







Elasticsearch 1: 基本原理和概念
Elasticsearch 2: 管理索引和文档
Elasticsearch 3: 数据检索和分析
Elasticsearch 4: 相关性检索和组合查询
Elasticsearch 5: 聚集查询
Elasticsearch 6: 索引别名
Elasticsearch 集群
SpringBoot 整合 Elasticsearch
1. 导入数据
- 提前准备好数据,这里使用es提供的样例数据
- 打开首页,点击Add data
- 选择 sample data 选项,添加Sample flight data和Sample web logs
- 导入成功

2. _search 接口
- 所有的 REST 搜索请求使用_search 接口,既可以是 GET 请求,也可以是 POST请求,也可以通过在搜索 URL 中指定索引来限制范围
- _search 接口有两种请求方法,一种是基于 URI 的请求方式,另一种是基于请求体的方式,无论哪种,他们执行的语法都是基于 DSL(ES 为我们定义的查询语言,基于 JSON 的查询语言),只是形式上不同。
- 基于请求体的方式如下
- 匹配所有字段
get kibana_sample_data_flights/_search
{
"query": {
"match_all": {
}
}
}

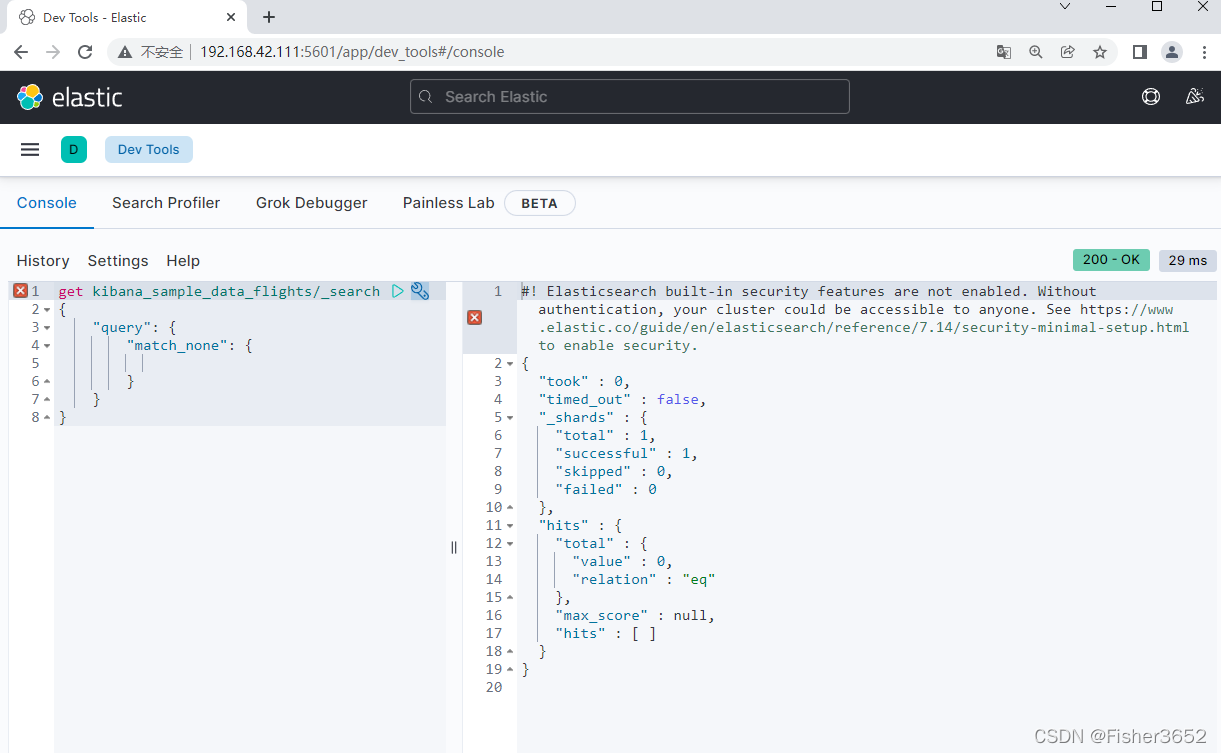
- 全不匹配
get kibana_sample_data_flights/_search
{
"query": {
"match_none": {
}
}
}
- query-这是搜索请求中最重要的组成部分,它配置了基于评分返回的最佳文档,也包括了你不希望返回哪些文档
- size-代表了返回文档的数量
- from和 size 一起使用,from 用于分页操作。需要注意的是,为了确定第 2 页的 10 项结果,Elasticsearch 必须要计算前 20 个结果。如果结果集合不断增加,获取某些靠后的翻页将会成为代价高昂的操作
- _ source 指定_source 字段如何返回。默认是返回完整的_source 字段。 通过配置_source,将过滤返回的字段。如果索引的文档很大,而且无须结果中的全部内容,就使用这个功能。如果想使用它,就不能在索引映射中关闭 _source 字段
- sort 默认的排序是基于文档的得分。如果并不关心得分,或者期望许多文档的得分相同,添加额外的 sort 将帮助你控制哪些文档被返回。
2.1 分页
- 命名适宜的 from 和 size 字段,用于指定结果的开始点,以及每“页"结果的 量。比如,发送的 from 值是 7,size 值是 5,那么 Elasticsearch 将返回 第 8、9、10、 11 和 12 项结果(由于 from 参数是从 0 开始,指定 7 就是从第 8 项结果开始)。如果没有发送这两个参数,Elasticsearch 默认从第一项结果开始 ( 第 0 项结果),在回复中返回 10 项结果。
get kibana_sample_data_flights/_search
{
"from": 100,
"size": 20,
"query": {
"term": {
"DestCountry": "CN"
}
}
}
- 但是,from 与 size 的和不能超过 index. max_result_window 这个索引配置项设置的值。默认情况下这个配置项的值为 10000,所以如果要查询 10000 条以后的文档,就必须要增加这个配置值。例如,要检索第 10000 条开始的 200 条数 据,这个参数的值必须要大于 10200,否则将会抛出类似“ Result window is too large”的异常。
- 由此可见,Elasticsearch 在使用 from 和 size 处理分页问题时会将所有数据全部取出来,然后再截取用户指定范围的数据返回。所以在查询非常靠后的数据时,即使使用了 from 和 size 定义的分页机制依然有内存溢出的可能,而 max_ result_ window 设置的 10000 条则是对 Elastiesearch 的一种保护机制。
- 为什么要这么设计,首先,在互联网时代的数据检索应该通过相似度算法,提高检索结果与用户期望的附和度,而不应该让用户在检索结果中自己挑选满意的数据。以互联网搜索为例,用户在浏览搜索结果时很少会 看到第 3 页以后的内容。假如用户在翻到第 10000 条数据时还没有找到需要的结果,那么他对这个搜索引擎一定会非常失望。
2.2 字段匹配
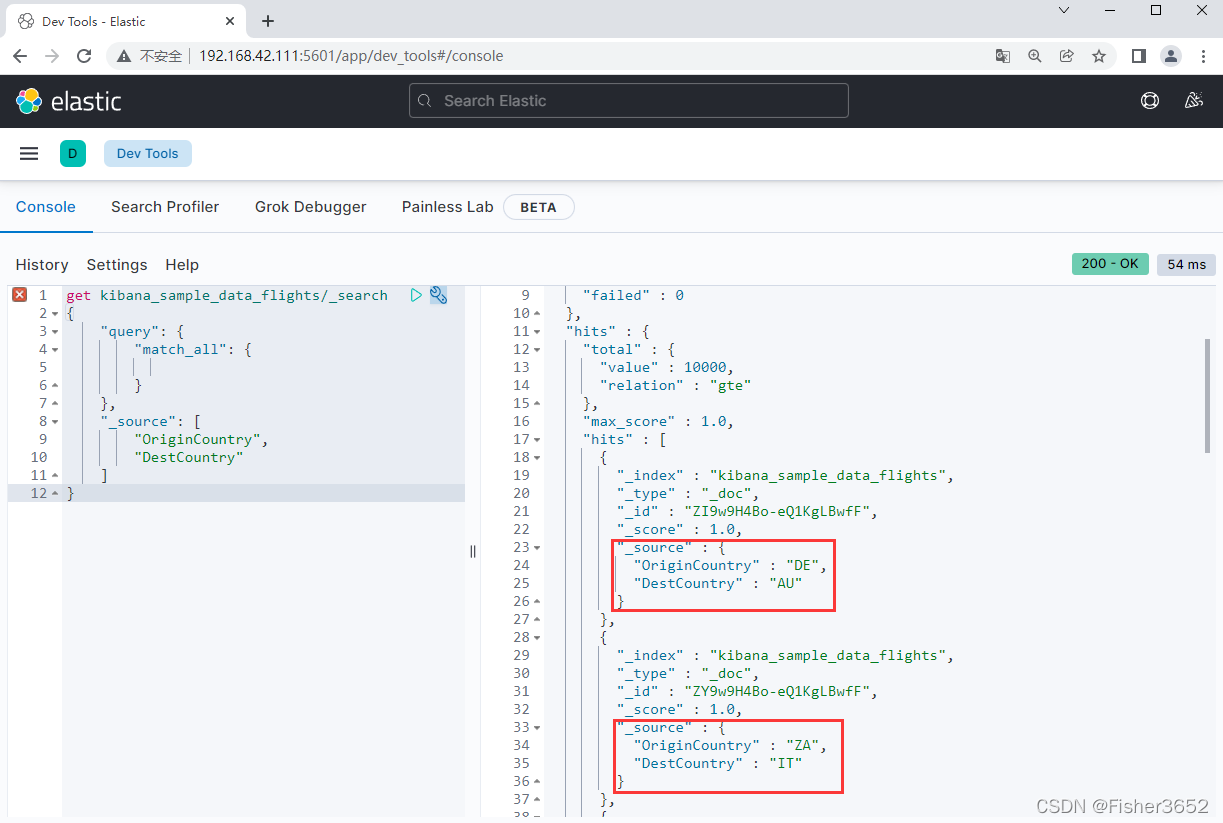
- 元字段_source 中存储了文档的原始数据。如果请求中没有指定_source, Elasticsearch 默认返回整个_ source, 或者如果_ source 没有存储,那么就只返回匹配文档的元数据:_ id、_type、_index 和_score。
get kibana_sample_data_flights/_search
{
"query": {
"match_all": {
}
},
"_source": [
"OriginCountry",
"DestCountry"
]
}
- 只返回了OriginCountry和DestCountry字段
