime.strptime("20-Mar-2022", "%d-%b-%Y")
now = datetime.strftime(datetime.now(), "%d-%b-%Y")
# 重置结束日期为0点0分0秒
end = datetime.strptime(now, "%d-%b-%Y")
print(f"输出一下日期格式\n{start}\n{end}")
print(f"今天打卡日期:\t{now}")
timeList = []
temp = end
while temp != start:
# 转化为字符串格式,放入列表中
timeList.append(datetime.strftime(temp, "%d-%b-%Y"))
# 向前推一天
temp = temp - timedelta(days=1)
print(f"日历列表如下:\n{timeList}")
print(f"打卡天数:\t{len(timeList)}")
print(f"打卡开始日期:\t{timeList[len(timeList) - 1]}")
print(f"打卡结束日期:\t{timeList[0]}")
# 读取第一个文件name,包含全部打卡人员名字
with open(root + '\\benkesheng.txt', 'r', encoding='utf-8') as f1:
name = f1.read()
# 将字符串 name 切片成 list
name = name.split()
print(f"总人数:\t{len(name)}")
# 存放全部日期未打卡人员的名字,即每一天
notFindName = []
# 读取第二个文件
with open(root + '\\1.csv', 'r', encoding='utf-8') as f2:
reader = csv.reader(f2)
# 略过第一行
next(reader)
# 一天未打卡人员名字,结果中包含所有名字,打卡的则从中剔除,剩下即为未打卡
res = name[:]
# 逐行遍历剩下的每行数据
i = 0
for row in reader:
# 打印文件中的时间格式
# print(row[2])
# 找到对应的日期
while timeList[i] not in row[2]:
if len(res) != len(name):
# 控制台输出
print(f"{timeList[i]}未打卡人数:\t{len(res)}\n{res}")
# 结果放入列表中,最后读入文件
notFindName.append(res)
# 下一天的打卡信息
i += 1
res = name[:]
# 打卡的则从中剔除,剩下即为未打卡
if row[11] in res:
res.remove(row[11])
# 输出最早的一天数据
notFindName.append(res)
print(f"{timeList[i]}未打卡人数:\t{len(res)}\n{res}")
# 将结果输出到文件中
with open(root + '\\result.txt', 'w', encoding='utf-8') as f3:
# 逐行遍历日期列表timeList
for i in range(len(timeList)):
f3.write(f"{timeList[i]}未打卡人数:\t{len(notFindName[i])}\n{notFindName[i]}\n")
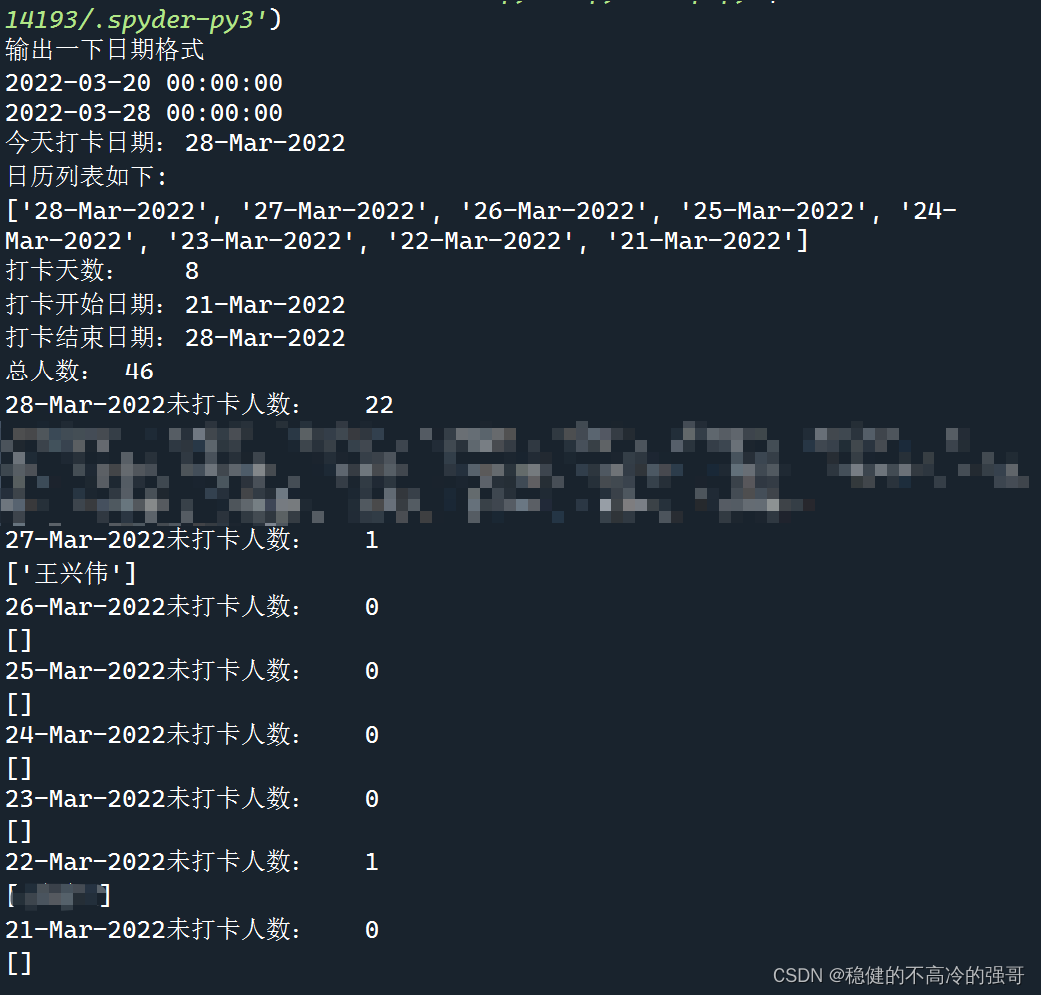
4、url下载文件,打卡检测(未成功)
因为腾讯问卷的url时刻变化,
实现后发现,腾讯问卷导出数据的链接,每次都不一样,因此通过同一个url下载的数据一致,无法动态检测。
因此还需手动点击下载数据
root = os.getcwd() # 获取当前文件执行路径
url = r'https://wj-collection-1258344706.cos-website.ap-guangzhou.myqcloud.com/export/answer/9501508_202205091414576686.csv.zip?sign=q-sign-algorithm%3Dsha1%26q-ak%3DAKID3dz5uN4cMpGamjMvBaySkOoxwmMgMacO%26q-sign-time%3D1652076839%3B1652098499%26q-key-time%3D1652076839%3B1652098499%26q-header-list%3Dhost%26q-url-param-list%3D%26q-signature%3D4954e92a16074b56f7812697c298c238c5a5aa2b&_=1652076899732'
