







前言
前面介绍了MySQL,B+树索引的使用。B+树索引在空间和时间行都是有代价的,所以没事儿别瞎建索引。索引不仅可以用于减少需要扫描的记录数量,还可以用于排序和分组。介绍了回表、索引覆盖以及索引下推等常见知识点。最后说了创建索引的建议。
(如果没有看前面四篇文章,不建议看此篇文章)
传送门:
表空间
前面章节说过,InnoDB使用页为基本单位来管理存储空间的,默认大小为16KB。大家可以脑补一下刚开始数据很少,对应的页数量也很少,这时查询也很快。但经过一段时间,数据量暴涨,对应的页数量也会增加。这时有很多的数据页,如何快速的定位到需要查询的页呢??
这时就有了表空间,表空间是一个抽象的概念,它可以对应文件系统上一个或多个真实文件(不同表空间对应的文件数量可能不同)。每个表空间可以被划分为很多个页,表数据就存放在某个表空间下的某个页中。(概念可能不太好理解,大家可以把表空间想象成被切分为许多个页的池子)
表空间又分为系统表空间和独立表空间。
说独立表空间之前,先回顾一下页的通用结构
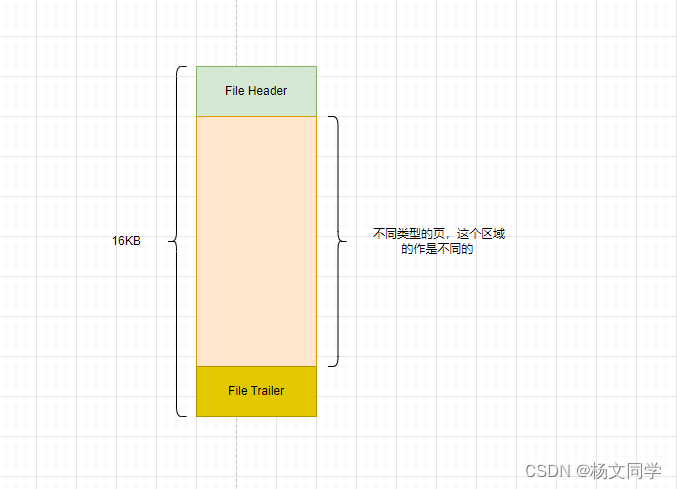
在把File Header的结构拿过来。
| 名称 | 占用大小(字节) | 描述 |
| fil_page_offset | 4 | 页号 |
| fil_page_prev | 4 | 上一个页的页号 |
| fil_page_next | 4 | 下一个页的页号 |
| fil_page_lsn | 8 | 页面最后被修改时对应的LSN值 |
| fil_page_type | 2 | 该页的类型 |
| fil_page_file_flush_lsn | 8 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
| fil_page_arch_log_no_or_space_id | 4 | 该页属于哪个表空间 |
| fil_page_space_or_chksum | 4 | 表示页的校验和 |
表空间中的每一个页都对应着一个页号,也就是fil_page_offset,我们可以通过这个页号在表空间中快速定位到指定的页。fil_page_offset是由4个字节组成的,所以一个表空间最多可以拥有2的32次方个页,也就是64T的数据。
每个页的类型由fil_page_type表示,之前介绍的是INDEX类型,也就是前面说的数据页。后续再讲其他类型的页。
其实我理解,表空间就是将所有页分开管理,一个表有自己的一个表空间,方便管理页和后面查询。
独立表空间
区(extennt)
表空间中的页实在是太多了,为了更好的管理这些页,InnoDB提出了区的概念,区(extennt):对于16KB的页来说,连续的64个页就是一个区,一个区也就是1MB的空间大小。
无论是系统表空间还是独立表空间,都可以看成是由若干个连续的区组成的。每256个区被划分为一组。如下图所示