- 还可以指定通配符。例如,如果想同时返回" DestCountry “和” DestWeather “字段,可以这样配置_ source: “Dest*”。 也可以使 用通配字符串的数组来指定多个通配符,例如_ source:[” Origin*", "* Weather "]
get kibana_sample_data_flights/_search
{
"query": {
"match_all": {
}
},
"_source": [
"Origin*",
"*Weather"
]
}
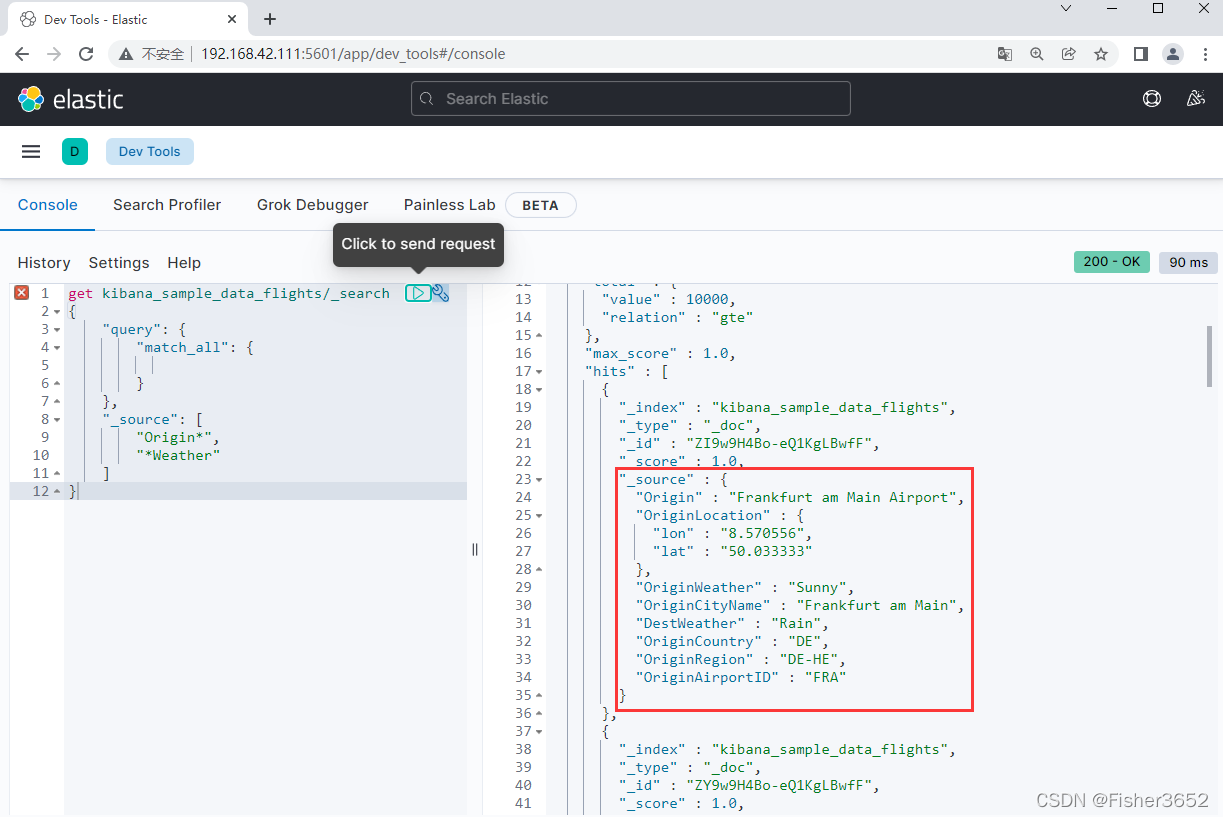
- 可以指定哪些字段需要返回,哪些字段无须返回
get kibana_sample_data_flights/_search
{
"_source": {
"includes": [
"*.lon",
"*.lat"
]
}
}

- 排除DestLocation的经纬度
get kibana_sample_data_flights/_search
{
"_source": {
"includes": [
"*.lon",
"*.lat"
],
"excludes": "DestLocation.*"
}
}
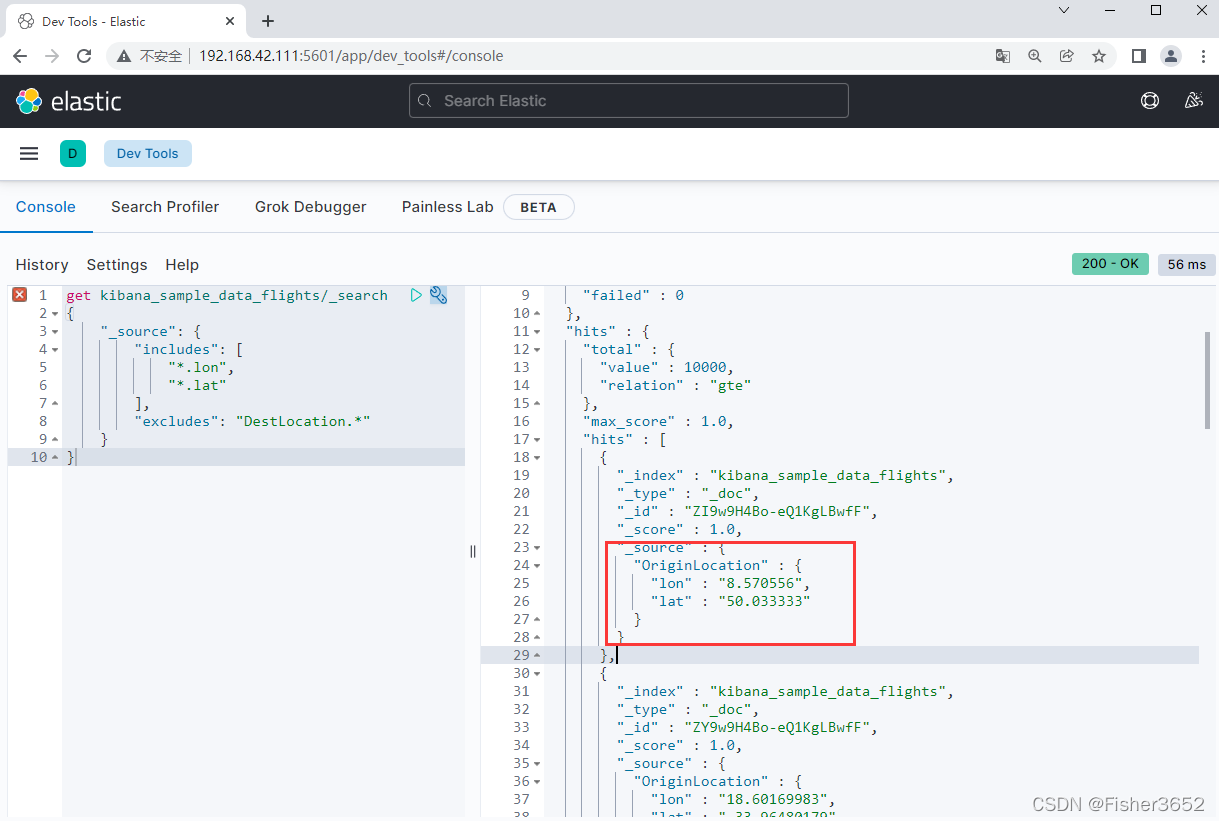
2.3 排序
- 大多搜索最后涉及的元素都是结果的排序( sort )。如果没有指定 sort 排序选 项,Elasticsearch 返回匹配的文档的时候,按照_ score 取值的降序来排列,这样 最为相关的(得分最高的)文档就会排名在前。为了对字段进行升序或降序排列,指定映射的数组,而不是字段的数组。通过在 sort 中指定字段列表或者是字段映 射,可以在任意数量的字段上进行排序。
get kibana_sample_data_flights/_search
{
"from": 100,
"size": 20,
"query": {
"match_all": {
}
},
"_source": [
"Origin*",
"*Weather"
],
"sort": [
{
"DistanceKilometers": "asc"
},
{
"FlightNum": "desc"
}
]
}

3. 检索
- 想要更精确的找到我们需要的文档,就需要使用带条件的搜索,主要包括两类,基于词项的搜索和基于全文的搜索
3.1 基于词项的搜索
3.1.1 term 查询
- 对词项做精确匹配,数值、日期等
get kibana_sample_data_flights/_search
{
"query": {
"term": {
"dayOfWeek": 3
}
}
}
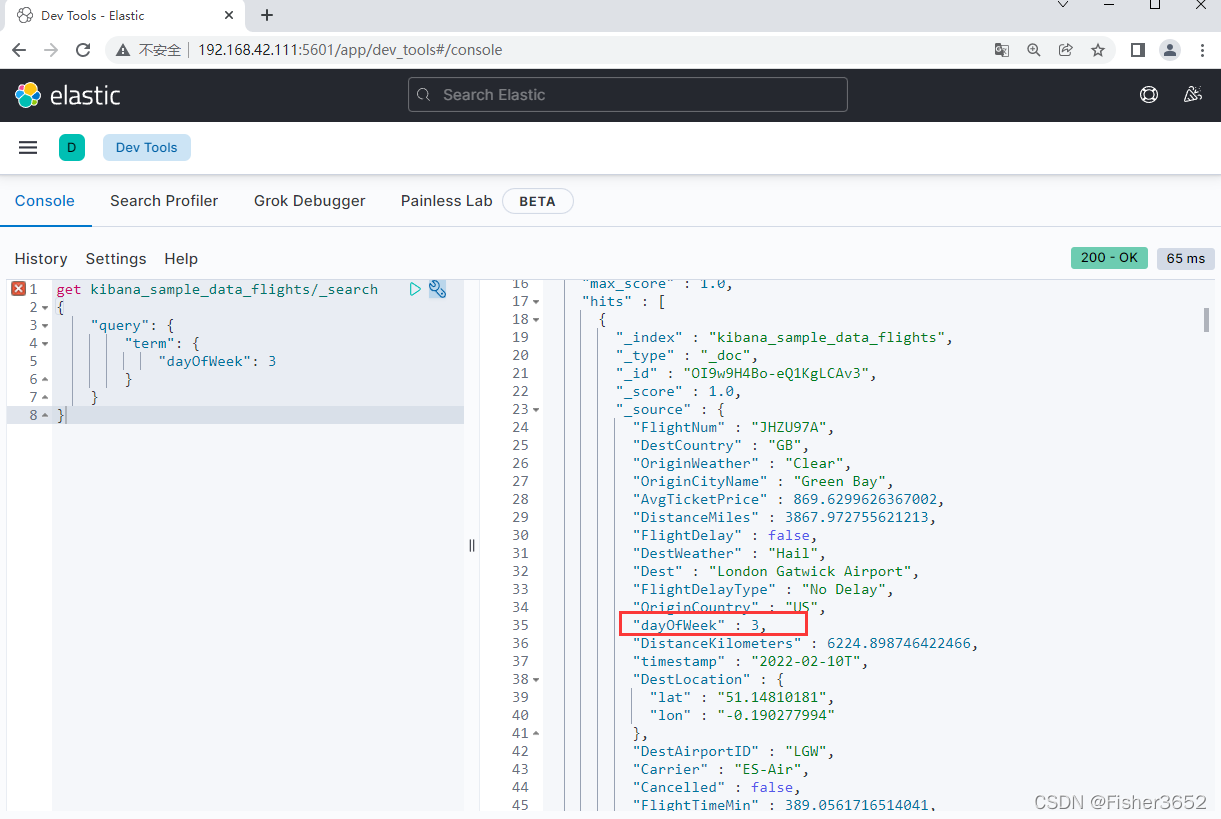
- 对于字符串而言,字符串的精确匹配是指字符的大小写,字符的数量和位置 都是相同的,词条(term)查询使用字符的完全匹配方式进行文本搜索,词条查询不会分析(analyze)查询字符串,给定的字段必须完全匹配词条查询中指定的字符串,可以把 term 查询理解为 SQL 语句中 where 条件的等于号
get kibana_sample_data_flights/_search
{
"query": {
"term": {
"OriginCityName": "Frankfurt am Main"
}
}
}

3.1.2 terms 查询
- 可以把 terms 查询理解为 SQL 语句中 where 条件的 in 操作符
get kibana_sample_data_flights/_search
{
"query": {
"terms": {
"OriginCityName": [
"Frankfurt am Main",
"Cape Town"
]
}
},
"_source": [
"OriginCountry",
"OriginCityName"
]
}
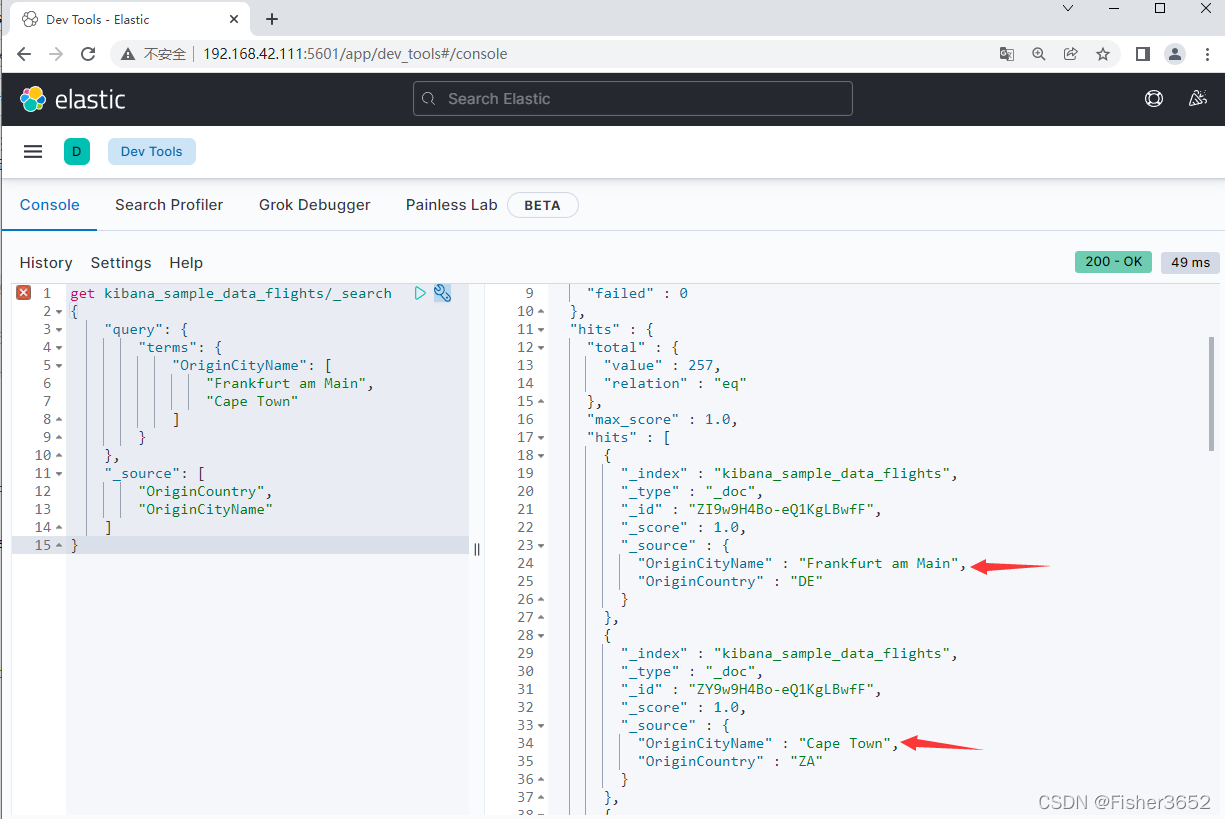
- Elasticsearch 在 terms 查询中还支持跨索引查询,这类似于关系型数据库中 的一对多或多对多关系。比如,用户与文章之间就是一对多关系,可以在用户索 引中存储文章编号的数组以建立这种对应关系,而将文章的实际内容保存在文章 索引中( 当然也可以在文章中保存用户 ID)。如果想将 ID 为 1 的用户发表的所有 文章都找出来,在文章索引中查询时为
POST /articles/ search
{
"query": {
"terms": {
"_id": {
"index": "users",
"id": 1,
"path": "articles"
}
}
}
}
- 在上面的例子中,terms 要匹配的字段是 id, 但匹配值则来自于另一个索引。 这里用到了 index、id 和 path 三个参数,它们分别代表要引用的索引、文档 ID 和字段路径。在上面的例子中,先会到 users 索引中在找 id 为 1 的文档,然后 取出 articles 字段的值与 articles 索引里的_id 做对比,这样就将用户 1 的所有文章都取出来了。
3.1.3 range 查询
- range 查询和过滤器的含义是不言而喻的,它们查询介于一定范围之内的值, 适用于数字、日期甚至是字符串。 为了使用范围查询,需要指定某个字段的上界和下界值
