






 本文详细解释了PyTorch中的叶子张量概念,介绍了如何判断和处理叶子节点,以及detach(),.clone(),.grad_fn()等方法在梯度计算和模型训练中的作用。此外,还涵盖了requires_grad属性、不同梯度模式和Optimizer的使用规范。
本文详细解释了PyTorch中的叶子张量概念,介绍了如何判断和处理叶子节点,以及detach(),.clone(),.grad_fn()等方法在梯度计算和模型训练中的作用。此外,还涵盖了requires_grad属性、不同梯度模式和Optimizer的使用规范。
参考连接:Pytorch 叶子张量 leaf tensor (叶子节点) (detach)
pytorch网络冻结的三种方法区别:detach、requires_grad、with_no_grad
detach()、data、with no_grad()、requires_grad之间关系
What does require_grad=false or true in PyTorch?
本人综合了以上链接并作出自己的理解。
文章目录
一、leaf tensor (叶子节点)
什么是叶子节点、非叶子节点?
叶子节点包括两类:
- 所有requires_grad为False的张量,都约定俗成地归结为叶子张量
- requires_grad为True且由用户创建的,则它们是叶张量(leaf Tensor),例如各种网络层,nn.Linear(), nn.Conv2d()等。下图中绿色的点都是叶子节点:

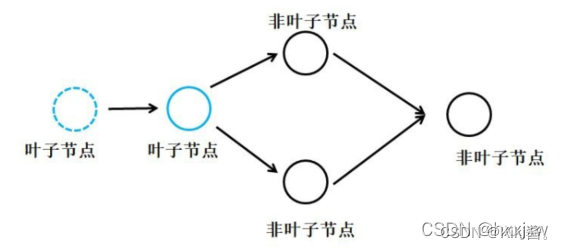
- 非叶子节点是通过用户所定义的叶子节点的一系列运算生成的,也就是这些非叶子节点都是中间变量,一般情况下,用户不会使用这些中间变量的导数,所以为了节省内存,它们在用完之后就被释放了。
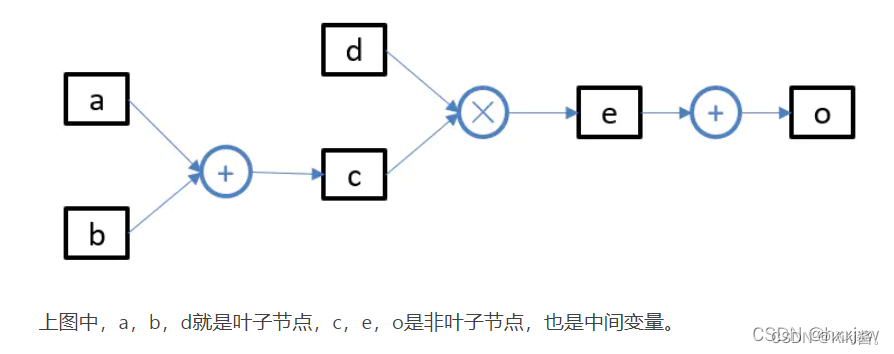
- 如果需要使得某一个节点成为叶子节点,只需使用detach()即可将它从创建它的计算图中分离开来。即detach()函数的作用就是把一个节点从计算图中剥离,使其成为叶子节点
如何判断某个量是否是叶子节点?以及叶子节点在训练过程中的作用
- 对于任意一个张量,可以用 tensor.is_leaf 来判断它是否是叶子张量(leaf tensor)
- 基于pytorch构建神经网络进行训练时,loss.backward()就是为了求叶子节点的梯度,即神经网络的权重w和偏置b,它们的require_grad都是True,然后optimizer.step()使用梯度进行更新。
- 在调用loss.backward()时,只有当requires_grad和is_leaf同时为真时,才会计算节点的梯度值。也就是说,用户构建的torch.nn.Parameter(xx,require_grad=False)虽然是叶子节点,但梯度为None,也不会更新;对于非叶子节点的变量调用para.grad会报错“The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won’t be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead.”
