







树数据结构
我们读取线性数据结构,如数组,链表,堆栈和队列,其中所有元素都按顺序排列。不同的数据结构用于不同类型的数据。
在选择数据结构时会考虑一些因素:
- 需要存储什么类型的数据?某种数据结构可能最适合某种数据。
- 运营成本:如果我们要最小化最常执行的操作的操作成本。例如,我们有一个简单的列表,我们必须在其上执行搜索操作;然后,我们可以创建一个数组,其中元素按排序顺序存储以执行二进制搜索。二进制搜索对于简单列表非常快速,因为它将搜索空间分成两半。
- 内存使用情况:有时,我们想要一个使用更少内存的数据结构。
树也是表示分层数据的数据结构之一。
树数据结构中使用的一些基本术语。
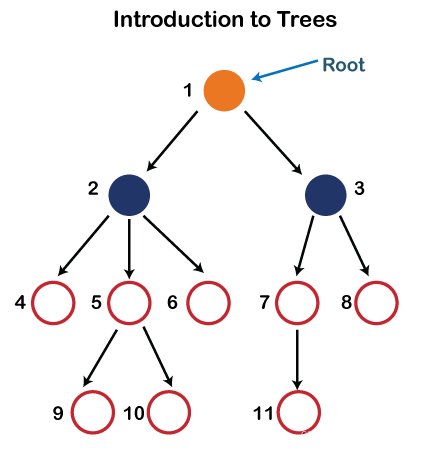
在上面的结构中,每个节点都标有一些数字。上图中显示的每个箭头称为两个节点之间的链接。
- 根:根节点是树层次结构中最顶层的节点。换句话说,根节点是没有任何父节点的节点。在上面的结构中,编号为 1 的节点是树的根节点。如果某个节点直接链接到某个其他节点,则该节点将称为父子关系。
- 子节点:如果节点是任何节点的后代,则该节点称为子节点。
父母:如果节点包含任何子节点,则该节点称为该子节点的父节点。
兄弟:具有相同父级的节点称为同级节点。 - 叶节点:-树的节点(没有任何子节点)称为叶节点。叶节点是树的最底部节点。一般树中可以存在任意数量的叶节点。叶节点也可以称为外部节点。
- 内部节点:一个节点至少有一个称为内部的子节点
- 祖先节点:-节点的祖先是从根节点到该节点的路径上的任何前置节点。根节点没有任何祖先。在上图所示的树中,节点 1、2 和 5 是节点 10 的祖先。
- 后代:给定节点的直接后继者称为节点的后代。在上图中,10 是节点 5 的后代。
树数据结构的属性
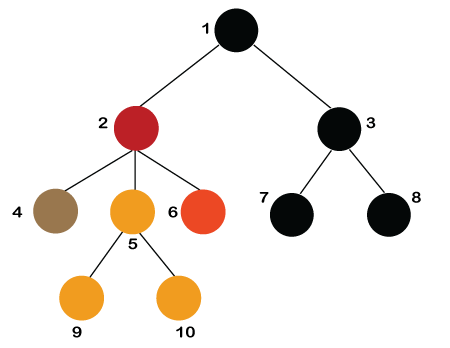
递归数据结构:该树也称为递归数据结构。树可以递归方式定义,因为树数据结构中的可分辨节点称为根节点。树的根节点包含指向其子树的所有根的链接。左子树在下图中以黄色显示,右子树以红色显示。左侧子树可以进一步拆分为以三种不同颜色显示的子树。递归意味着以自我相似的方式减少某些东西。因此,树数据结构的这种递归属性在各种应用程序中实现。
- 边数:如果有 n 个节点,则将有
n-1 条边。结构中的每个箭头都表示链接或路径。除根节点外,每个节点将至少有一个称为边的传入链路。父子关系将有一个链接。 - 节点深度 x:节点 x 的深度可以定义为从根到节点 x 的路径长度。一条边在路径中贡献一个单位长度。因此,节点 x 的深度也可以定义为根节点和节点 x 之间的边数。根节点的深度为 0。
- 节点 x 的高度:节点 x 的高度可以定义为从节点 x 到叶节点的最长路径。
根据树数据结构的属性,树被分类为各种类别。
叶的高度为0
树的实现
树数据结构可以通过在指针的帮助下动态创建节点来创建。内存中的树可以表示如下图所示:
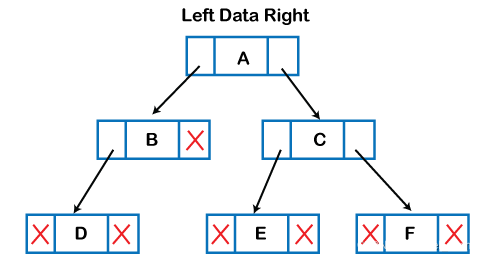
上图显示了内存中树数据结构的表示形式。在上面的结构中,节点包含三个字段。第二个字段存储数据;第一个字段存储左子项的地址,第三个字段存储右子项的地址。
在编程中,节点的结构可以定义为:
结构节点
{
整数 数据;
结构节点 *左;
结构节点 *右;
}
struct node
{
int data;
struct node *left;
struct node *right;