get kibana_sample_data_flights/_search
{
"query": {
"range": {
"FlightDelayMin": {
"gte": 100,
"lte": 200
}
}
}
}

- 可以查询出延误时间在 100~200 之间的航班。
gte:大于等于 (greater than and equal)
gt:大于 (greater than)
lte:小于等于 (less than and equal)
lt:大于 (less than )
boost:相关性评分
3.1.4 prefix 查询
- prefix 查询允许你根据给定的前缀来搜索词条
get kibana_sample_data_flights/_search
{
"query": {
"prefix": {
"DestCountry": "C"
}
}
}
3.1.5 wildcard 查询
- 通配符查询,使用字符串可以让 Elasticsearch 使用*通配符替代任何数量的字符(也可以 不含)或者是使用?通配符替代单个字符
- 例如,有 5 个单词:“bacon”“barn” “ban” 和“baboon” “bam”,
- “ban”的查询会匹配“bacon”“barn” “ban” 和“baboon”,这是因 为号可以匹配多个任意字符序列,而查询“ba?n” 只会匹配“barn",因为?任何时候都需要匹配一个单独字符
- 也可以混合使用多个和?字符来匹配更为复杂的通配模板,比如 ff?x 就可 以匹配 firefox
get kibana_sample_data_flights/_search
{
"query": {
"wildcard": {
"Dest": "*Marco*"
}
}
}
3.1.6 regexp 查询
- 正则查询
get kibana_sample_data_flights/_search
{
"query": {
"regexp": {
"字段名": "正则表达式"
}
}
}
4. 文本分析
- 词条(term)查询和全文(fulltext)查询最大的不同之处是:全文查询首先 分析(Analyze)查询字符串,使用默认的分析器分解成一系列的分词,term1, term2,termN,然后从索引中搜索是否有文档包含这些分词中的一个或多个。
- 所以,在基于全文的检索里,ElasticSearch 引擎会先分析(analyze)查询字 符串,将其拆分成小写的分词,只要已分析的字段中包含词条的任意一个,或全部包含,就匹配查询条件,返回该文档;如果不包含任意一个分词,表示没有任 何文档匹配查询条件。
- 这里就牵涉到了 ES 里很重要的概念,文本分析,当然对应非 text 类型字段来说,本身不存在文本数据词项提取的问题,所以没有文本分析的问题。
4.1 分析
- 分析( analysis )是在文档被发送并加入倒排索引之前,Elasticsearch 在其主体 上进行的操作。在文档被加入索引之前,Elasticsearch 让每个被分析字段经过一 系列的处理步骤。
- 字符过滤–使用字符过滤器转变字符
- 文本切分为分词—将文本切分为单个或多个分词
- 分词过滤—使用分词过滤器转变每个分词
- 分词索引–将这些分词存储到索引中
- 比如有段话“I like ELK,it include Elasticsearch&LogStash&Kibana”,分析以后的分词为 : i like elk it include elasticsearch logstash kibana
4.2 字符过滤
- Elasticsearch 首先运行字符过滤器(char filter)。这些过滤器将特定的字符 序列转变为其他的字符序列。这个可以用于将 HTML 从文本中剥离,或者是将任 意数量的字符转化为其他字符(也许是将“I love u 2”这种缩写的短消息纠正为“I love you too”。
- 在“I like ELK……”的例子里使用特定的过滤器将“&” 替换为“and”。
4.3 切分为分词
- 在应用了字符过滤器之后,文本需要被分割为可以操作的片段。底层的 Lucene 是不会对大块的字符串数据进行操作。相反,它处理的是被称为分词 ( token)的数据。
- 分词是从文本片段生成的,可能会产生任意数量(甚至是 0)的分词。例如, 在英文中一个通用的分词是标准分词器,它根据空格、换行和破折号等其他字符, 将文本分割为分词。在我们的例子里,这种行为表现为将字符串“I like ELK,it include Elasticsearch&LogStash&Kibana”分解为分词 I like ELK it include Elasticsearch and LogStash Kibana。
4.4 分词过滤器
- 一旦文本块被转换为分词,Elasticsearch 将会对每个分词运用分词过滤器 ( token filter)。 这些分词过滤器可以将一个分词作为输入, 然后根据需要进行修改,添加或者是删除。最为有用的和常用的分词过滤器是小写分词过滤器,它将输人的分词变为小写,确保在搜索词条“nosql" 的时候,可以发现关于“NoSq" 的聚会。分词可以经过多于 1 个的分词过滤器,每个过滤器对分词进行不同的操作,将数据塑造为最佳的形式,便于之后的索引。