- 在Pytorch中,默认情况下,非叶节点的梯度值在反向传播过程中使用完后就会被清除,不会被保留(即调用loss.backward() 会将计算图的隐藏变量梯度清除)。只有叶节点的梯度值能够被保留下来。被保留下来的叶子节点的梯度值会存入tensor的grad属性中,在 optimizer.step()过程中会更新叶子节点的data属性值,从而实现参数的更新。如果想得到requires_grad为True的非叶子节点的tensor在反向传播时的grad, 可以用retain_grad()这个属性(或者是hook机制)

一些特殊操作产生的叶子节点和非叶子节点
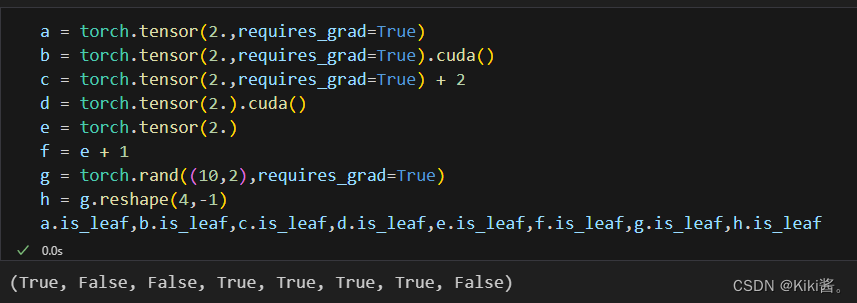
- 从cpu投射到gpu区,二次计算等
- require_grad为False的上级节点。单纯从数值关系上f=e+1,f确实依赖e(f是由e经过某个操作创建的)。但是从pytorch的看来,一切是为了反向求导,e的requires_grad属性为False,其不要求获得梯度,那么e这个tensor在反向传播时其实是“无意义”的,可认为是游离在计算图之外的,故b仍然为叶子节点,如下图
- reshape操作
获取非叶子节点的梯度retain_grad()
**只有叶子节点with requires_grad=True有梯度值grad,非叶节点为None;
只有非叶节点有grad_fn,叶节点为None;
with requires_grad=False的节点.grad 和 .grad_fn都是None
**
- 要在backward()之后仍然保留非叶子节点的grad,可以使用xx.retain_grad(),注意retain_grad()一定要写在backward()前面。

- 使用hook。register_full_backward_hook
二、Setting requires_grad
- requires_grad是一个flag,除了nn.Parameter对象都默认为False,以便于从梯度计算中排除子图。requires_grad=False —> requires_grad=False,grad=None
- During the forward pass, an operation is only recorded in the backward graph if at least one of its input tensors require grad.
- During the backward pass (.backward()), only leaf tensors with requires_grad=True will have gradients accumulated into their .grad fields.
- To freeze parts of your model, simply apply .requires_grad_(False) to the parameters that you don’t want updated,then these parameters will have .grad and .grad_fn to be set None and None.
比如:
model = torchvision.models.vgg16(pretrained=True)
for param in model.features.parameters():
param.requires_grad = False
- requires_grad can also be set at the module level with nn.Module.requires_grad_(). When applied to a module, .requires_grad_() takes effect on all of the module’s parameters (which have requires_grad=True by default).
注意事项:
- requires_grad属性置为 False或者默认时,不能在对该tensor计算梯度.grad或者.grad_fn,否则会进行报错。RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn.