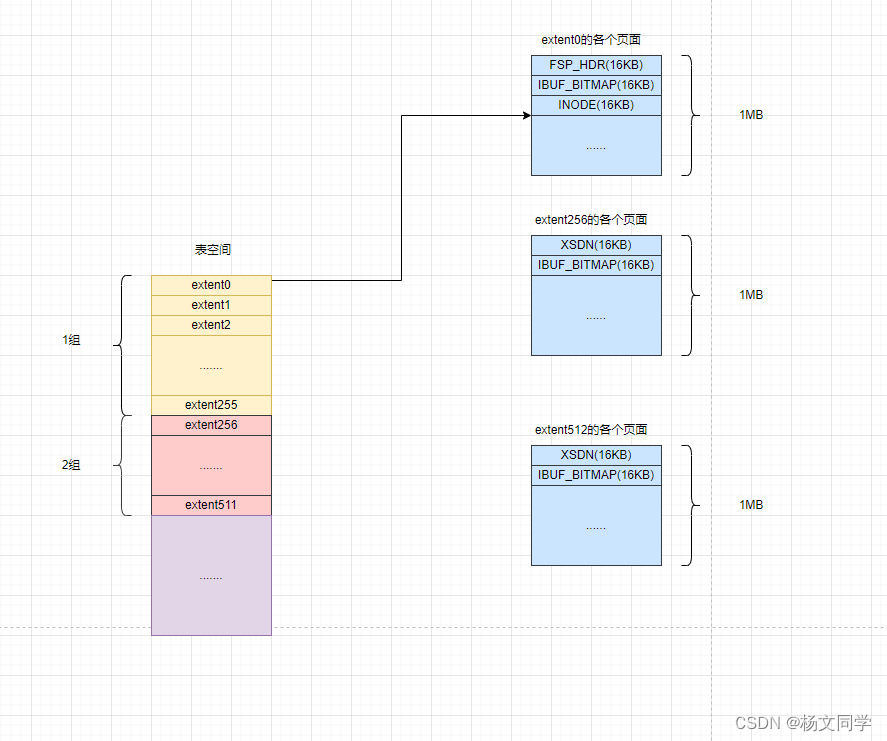
从上面的图可以看出,每个表空间第一组最开始的3个页的类型是固定的,分别是
FSP_HDR:用来登记整个表空间的一些整体属性以及本组所有的区的属性,后面再详细介绍,还需要知道的一点是,每个表空间只有一个FSP_HDR类型的页。
IBUF_BITMAP:用来存储关于Change Buffer的一些信息。还是后面再细说。
INODE:这个页存储了许多称为INODE Entry的数据结构。
其余各个组最开始的2个页的类型也是固定的。就是说extent256、extent512...这些区最开始的2个页的类型是一样的。分别是
XSDN:全称是extent descriptor,翻译过来就是区描述,用来登记256个区的属性。跟前面说的FSP_HDR有点类似,不过FSP_HDR还存储一些表空间的属性。
IBUF_BITMAP:后面再细说。
总体来说就是,表空间被划分为许多连续的区,每个区默认由64个页组成,每256个区划分为一个组。除了第一组之外,每个组的最开始的几个页的类型是固定的。
段(segment)
哇,又来一个概念。不要慌,听我娓娓道来。我们每向表中插入一条记录,本质上是向该表的聚簇索引和表的所有二级索引插入数据。而B+树每一层中的页都会形成 一个双向链表,但如果两个页在物理位置上离的很远,也就是物理位置不连续。对于传统的机械硬盘,就需要重新定位磁头位置,也就会产生随机I/O,这肯定会影响性能。所以我们引入了区的概念,一个区在物理位置上是连续的64个页。说到这里跟段还是没什么关系。。。
我们用区解决了减少随机I/O的问题,但是再想一下,我们在使用索引查询的时候 ,页都放在了区中,而区没有区分叶子节点和非叶子节点,那扫描的效果肯定会大大折扣。所以InnoDB就提出了叶子节点和非叶子节点进行了区别对待,也就提出了段的概念。
存放叶子节点的区的集合就是一个段,存放非叶子节点的区的集合也是一个段。也就等价于,一个索引会生成两个段,一个叶子节点段,一个非叶子节点段 。
默认情况下,一个使用InnoDB存储引擎的表只有一个聚簇索引,一个索引有两个段,而段是以区为单位申请存储空间的,一个区默认1MB。刚开始向表插入数据时,只有几条数据,但却占着2MB的存储空间,这肯定是很浪费的。
针对上面的问题,InnoDB提出了“碎片区”的概念。也就是一个碎片区中的页,并不是都存储一个段的数据。比如碎片区中某些页属于段A,某些页属于段B,有些页甚至不属于任何段。碎片区直属于表空间。
所以为某个段分配存储空间的策略是这样的:
1、在刚开始向表中插入数据时,段是从某个碎片区以单个页为单位来分配存储空间的。
2、当某个段已经占用了32个碎片区之后,再插入数据,就会以一个完整的区为单位来申请存储空间(之前占用的32个碎片区的数据不会复制到新申请的存储空间中)
总结一下,段更加准确的来说,段是某些零散的页加上一些完整的区的集合。InnoDB还定义了其他类型的段,比如回滚段。这些后面再做介绍。