- 在上面的例子,有 3 种分词过滤器:第 1 个将分词转为小写,第 2 个删除停用词 (停止词)“and”。
4.5 分词索引
- 当分词经历了零个或者多个分词过滤器,它们将被发送到 Lucene 进行文档的索引。这些分词组成了倒排索引。
4.6 分析器
- 所有这些不同的部分,组成了一个分析器( analyzer ),它可以定义为零个或多个字符过滤器、1 个分词器、零个或多个分词过滤器。Elasticsearch 中提供了很多预定义的分析器。我们可以直接使用它们而无须构建自己的分析器。
4.7 配置分析器
4.7.1 _analyze 接口
- 可以使用_analyze API 来测试 analyzer 如何解析字符串的
GET /<index>/_analyze
POST /<index>/_analyze
4.7.2 分词综述
- 因为文本分词会发生在两个地方:创建索引:当索引文档字符类型为 text 时, 在建立索引时将会对该字段进行分词;搜索:当对一个 text 类型的字段进行全文 检索时,会对用户输入的文本进行分词。
- 所以这两个地方都可以对分词进行配置
4.7.3 创建索引时
- ES 将按照下面顺序来确定使用哪个分词器
- 先判断字段是否有设置分词器,如果有,则使用字段属性上的分词器设置;(字段上)
- 如果设置了 analysis.analyzer.default,则使用该设置的分词器;(索引上)
- 如果上面两个都未设置,则使用默认的 standard 分词器。(默认 standard)
- 设置索引默认分词器
PUT test
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple"
}
}
}
}
}
- 为索引配置内置分词器,并修改内置的部分选项修改它的行为,设置停止词
put test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "standard",
"stopwords": [
"the",
"a",
"an",
"this",
"is"
]
}
}
}
}
}
- 为字段指定内置分词器
PUT test
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard",
"search_analyzer": "simple"
}
}
}
}
- 自定义分词器
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"std_english": {
"type": "standard",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "standard",
"fields": {
"english": {
"type": "text",
"analyzer": "std_english"
}
}
}
}
}
}
- 首先在索引 my_index 中配置了一个分析器 std_english,std_english 中使用了内置分析器 standard,并将 standard 的停止词模式改为英语模式
_english_(缺省是没有的),对字段 my_text 配置为多数据类型,分别使用了两 种分析器,standard 和 std_english。
POST /my_index/_analyze
{
"field": "my_text",
"text": "The old brown cow"
}

POST /my_index/_analyze
{
"field": "my_text.english",
"text": "The old brown cow"
}
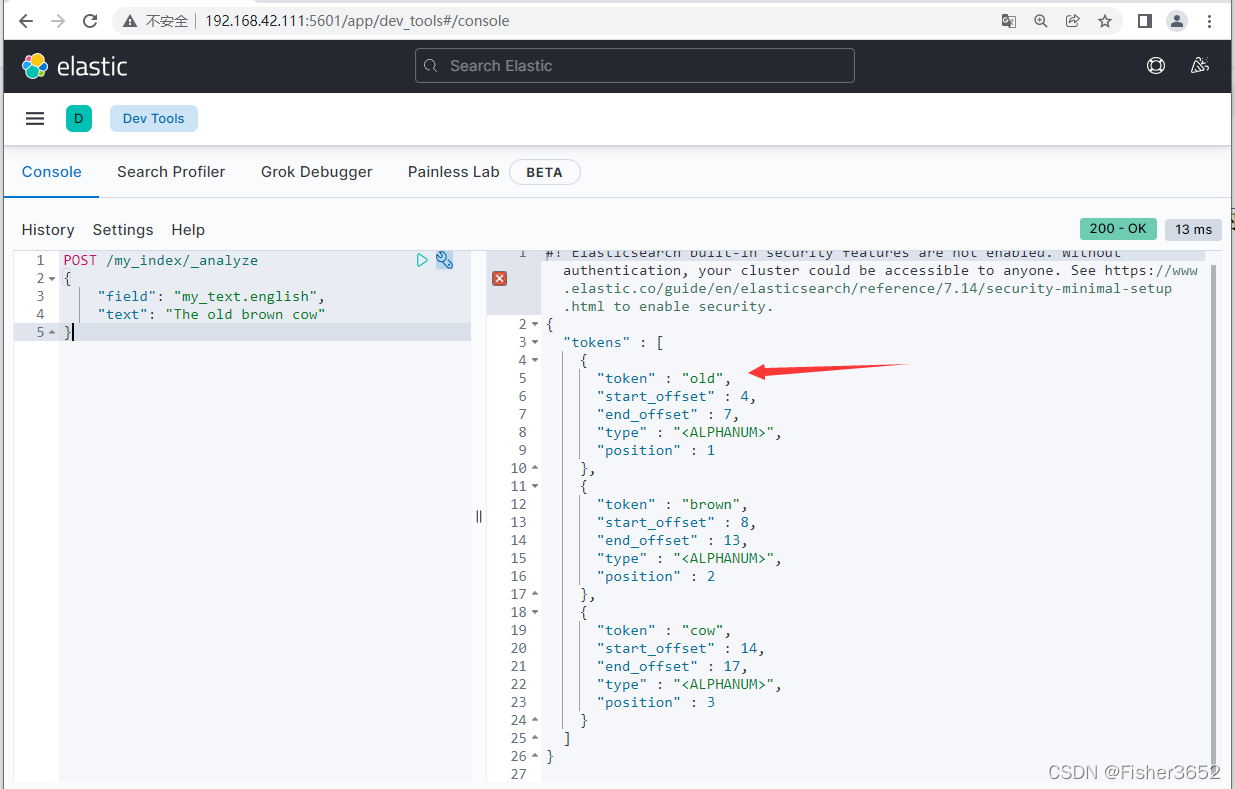
- 通过上述运行可以看到,分析器 std_english 中的 The 被删除,而 standard 中的并没有。这是因为 my_text.english 配置了单独的停止词,而standard 中没有设置停止词。
- 停止词/停用词一般是使用频率高,但没有太多实际意义的词,比如:this,is,the,what,not,then,with等
4.7.4 文档搜索时
- 文档搜索时使用的分析器有一点复杂,它依次从如下参数中如果查找文档分 析器,如果都没有设置则使用 standard 分析器
1、搜索时指定 analyzer 参数
2、创建索引时指定字段的 search_analyzer 属性
3、创建索引时字段指定的 analyzer 属性
4、创建索引时 setting 里指定的 analysis.analyzer.default_search
5、如果都没有设置则使用 standard 分析器
1: 搜索时指定 analyzer 查询参数
GET my_index/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop"
}
}
}
}
2、3: 指定字段的 analyzer 和 seach_analyzer
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}
4:指定索引的默认搜索分词器
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple"
},
