







<!--一个博主专栏付费入口结束-->
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-d284373521.css">
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-d284373521.css">
<div class="htmledit_views" id="content_views">
<p> 在<a href="http://www.cnblogs.com/pinard/p/6509630.html" rel="nofollow" id="homepage1_HomePageDays_DaysList_ctl00_DayList_TitleUrl_0" data-token="04f52ae7b745f972bb5f70f1da8ffdef">循环神经网络(RNN)模型与前向反向传播算法</a>中,我们总结了对RNN模型做了总结。由于RNN也有梯度消失的问题,因此很难处理长序列的数据,大牛们对RNN做了改进,得到了RNN的特例LSTM(Long Short-Term Memory),它可以避免常规RNN的梯度消失,因此在工业界得到了广泛的应用。下面我们就对LSTM模型做一个总结。</p>
1. 从RNN到LSTM
在RNN模型里,我们讲到了RNN具有如下的结构,每个序列索引位置t都有一个隐藏状态h(t)h(t)。
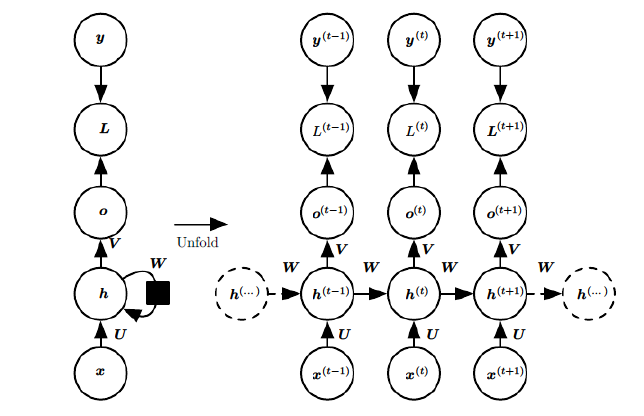
如果我们略去每层都有的o(t),L(t),y(t)o(t),L(t),y(t),则RNN的模型可以简化成如下图的形式:
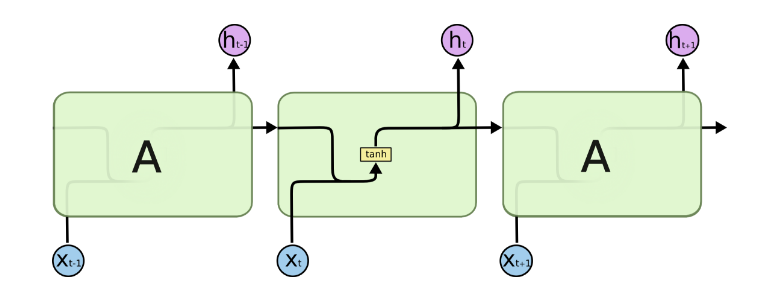
图中可以很清晰看出在隐藏状态h(t)h(t)由x(t)x(t)和h(t−1)h(t−1)得到。得到h(t)h(t)后一方面用于当前层的模型损失计算,另一方面用于计算下一层的h(t+1)h(t+1)。
由于RNN梯度消失的问题,大牛们对于序列索引位置t的隐藏结构做了改进,可以说通过一些技巧让隐藏结构复杂了起来,来避免梯度消失的问题,这样的特殊RNN就是我们的LSTM。由于LSTM有很多的变种,这里我们以最常见的LSTM为例讲述。LSTM的结构如下图:
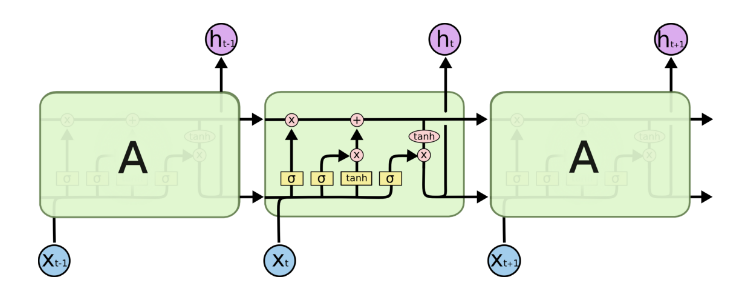
可以看到LSTM的结构要比RNN的复杂的多,真佩服牛人们怎么想出来这样的结构,然后这样居然就可以解决RNN梯度消失的问题?由于LSTM怎么可以解决梯度消失是一个比较难讲的问题,我也不是很熟悉,这里就不多说,重点回到LSTM的模型本身。
2. LSTM模型结构剖析
上面我们给出了LSTM的模型结构,下面我们就一点点的剖析LSTM模型在每个序列索引位置t时刻的内部结构。
从上图中可以看出,在每个序列索引位置t时刻向前传播的除了和RNN一样的隐藏状态h(t)h(t),还多了另一个隐藏状态,如图中上面的长横线。这个隐藏状态我们一般称为细胞状态(Cell State),记为C(t)C(t)。如下图所示:
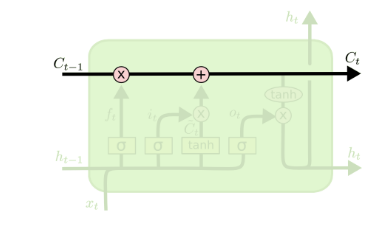
除了细胞状态,LSTM图中还有了很多奇怪的结构,这些结构一般称之为门控结构(Gate)。LSTM在在每个序列索引位置t的门一般包括遗忘门,输入门和输出门三种。下面我们就来研究上图中LSTM的遗忘门,输入门和输出门以及细胞状态。
2.1 LSTM之遗忘门
遗忘门(forget gate)顾名思义,是控制是否遗忘的,在LSTM中即以一定的概率控制是否遗忘上一层的隐藏细胞状态。遗忘门子结构如下图所示:
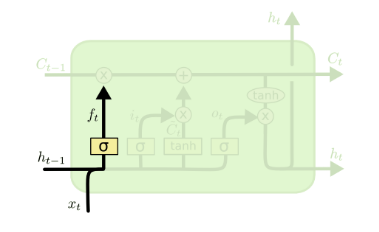
图中输入的有上一序列的隐藏状态h(t−1)h(t−1)和本序列数据x(t)x(t),通过一个激活函数,一般是sigmoid,得到遗忘门的输出f(t)f(t)。由于sigmoid的输出f(t)f(t)在[0,1]之间,因此这里的输出f^{(t)}代表了遗忘上一层隐藏细胞状态的概率。用数学表达式即为:
f(t)=σ(Wfh(t−1)+Ufx(t)+bf)f(t)=σ(Wfh(t−1)+Ufx(t)+bf)
其中Wf,Uf,bfWf,Uf,bf为线性关系的系数和偏倚,和RNN中的类似。σσ为sigmoid激活函数。
2.2 LSTM之输入门
输入门(input gate)负责处理当前序列位置的输入,它的子结构如下图:

从图中可以看到输入门由两部分组成,第一部分使用了sigmoid激活函数,输出为i(t)i(t),第二部分使用了tanh激活函数,输出为a(t)a(t), 两者的结果后面会相乘再去更新细胞状态。用数学表达式即为:
i(t)=σ(Wih(t−1)+Uix(t)+bi)i(t)=σ(Wih(t−1)+Uix(t)+bi)
a(t)=tanh(Wah(t−1)+Uax(t)+ba)a(t)=tanh(Wah(t−1)+Uax(t)+ba)
其中Wi,Ui,bi,Wa,Ua,ba,Wi,Ui,bi,Wa,Ua,ba,为线性关系的系数和偏倚,和RNN中的类似。σσ为sigmoid激活函数。
2.3 LSTM之细胞状态更新
在研究LSTM输出门之前,我们要先看看LSTM之细胞状态。前面的遗忘门和输入门的结果都会作用于细胞状态C(t)C(t)。我们来看看从细胞状态C(t−1)C(t−1)如何得到C(t)C(t)。如下图所示:
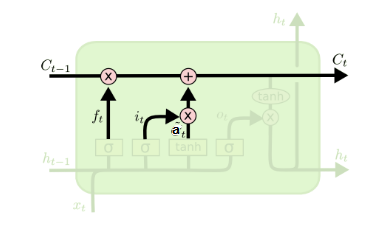
细胞状态C(t)C(t)由两部分组成,第一部分是C(t−1)C(t−1)和遗忘门输出f(t)f(t)的乘积,第二部分是输入门的i(t)i(t)和a(t)a(t)的乘积,即:
C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)
其中,⊙⊙为Hadamard积,在DNN中也用到过。
2.4 LSTM之输出门
有了新的隐藏细胞状态C(t)C(t),我们就可以来看输出门了,子结构如下:
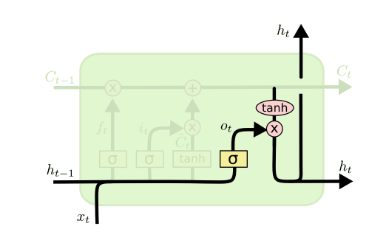
从图中可以看出,隐藏状态h(t)h(t)的更新由两部分组成,第一部分是o(t)o(t), 它由上一序列的隐藏状态h(t−1)h(t−1)和本序列数据x(t)x(t),以及激活函数sigmoid得到,第二部分由隐藏状态C(t)C(t)和tanh激活函数组成, 即:
o(t)=σ(Woh(t−1)+Uox(t)+bo)o(t)=σ(Woh(t−1)+Uox(t)+bo)
h(t)=o(t)⊙tanh(C(t))h(t)=o(t)⊙tanh(C(t))
通过本节的剖析,相信大家对于LSTM的模型结构已经有了解了。当然,有些LSTM的结构和上面的LSTM图稍有不同,但是原理是完全一样的。
3. LSTM前向传播算法
现在我们来总结下LSTM前向传播算法。LSTM模型有两个隐藏状态h(t),C(t)h(t),C(t),模型参数几乎是RNN的4倍,因为现在多了Wf,Uf,bf,Wa,Ua,ba,Wi,Ui,bi,Wo,Uo,boWf,Uf,bf,Wa,Ua,ba,Wi,Ui,bi,Wo,Uo,bo这些参数。
前向传播过程在每个序列索引位置的过程为:
1)更新遗忘门输出:
f(t)=σ(Wfh(t−1)+Ufx(t)+bf)f(t)=σ(Wfh(t−1)+Ufx(t)+bf)
2)更新输入门两部分输出:
i(t)=σ(Wih(t−1)+Uix(t)+bi)i(t)=σ(Wih(t−1)+Uix(t)+bi)
a(t)=tanh(Wah(t−1)+Uax(t)+ba)a(t)=tanh(Wah(t−1)+Uax(t)+ba)
3)更新细胞状态:
C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)
4)更新输出门输出:
o(t)=σ(Woh(t−1)+Uox(t)+bo)o(t)=σ(Woh(t−1)+Uox(t)+bo)