区的分类
区根据不同状态,有不同的作用。
| 状态名 | 含义 |
| free | 空闲的区 |
| free_frag | 有剩余空闲页的碎片区 |
| full_frag | 没有剩余空闲页的碎片区 |
| fseg | 附属于某个段的区 |
需要强调的是,处于free、free_frag、full_frag,这三种状态的区都是独立的,直属于表空间。
为了管理这些区,InnoDB每个区设计了XDES Entry的结构。如下图所示
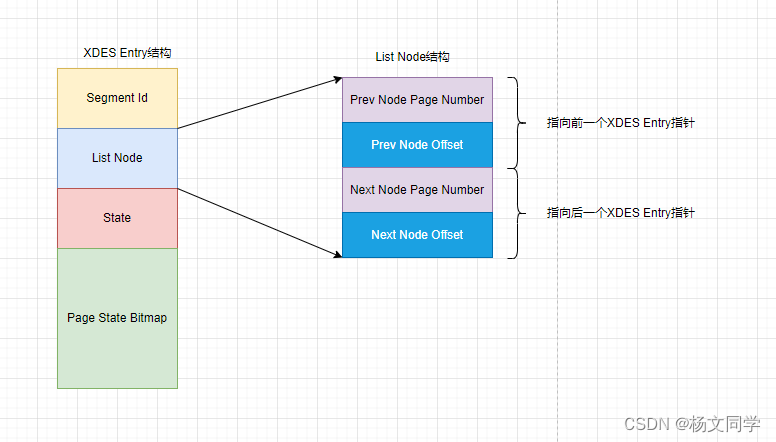
| 结构名称 | 占用字节 | 描述 |
| Segment Id | 8 | 每个段都有一个唯一编号。如果某个区已经被分配给某个段,那么该属性会有值。 (如果某个区有超过一个段的数据,则该值为空) |
| List Node | 12 | 该部分可以将表空间所有区串联成一个链表 |
| State | 4 | 表明该区的状态,具体含义参照上面区的分类 |
| Page State Bitmap | 16 | 表示区中的页是否被使用。占用16字节,也就是128位,一个区有64个页,所以每2位对应区中一个页。2位中的第一位表示是否空闲,第二位还没有用到(冗余位) |
XDES Entry链表
提出了这么多概念,回到原点,我们的初心是什么--减少随机I/O,并且又不让数据少的表浪费空间。我们再捋一下向某个表插入数据时(其实也是向段插入数据),申请页的过程。
当段中的数据较少时,首先会查看表空间中是否有状态为free_frag的区(也就是碎片区)。如果找到了,就从该区中取出一个零散的页把数据插进去。如果没有找到 ,则新申请一个free的区,然后找一个页把数据插入进去,并且把区的状态改为free_frag。直到区中零散的页都被使用完了,则把区的状态改为full_frag。
那又来问题了,我们怎么知道表空间中哪些区是free哪些是free_frag呢?随着数据量的增大,增长到GB级别,区的数量也有上千个。总不能遍历吧。。这时XDES Entry中List Node部分发挥重要作用了。
- 通过List Node把状态为free的区对应的XDES Entry结构连成一个链表,这个链表叫free链表。
- 通过List Node把状态为free_frag的区对应的XDES Entry结构连成一个链表,这个链表叫free_frag链表。
- 通过List Node把状态为full_frag的区对应的XDES Entry结构连成一个链表,这个链表叫full_frag链表。
当想查找一个free_frag的区,直接free_frag链表的头节点拿出来,然后找出一个零散的页。当没有零散的页之后,就修改state的值,然后将该区从free_frag链表移到full_frag链表。以此类推。
前面说的是从区的维度来找的,那么从段的维度来说,我们怎么知道哪些区是属于哪个段呢?