"default_seach": {
"type": "whitespace"
}
}
}
}
}
4.8 内置分析器
- 每个被分析字段经过一系列的处理步骤:
- 字符过滤–使用字符过滤器转变字符
- 文本切分为分词—将文本切分为单个或多个分词
- 分词过滤—使用分词过滤器转变每个分词
- 每个分析器基本上都要包含上面三个步骤至少一个。其中字符过滤器可以为 0 个,也可以为多个,分词器则必须,但是也只能有一个,分词过滤器可以为 0 个,也可以为多个。
- Elasticsearch 已经为我们内置了很多的字符过滤器、分词器和分词过滤器, 以及分析器。以下是几种比较常用的分析器。
4.8.1 字符过滤器(Character filters)
- 字符过滤器种类不多。elasticearch 只提供了三种字符过滤器:
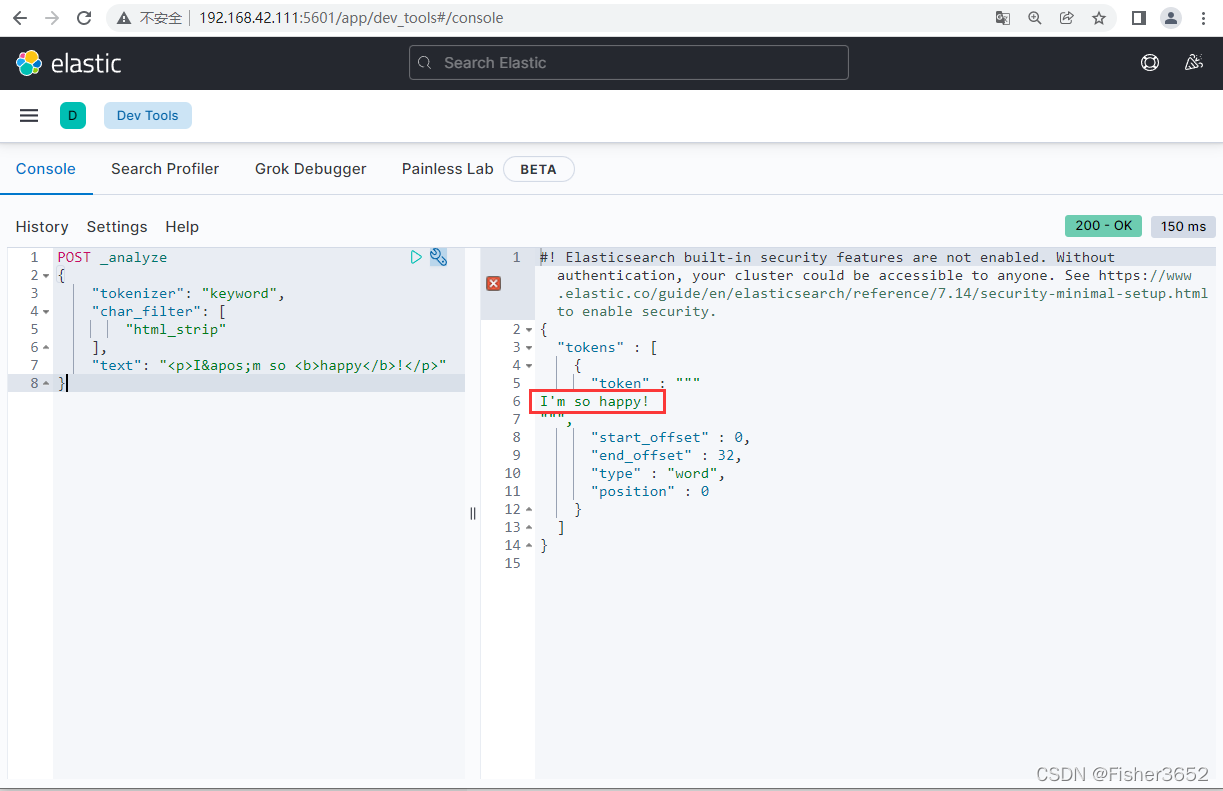
- HTML 字符过滤器(HTML Strip Char Filter):从文本中去除 HTML 元素
POST _analyze
{
"tokenizer": "keyword",
"char_filter": [
"html_strip"
],
"text": "<p>I'm so <b>happy</b>!</p>"
}
2. 映射字符过滤器(Mapping Char Filter):接收键值的映射,每当遇到与键相同的字符串时,它就用该键关联的值替换它们。
PUT pattern_test4
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "keyword",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
"James => 666",
"13 号 => 888"
]
}
}
}
}
}
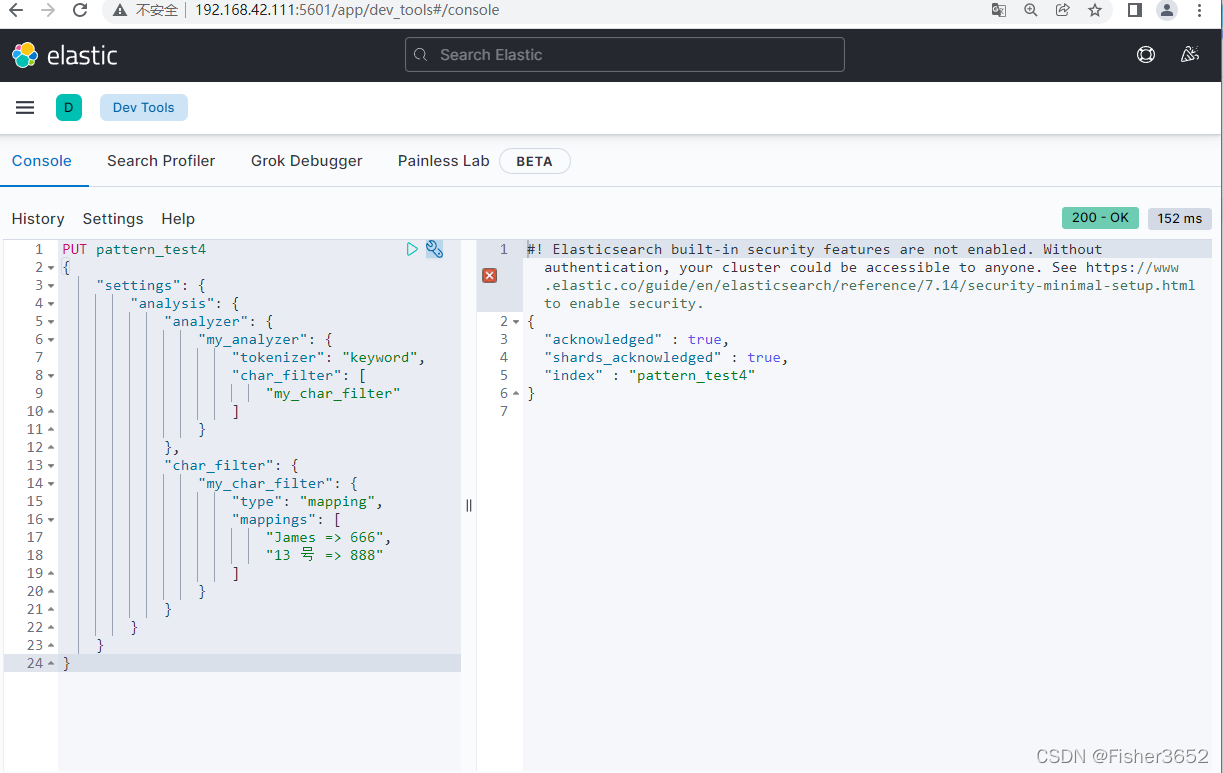
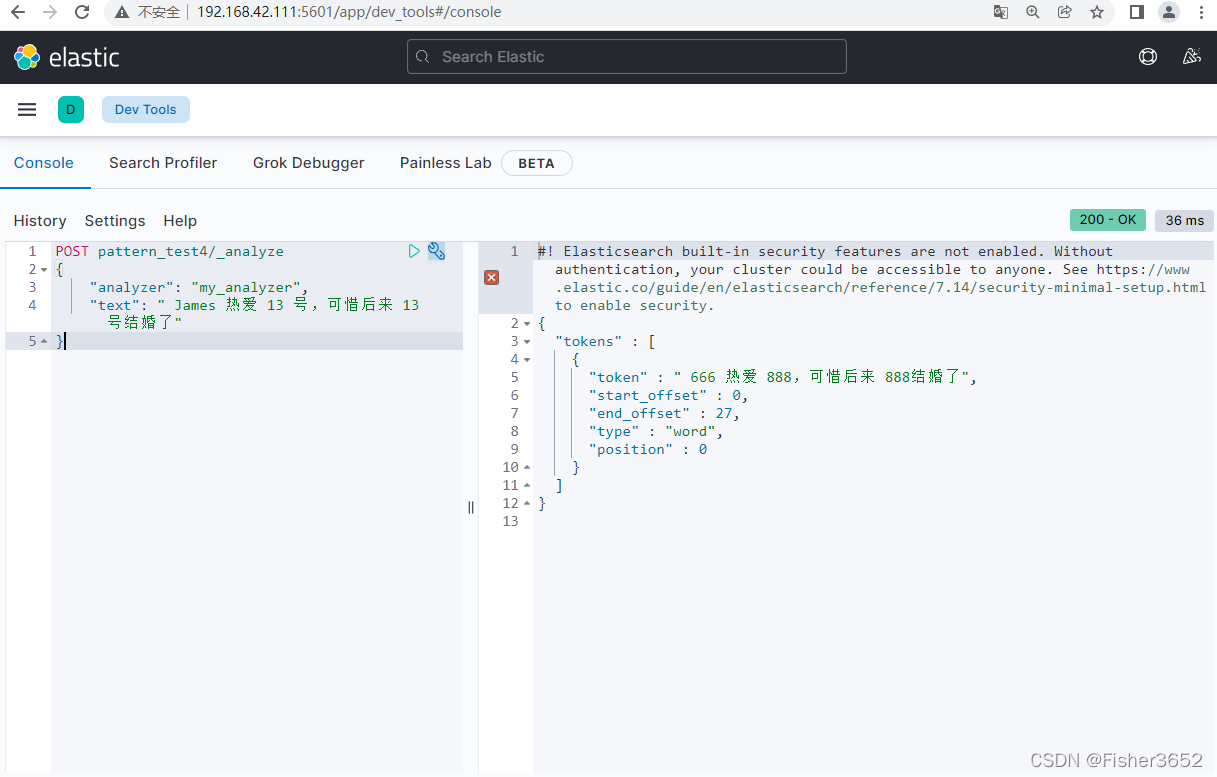
- 上例中,我们自定义了一个分析器,其内的分词器使用关键字分词器,字符 过滤器则是自定制的,将字符中的 James 替换为 666,13 号替换为 888。
POST pattern_test4/_analyze
{
"analyzer": "my_analyzer",
"text": " James 热爱 13 号,可惜后来 13 号结婚了"
}
3. 模式替换过滤器(Pattern Replace Char Filter):使用正则表达式匹配并替换字符串中的字符。但可能会导致性能变慢
POST _analyze
{
"analyzer": "standard",
"text": "My credit card is 123-456-789"
}
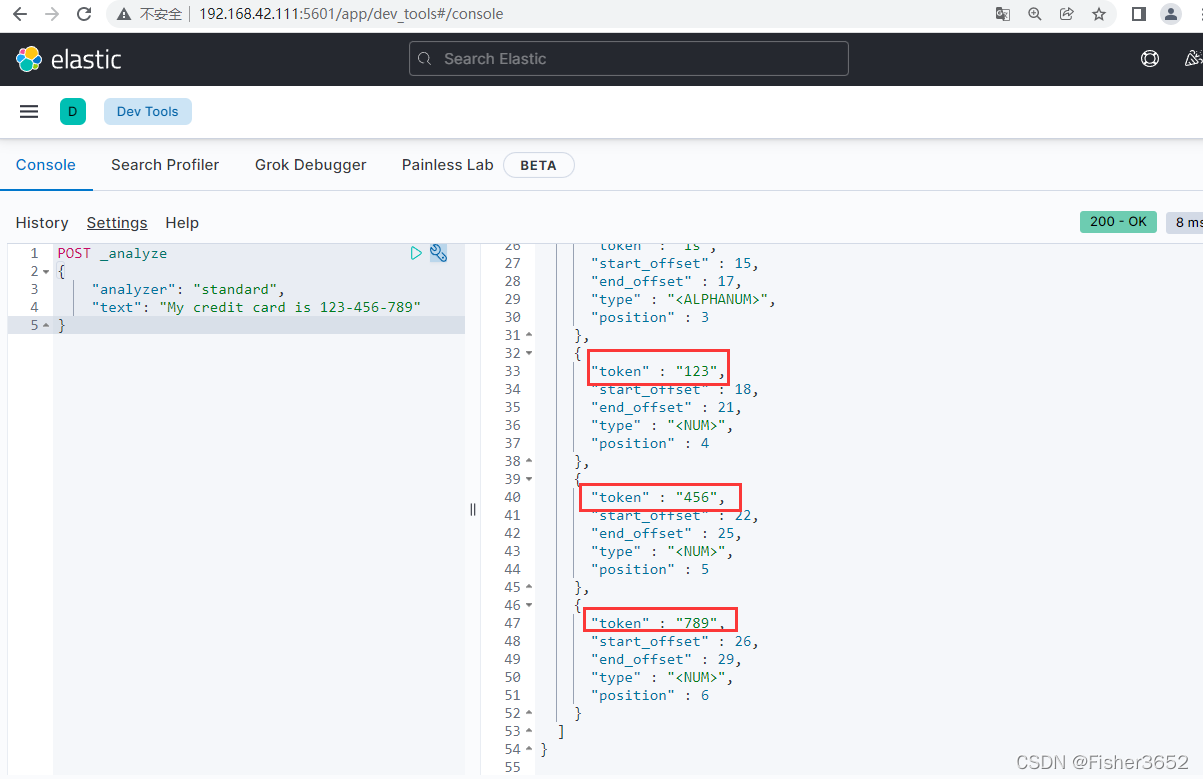
- 这样分词,会导致 123-456-789 被分为 123 456 789,但是我们希望 123-456-789 是一个整体,可以使用模式替换过滤器,替换掉“-”
PUT pattern_test5
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}
}
}
}
POST pattern_test5/_analyze
{
"analyzer": "my_analyzer",
"text": "My credit card is 123-456-789"
}

- 把数字中间的“-”替换为下划线“_”,这样的话可以让“123-456-789”作 为一个整体,而不至于被分成 123 456 789
4.8.2 分词器(Tokenizer)
- 标准分词器(standard)
标准分词器( standard tokenizer) 是一个基于语法的分词器,对于大多数欧洲 语言来说是不错的。它还处理了 Unicode 文本的切分。它也移除了逗号和句号这 样的标点符号。
“I have, potatoes.”切分后的分词分别是” I” 、” have” 和” potatoes”。 - 关键词分词器(keyword)
关键词分词器( keyword tokenizer )是- -种简单的分词器,将整个文本作为单 个的分词,提供给分词过滤器。只想应用分词过滤器,而不做任何分词操作时, 它可能非常有用。
‘Hi, there.’ 唯一的分词是 Hi, there。 - 字母分词器(letter)
字母分词器根据非字母的符号,将文本切分成分词。例如,对于句子 “Hi,there."分词是 Hi 和 there,因为逗号、空格和句号都不是字母:
'Hi, there. '分词是 Hi 和 there。 - 小写分词器(lowercase)
小写分词器( lowercase tokenizer)结合了常规的字母分词器和小写分词过滤 器(如你所想,它将整个分词转化为小写)的行为。通过 1 个单独的分词器来实现 的主要原因是,2 次进行两项操作会获得更好的性能。
'Hi, there.'分词是 hi 和 there。 - 空白分词器(whitespace)
空白分词器( whitespace tokenizer )通过空白来分隔不同的分词,空白包括空 格、制表符、换行等。请注意,这种分词器不会删除任何标点符号,所以文本“Hi, there." 的分词.