- 整数型的tensor并没有requires_grad这个属性
torch.tensor([3,4], requires_grad=True),只有浮点类型的tensor可以计算梯度。 - 在创建tensor后也可以通过**requires_grad_()**方法设置该参数,但是只有叶子节点才可以设置该参数。
三、detach()
detach方法就是返回了一个新的张量,该张量与当前计算图完全分离,新张量与原张量共享数据的存储空间,一变都变,新张量requires_grad=False,grad=None。
举例:
from torchviz import make_dot
x=torch.tensor(2.0, requires_grad=True)
y=2*x
z=3+x
r=(y+z).sum()
make_dot(r)
#Detach
x=torch.tensor(2.0, requires_grad=True)
y=2*x
z=3+x.detach()
r=(y+z).sum()
make_dot(r)

四、.clone()
tensor.clone() 是 PyTorch 中用于创建张量的深拷贝(deep copy)的方法。深拷贝意味着新创建的张量与原张量有相同的数据,但它们存储在不同的内存位置,改变一个张量不会影响另一个。
基本用法
import torch
# 创建一个张量
tensor = torch.tensor([1, 2, 3])
# 克隆张量
tensor_clone = tensor.clone()
print(tensor) # 输出: tensor([1, 2, 3])
print(tensor_clone) # 输出: tensor([1, 2, 3])
# 检查它们是否是同一个对象
print(tensor is tensor_clone) # 输出: False
验证深拷贝
为了验证 clone 方法确实创建了一个深拷贝,我们可以对克隆的张量进行修改,并观察原张量是否受到影响。
import torch
# 创建一个张量
tensor = torch.tensor([1, 2, 3])
# 克隆张量
tensor_clone = tensor.clone()
# 修改克隆的张量
tensor_clone[0] = 99
print(tensor) # 输出: tensor([1, 2, 3])
print(tensor_clone) # 输出: tensor([99, 2, 3])
可以看到,修改 tensor_clone 不会影响原始的 tensor。
克隆张量时保留梯度信息
在进行自动求导时,克隆张量时可以选择保留梯度信息,这对于需要在计算图中复制张量的场景非常有用。
import torch
# 创建一个需要梯度的张量
tensor = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# 克隆张量
tensor_clone = tensor.clone()
# 检查克隆的张量是否保留了梯度信息
print(tensor_clone.requires_grad) # 输出: True
# 如果不需要保留梯度信息
tensor_clone_no_grad = tensor.clone().detach()
print(tensor_clone_no_grad.requires_grad) # 输出: False
在计算图中的使用
克隆张量时,新的张量会在计算图中创建新的节点,这对于需要在计算图中间进行操作的场景非常重要。
import torch
# 创建一个需要梯度的张量
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# 进行一次操作
y = x * 2
# 克隆中间结果
y_clone = y.clone()
# 进行进一步的操作
z = y_clone.sum()
# 进行反向传播
z.backward()
# 检查梯度
print(x.grad) # 输出: tensor([2., 2., 2.])
在这个例子中,y 和 y_clone 都在计算图中起作用,最终通过 z.backward() 计算得到 x 的梯度。
五、.grad_fn()
如果y2 = y1 + x,则y2.grad_fn()会返回“获得y2的最后一步操作的函数”,例如:
<PowBackward0> 、<MulBackward0> 或者 <AddBackward0>。
六、梯度模式Grad Modes
三个影响autograd内部计算的模式:default mode (grad mode), no-grad mode, and inference mode。上述三种都可以通过context managers上下文管理器和decorators装饰器进行切换。
Default Mode (Grad Mode)
Default Mode是唯一一个requires_grad生效的模式,在其他两个模式中requires_grad被overridden为False。
No-grad Mode
- 在No-grad Mode中所有的计算都不需要计算梯度,即使输入的require_grad=True。
- Enable no-grad mode when you need to perform operations that should not be recorded by autograd, but you’d still like to use the outputs of these computations in grad mode later.这样就不用来回切换requires_grad的True和False。
- No-grad Mode模式中,grad_fn=None,requires_grad=False
with torch.no_grad():
# 在这个代码块中进行推断操作
@torch.no_grad()
def inference_function(input_data):
# 在这个函数中进行推断操作
比如:
x = torch.tensor([1.], requires_grad=True)
with torch.no_grad():
y = x * 2
print(y.requires_grad) #False
@torch.no_grad()
def doubler(x):
return x * 2
z = doubler(x)
print(z.requires_grad) #False
def doubler(x):
return x * 2
z = doubler(x)
print(z.requires_grad) #True
Inference Mode
- Inference mode is the extreme version of no-grad mode. Just like in no-grad mode, computations in inference mode are not recorded in the backward graph, but enabling inference mode will allow PyTorch to speed up your model even more. This better runtime comes with a drawback: tensors created in inference mode will not be able to be used in computations to be recorded by autograd after exiting inference mode.