InnoDB为每个段中的区对应的XDES Entry也构建了3个链表。
- free链表:同一个段中,所有页都是空闲的页对应的XDES Entry结构会被加入到free链表中。注意,这与属于表空间的free链表是分开的,此处的free链表是附属于某个段的链表。(我理解其实就是区的类型是fseg的区。)
- not_full链表:同一个段中,仍有空闲页对应的XDES Entry结构会被加入到not_full链表中。
- full链表:同一个段中,已经没有空闲页对应的XDES Entry结构会被加入到full链表中。
这里需要强调一下,每个索引都会对应两个段,所有每个段都会维护上述3个链表。不知道大家在这里会不会有疑问,零散的32个页去哪里,答案是 会在段的结构中存储。好烦,还有结构。。。
链表基节点
前面介绍了一堆链表,那我们怎么找到这个链表,也就是如何找到链表的头节点或者尾节点呢?InnoDB设计了一个名为List Base Node的结构。
| 结构名称 | 占用字节 | 描述 |
| List Length | 4 | 该链表一共有多少个节点 |
| First Node Page Number | 4 | 表示该链表的头节点在表空间中的位置 |
| First Node Offset | 2 | |
| Last Node Page Number | 4 | 表示该链表的尾节点在表空间中的位置 |
| Last Node Offset | 2 |
一般会把链表基节点,也就是List Base Node存放在表空间中的固定位置,不为别的,只为快速且容易定位到某个链表。具体位置在哪下面会有介绍。
段的结构
我们前面说过,段是一个逻辑上的概念,是由若干个零散的页(最多32个零散的页)以及一些完整的区组成。每个区有XDES Entry结构,所以段也有结构,叫做INODE Entry结构。如下图所示
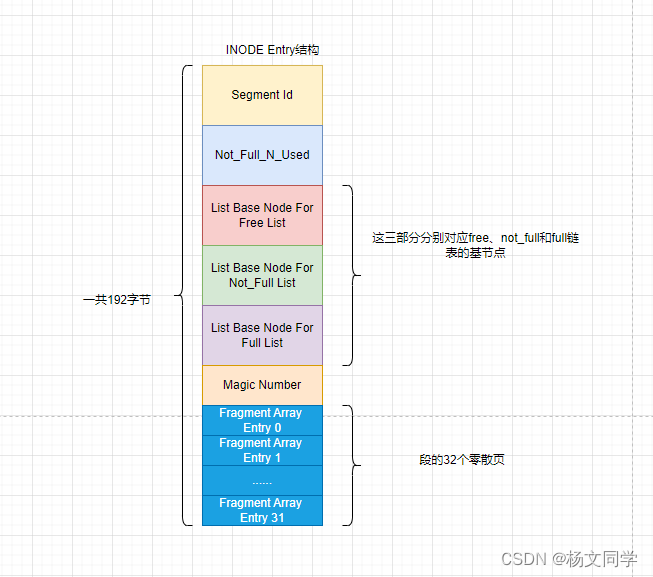
| 结构名称 | 占用字节 | 描述 |
| Segment Id | 8 | 每个段都有一个段号 |
| Not_Full_N_Used | 4 | 在Not_Null链表中已经使用了多少个页 |
| List Base Node For Free List | 16 | 段的free链表的List Base Node |
| List Base Node For Not_Full List | 16 | 段的not_full链表的List Base Node |
| List Base Node For Full List | 16 | 段的full链表的List Base Node |
| Magic Number | 4 | 标记INODE Entry是否已经初始化 |
| Fragment Array Entry 0 ~~ Fragment Array Entry 31 | 4*32 | 零散页的页号 |
说了这么多,那上述的各个链表,到底存储在哪里?答案就是表空间第一个区中,FSP_HDR、INODE中。下面再聊聊这些内容。
FSP_HDR页类型
FSP_HDR首先是一个页,页的类型就是FSP_HDR,然后它又是一个表空间中第一个页,页号为0。具体的结构如下图所示。
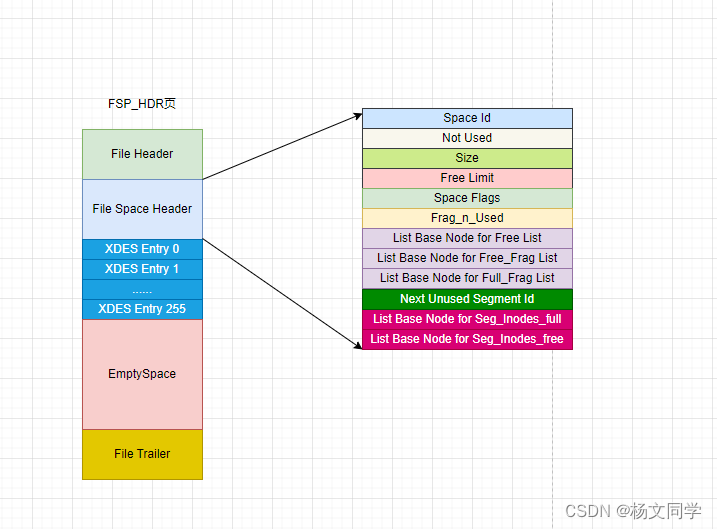
| 结构名称 | 占用字节 | 描述 |
| Fiile Header | 38 | 页的一些通用信息 |
| File Space Header | 112 | 表空间的一些整体属性信息 |
| XDES Entry | 10240 | 存储本组256个区对应的属性信息 |