h(t)=o(t)⊙tanh(C(t))h(t)=o(t)⊙tanh(C(t))
5)更新当前序列索引预测输出:
ŷ (t)=σ(Vh(t)+c)y^(t)=σ(Vh(t)+c)
4. LSTM反向传播算法推导关键点
有了LSTM前向传播算法,推导反向传播算法就很容易了, 思路和RNN的反向传播算法思路一致,也是通过梯度下降法迭代更新我们所有的参数,关键点在于计算所有参数基于损失函数的偏导数。
在RNN中,为了反向传播误差,我们通过隐藏状态h(t)h(t)的梯度δ(t)δ(t)一步步向前传播。在LSTM这里也类似。只不过我们这里有两个隐藏状态h(t)h(t)和C(t)C(t)。这里我们定义两个δδ,即:
δ(t)h=∂L∂h(t)δh(t)=∂L∂h(t)
δ(t)C=∂L∂C(t)δC(t)=∂L∂C(t)
反向传播时只使用了δ(t)CδC(t),变量δ(t)hδh(t)仅为帮助我们在某一层计算用,并没有参与反向传播,这里要注意。如下图所示:
而在最后的序列索引位置ττ的δ(τ)hδh(τ)和 δ(τ)CδC(τ)为:
δ(τ)h=∂L∂O(τ)∂O(τ)∂h(τ)=VT(ŷ (τ)−y(τ))δh(τ)=∂L∂O(τ)∂O(τ)∂h(τ)=VT(y^(τ)−y(τ))
δ(τ)C=∂L∂h(τ)∂h(τ)∂C(τ)=δ(τ)h⊙o(τ)⊙(1−tanh2(C(τ)))δC(τ)=∂L∂h(τ)∂h(τ)∂C(τ)=δh(τ)⊙o(τ)⊙(1−tanh2(C(τ)))
接着我们由δ(t+1)CδC(t+1)反向推导δ(t)CδC(t)。
δ(t)hδh(t)的梯度由本层的输出梯度误差决定,即:
δ(t)h=∂L∂h(t)=VT(ŷ (t)−y(t))δh(t)=∂L∂h(t)=VT(y^(t)−y(t))
而δ(t)CδC(t)的反向梯度误差由前一层δ(t+1)CδC(t+1)的梯度误差和本层的从h(t)h(t)传回来的梯度误差两部分组成,即:
δ(t)C=∂L∂C(t+1)∂C(t+1)∂C(t)+∂L∂h(t)∂h(t)∂C(t)=δ(t+1)C⊙f(t+1)+δ(t)h⊙o(t)⊙(1−tanh2(C(t)))δC(t)=∂L∂C(t+1)∂C(t+1)∂C(t)+∂L∂h(t)∂h(t)∂C(t)=δC(t+1)⊙f(t+1)+δh(t)⊙o(t)⊙(1−tanh2(C(t)))
有了δ(t)hδh(t)和δ(t)CδC(t), 计算这一大堆参数的梯度就很容易了,这里只给出WfWf的梯度计算过程,其他的Uf,bf,Wa,Ua,ba,Wi,Ui,bi,Wo,Uo,bo,V,cUf,bf,Wa,Ua,ba,Wi,Ui,bi,Wo,Uo,bo,V,c的梯度大家只要照搬就可以了。
∂L∂Wf=∑t=1τ∂L∂C(t)∂C(t)∂f(t)∂f(t)∂Wf=∑t=1τδ(t)C⊙C(t−1)⊙f(t)⊙(1−f(t))(h(t−1))T∂L∂Wf=∑t=1τ∂L∂C(t)∂C(t)∂f(t)∂f(t)∂Wf=∑t=1τδC(t)⊙C(t−1)⊙f(t)⊙(1−f(t))(h(t−1))T
5. LSTM小结
LSTM虽然结构复杂,但是只要理顺了里面的各个部分和之间的关系,进而理解前向反向传播算法是不难的。当然实际应用中LSTM的难点不在前向反向传播算法,这些有算法库帮你搞定,模型结构和一大堆参数的调参才是让人头痛的问题。不过,理解LSTM模型结构仍然是高效使用的前提。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
参考资料:
1) Neural Networks and Deep Learning by By Michael Nielsen
2) Deep Learning, book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville















 5927
5927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









