







前言
前面介绍了MySQL各种连接,包括常用的内连接、外连接、全连接、笛卡尔积以及不常用的自然连接和USING连接。下面将详细介绍MySQL中EXPLAIN,这个对我们优化慢sql有很大作用。老规矩还是把之前文章传送一下。
传送门:
MySQL查询优化器在基于成本和规则对一条查询语句进行优化后,会生成一个执行计划。这个执行计划展示了接下来执行查询的具体方式,比如多表连接的顺序是什么,采用什么访问方法来查询某个表等等。这就是接下来要讲的EXPLAIN语句。
具体EXPLAIN的用法如下:
EXPLAIN SELECT * FROM `students`在执行的查询语句前加上EXPLAIN关键字,显示内容如下:
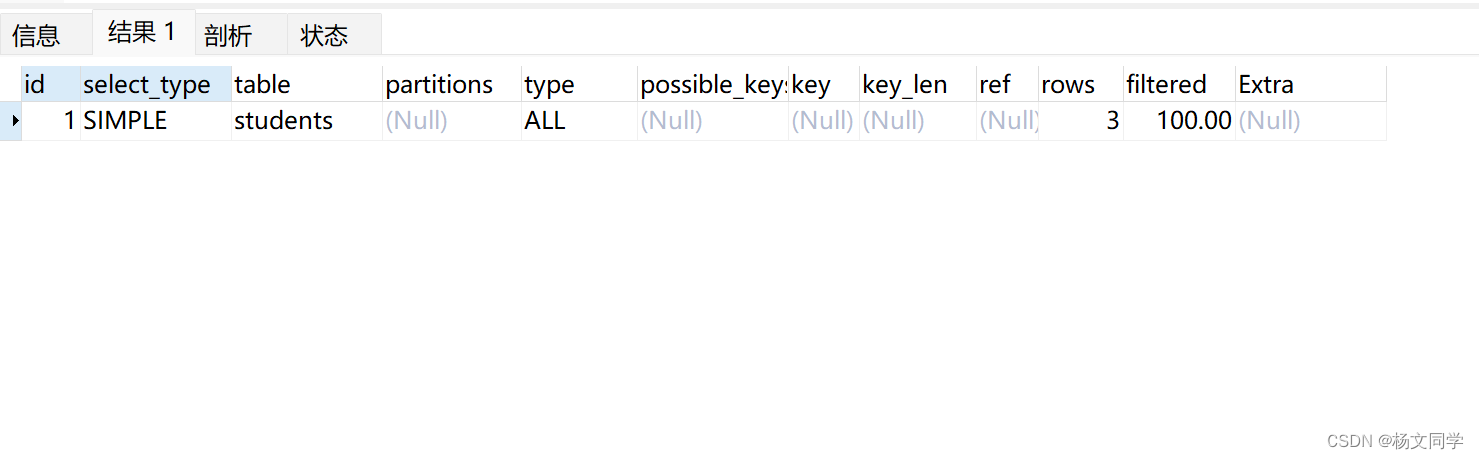
上面输出的内容就是执行计划,下面就依次介绍输出的每个列都表达什么意思,以及在这个执行计划的辅助下,如何改进自己的查询语句。其实不只是SELECT可以加EXPLAIN,INSERT、DELETE、UPDATE都可以加,但是SELECT用到的地方更多,所以本篇文章只会介绍SELECT的EXPLAIN具体用法。
| 列名 | 描述 |
| id | 在一个复杂的查询语句中,每个SELECT关键字都对应一个唯一的id |
| select_type | SELECT关键字对应的查询类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际使用到的索引 |
| key_len | 实际使用的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估需要读取的记录条数 |
| filtered | 针对预估需要读取的记录,经过筛选条件过滤后剩余记录条数的百分比 |
| Extra | 一些额外的信息 |
不了解的EXPLAIN的,看着这么多列,可能一脸懵逼,下面我就依次具体介绍每个列。希望和大家一起熟练掌握EXPLAIN相关内容。
老规矩,我们还是创建几个表,来具体演示EXPLAIN的执行计划。根据最常用的订单场景,来创建几张表。
//客户表
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY AUTO_INCREMENT,
CustomerName VARCHAR(100) NOT NULL,
ContactName VARCHAR(100),
Country VARCHAR(50)
);
//产品表
CREATE TABLE Products (
ProductID INT PRIMARY KEY AUTO_INCREMENT,
ProductName VARCHAR(100) NOT NULL,
SupplierID INT,
CategoryID INT,
Unit VARCHAR(50),
Price DECIMAL(10, 2)
);
//订单表
CREATE TABLE Orders (
OrderID INT PRIMARY KEY AUTO_INCREMENT,
OrderNumer VARCHAR(50),
CustomerID INT,
OrderDate DATE,
Status VARCHAR(50),
UNIQUE INDEX uq_order_number(OrderNumer),
INDEX idx_order_date_customer_id (OrderDate, CustomerID)
);
//订单详情表
CREATE TABLE OrderDetails (
OrderDetailID INT PRIMARY KEY AUTO_INCREMENT,
OrderID INT,
ProductID INT,
Quantity INT,
Price DECIMAL(10, 2)
);
其中订单表,有一个唯一索引和联合索引。
可以执行下面的存储过程,批量插入数据。
-- 存储过程插入Customers数据
CREATE PROCEDURE InsertCustomers()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000 DO
INSERT INTO Customers (CustomerName, ContactName, Country)
VALUES (CONCAT('Customer', i), CONCAT('Contact', i), 'Country');
SET i = i + 1;
END WHILE;
END//
-- 存储过程插入Products数据
CREATE PROCEDURE InsertProducts()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000 DO
INSERT INTO Products (ProductName, SupplierID, CategoryID, Unit, Price)
VALUES (CONCAT('Product', i), FLOOR(1 + RAND() * 100), FLOOR(1 + RAND() * 10), CONCAT('Unit', i), ROUND(RAND() * 100, 2));
SET i = i + 1;
END WHILE;
END//
-- 存储过程插入Orders数据
CREATE PROCEDURE InsertOrders()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000 DO
INSERT INTO Orders (OrderNumer, CustomerID, OrderDate, Status)
VALUES (CONCAT('ORD', LPAD(i, 7, '0')), FLOOR(1 + RAND() * 1000), CURDATE() - INTERVAL FLOOR(RAND() * 3650) DAY, ELT(FLOOR(1 + RAND() * 4), 'Pending', 'Shipped', 'Delivered', 'Cancelled'));
SET i = i + 1;
END WHILE;
END//
-- 存储过程插入OrderDetails数据
CREATE PROCEDURE InsertOrderDetails()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000 DO
INSERT INTO OrderDetails (OrderID, ProductID, Quantity, Price)
VALUES (FLOOR(1 + RAND() * 1000), FLOOR(1 + RAND() * 1000), FLOOR(1 + RAND() * 20), ROUND(RAND() * 100, 2));
SET i = i + 1;
END WHILE;
END//
DELIMITER ;
-- 调用存储过程插入数据
CALL InsertCustomers();
CALL InsertProducts();
CALL InsertOrders();
CALL InsertOrderDetails();注:下面的sql,有的可能没有意义,只是为了造出EXPLAIN对应的结果。
id
我们知道,查询语句一般都以SELECT关键字开头,比较常见的查询,比如单表查询,多表关联查询。但还有另外两种情况,会有多个SELECT关键字,查询中包含子查询,还有个就是UNION子句的情况。
那么SELECT关键字跟id有什么关系,查询语句中每出现一个SELECT关键字,EXPLAIN就会分配一个唯一的id值,简单来说就是查询语句中有几个SELECT关键字,就有几个不同的id值。
- 单表查询
EXPLAIN SELECT * FROM `orders` where OrderID = 1执行结果:

- 连接查询
EXPLAIN SELECT * FROM `orders` a inner join orderdetails b on a.OrderID = b.OrderID执行结果:

对于连接查询来说,一个SELECT关键字后面的FROM中可以写多个表,那么在EXPLAIN执行计划中,每个表都会对应一条记录,但是这些记录的id值都是相同的。
连接查询和单表查询还有个区别:出现在前面的表表示驱动表,出现后面的表表示被驱动表。所以从上面执行结果可以看出,EXPLAIN执行计划,准备让orderdetails表作为驱动表,orders表作为被驱动表。(INNER JOIN驱动表是可以互换位置的,不知道驱动表和被驱动表的,可以翻看前面连接原理的文章)
- 子查询
sql1:
EXPLAIN SELECT * FROM `customers` where CustomerID in (select CustomerID from orders)
这里需要注意的是,虽然语句中包含一个子查询,但是查询优化器可能对设计的子查询语句进行重写,从而转换成连接查询。如果执行子查询的EXPLAIN,id显示的是一样的,那么就表示是连接查询。还可以看出,又多了条table列<subquery2>的数据,这个我们下面再讲。
sql2:
explain select * from orders where OrderID IN
(select OrderID from orderdetails where ProductId = 100) OR status = 'Delivered'执行结果:

这个id显示的是不一样的,所有它是一个子查询。
- UNIION子句
EXPLAIN
select * from `orders` where Status = 'Shipped'
union
select * from `orders` where Status = 'Pending'执行结果:

根据上面的执行结果可以看出,前两条数据没有问题,第三条是什么意思。前篇文章说了UNION的用法,它会把多个查询的结果集合并成一个结果集 ,并且还要去重,那怎么去重呢?MySQL使用的是内部临时表,在内部创建了一个名为<union1,2>的临时表,所以id也会不一样。
因为UNION要去重,那么UNION ALL会不会也创建临时表呢?答案是不会。
EXPLAIN
select * from `orders` where Status = 'Shipped'
union all
select * from `orders` where Status = 'Pending'执行结果:

select_type
通过前面id我们知道,一条大的查询语句里面可以包含若干个SELECT关键字,每个SELECT关键字代表着一个小的查询语句。而每个SELECT语句的FROM后面可以包含多个表,每张表都会对应一条执行计划的记录,并且id值是相同的。
MySQL为了知道,每个小查询的SELECT在整个大查询中扮演的是什么角色,所以就有了select_type属性。
| 列名 | 描述 |
| simple | 简单查询,不包含UNION查询或子查询 |
| primary | 最外层的查询 |
| union | 第二个或后续的 SELECT 查询语句,它是 UNION 语句的一部分 |
| union result | UNION 的结果集 |
| subquery | 子查询中的第一个 SELECT 语句 |
| dependent subquery | 子查询中的第一个 SELECT 语句,依赖于外部查询 |
| dependent union | 第二个或后续的 SELECT 查询语句,是 UNION 语句的一部分,并依赖于外部查询 |
| derived | 衍生表(临时表)查询,通常是子查询中的 FROM 子句 |
| materialized | 表示一个在执行计划中需要物化的子查询 |
| uncacheable subquery | 表示结果集不能被缓存的子查询,每次都需要重新计算 |
| uncacheable union | UNION 中包含不能被缓存的子查询 |
- simple
查询语句中不包含UNION或者子查询的语句都都算是simple类型。可以参照上面说过的单表查询和连接查询的例子,这里就不赘述了。
- primary
对于包含UNION、UNION ALL或者子查询的大查询来说,它是由几个小查询组成。其中最左边那个查询的select_type就是primary。可以参照上面说过的子查询和UNION子句的例子,这里就赘述了。
- union
对于包含UNION或者UNION ALL的大查询来说,它是由几个小查询组成的,其中除了最左边的那个小查询是primary类型以外。其余小查询的select_type就是UNION。可以参照上面说过的UNION子句的例子,这里就赘述了。
- union result
上面我们说过,在使用UNION时,MySQL会使用临时表来完成去重的工作,针对该临时表的查询就是union result。可以参照上面说过的UNION子句的例子,这里就赘述了。
- subquery
如果包含子查询的语句不能转化为连接查询,那么该子查询是不相关子查询,而且查询优化器决定将该子查询物化的方案来执行,该子查询的第一个SELECT关键字代表的那个查询的select_type就是subquery。(所谓物化,就是将子查询的结果存储在一个临时表中,以便主查询可以更高效地访问这些结果,所以物化的子查询只会执行一次)
sql:
explain select * from orders where OrderID IN
(select OrderID from orderdetails where ProductId = 100) OR status = 'Delivered'执行结果:
因为有 OR status = 'Delivered',所以无法转换为连接查询。
- dependent subquery
dependent subquery是指子查询中的某些列依赖于外部查询中的列。换句话说,子查询的执行依赖于外部查询的每一行。这种情况下,子查询不能独立于外部查询执行,每次外部查询处理一行数据时,子查询都会重新执行一次。
sql:
explain
SELECT OrderNumer,
( SELECT SUM( Price ) FROM orderdetails WHERE orders.OrderID = orderdetails.OrderID ) AS total
FROM
orders执行结果:

相较于subquery类型,dependent subquery子查询会被执行多次。
- dependent union
在包含UNION或者UNION ALL的大查询中,如果各个小查询都依赖于外层查询,则除了最左边的那个小查询外,其余小查询的select_type就是dependent union。说的可能有点绕,我们看下具体的例子。
sql:
EXPLAIN select * from orders where OrderID IN
(
SELECT OrderID FROM orders WHERE status = 'Pending'
union
SELECT OrderID FROM orders WHERE status = 'Shipped'
)执行结果:

大查询中包含一个子查询,子查询中又包含UNION连接的两个小查询。所以union前面一个就是dependent subquery,后面一个就是dependent union。
- materialized
当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层进行连接查询,那么该子查询对应的select_type就是materialized。
sql:
explain select * from orders where OrderID IN
(select OrderID from orderdetails where ProductId = 100) 执行结果:

执行计划有3条记录,其中前两条id都是1,说明是连接查询。其中有条记录是<subquery2>,表示是id为2对应子查询执行之后产生的物化表。然后将orders和该物化表进行关联查询。
- derived
derived表示派生表,也就是在查询中使用的子查询。派生表是通过在查询中定义的子查询创建的临时表,这些子查询在主查询执行之前先被执行。
sql:
EXPLAIN select * from
(
SELECT status,count(*) as num FROM orders group by status
) as tab where num > 1执行结果:

从执行计划可以看出,id为2的记录就代表子查询的执行方式,是derived。id为1代表最外层查询,它的table列是<derived2>,表示该查询是针对将派生表物化之后的表进行查询。
- uncacheable subquery:不常用
- uncacheable union:不常用
partitions
查询访问的分区。对于非分区表,该字段显示 NULL。
type
前面说过,执行计划的一条记录代表着MySQL对某个表执行查询时的访问方法,type就表示这个访问方法具体类型。下面的排序是执行效果从最优到最差。
| 类型 | 描述 |
| system | 该表只有一行,这是const连接类型的一种特殊情况。 |
| const | 通过主键或者唯一二级索引列进行等值查询 |
| eq_ref | 执行连接查询时,如果被驱动表是通过主键或不允许为NULL值的唯一二级索引列进行等值匹配 |
| ref | 通过二级索引列进行等值查询 |
| fulltext | 全文索引 |
| ref_or_null | 类似于ref,但是多了一个为空的条件 |
| index merge | 索引合并,可以分三种情况:Intersection 索引合并, Union索引合并,Sort-Union索引合并。 |
| unique_subquery | 是一个索引查找函数,它完全取代了子查询以提高效率 |
| index_subquery | |
| range | 使用索引查找在特定范围内的行 |
| index | 扫描全索引,比扫描全表效率要高 |
| all | 全表扫描 |
- system
当表中只有一条数据并且该表使用的存储引擎是MyISAM、MEMORY,这种引擎统计数据是精准的。我们主要介绍的存储引擎是InnoDB,这里就不做过多了解。
- const
表中最多有一个匹配行,在查询开始时读取。因为只有一行,所以该行中列的值可以被优化器的其余部分视为常量。const非常快,因为它们只被读取一次。
const用于将PRIMARY KEY或UNIQUE索引的所有部分与常数值进行比较。
EXPLAIN SELECT * FROM `orders` where OrderID = 100
EXPLAIN SELECT * FROM `c` where OrderNumer ='ORD0000003'上面的orders表,OrderID是主键,OrderNumer 是唯一索引。执行结果就不展示了。
- eq_ref
对于来自前一个表的每个行组合,从这个表中读取一行。除了系统类型和const类型之外,这是最好的连接类型。(执行连接查询时,如果被驱动表是通过主键或不允许为NULL值的唯一二级索引列进行等值匹配)
- ref
对于来自前一个表的每个行组合,将从这个表中读取具有匹配索引值的所有行。如果连接只使用键的最左边的前缀,或者键不是PRIMARY key或UNIQUE索引(换句话说,如果连接不能根据键值选择单行),则使用ref。如果所使用的键只匹配几行,则这是一个很好的连接类型。
- fulltext
fulltext是一种专门用于对文本数据进行快速全文搜索的索引类型。它可以在大文本字段(例如 VARCHAR 和 TEXT 类型)上创建,并允许用户进行高效的自然语言搜索。这种平时很少用到,有场景用到快速全文搜索,可以详细了解下。
- ref_or_null
这种类型类似于ref,但是MySQL会对包含NULL值的行进行额外的搜索。这种类型优化最常用于解析子查询。我们把order表中status创建为普通二级索引。
sql:
EXPLAIN select * from orders where status = 'Shipped' or status is null执行结果:

- index merge
索引合并这个在我之前的文章,单表访问方法,有详细介绍。
简单来说,一个查询sql中,where条件可能有多个索引列,具体使用哪一个,就要看执行计划了。但是还有另外一种特殊情况,就是多个索引列都执行,取几个索引的交集或并集,从而减少回表次数。
//key1和key3列都是二级索引
select * from demo_table where key1 = 'a' and key3 = 'c';
使用key1的二级索引和key3的二级索引。key1索引的扫描区间是[a,a],key3的扫描区间是[b,b],然后在两者的操作结果中找出主键值相同的记录(就是共有的主键值)。然后根据共有的主键值回表,去聚簇索引中查找完整记录。
上面的例子说的是Intersection 索引合并,还有Union索引合并,Sort-Union索引合并。都是不同的特殊情况,使用条件也有点苛刻。
- unique_subquery
unique_subquery 是一种特定的连接类型,用于优化 IN 子查询。它表明 MySQL 将子查询转换为一种更高效的形式,利用唯一索引来快速查找结果。这种类型替换了一些IN子查询的eq_ref,Unique_subquery只是一个索引查找函数,它完全取代了子查询以提高效率。
(说了这么多,其实就是IN子句中的sql是一个eq_ref类型的语句,还要知道就是unique_subquery 是MySQL 优化器的一种优化类型)
value IN (SELECT primary_key FROM single_table WHERE some_expr)- index_subquery
index_subquery相比较于unique_subquery,其实差不多,唯一的区别是,index_subquery的子查询中的sql语句是一个二级索引列。
//key_column是二级索引
value IN (SELECT key_column FROM single_table WHERE some_expr)- range
只检索给定范围内的行,使用索引选择行。当使用=、<>、>、>=、<、<=、is NULL、<=>、BETWEEN、LIKE或IN()操作符将键列与常量进行比较时,可以使用range。这个很简单,就不再 详细介绍了 。
- index
当 type 列的值为 index 时,这表示 MySQL 进行了一次全索引扫描。与全表扫描相比,全索引扫描只扫描索引而不是数据行。索引扫描比全表扫描更高效,因为索引通常比数据行小得多。
EXPLAIN select status from ordersstatus是orders表的一个二级索引。
- all
all,全表扫描 ,性能肯定是最,也是需要优化sql,最基础的一步。
possible_keys和key
possible_keys列表示在某个查询语句中,对某个表执行单表查询中可能用到的索引有哪些。
key则表示实际用到的索引有哪些。
sql:
EXPLAIN select * from orders where status = 'Shipped' or OrderID > 100执行结果:

根据上面的执行结果可以看出,可能使用到的索引是主键和status的二级索引。但实际没有使用到任何索引,而是全表扫描。这是因为MySQL优化器认为,执行索引的代价大于全表扫描。
另外需要注意的一点是,possible_keys列中的值并不是越多越好,可以使用的索引越多,查询优化器在计算查询成本时话费的时间就越长。如果可以,尽量删除那些用不到的索引。
key_len
key_len列表示MySQL决定使用的索引列的长度。帮助理解 MySQL 在查询中实际使用了索引的哪一部分。这可以帮助优化索引和查询。如果key列为NULL,则key_len列也为NULL。
sql:
EXPLAIN select * from orders where status = 'Shipped' 执行结果:

根据执行结果,可以看出 key_len为153,那么这个值是怎么来的?这个还要说下,key_len表示 MySQL 使用的索引键的长度,是以字节为单位来计算。ken-len是由三部分组成:
- 该列的实际数据最多占用的存储空间长度。对于固定长度类型列来说,比如INT类型,该列的实际数据最多占用的存储空间长度就是4字节。但对于可变长度VARCHAR来说,后面的数据表示占用的字符数量,而一个字符对应的字节数,还要根据MySQL使用的字符集有所不同。比如utf-8,一个字符对应3个字节。
- 如果该列可以存储NULL值,则key_len的值在该列的实际存储长度基础上再加1。
- 我们之前介绍MySQL行格式的时候,说过对于可变长度数据类型,行格式中还会有1~2字节来存储该列实际占用的存储空间长度,所以key_len的值在原来的基础上个还要加2。
所以上述的153的值,计算方式就是,status的数据类型是VARCHAR(50),我的编码格式是utf-8,所以我的字节是 50 * 3,status可以为空,所以再加1,又是可变长度,所以再加2,最后就是153。
key_len的值还有个重要的作用,就是判断在使用联合索引的时候,到底使用了哪几个列。
sql:
EXPLAIN select * from orders where OrderDate = '2024-01-01' AND CustomerID = 66执行结果:

在orders中,OrderDate和CustomerID是联合索引。OrderDate是date类型,长度是3,可以为空,CustomerID是int,长度是4,也可以为空,所以加起来就是9,说明联合索引中的所有列,都使用到了。
还有另外一种情况:
EXPLAIN select * from orders where OrderDate > '2024-01-01' AND CustomerID = 66执行结果:

根据上面的执行结果,key_len变成了4,所以联合索引中CustomerID列是没有用到的。这是因为当遇到范围条件时,MySQL 只能使用联合索引的前缀部分。范围条件会限制索引的使用,因为在找到范围的起点之后,后续的查找不能继续高效地利用索引的剩余部分。这是因为范围条件会使索引查找变得不确定,后面的列无法通过简单的索引查找来确定。(但是这条语句使用了索引下推)
ref
当访问方法type的类型是,const、eq_ref、ref、ref_or_null、unique_subquery、index_subquery时,ref列展示的就是与索引列进行等值匹配的内容是什么,可能是常量或是某个具体列名,还有可能是一个函数。
sql1:
EXPLAIN select * from orders where OrderID = 686执行结果:

sql2:
EXPLAIN select * from orders a inner join orders b on a.OrderID = b.OrderID执行结果:

根据执行结果可以看出,被驱动表b,的访问方法是 eq_ref,而对于的ref列的值是test_db.a.OrderID。这表明在对b表进行访问时,与b表的id进行等值匹配的是a表的OrderID。
sql3:
EXPLAIN select * from orders a inner join orders b on a.OrderID = UPPER(b.OrderID)执行结果:

ref说下来,感觉没啥用。。ref显示了 MySQL 在查询中用于索引查找的值或列。具体而言,它表示用于匹配索引的常量或列。这可以帮助你理解 MySQL 如何通过索引查找匹配行,并有助于优化查询性能。
rows
rows列表示MySQL认为执行查询必须检查的行数。对于InnoDB的表,这个数字是一个估计值,可能并不总是准确的。
在查询优化器决定使用全表扫描的方式对某个表执行查询时,执行计划的rows列就代表该表的估计行数。如果使用索引来执行查询,执行计划的rows列就代表预计扫描的索引记录行数。
filtered
对于单表查询来说,filtered列值没什么意义,我们更关注的是在连接中驱动表对应的执行计划的filtered值。
sql:
EXPLAIN select * from orderdetails a inner join products b on a.ProductID = b.ProductID执行结果:

从执行计划中可以看出,查询优化器把a表作为驱动表,把b作为被驱动表。同时也可以看出驱动表a的执行计划的rows列为1005,filtered列为100.00。这就意味着驱动表a要对被动表b大约执行1005 * 100.00% = 1005次。
其中最大值是100,这意味着没有对行进行过滤。从100开始递减的值表示过滤量在增加。
简单来说就是,rows显示检查的估计行数,rows × filtered显示与下表连接的行数。例如,如果rows为1000,filtered为50.00(50%),则要与下表连接的行数为1000 × 50% = 500。
Extra
Extra列是用来说明一些额外信息的,我们可以通过这些额外信息来更准确地了解MySQL到底如何执行给定的查询语句。Extra列可能显示额外的信息有几十个,我们这里主要介绍主要的,如果大家用到这里没有介绍的,可以到MySQL官网里查询一下。
- Impossible WHERE:查询语句的WHERE子句永远为false时,会提示该额外信息。
sql:
EXPLAIN select * from products where 1<>1执行结果:

- Using index:使用索引覆盖执行查询时会提示该额外信息。
sql:
EXPLAIN select CustomerID from orders where OrderDate > '2024-01-01' 执行结果:

- Using index condition:如果查询语句在执行过程中使用索引下推特性,则会提示该额外信息。
EXPLAIN select * from orders where OrderDate > '2024-01-01' AND CustomerID = 66执行结果:

具体什么是索引下推,这个大家可以自行了解下。我这里大概描述一下,我们知道MySQL程序分为server层和存储引擎层。以上面的sql为例,其中OrderDate和CustomerID是联合索引,在没有索引下推的情况下,我们在存储引擎B+树上二级索引找到一条符合OrderDate > '2024-01-01'的一条记录,这时就会根据二级索引记录中的主键,进行回表,查询其余列的信息。这时会返回给server层,然后server层会进行CustomerID = 66判断,不成立则跳过该记录,成立则返回给客户端。继续上一步,直到整个OrderDate > '2024-01-01'查询完毕。
那有索引下推的情况下,在存储引擎B+树上二级索引找到一条符合OrderDate > '2024-01-01'的一条记录,这时就会判断CustomerID = 66条件是否成立,成立则回表返回整条记录给sever层,不成立则跳过。
大家肯定看出来了,少了一步回表的操作。只是改了一点,但是对性能提高是很有帮助的,因为回表的代价也是挺大的。
当后面的where条件只是普通列的时候,则Extra就不会展示Using index condition。
这里需要注意的是索引下推只适合二级索引。
但是还有一种情况,也会返回Using index condition。
EXPLAIN select * from orders where status like 're%';执行结果:

status是一个二级索引,不是联合索引,为什么也会有Using index condition。我这里在网上找到的是,MySQL为了编码方面做的一种冗余处理,多判断一边没啥印象。我认为都差不多,也可能是MySQL存储引擎,对二级索引的查询默认有索引下推的优化。
- Using where:当某个搜索条件需要在server层进行判断时,Extra则会展示该提示。
sql:
EXPLAIN select * from orderdetails where OrderID = 100执行结果:

- Using join buffer (Block Nested Loop):在连接查询的执行过程中,当被驱动表不能有效地利用索引加快访问速度时,MySQL会为其分配一块名为连接缓冲区的内存来加快查询速度。可以看我之前的 连接查询的文章,有详细介绍。
- Using sort_union(...), Using union(...), Using intersect(...):索引合并,括号里的是合并的具体索引列。上面有大致介绍索引合并,这里就不再赘述了。
- Using filesort:MySQL做一个额外的传递来找出如何按排序顺序检索。如果在排序时,无法使用索引,只能在内存中(记录较少)或者在磁盘中(记录较多)进行排序。MySQL把这种排序称为文件排序filesort
sql:
EXPLAIN select * from orderdetails where OrderID = 100 order by Price执行结果:

如果使用到了索引排序,则不会展示Using filesort。
- Using temporary
在许多查询过程中,可能会用到临时表,比如去重、排序、分组。如果不能有效的利用索引,MySQL很可能会在内部创建临时表来帮助完成此操作。
sql:
EXPLAIN select COUNT(*) AS Num,CategoryID from products group by CategoryID执行结果:

如果执行计划出现Using temporary,说明这个需要优化。因为创建和维护临时表需要很大的成本,所以最好使用索引来替代临时表。如果将CategoryID索引,如下:

总结
说了这么多,大家可能对EXPLAIN有了大致的了解。但是具体怎么优化,可能还是有点懵,大家可以把自己需要优化的sql,拿出来分析一下。
最主要看以下指标:
type,大家可以根据上面从最优到最差的排序,对自己的sql性能有个了解。
key和key_len,最好肯定还是用到索引,有索引执行效率还是很明显的。
rows和filtered,也是一个重要的参考指标,如果被驱动表需要访问很多次,那么执行时长相对也就变长了。所以多表联查的时候,需要考虑哪个做为驱动表,能用内连接 ,不用外连接。
Extra,这个也很重要,比如,Using where,MySQL 需要在存储引擎返回的数据上进一步应用 WHERE 子句过滤。这表示在存储引擎层面没有完全利用索引。
Using temporary:MySQL 需要使用临时表来存储结果。可能会影响性能,尤其是大数据量时。
Using filesort:MySQL 需要进行文件排序,而不是使用索引顺序。这通常表示排序操作没有利用索引,可能需要优化。(有时进行GROUP BY时,没加ORDER BY,也会有Using filesort,这是因为MySQL会默认加上。可以手动加上ORDER BY NULL)
如果数据量达到一定级别,已经没有优化的空间了。如果是做统计,那么就需要加统计表,定时去更新统计表。如果不是做统计,那么就要考虑分表分库。解决方案有一个递增的过程。
参考:















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