| EmptySpace | 5986 | 用于填充页的结构,没啥实际意义 |
| File Trailer | 8 | 检验页是否完整 |
(1)、File Space Header
我们先来看下File Space Header部分,大致结构如上图。
| 结构名称 | 占用字节 | 描述 |
| Space Id | 4 | 表空间的Id |
| Not Used | 4 | 未被使用,可以忽略 |
| Size | 4 | 当前表空间拥有的页树 |
| Free Limit | 4 | 尚未被初始化的最小页号 |
| Space Flags | 4 | 表空间另外一些比较小的属性配置 |
| Frag_n_Used | 4 | Free_Frag链表中已使用的页面数量 |
| List Base Node for Free List | 16 | Free链表的基节点 |
| List Base Node for Free_Frag List | 16 | Free_Frag链表的基节点 |
| List Base Node for Full_Frag List | 16 | Full_Frag链表的基节点 |
| Next Unused Segment Id | 8 | 当前表空间中下一个未使用的Space Id |
| List Base Node for Seg_Inodes_Full | 16 | Seg_Inodes_Full链表的基节点 |
| List Base Node for Seg_Inodes_Free | 16 | Seg_Inodes_Free链表的基节点 |
- List Base Node for Free List、List Base Node for Free_Frag List、List Base Node for Full_Frag List:是直属于表空间的三个链表的基节点。位置是固定,所以后面定位到这几个链表就相对容易。
- Free Limit:表空间对应着磁盘文件。表空间在刚创建时会有一个默认大小,而磁盘文件是自增长的。当空间不够用时,会自动增加文件大小。那么如何增长就是一个问题。第一种是将分配的所有空闲的区,全部加入到 FREE链表。还有一种是先加一部分,等不够用时,再选择一部分加入到FREE链表。InnoDB肯定选择第一种,Free Limit表示该页号之后的区都未被使用并且没有加入到FREE链表。
- Next Unused Segment Id:表中的索引都对应着两个段,每个段都有一个唯一ID。当新增一个索引时,势必需要创建两个新段,那如何去分配段Id呢?所以就提出了Next Unused Segment Id字段,表明当前表空间中最大的段ID的下一个ID。创建新段时,段ID直接递增一下就好了 。
- List Base Node for Seg_Inodes_Full和List Base Node for Seg_Inodes_Free:每个段对应的INODE Entry结构会集中存放到一个类型为INODE的页中。如果表空间中段特别多,则会有多个INODE Entry结构,此时一个页可能存放不了,就会需要多个INODE类型的页。这些INODE的页会构成两种链表。
- Seg_Inodes_Full链表:INODE类型的页都被INODE Entry结构填充满了,没有空闲空间存放额外的INODE Entry结构。
- Seg_Inodes_Free链表:INODE类型的页仍有空闲空间来存放INODE Entry。
- Space Flags:存储一些表空间一些布尔值属性。比如,是否为共享表空间、表空间是否加密等等。
(2)、XDES类型
