







前言
在上篇文章中,说了MySQL连接的本质与原理,以及连接的两种算法。本篇文章再补充一下MySQL各种连接方式,从而更加深入的了解。
没有看前面几篇文章,推荐可以先看下
传送门:
MySQL的连接总体分为两种,一种是内连接和外连接。本文将连接的类型分的更细一点,分别为:内连接、外连接、全连接、全外连接、交叉连接、自然连接、using连接。
为了顺利进行下去,先创建两张表,很简单:学生表和成绩表,然后插入几条数据。
-- 创建学生表
CREATE TABLE students (
student_id INT PRIMARY KEY AUTO_INCREMENT,
student_name VARCHAR(50) NOT NULL,
age INT NOT NULL,
is_delete int
) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- 创建成绩表
CREATE TABLE grades (
grade_id INT PRIMARY KEY AUTO_INCREMENT,
student_id INT NOT NULL,
subject VARCHAR(50) NOT NULL,
score DECIMAL(5, 2) NOT NULL,
is_delete int
) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- 插入学生数据
INSERT INTO students (student_name, age, is_delete) VALUES
('张三', 20, 0),
('李四', 21, 0),
('王五', 22, 0),
('麻子', 23, 0);
-- 插入成绩数据
INSERT INTO grades (student_id, subject, score, is_delete) VALUES
(1, '数学', 85.5, 0),
(1, '英语', 78.0, 0),
(2, '数学', 92.0, 0),
(2, '英语', 88.5, 0),
(3, '数学', 76.0, 0),