'Hi, there. '分词是 Hi,和 there.。 - 模式分词器(pattern)
模式分词器( patterm tokenizer)允许指定一个任 意的模式,将文本切分为分 词。被指定的模式应该匹配间隔符号。例如,可以创建一个定制分析器,它在出 现文本“. -.”的地方将分词断开。 - UAX URL 电子邮件分词器(uax_url_email)
在处理英语单词的时候,标准分词器是非常好的选择。但是,当下存在不少 以网站地址和电子邮件地址结束的文本。标准分析器可能在你未注意的地方对其 进行了切分。例如,有一个电子邮件地址的样本 john.smith@example.com,用标 准分词器分析它,切分后:
'john.smith@example.com’分词是 john.smith 和 example.com。
它同样将 URL 切分为不同的部分: 'http://example. com?q=foo’分词是 http、example.com、q 和 foo。
UAX URL 电子邮件分词器( UAX URL email tokenizer )将电子邮件和 URL 都作 为单独的分词进行保留。 - 路径层次分词器(path_hierarchy)
路径层次分词器( path hierarchy tokenizer )允许以特定的方式索引文件系统 的路径,这样在搜索时,共享同样路径的文件将被作为结果返回。例如,假设有 一个文件名想要索引,看上去是这样的(ustl0oal/var/log/elasticsearch.log。路径层次分词器将其切分为:
/usr/local/var/1og/elasticsearch. log
分词是/usr、/usr/local、/usr/local/var、/usr/local/var/ log 和/usr/local/var/ log/elasticsearch.1og。
这意味着,一个用户查询时,和上述文件共享同样路径层次(名字也是如此) 的文件也会被匹配上。查询“/usr/local/var/log/es.log" 时,它和 “/usr/local/var/log/elasticsearch.log" 拥有同样的分词,因此它也会被作为结果返回.
4.8.3 分词过滤器(Token filters)
- 标准分词过滤器(standard)
不要认为标准分词过滤器( standard token filter )进行了什么复杂的计算,实 际上它什么事情也没做。 - 小写分词过滤器(lowercase)
小写分词过滤器( lowercase token filter)只是做了这件事:将任何经过的分词 转换为小写。这应该非常简单也易于理解。 - 长度分词过滤器(length)
长度分词过滤器(length token filter)将长度超出最短和最长限制范围的单词 过滤掉。举个例子,如果将 min 设置为 2,并将 max 设置为 8,任何小于 2 个字 符和任何大于 8 个字符的分词将会被移除。 - 停用词分词过滤器(stop)
停用词分词过滤器(stop token fite)将停用词从分词流中移除。对于英文而言, 这意味着停用词列表中的所有分词都将会被完全移除。用户也可以为这个过滤器 指定-个待移除单词的列表。
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语 言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为 Stop Words(停用词)。
停用词(Stop Words)大致可分为如下两类:
1、使用十分广泛,甚至是过于频繁的一些单词。比如英文的“i”、“is”、 “what”,中文的“我”、“就”之类词几乎在每个文档上均会出现,查询这样 的词搜索引擎就无法保证能够给出真正相关的搜索结果,难于缩小搜索范围提高 搜索结果的准确性,同时还会降低搜索的效率。因此,在真正的工作中,Google 和百度等搜索引擎会忽略掉特定的常用词,在搜索的时候,如果我们使用了太多 的停用词,也同样有可能无法得到非常精确的结果,甚至是可能大量毫不相关的 搜索结果。
2、文本中出现频率很高,但实际意义又不大的词。这一类主要包括了语气 助词、副词、介词、连词等,通常自身并无明确意义,只有将其放入一个完整的 句子中才有一定作用的词语。如常见的“的”、“在”、“和”、“接着”之类。
下面是英文的默认停用词列表:
a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or; such, that, the, their;, then,there, these, they, this, to, was, will, with
系统内置的停止词如下:
arabic, - armenian_, _ basque ,_ bengali 1,_ brazilian ,_ bulgarian_,_ catalan ,czech, danish_,_ dutch ,english_ ,finnish_, french_ ,galician ,german,greek.hindi, hungarian , indonesian_ ,_ irish_,_ italian , _ latvian_,norwegian,_ persian_ ,portuguese,_ romanian_,_ russian_,- sorani_,- spanish_,_ swedish_,thai ,turkish
- 截断分词过滤器
截断分词过滤器( truncate token filter )允许你通过定制配置中的 length 参 数,截断超过一定长度的分词。默认截断多于 10 个字符的部分。 - 修剪分词过滤器
修剪分词过滤器( trim token filter )删除 1 个分词中的所有空白部分。例如, 分词" foo "将被转变为分词 foo。 - 限制分词数量过滤器
限制分词数量分词过滤器(limit token count token filter)限制了某个字段可 包含分词的最大数量。例如,如果创建了一个定制的分词数量过滤器,限制是 8, 那么分词流中只有前 8 个分词会被索引。这个设置使用 max_ token_ count 参数, 默认是 1 (只有 1 个分词会被索引)。
4.9 自定义分析器
- 去除所有的 HTML 标签
- 将 & 替换成 and ,使用一个自定义的 mapping 字符过滤器
- 使用 standard 分词器分割单词
- 使用 lowercase 分词过滤器将词转为小写
- 用 stop 分词过滤器去除一些自定义停用词。
PUT pattern_custom
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"char_filter": [
"html_strip",
"&_to_and"
],
"filter": [
"lowercase",
"my_stopwords"
],
"tokenizer": "standard",
"type": "custom"
}
},
"char_filter": {
"&_to_and": {
"mappings": [
"&=>and"
],
"type": "mapping"
}
},
"filter": {
"my_stopwords": {
"stopwords": [
"king",
"james"
],
"type": "stop"
}
}
}
}
}
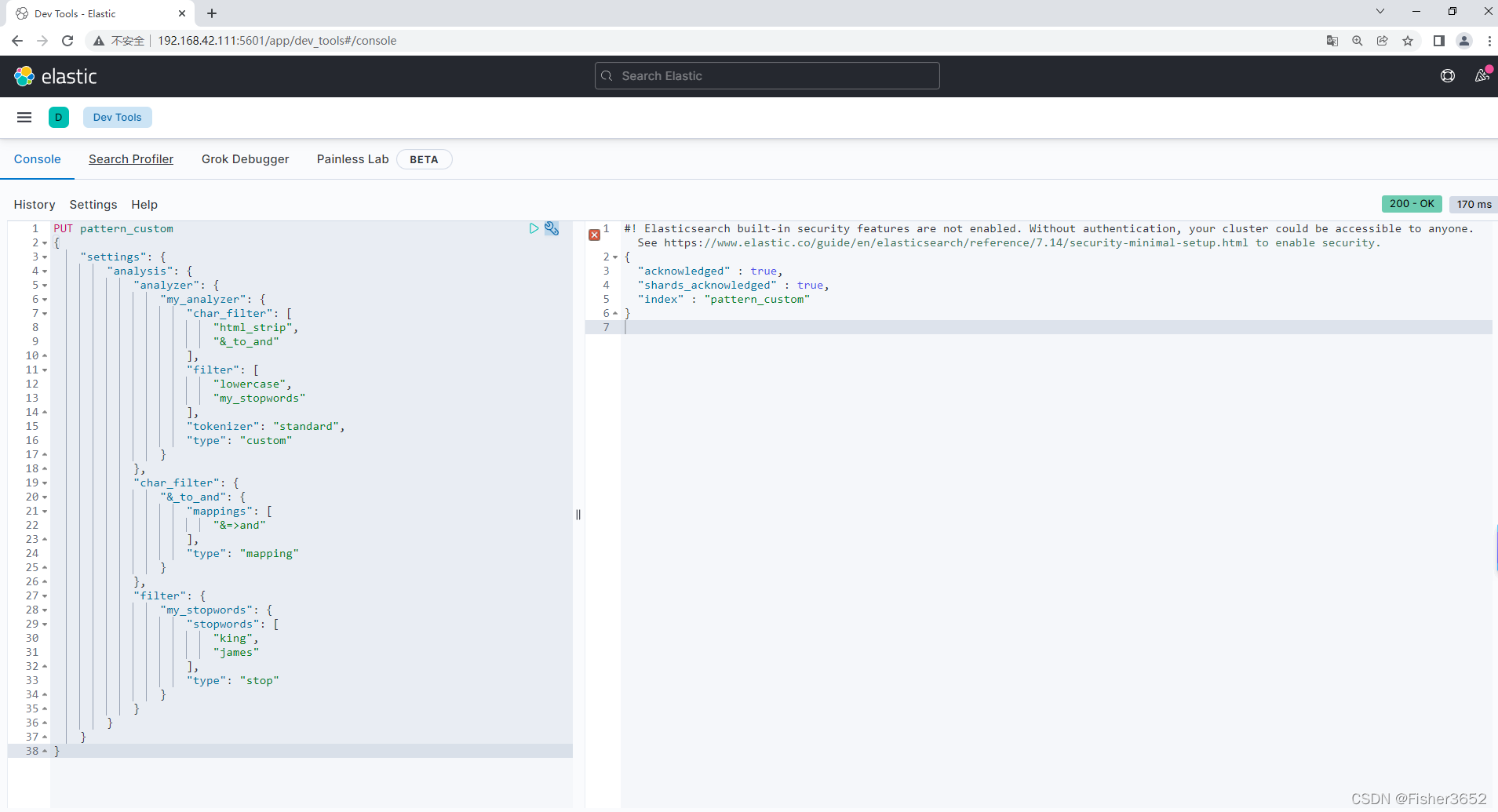
POST pattern_custom/_analyze
{
"analyzer": "my_analyzer",
"text": "<br> I & Lison & king & James are handsome<br>"
}
4.10 中文分析器
- 上面的分析器基本都是针对英文的,对中文的处理不是太好
POST _analyze
{
"analyzer": "standard",
"text": "中央广播电视总台"
}
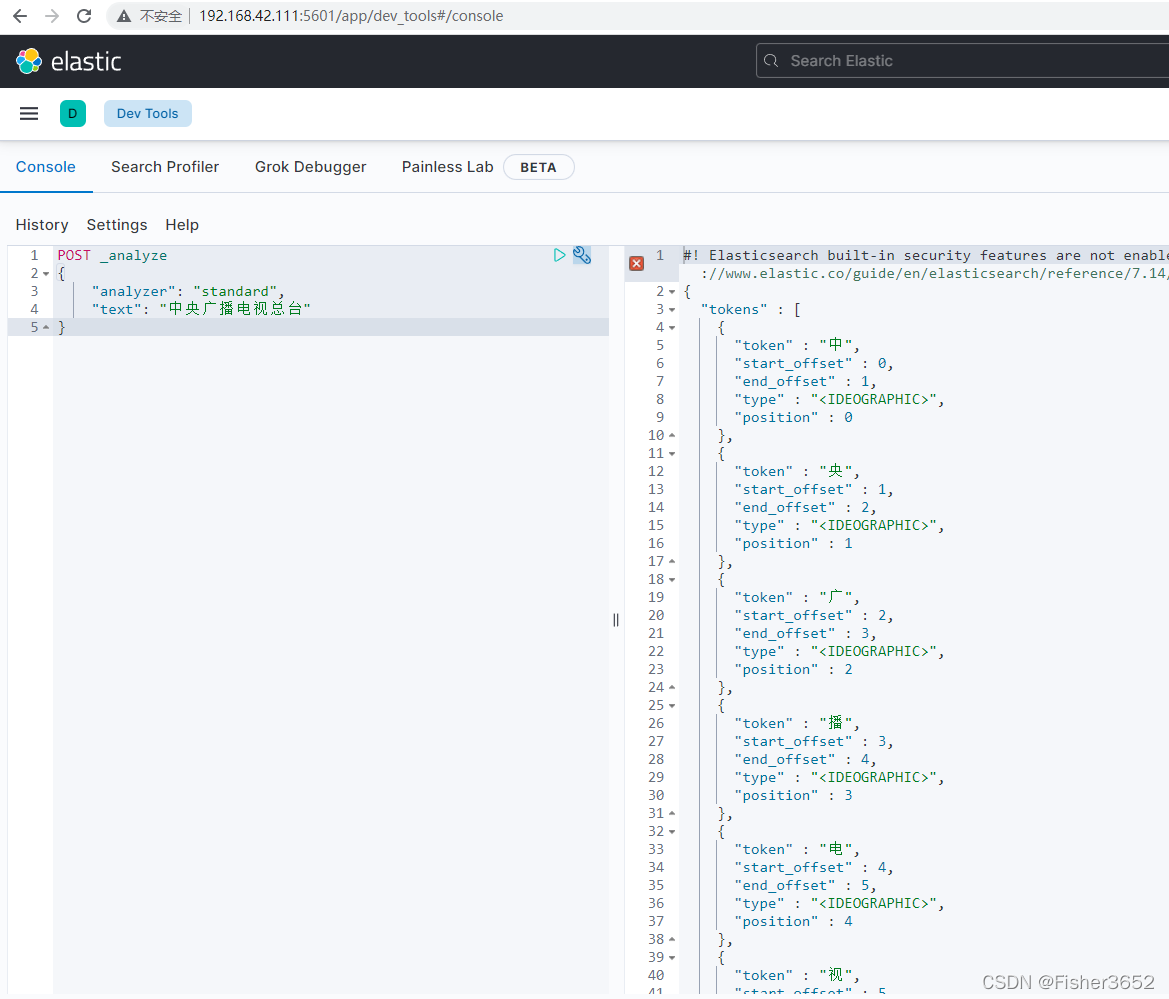
- Standard 分析器把中文语句拆分为一个个的汉字,并不是太适合。这时候,就需要中文分析器。中文分析器有很多,例如 cjk,ik 等等,我们选用比较有名的 ik 作为我们的中文分析器
- 安装,进入 elasticsearch 目录下的 bin 目录,并执行
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.0/elasticsearch-analysis-ik-7.14.0.zip

- 安装完成后,必须重启 elasticsearch
- 使用 IK 分词器有两种分词效果,一种是 ik_max_word(最大分词)和 ik_smart(最
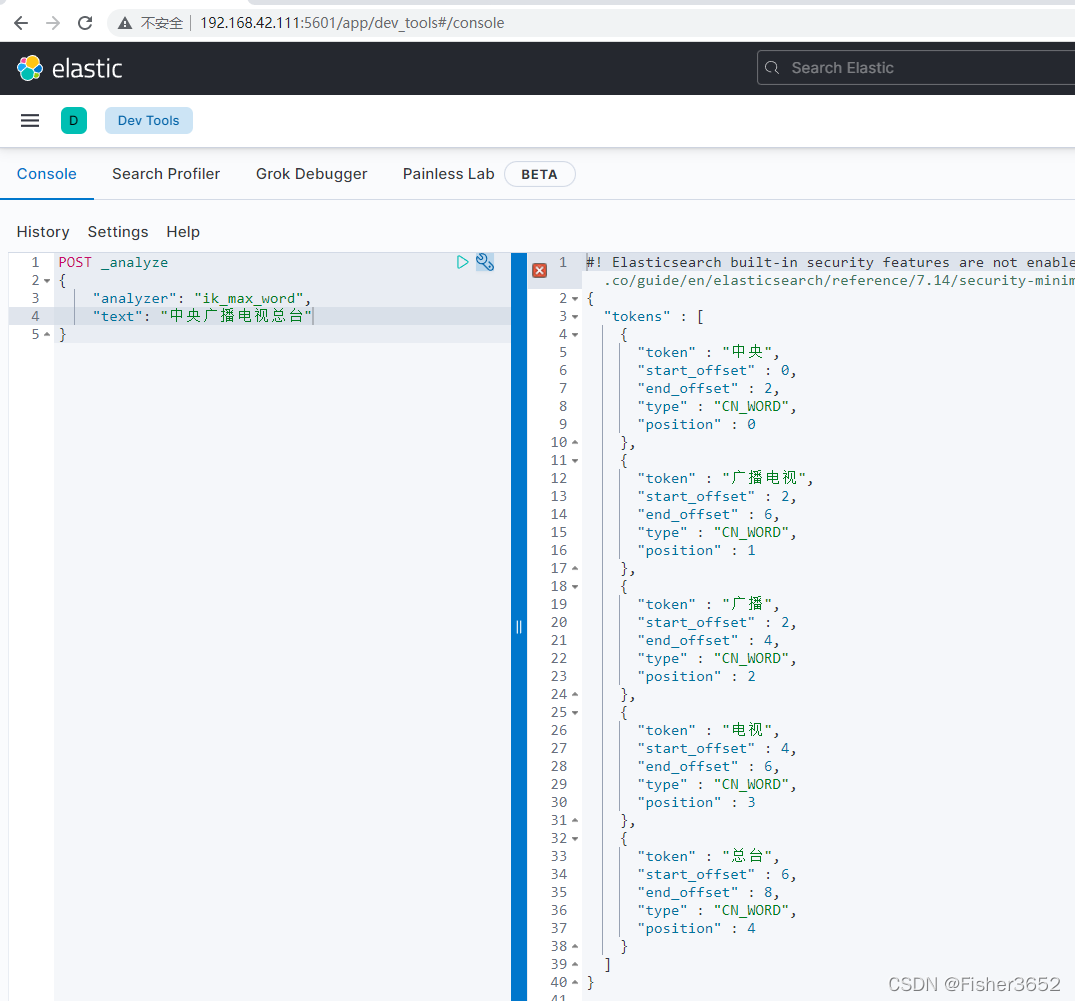
小分词) - ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国, 共和,和,国国,国歌”,会穷尽各种可能的组合;
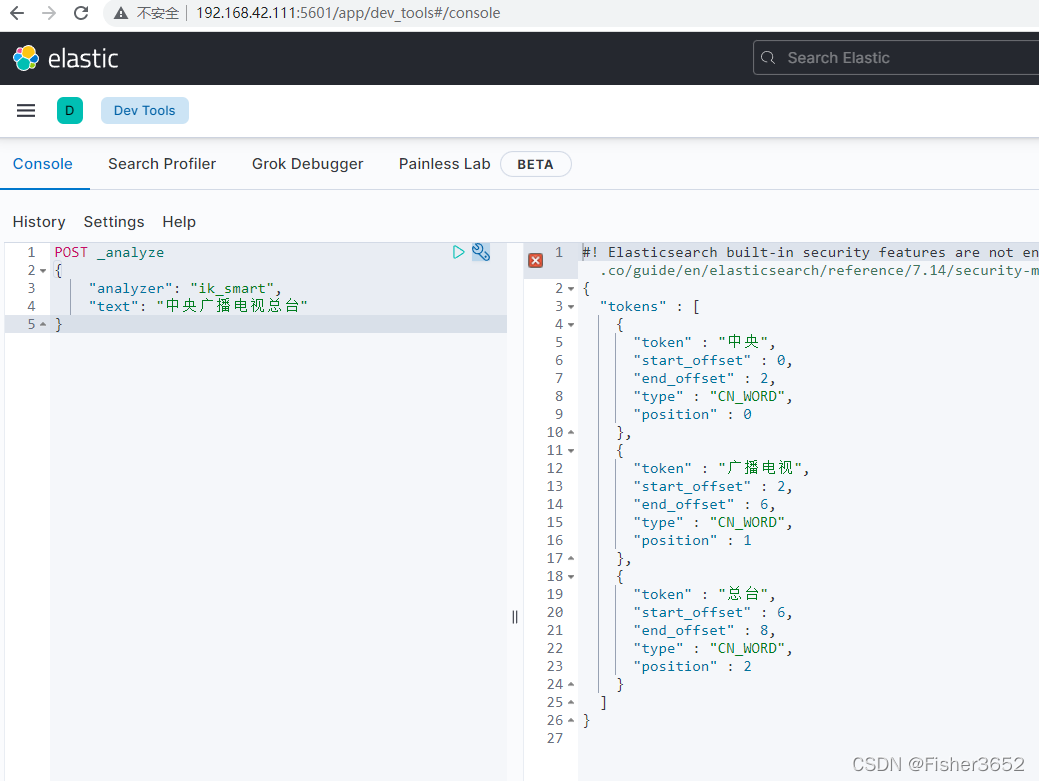
- ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
- 使用方式和一般的分析器没有什么差别。比如,我们对“中央广播电视总台” 进行分词。
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中央广播电视总台"
}
POST _analyze
{
"analyzer": "ik_smart",
"text": "中央广播电视总台"
}
5. 基于全文的搜索
- 了解了文本分析以后,就可以学习基于全文的搜索了,这里就需要用到 match 查询。
5.1 match 查询
"query":{
"match": {