- Enable inference mode when you are performing computations that don’t need to be recorded in the backward graph, AND you don’t plan on using the tensors created in inference mode in any computation that is to be recorded by autograd later,比如data processing and model evaluation。
- 更准确地说,在PyTorch中,要进入完整的推断模式,需要结合以下两个步骤:
- 使用torch.no_grad():关闭梯度计算,确保在推断过程中不进行梯度更新;
- 调用model.eval():将模型切换到评估模式,这会影响某些层(如Batch Normalization和Dropout)的行为,以便在推断阶段获得正确的结果。
Evaluation Mode (nn.Module.eval())
- Evaluation Mode不是被用来失效梯度计算的,module.eval() (or equivalently module.train(False)) 和no-grad mode and inference mode没有关系,module.eval()如何起作用完全取决于模型中的modules(比如, torch.nn.Dropout、torch.nn.BatchNorm2d)。
- 推荐在训练阶段使用model.train(),在验证或测试阶段使用model.eval()。
七、data属性
# 设置好requires_grad的值为True
import torch
x = torch.tensor([1.0, 2.0], requires_grad=True)
y1 = x ** 2
print(y1)
print(y1.data)
print(y1.detach())
print(id(y1), id(y1.data), id(y1.detach()))
print(id(y1.storage()), id(y1.data.storage()), id(y1.detach().storage()))
"""
tensor([1., 4.], grad_fn=<PowBackward0>)
tensor([1., 4.])
tensor([1., 4.])
3092644292392 3092631327272 3092631327272
3092650494536 3092650494536 3092650494536
"""
- y1.detach()和y1.data返回的对象都是一样的
- y1.detach()、y1.data、y1指向的内存单元是一样的
.data是从Variable中获取底层 Tensor 的主要方式。 合并后,y = x.data得到的y是一个与x共享内存的Tensor且 requires_grad = False,它与 x 的计算历史无关。
当然,在某些情况下 .data 可能不安全。 对 x.data 的任何更改都不会被 autograd 跟踪,如果在反向过程中需要 x,那么计算出的梯度将不正确。另一种更安全的方法是使用 x.detach(),它将返回一个共享内存地址的 Tensor(requires_grad = False),但如果在反向过程中需要 x,那么 autograd 将会提示你已经修改了该张量:one of the variables needed for gradient computation has been modified by an inplace operation:
八、Optimizer.zero_grad()、loss.backward()、Optimizer.step()
- 调用backward会计算叶子节点的偏微分,如果backward已经被调用过了,此时再次调用会导致损失函数再次求导,叶子节点的梯度会和历史已经计算过的梯度累加,导致错误的梯度结果。为了阻止损失函数重复求导,在每次迭代的时候都需要对梯度进行清零操作,即
optimizer.zero_grad(),执行操作后模型model.linear.weight.grad:tensor([[0.]])。 - loss.backward()计算了模型输出的损失函数对于模型参数的偏微分。When we call loss.backward(), PyTorch traverses this autograd graph in the reverse direction to compute the gradients and accumulate their values in the grad attribute of those tensors (the leaf nodes of the graph).
- 每一个optimizer都将模型参数作为第一个输入,All parameters passed to the optimizer are retained inside the optimizer object so the optimizer can update their values and access their grad attribute。
optimizer = optim.SGD(model.parameters(), lr=1e-3)
每个optimizer都有两个方法:
- zero_grad zeroes the grad attribute of all the parameters passed to the optimizer upon construction.
- step updates the value of those parameters according to the optimization strategy implemented by the specific optimizer.
常见的训练八股文:
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
如何统计模型训练参数的总数:
numel_list = [p.numel() for p in model.parameters() if p.requires_grad == True]
sum(numel_list)

















 4246
4246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