(3, '英语', 84.0, 0);内连接
MySQL的内连接只有一个,INNER JOIN。INNER JOIN用于从两个或多个表中选择符合连接条件的记录,内连接只返回两个关联表中都匹配的记录,所以关联表A或者关联表B都有可能是一对多的关系,是一对多或者一对一取决于ON后面的条件。上篇文章说过,对于内连接来说,驱动表和被驱动表是可以互换的,因为不影响最后的查询结果。
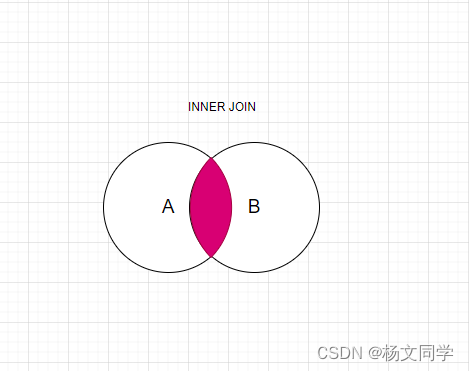
SELECT
st.student_name,
gr.score
FROM
students st
INNER JOIN grades gr ON st.student_id = gr.student_id
//驱动表和被驱动表互换
SELECT
st.student_name,
gr.score
FROM
grades gr
INNER JOIN students st ON st.student_id = gr.student_id 查询结果很简单

外连接
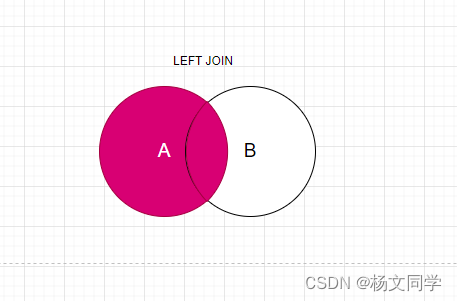
MySQL的外连接,分为左连接和右连接,即LEFT JOIN、RIGHT JOIN。这些都是我们工作中最常用到的。
左连接:左连接关联查询,返回左表中的所有行,即使在右表中没有匹配的行。如果右表中没有与左表匹配的记录,那么结果中返回的右表对应列将是NULL值。同理,表A或者关联的表B都有可能是一对多的关系,是一对多或者一对一取决于ON后面的条件。
SELECT
st.student_name,
gr.score
FROM
students st
LEFT JOIN grades gr ON st.student_id = gr.student_id 返回结果也很简单:
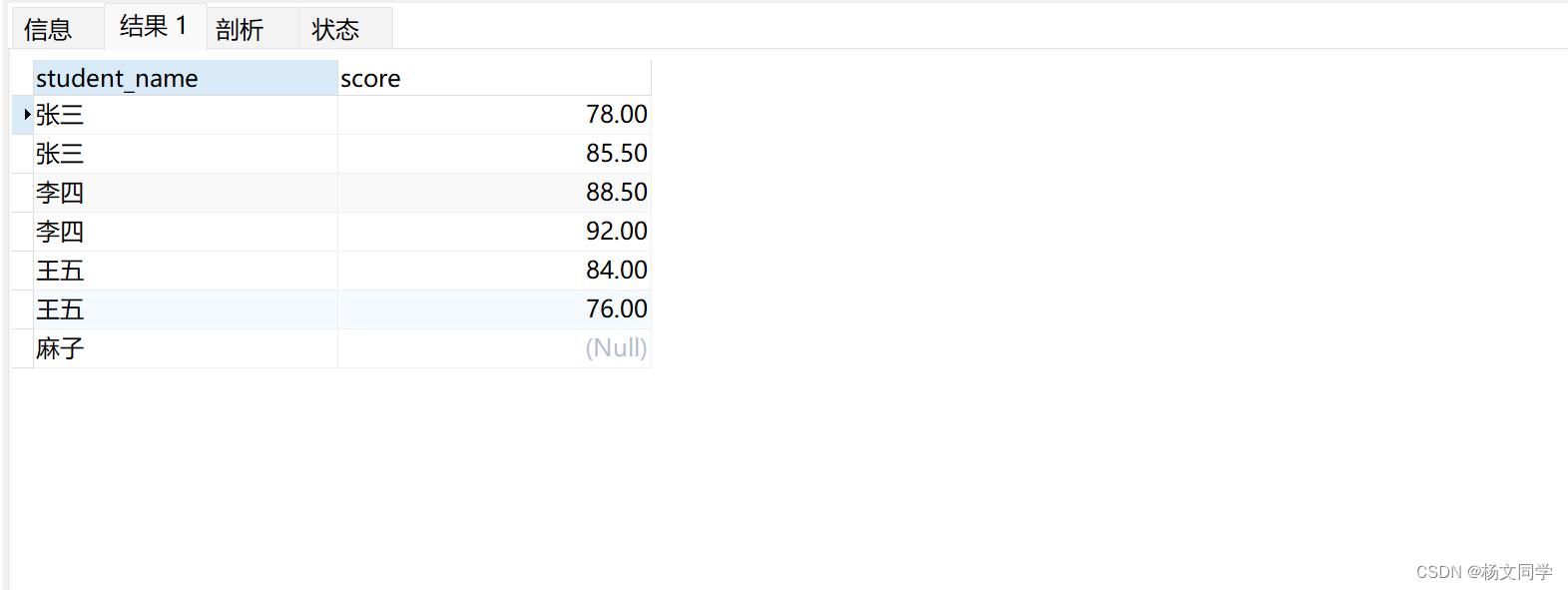
以上都很容易理解,下面我介绍一下,写在ON和WHERE后面,有什么不同。为了顺利的进行,我们先把grades表中王五的成绩给删掉,即is_delete改为1。
下面我们看下这两个sql:
//sql1