紧挨着File Space Header部分就是XDES Entry部分。一个XDES Entry结构大小时40KB,由于一个页的大小有限,只能存储有限的XDES Entry结构,所以才会把256个区划分为一组,在每个组的第一个页中存放256个XDES Entry结构。
因为每个区对应的XDES Entry结构地址是固定的,因此我们可以轻松地访问extent0对应的XDES Entry结构(页的偏移量为150字节)、extent1对应的XDES Entry结构(页的偏移量为150+40)等等。
XDES页类型
前面我们说了,FSP_HDR页类型的XDES Entry部分,是第一组里的第一个页。后面每组中的第一个页都是XDES页类型,记录着本组中的XDES Entry结构部分。跟XDES页类型很相似。如下如所示:

除了页头和页尾是所有页类型的通用属性之外,还有一部分是未使用的空间,理由很简单,是为了和XDES页类型取XDES Entry结构保持一致。其余部分与FSP_HDR页类型一样。
IBUF_BITMAP页类型
在前面分组中的图,我们知道,每个分组的第二个页是IBUF_BITMAP类型。我们上面也说过,我们每向表中插入一条记录,本质上是向该表的聚簇索引和表的所有二级索引插入数据。先插入聚簇索引,再插入二级索引。要插入的二级索引,页可能在表空间随机分布,将会产生随机I/O,所以InnoDB引入了Change Buffer,以前被称作 Insert Buffer(插入缓冲区)。
插入缓冲区是一种优化机制,主要用于减少对二级索引页的随机写操作。对于二级索引的插入操作,InnoDB并不会立即将数据写入索引页,而是先将其放入插入缓冲区。这种缓冲区可以批量处理多次插入操作,从而减少磁盘I/O并提高性能。
IBUF_BITMAP页类型这里不再多做介绍,想了解的可以网上搜一搜。
INODE页类型
在第一个分组中还有一个页类型没有介绍,那就是INODE类型。前面我们说过,每个索引有两个段,加入有一个表有很多索引,那段的数量就是*2。为了管理这些段,为每个段设计了INODE Entry结构,这个结构定义了段的相关属性。我们说的INODE页类型,就是存储这些INODE Entry结构。如下图所示:
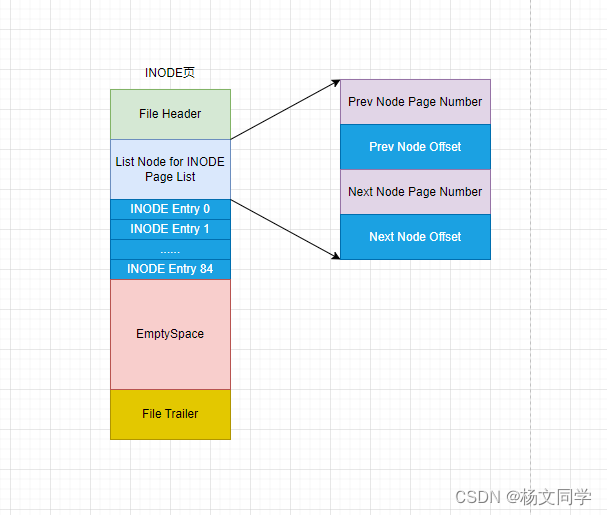
页头和页尾还有未使用的空间,就不再介绍了。
- INODE Entry部分,上面已经介绍了INODE Entry具体的结构,并且占用了192字节,一个页可以存储85个INODE Entry结构。
- List Node for INODE Page List部分,如果一个表空间中的段超过85个,那么一个INODE页类型是存储不了的。所以InnoDB将INODE页类型连接成两个不同的链表。
- Seg_Inodes_Full链表:在该链表中,已经没有剩余空间存储INODE Entry结构。
- Seg_Inodes_Free链表:在该链表中,还有剩余空间存储INODE Entry结构
这两个链表,就是我们前面在FSP_HDR页类型中的File Space Header部分。有这两个链表的基节点,位置也是固定的 。当我们创建一个索引时(同时会创建段),会创建一个与之对应的INODE Entry结构。首先会看Seg_Inodes_Free链表是否为空。如果不为空,直接从该链表中获取一个有剩余空间的INODE页类型,然后INODE Entry结构放到该页中,如果满了,则把该页放到Seg_Inodes_Full链表中。如果为空,则需要从Free_Frag(碎片区中Free_Frag链表),申请一个页,并将页类型改为INODE类型,并把该页放到Seg_Inodes_Free链表中,同时也会把INODE Entry结构放到该页中。
Segment Header结构