}
上述结构只能为二叉树定义,因为二叉树最多可以有两个子树,而通用树可以有两个以上的子树。与二叉树相比,通用树的节点结构将有所不同。
树的应用
以下是树的应用:
- 存储自然分层数据:树用于将数据存储在层次结构中。例如,文件系统。存储在光盘驱动器上的文件系统,文件和文件夹以自然分层数据的形式存储,并以树的形式存储。
- 组织数据:它用于组织数据以进行有效的插入、删除和搜索。例如,二叉树具有用于搜索元素的 logN 时间。
- Trie:它是一种特殊的树,用于存储字典。这是一种快速有效的动态拼写检查方法。
- 堆:它也是使用数组实现的树数据结构。它用于实现优先级队列。
- B 树和 B+树:B-Tree 和 B+Tree 是用于在数据库中实现索引的树数据结构。
- 路由表(Routing table):树数据结构还用于将数据存储在路由器的路由表中。
树数据结构的类型
以下是树数据结构的类型:
- 通用树(General tree):通用树是树数据结构的类型之一。在常规树中,一个节点可以有 0 个或最大 n 个节点。对节点的程度(节点可以包含的节点数)没有限制。常规树中最顶层的节点称为根节点。父节点的子节点称为子树。
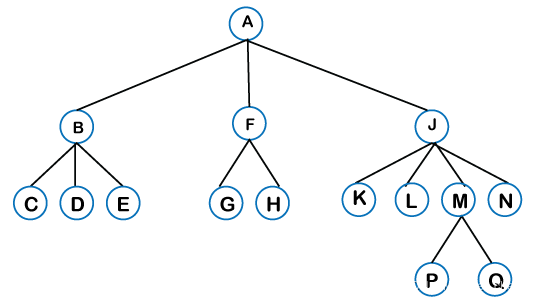
一般树中可以有 n 个子树。在常规树中,子树是无序的,因为子树中的节点无法排序。
每个非空树都有一个向下的边缘,这些边缘连接到称为子节点的节点。根节点标记为级别 0。具有相同父级的节点称为同级节点。
二叉树(Binary tree)
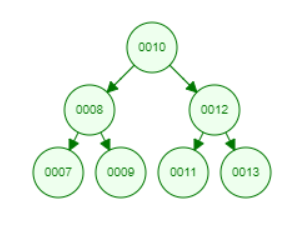
二叉树(Binary tree):在这里,二进制名称本身表示两个数字,即 0 和 1。在二叉树中,树中的每个节点最多可以有两个子节点。此处,最大值表示节点是有 0 个节点、1 个节点还是 2 个节点。
二叉搜索树:二叉搜索树是一种非线性数据结构,其中一个节点连接到n个节点。它是一种基于节点的数据结构。节点可以在具有三个字段的二叉搜索树中表示,即数据部分,左子项和右子项。一个节点可以连接到二叉搜索树中最多两个子节点,因此该节点包含两个指针(左子指针和右子指针)。
左侧子树中的每个节点都必须包含一个小于根节点值的值,并且右侧子树中每个节点的值必须大于根节点的值。
AVL 树(平衡树)
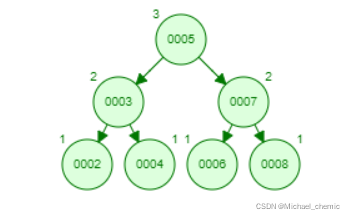
它是二叉树的类型之一,或者我们可以说它是二叉搜索树的变体。AVL 树满足二叉树和二叉搜索树的属性。它是一个自平衡的二叉搜索树,由Adelson Velsky Lindas发明。在这里,自平衡意味着平衡左子树和右子树的高度。这种平衡是根据平衡因素来衡量的。
如果树遵循二叉搜索树以及平衡因子,我们可以将树视为 AVL 树。平衡因子可以定义为左子树的高度和右子树的高度之间的差值。平衡因子的值必须为 0、-1 或 1;因此,AVL 树中的每个节点的平衡因子值都应为 0、-1 或 1。
红黑树(Red-Black Tree)
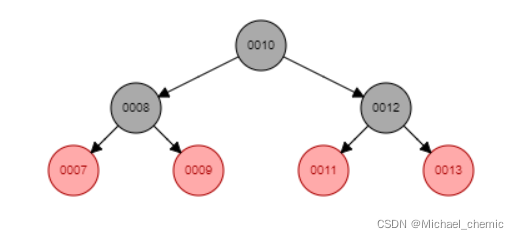
红黑树是二叉搜索树。红黑树的先决条件是我们应该了解二叉搜索树。在二叉搜索树中,左子树的值应小于该节点的值,并且右子树的值应大于该节点的值。众所周知,二进制搜索在平均情况下的时间复杂度为log2n,最佳情况为O(1),最坏情况为O(n)。
当对树执行任何操作时,我们希望我们的树是平衡的,以便所有操作(如搜索,插入,删除等)花费的时间更少,并且所有这些操作都将具有log2n的时间复杂度。