SELECT
st.student_name,
gr.score
FROM
students st
LEFT JOIN grades gr ON st.student_id = gr.student_id and gr.is_delete = 0
//sql2
SELECT
st.student_name,
gr.score
FROM
students st
LEFT JOIN grades gr ON st.student_id = gr.student_id
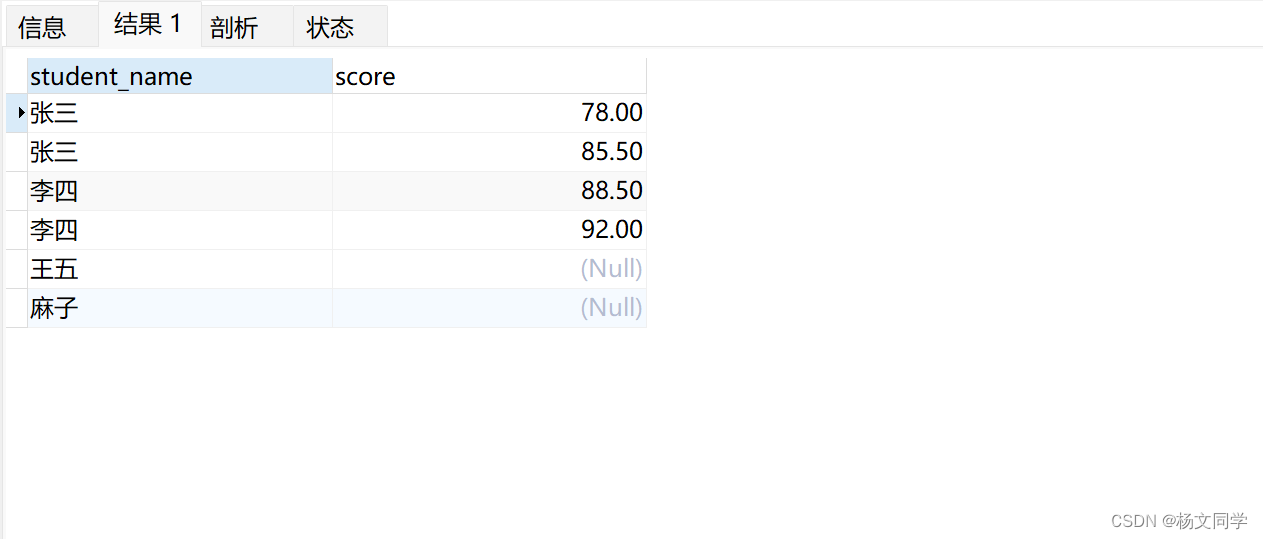
WHERE gr.is_delete = 0sql1返回的结果集为:
sql2返回的结果集为:
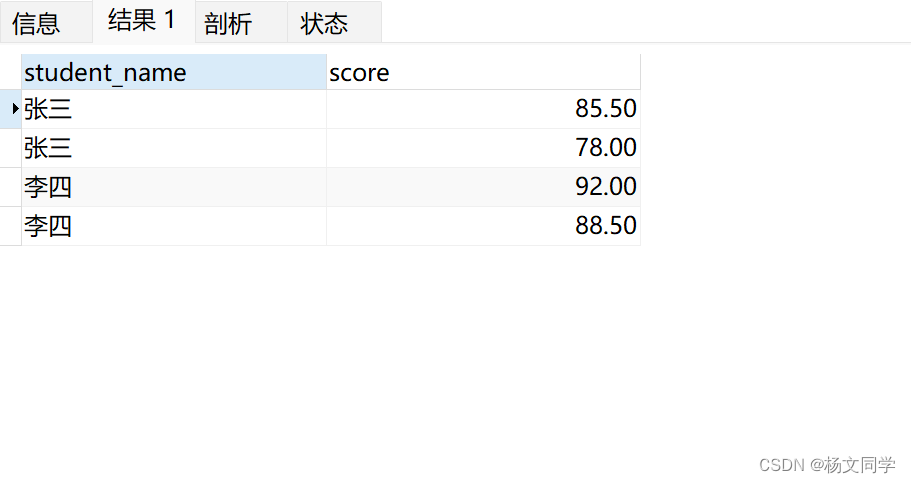
一对比很明显,sql2数据少了很多,为什么相同的条件加在ON后面和WHERE后面,数据差距这么大。
sql1执行步骤:
- 在进行LEFT JOIN时,使用的条件是st.student_id = gr.student_id and gr.is_delete = 0。这意味着 grades 中的记录只有在 student_id 匹配并且 is_deleted 为0时才会被匹配上。没有匹配上,则查询的表grades中的列的值是NULL。
- 由于没有额外的WHERE条件,所有 students中的记录都会出现在结果集中,不论 grades表中是否有匹配的记录。
sql2执行步骤:
- 首先进行左连接,把 students中的每一条记录与 grades中的记录进行匹配,条件是 st.student_id = gr.student_id。如果匹配不上,则查询的表grades中的列的值是NULL。
- 然后,由于有WHERE条件 gr.is_delete = 0。这会过滤掉那些 gr.is_delete = 0 不等于0的记录。(NULL值也不等于0)
- 这相当于一个内连接,因为所有LEFT JOIN中 grades为NULL的记录都被WHERE过滤掉了。
右连接同理,这里就不做过多介绍。
全连接