# 下载文件到本地的路径,拼接路径,等价于 root \ 文件名
zippath = os.path.join(root, '9501508_202205091414576686.zip')
urllib.request.urlretrieve(url, zippath) # 下载文件
with zipfile.ZipFile(zippath, 'r') as zip: # 解压文件
zip.extractall(root) # 压缩包内文件全部解压到root目录
# 压缩包文件名,拼接成路径,等价于 root \ 文件名
datafile = os.path.join(root, zip.namelist()[0])
# 删除压缩文件
# os.remove(zippath)
# 删除解压后的文件
# os.remove(datafile)5、改进Python实现连续多天打卡检测(仅需手动下载数据,然后运行)
默认下载路径:C:\Users\Lenovo\Downloads
在该路径下找csv.zip压缩包,然后解压,读取解压文件,然后删除压缩包和数据文件。
每次运行前,需要下载好数据压缩包
from datetime import datetime, timedelta
import csv
import zipfile
import os
# 生成打卡日期的timeList
def makeTimeList(start, end, timeList):
temp = end
while temp != start:
# 转化为字符串格式,放入列表中
timeList.append(datetime.strftime(temp, "%d-%b-%Y"))
# 向前推一天
temp = temp - timedelta(days=1)
print(f"日历列表如下:\n{timeList}")
print(f"打卡天数:\t{len(timeList)}")
print(f"打卡开始日期:\t{timeList[len(timeList) - 1]}")
print(f"打卡结束日期:\t{timeList[0]}")
# 从文件一,读取名字list
def getName(root):
# 读取第一个文件name,包含全部打卡人员名字
with open(root + '\\name.txt', 'r', encoding='utf-8') as f1:
name = f1.read()
# 将字符串 name 切片成 list
name = name.split()
return name
# 解压文件,返回解压后的数据文件路径
def zipFile(root):
downloadpath = r'C:' + os.environ['HOMEPATH'] + r'\Downloads' # 下载的压缩包所在路径
# 遍历当前路径的文件列表
for i in os.listdir(downloadpath):
if '.csv.zip' in i:
zippath = os.path.join(downloadpath, i) # 压缩包文件名,拼接成路径
break
# 解压文件
with zipfile.ZipFile(zippath, 'r') as zip:
zip.extractall(downloadpath) # 压缩包内文件全部解压到downloadpath目录
# 压缩包解压后文件名,拼接成路径
datafile = os.path.join(downloadpath, zip.namelist()[0])
os.remove(zippath)
return datafile
# 读取数据文件,找到每天未打卡的名字
def FindName(notFindName, name, timeList):
with open(datafile, 'r', encoding='utf-8') as f2:
reader = csv.reader(f2)
# 略过第一行各种标签行
next(reader)
# 一天未打卡人员名字,结果中包含所有名字,打卡的则从中剔除,剩下即为未打卡
res = name[:]
# 逐行遍历剩下的每行数据
i = 0
for row in reader:
# 打印文件中的时间格式
# print(row[2])
# 找到对应的日期
while timeList[i] not in row[2]:
# 结果放入列表中,最后读入文件
notFindName.append(res)
#print(i, ' ', len(notFindName))
# 下一天的打卡信息
i += 1
res = name[:]
# 打卡的则从中剔除,剩下即为未打卡
if row[11] in res:
res.remove(row[11])
# 输出最早的一天的结果加入
notFindName.append(res)
# print(len(notFindName))
# 对未找到的名字,进行统计,返回统计的字典
def countNUm(dic, notFindName):
for i in notFindName:
for j in i:
if j not in dic:
dic[j] = 1
else:
dic[j] += 1
# 按照字典值降序排列,次数为临时的字典,需要使用deepcopy, 或者返回赋值
return {k: v for k, v in sorted(dic.items(), key=lambda item: item[1], reverse=True)}
# 将结果输出到文件中
def outputToFileAndConsole(root, dic, timeList, notFindName):
with open(root + '\\result.txt', 'w', encoding='utf-8') as f3:
f3.write(f'打卡的总次数\t{len(timeList)}\n未打卡的统计次数\n')
# 控制台输出
print(f'打卡的总次数\t{len(timeList)}\n未打卡的统计次数\n', end='')
# 逐行遍历日期列表timeList
i = 0
for key, value in dic.items():
f3.write(
f'{key}:\t{value}\t')
print(f'{key}:\t{value}\t', end='')
i += 1 # 控制输出格式5个输出一行
if i % 5 == 0:
f3.write(f'\n')
print()
f3.write(f'\n\n\n')
print(f'\n\n\n', end='')
print(len(timeList), len(notFindName))
# 逐行遍历日期列表timeList
for i in range(len(timeList)):
f3.write(
f'{timeList[i]}未打卡人数:\t{len(notFindName[i])}\n{notFindName[i]}\n')
print(
f'{timeList[i]}未打卡人数:\t{len(notFindName[i])}\n{notFindName[i]}\n', end='')
# 开始日期的前一天
start = datetime.strptime("20-Mar-2022", "%d-%b-%Y")
now = datetime.strftime(datetime.now(), "%d-%b-%Y")
# 重置结束日期为0点0分0秒
end = datetime.strptime(now, "%d-%b-%Y")
print(f'输出一下日期格式\n{start}\n{end}')
print(f'今天打卡日期:\t{now}')
timeList = []
# 获取日期timelist
makeTimeList(start, end, timeList)
# 获取当前文件执行路径
root = os.getcwd()
# 解压后返回数据文件路径
datafile = zipFile(root)
# 从文件获取名字list
name = getName(root)
# 存放全部日期未打卡人员的名字,即每一天
notFindName = []
FindName(notFindName, name, timeList)
# 删除csv数据文件
os.remove(datafile)
# 结果使用字典进行计数并输出
dic = {}
dic = countNUm(dic, notFindName)
outputToFileAndConsole(root, dic, timeList, notFindName)

















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