上面虽然没有介绍Segment Header结构,但是后面系统表空间会有用到。我们知道一个索引会产生两个段。那我怎么知道数据页属于哪个段呢。这要把数据页中Page Heade部分结构搬过来了。
| 名称 | 占用大小(字节) | 描述 |
| page_btr_seg_leaf | 10 | B+树叶子节点段的头部信息,仅在B+树的根页面中定义 |
| page_btr_seg_top | 10 | B+树非叶子节点段的头部信息,仅在B+树的根页面中定义 |
这两个都是占用10字节,它们其实分别对应一个名为Segment Header结构。

| 名称 | 占用大小(字节) | 描述 |
| Space ID of the INODE Entry | 4 | INODE Entry结构所在的表空间ID |
| Page Number of the INODE Entry | 4 | INODE Entry结构所在的页号 |
| Byte Offset of the INODE Entry | 2 | INODE Entry结构在该页中的偏移量 |
系统表空间
系统表空间的结构与独立表空间基本类似。只不过由于整个MySQL进程只有一个系统表空间,系统表空间中需要记录一些与整个系统相关的信息,所以会比独立表空间多出一些用来记录这些信息的页。
系统表空间的整体结构
如下图所示:
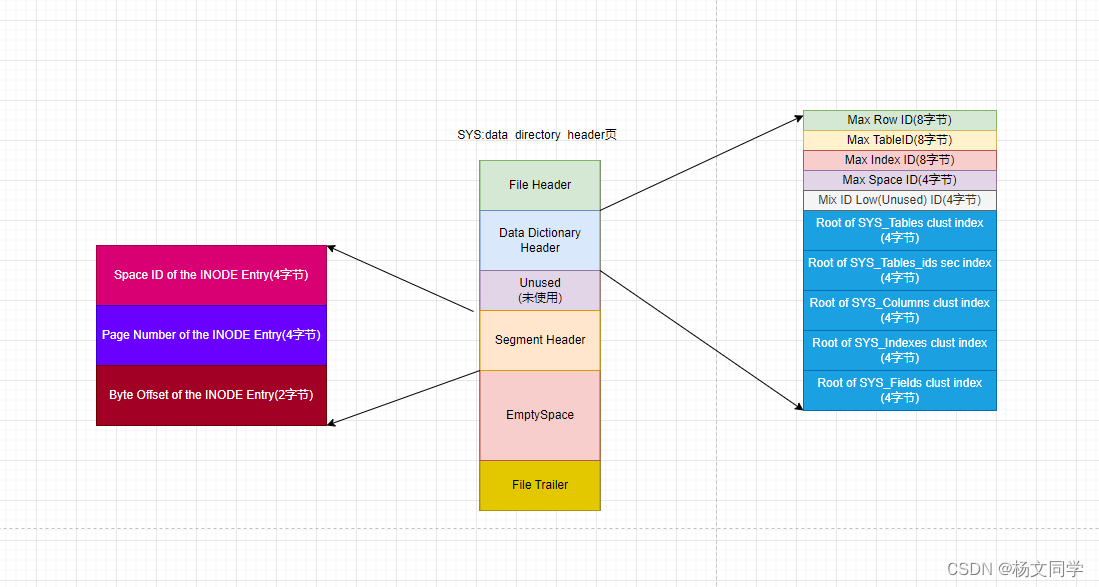
可以看到,系统表空间和独立表空间的前三个页是一样的,但是后面的页就不一样了。
SYS:Insert buffer header、TRX_SYS都是设计事务和MVCC的知识,后面再介绍。重点介绍一下InnoDB数据字典。
InnoDB数据字典
我们平时使用Insert语句向表中插入数据称为用户数据或者叫用户记录。MySQL只是作为一个软件来保存这些数据。但是每插入一条记录时,MySQL需要判断表是否存在,插入的列与表中的列是否符合等等。这些都是需要保存的额外信息。这些数据也称为元数据。InnoDB存储引擎特意定义了一系列的内部系统表来记录这些元数据。比如下面主要的系统表:
| 表名 | 描述 |
| sys_tables | 整个InnoDB存储引擎所有表的信息 |
| sys_columns | 整个InnoDB存储引擎所有列的信息 |
| sys_indexes | 整个InnoDB存储引擎所有索引的信息 |
| sys_fields | 整个InnoDB存储引擎所有索引对应的列的信息 |
| sys_foreign | 整个InnoDB存储引擎所有外键的信息 |
| sys_tabespaces | 整个InnoDB存储引擎所有表空间的信息 |
| ......... | ......... |
这些系统表也被称为数据字典,它们都是以B+树的形式保存在系统表空间的某些页中。其中比较重要的包括sys_tables、sys_columns、sys_indexes、sys_fields。
这些表有哪些字段以及索引,InnoDB把这些数据硬编码到代码中了。然后拿出一个页,存放4个表的聚簇索引和二级索引对应的B+树位置。这个页就是上面图中的data directory header,页类型时SYS。一图胜千言,如下图所示:
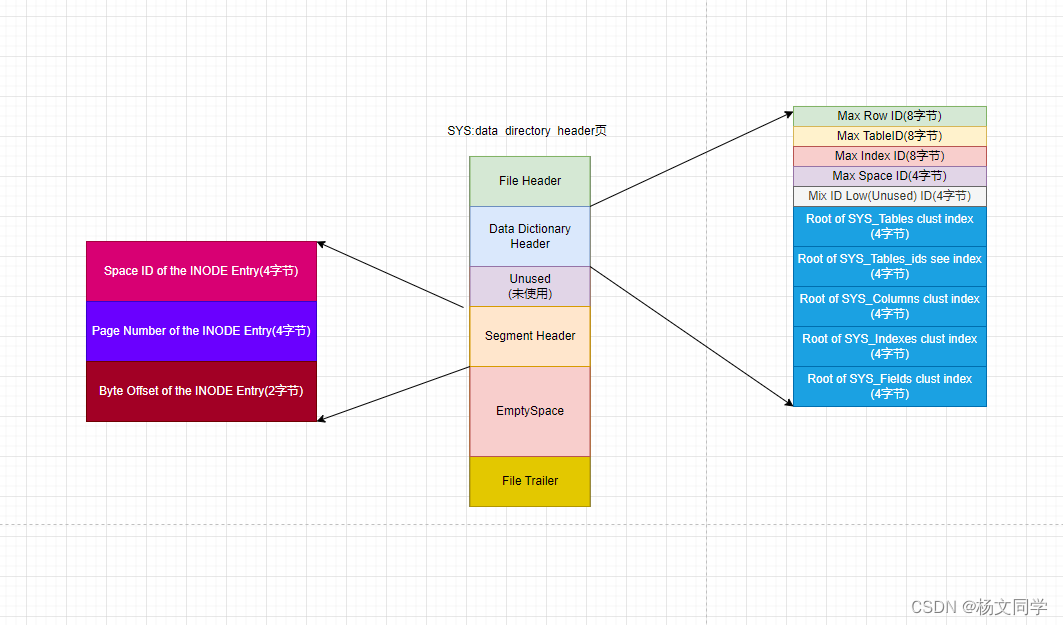
- Max Row ID:我们说过,如果不显示的为表创建主键,而且表中也没有存储不为NULL且是UNIQUE键,那么InnoDB会默认创建一个名为row_id的列作为主键。原则上一个表的row_id列的值不重复就可以了。但是Max Row ID是全局共享的,无论哪个表的row_id要插入一条记录,row_id就是在该 Max Row ID值的基础上+1。