全连接即是,FULL JOIN,用于返回两个表中所有匹配和不匹配的记录。它结合了左连接(LEFT JOIN)和右连接(RIGHT JOIN)的效果,即返回左表中的所有行和右表中的所有行,并且在没有匹配的情况下,结果中的对应列将包含 NULL 值。然而,MySQL 本身并不直接支持 FULL JOIN。为了实现全连接,可以使用 UNION 运算符结合左连接和右连接来模拟全连接。
全连接在工作中用到的不是很多,但也有场景会用到。比如一个结果集,需要结合两张表的数据。但是,两张并没有关联关系。这时就需要用全连接,MySQL用UNION、UNION ALL来实现全连接。
假如上面的学生表是大学生表,现在还有一张中学生表。现在要统计某个市所有的学生(也可以在学生表创建一个字段,区分是中学生或者是大学生,这里只是为了满足场景的需要)。
CREATE TABLE middle_students (
student_id INT PRIMARY KEY AUTO_INCREMENT,
student_name VARCHAR(50) NOT NULL,
age INT NOT NULL,
is_delete int
) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
INSERT INTO middle_students (student_name, age,is_delete) VALUES
('张一', 20, 0),
('李二', 21, 0),
('王三', 22, 0),
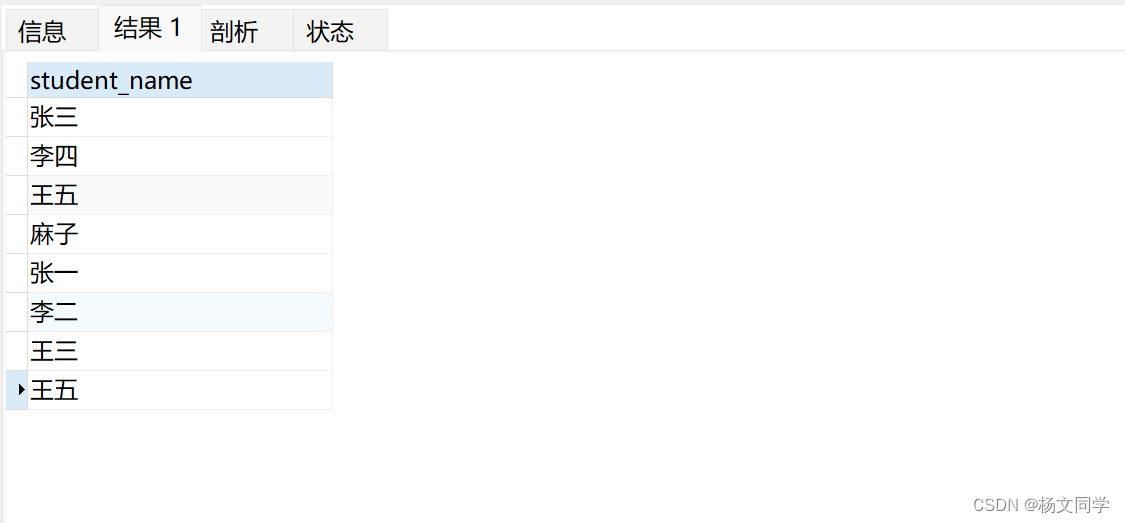
('王五', 23, 0);查询所有学生
SELECT student_name FROM students WHERE is_delete = 0
UNION ALL
SELECT student_name FROM middle_students WHERE is_delete = 0结果集也很简单
上面只是简单两个单表的UNION,也可以在两个学生表后面内连接或者外连接都可以。需要注意的是,UNION的两个结果集,字段名称和字段类型都要保持一致,否则会有语法错误。