红黑树是一个自平衡的二叉搜索树。AVL树也是一个高度平衡二叉搜索树,那么为什么我们需要红黑树。在 AVL 树中,我们不知道需要多少次旋转才能平衡树,但在红黑树中,最多需要 2 次旋转来平衡树。它包含一个额外的位,表示节点的红色或黑色,以确保树的平衡。
Splay tree
splay树数据结构也是二叉搜索树,其中通过执行一些旋转操作将最近访问的元素放置在树的根位置。此处,播放表示最近访问的节点。它是一个自平衡二叉搜索树,没有像AVL树那样的显式平衡条件。
splay 树的高度可能不平衡,即左子树和右子树的高度可能不同,但 splay 树中的操作采用 logN 时间的顺序,其中 n 是节点数。
Splay树是一棵平衡树,但它不能被视为高度平衡树,因为每次操作后,都会执行旋转,从而导致平衡树。
Treap
Treap 数据结构来自树和堆数据结构。因此,它包含树和堆数据结构的属性。在二叉搜索树中,左侧子树上的每个节点必须等于或小于根节点的值,并且右侧子树上的每个节点必须等于或大于根节点的值。在堆数据结构中,右子树和左子树都包含比根更大的键;因此,我们可以说根节点包含最低值。
在 treap 数据结构中,每个节点都有键和优先级,其中键派生自二叉搜索树,优先级派生自堆数据结构。
Treap 数据结构遵循下面给出的两个属性:
- 节点的右子节点>=当前节点,节点的左子节点<=当前节点(二叉树)
- 任何子树的子项必须大于节点(堆)
B 树
Max.Degree = 3
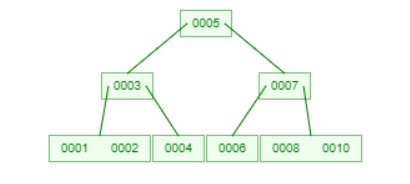
B 树是一个平衡的 m-way 树,其中 m 定义了树的顺序。到目前为止,我们读到节点只包含一个键,但b-tree可以有多个键和2个以上的子项。它始终维护排序的数据。在二叉树中,叶节点可能位于不同的级别,但在 b 树中,所有叶节点必须位于同一级别。
如果 order 为 m,则 node 具有以下属性:
- b 树中的每个节点最多可以有 m 个子节点
- 对于最小子节点,叶节点有 0 个子节点,根节点至少有 2 个子节点,内部节点的最小上限为 m/2 子节点。例如,m 的值为 5,这意味着一个节点可以有 5 个子节点,内部节点最多可以包含 3 个子节点。
- 每个节点都有最大 (m-1) 个键。
根节点必须至少包含 1 个密钥,所有其他节点必须包含至少 m/2 减去 1 个密钥的上限。
索引 Index
Binary and Linear Search (of sorted list)
Binary Search Trees
AVL Trees (Balanced binary search trees)
Red-Black Trees
Splay Trees
Open Hash Tables (Closed Addressing)
Closed Hash Tables (Open Addressing)
Closed Hash Tables, using buckets
Trie (Prefix Tree, 26-ary Tree)
Radix Tree (Compact Trie)
Ternary Search Tree (Trie with BST of children)
B Trees
B+ Trees
















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