- Max TableID:在InnoDB中,每个表都对应一个唯一的ID,每次新建一个表,就会把该值+1,作为表的ID。
- Max Index ID:在InnoDB中,每个索引都对应一个唯一的ID,每次新建一个索引,就会把该值+1,作为索引的ID。
- Max Space ID:在InnoDB中,所有表空间都对应一个唯一的ID,每次新建一个表空间,就会把该值+1,作为表空间的ID。
- Mix ID Low(Unused) ID:未使用。
- Root of SYS_Tables clust index:表示SYS_Tables表聚簇索引的根页号。(Name是聚簇索引)
- Root of SYS_Tables_ids sec index:表示SYS_Tables表为ID列创建的二级索引的根页号。
- Root of SYS_Columns clust index:表示SYS_Columns表聚簇索引的根页号。
- Root of SYS_Indexes clust index:表示SYS_Indexes表聚簇索引的根页号。
- Root of SYS_Fields clust index:表示SYS_Fields表聚簇索引的根页号。
在查询中,不是直接用SYS开头的表,用法如下所示,大家可以自行执行以下试试。
SELECT * FROM information_schema.TABLES;
SELECT * FROM information_schema.COLUMNS;
SELECT * FROM information_schema.STATISTICS; //查询索引总结
表空间分为独立表空间和系统表空间。
为了减少随机I/O,所以基于页,InnoDB设计了区,一个区有连续的64个页。256个区为一组。
区又分为
- 空闲区:这些区会加入到FREE链表。
- 有空闲的碎片区:这些区会加入到FREE_FRAG链表。
- 没有剩余空间的碎片区:这些区会加入到FULL_FRAG链表。
- 直属于段的区:每个段下面的区又组成三个链表。
- FREE链表:同一个段中,所有页面都是空闲的区对应的XDES Entry结构会加入该链表。
- NOT_FULL链表:同一个段中,有空闲的区对应的XDES Entry结构会加入该链表。
- FULL链表:同一个段中,没有空闲的区对应的XDES Entry结构会加入该链表。
为了提高索引页的检索效率,将叶子节点和非叶子节点区分开,所以有了段。
InnoDB设计了区和段,那么又有了新问题。为了更好的管理页、区、段,InnoDB设计了XDES Entry结构和INODE结构。
独立表空间第一个页是FSP_HDR,它存储了表空间的一些整体属性和第一个组内256个区XDES Entry结构(一个DES Entry结构有40个字节)。第二个页是IBUF_BITMAP,存储了一些Change Buffer的信息。第三个页是INODE,它存储了INODE Entry结构,因为只够存储85个,所以该页存储的还有两个链表。
上述相关链表,都有基节点,存放在系统表空间中第一组第一个页中。也就是FSP_HDR页类型。
系统表空间,整个MySQL进程只有一个。结构与独立表空间大体一致,系统表空间提供了一系列系统表来描述元数据。比较重要的4个表是sys_tables、sys_columns、sys_indexes、sys_fields。
其中系统表空间有个页,专门记录这4个表的索引根页号。
建议多看几遍,确实有点绕。。。















 2100
2100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