再说一下UNION和UNION ALL的基本区别:
- 首先UNION和UNION ALL,都是将多个结果集合并为一个。
- UNION,会去除结果集中重复的行。所有性能相交于UNION ALL会低,因为有额外的开销,要去除重复的数据。
- UNION ALL,不会去除重复行,会返回所有查询结果的并集,包括重复的行。
左外连接和右外连接
LEFT JOIN也可以叫做左外连接,RIGHT JOIN也可以叫做右外连接,为了和上面外连接做区分,这里名字叫法稍有不同。其实下面这两种连接,也是LEFT JOIN和RIGHT JOIN不同使用场景的变种。
左外连接:返回左表独有的数据。
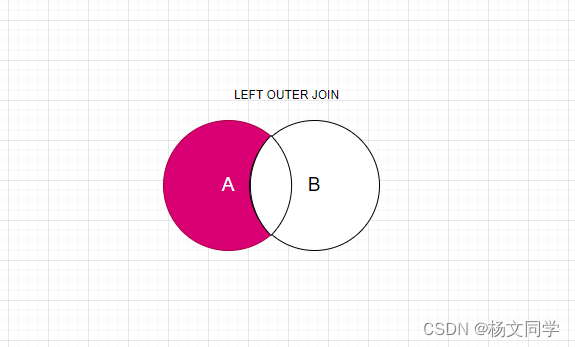
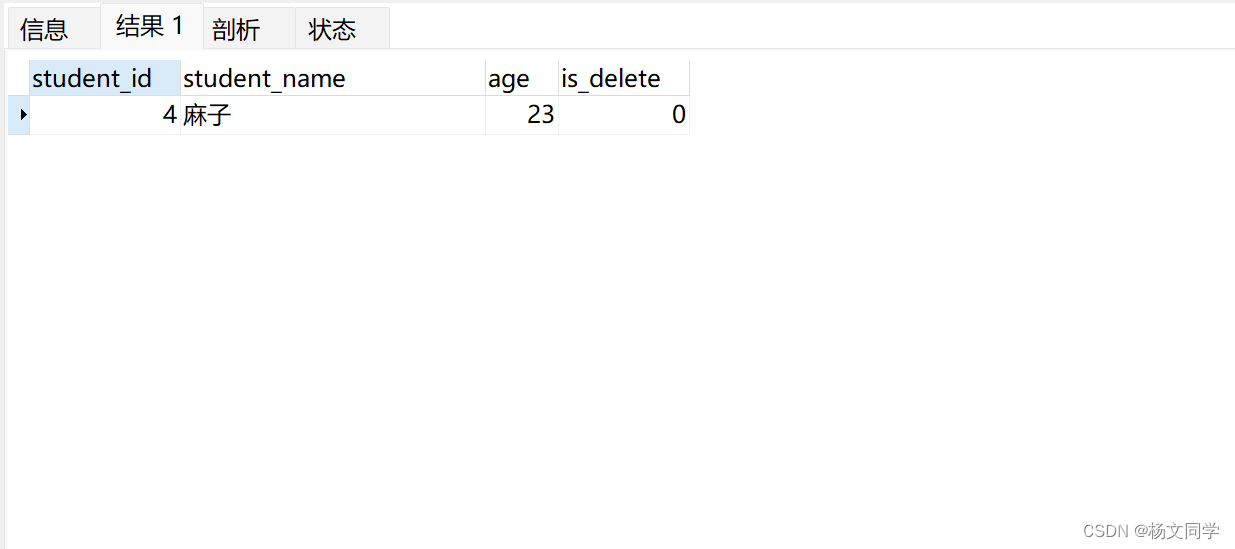
实现sql:
SELECT st.* FROM students st
LEFT JOIN grades gr ON st.student_id = gr.student_id
WHERE
gr.grade_id IS NULL查询结果集:
右外连接:返回右表独有的数据。
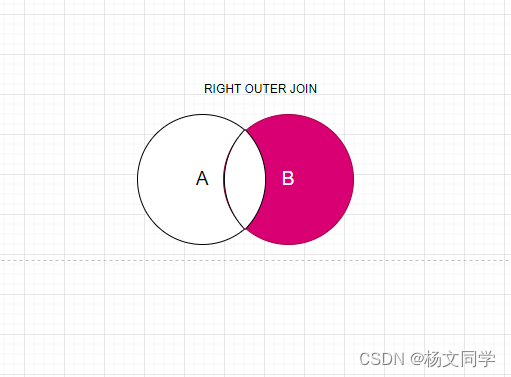
右外连接跟左外连接一样,只是JOIN语法不同,这里不再赘述。
全外连接
全外连接,大家应该也知道了,就是返回左表独有的数据和右表独有的数据。
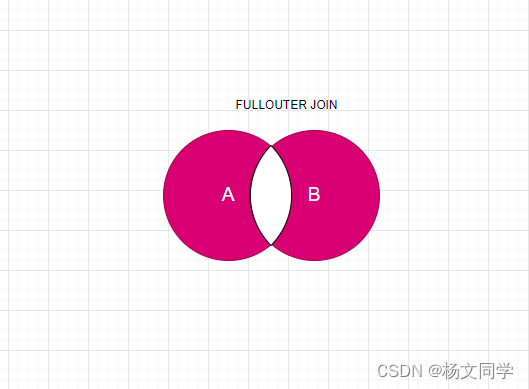
实现sql:
SELECT st.* FROM students st
LEFT JOIN grades gr ON st.student_id = gr.student_id
WHERE
gr.grade_id IS NULL
UNION ALL
SELECT st.* FROM students st
RIGHT JOIN grades gr ON st.student_id = gr.student_id
WHERE
st.student_id IS NULL查询结果集:
交叉连接
交叉连接,即CROSS JOIN也叫做笛卡尔积,是将两个表的所有可能的记录进行组合,返回结果的行数等于两个表行数的乘积。
笛卡尔积在工作中很少使用,但在某些特定场景下非常有用,比如:
- 查询所有可能的组合,比如在交通和物流领域,生成所有可能的路径或路线组合。
- 测试和调试,在开发和调试阶段,有时需要快速查看两个表的所有可能组合,以检查数据是否匹配或找出逻辑上的错误。
假设我有一个产品表和一个颜色表,我希望生成每个产品与每种颜色的所有可能组合,以便查看不同产品和颜色的效果。
CREATE TABLE products (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL
);
-- 创建颜色表
CREATE TABLE colors (
id INT AUTO_INCREMENT PRIMARY KEY,
color VARCHAR(50) NOT NULL
);
-- 向产品表插入数据
INSERT INTO products (name) VALUES
('手机'),
('笔记本');
-- 向颜色表插入数据
INSERT INTO colors (color) VALUES
('红色'),
('蓝色'),
('绿色');查询sql:
SELECT
pr.`name`,
co.color
FROM
products pr
CROSS JOIN colors co查询结果:
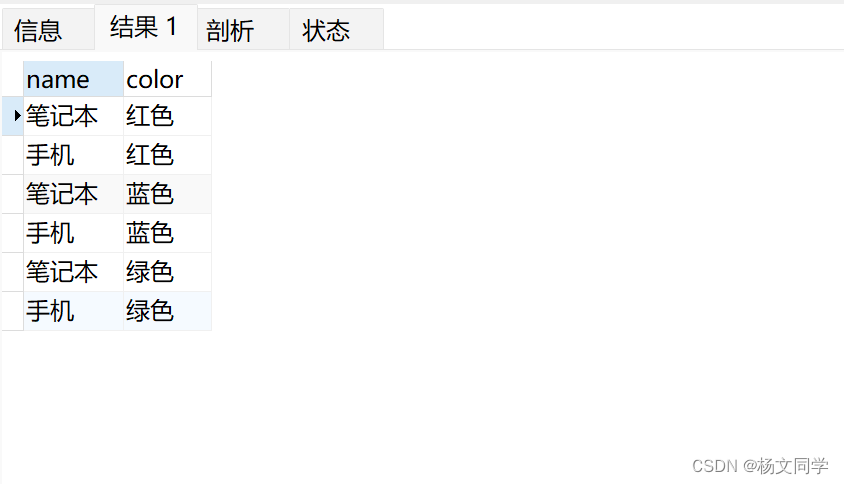
需要注意的是性能问题,笛卡尔积的结果集可能非常大,消耗大量的资源。在使用时需谨慎,特别是处理大数据集时。
自然连接
自然连接,即NATURAL JOIN,)是一种基于表中具有相同名称的列自动进行连接。它会自动匹配两张表中具有相同名称的列,并使用这些列进行连接,不需要显式指定连接条件。
SELECT
st.student_name,
gr.score
FROM
students st
NATURAL JOIN grades gr 查询结果:
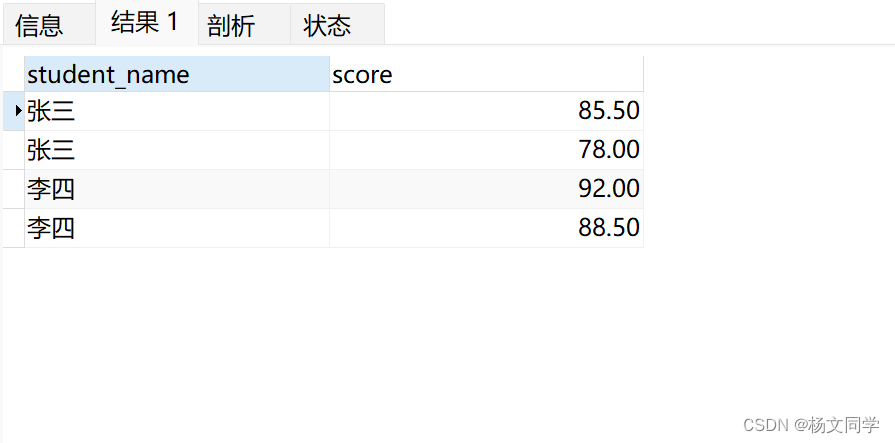
以上结果,可以看出自然连接在 MySQL 中本质上是一种 INNER JOIN。它会返回两个表中具有相同列名的所有匹配行。如果没有匹配的行,则不会返回结果。(我理解自然连接,就是解决两个关联表ON后面有很多关联条件,帮我们省去这些关联条件)
USING连接
USING连接,用于连接两个表时指定共同的列名。它是 INNER JOIN 和 LEFT JOIN 的一种简化语法,用于连接具有相同列名的表。使用 USING 子句可以使查询更简洁和易读。
那大家可能会有疑惑,那我不直接用自然连接不就好了,但是自然连接有两个缺点:
- 自然连接,只能是INNER JOIN ,不能用LEFT JOIN或者RIGHT JOIN。
- 自然连接,会自动关联两个表所有相同的字段,那如果我不想关联其中一个字段呢。。
SELECT
st.student_name,
gr.score
FROM
students st
LEFT JOIN grades gr USING(student_id)
//或者
SELECT
st.student_name,
gr.score
FROM
students st
INNER JOIN grades gr USING(student_id)
//USING可以多个
SELECT
st.student_name,
gr.score
FROM
students st
INNER JOIN grades gr USING(student_id,is_delete)结果集和上面INNER JOIN,RIGHT JOIN结果一致,这里就不截图了。
总结
内连接、外连接、全连接、全外连接,其实这些在数学里面,就是代表两个集合的交集、差集、并集,还有差集的合集。看图很容易理解。以及也说了条件写在ON或者WHERE不同位置的区别。
笛卡尔积,主要知道是返回的数据集是两个表的乘积,在工作中很少用,然后知道主要的适用场景。
自然连接,是内连接的一个升级版,主要是减少写ON后面的关联条件。
USING连接,它是INNER JOIN 和LEFT/RIGHT JOIN的一种简化语法。















 5334
5334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