"elk": "Elasticsearch LogStash Kibana"
}
}
- 查询字符串是“Elasticsearch LogStash Kibana”,被分析器分词之后,产生三个小写的单词:elasticsearch logstash kibana,然后根据分析的结果构造一个布尔查询,默认情况下,引擎内部执行的查询逻辑是:只要 elk 字段值中包含有任意一个关键字 elasticsearch 或 logStash 或 kibana,那么返回该文档,相对于的伪代码是
if( doc. elk.contains(elasticsearch)
||doc. elk.contains(logstash)
||doc. elk.contains (kibana) ){
return doc ;
}
- 匹配查询的行为受到两个参数的控制:
operator:表示单个字段如何匹配查询条件的分词
minimum_should_match:表示字段匹配的数量 - 通过调整 operator 和 minimum_should_match 属性值,控制匹配查询的逻 辑条件,进而控制引擎返回的结果。默认情况下 operator 的值是 or,在构造查 询时设置分词之间的逻辑运算符,如果设置为 and,那么引擎内部执行的查询逻辑是:
if( doc.elk.contains(elasticsearch)
&&doc. elk.contains(logstash)
&&doc. elk.contains (kibana) ){
return doc ;
}
- 对于 minimum_should_match 属性值,默认值是 1,如果设置其值为 2,表示分词必须匹配查询条件的数量为 2,这意味着,只要文档的 elk 字段包含任意两个关键字,就满足查询条件,但是如果文档中只有 1 个关键字,这个文档就不满足条件。比如:
POST /kibana_sample_data_logs/_search
{
"query": {
"match": {
"message": "firefox chrome"
}
}
}

- 检索包含 firefox 或 chrome 的文档,如果改为:
POST /kibana_sample_data_logs/_search
{
"query": {
"match": {
"message": {
"query": "firefox chrome",
"operator": "and"
}
}
}
}
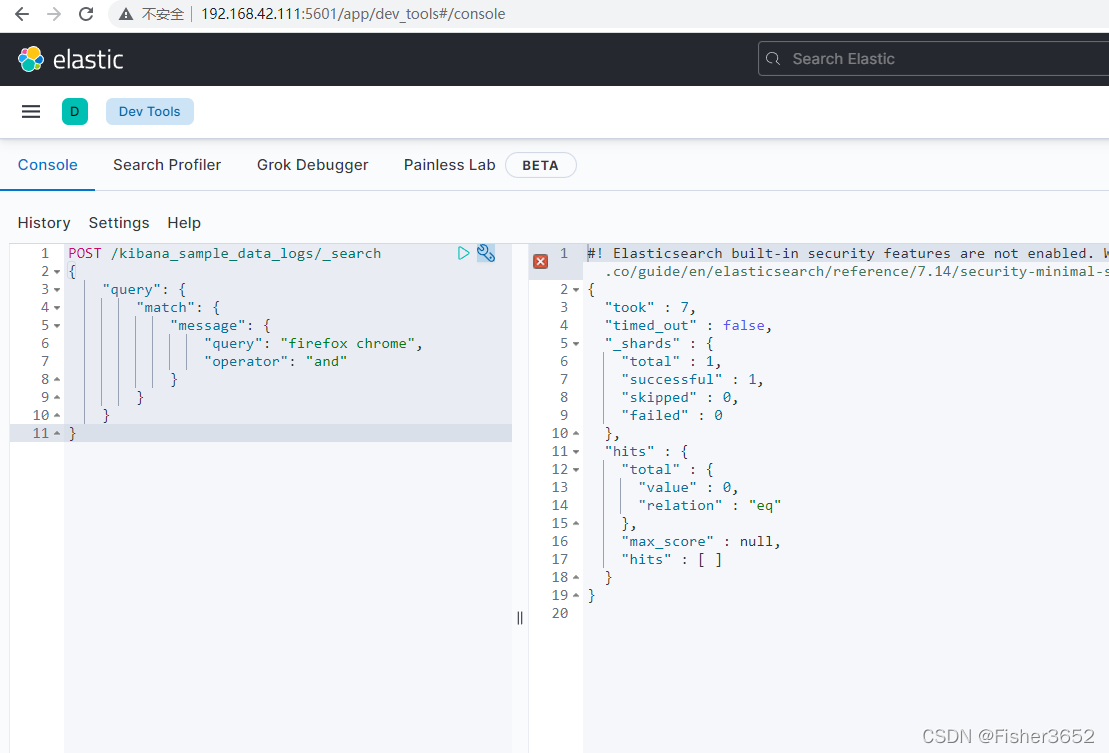
- 则不会有任何文档返回,因为没有文档的 message 字段既包含 firefox 又包 含 chrome。同样:
POST /kibana_sample_data_logs/_search
{
"query": {
"match": {
"message": {
"query": "firefox chrome",
"minimum_should_match": 2
}
}
}
}
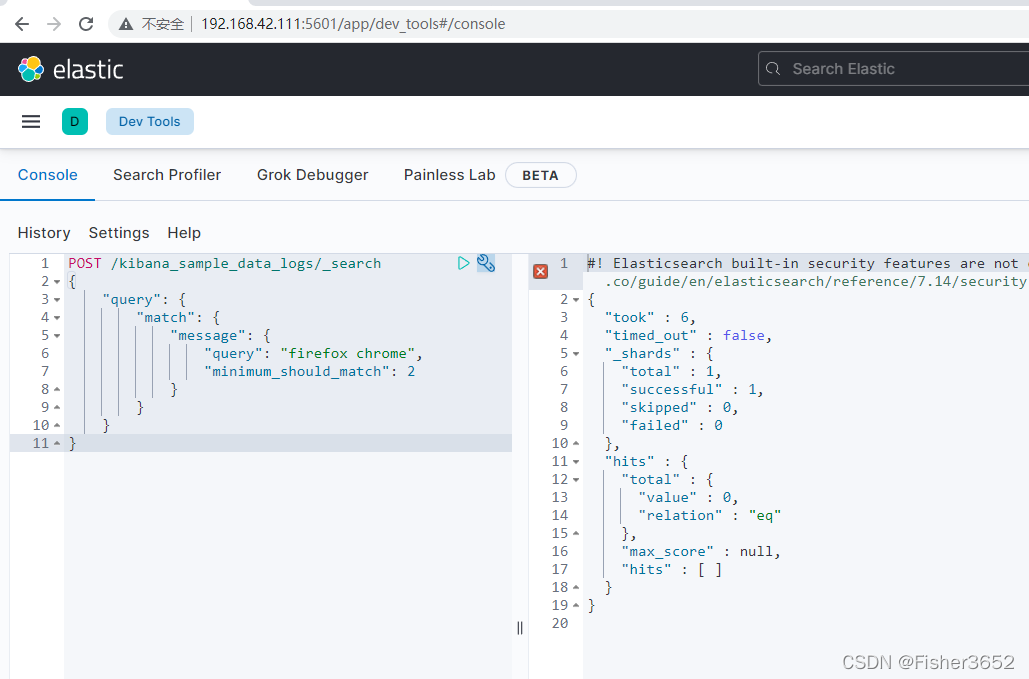
- 也不会任何文档返回,原因也是一样的,因为没有文档的 message 字段既包 含 firefox 又包含 chrome。
5.2 multi_match 查询
- 多个字段上执行匹配相同的查询,比如:
POST /kibana_sample_data_flights/_search
{
"query": {
"multi_match": {
"query": "AT",
"fields": [
"DestCountry",
"OriginCountry"
]
}
}
}
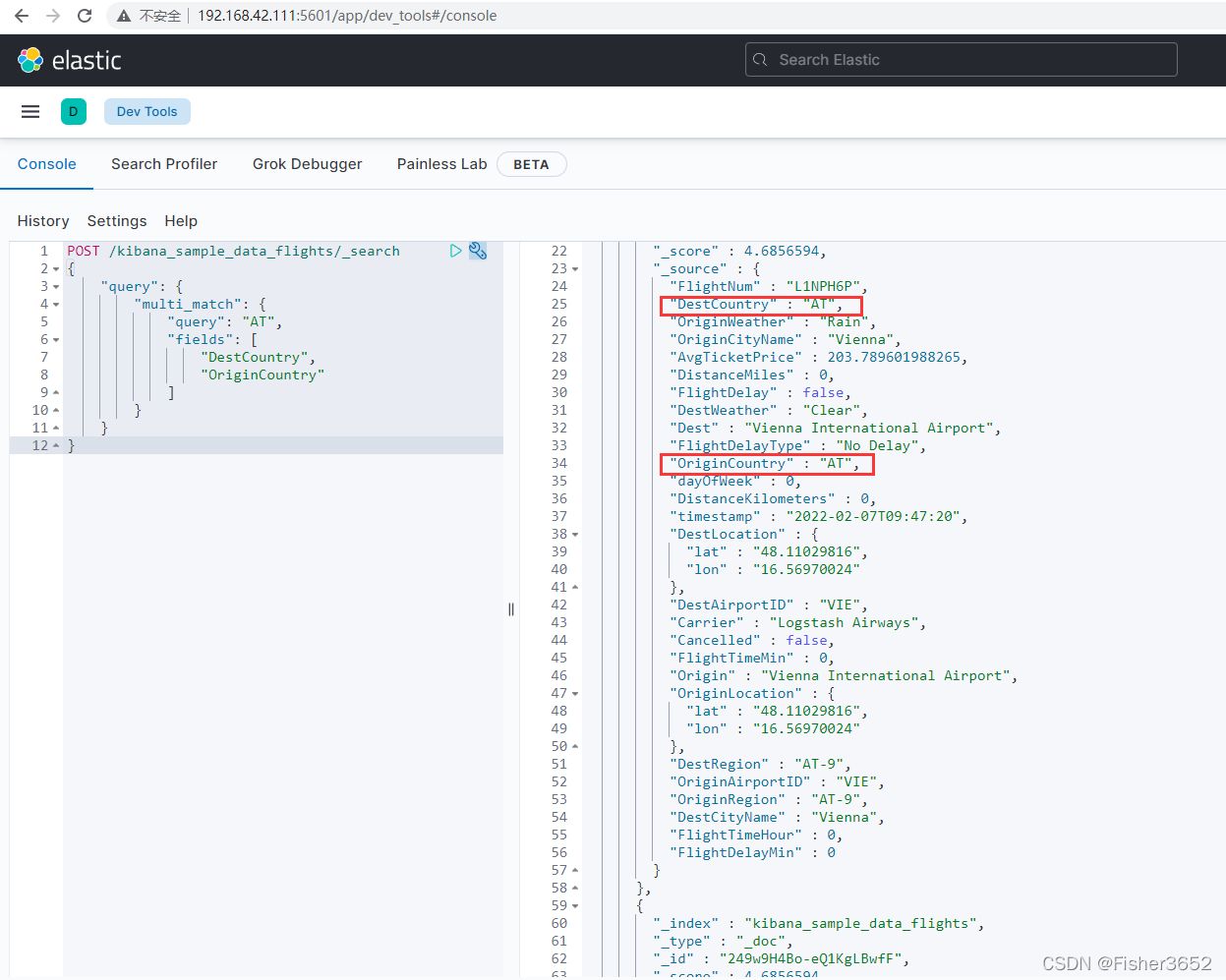
- 请求将同时检索文档中 DestCountry 和 OriginCountry 这两个字段,只要有一 个字段包含 AT 词项该文档就满足查询条件。
5.3 match_phrase 查询
- 当你希望寻找邻近的单词时,可以使用match_phrase 查询
- 假设我们要找到 title 字段包含这么一段文本“quick brown fox”的文档,然 后我们用
GET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": "quick brown fox"
}
}
}
- match_phrase 查询首先解析查询字符串来产生一个词条列表。然后会搜索所有的词条,但只保留包含了所有搜索词条的文档,并且词条的位置要邻接。
GET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": "quick fox"
}
}
}
- 这个查询查询不会匹配我们的任何文档,因为没有文档含有邻接在一起的 quick 和 fox 词条。也就是说,匹配的文档必须满足
1、quick、brown 和 fox 必须全部出现在 title 字段中。
2、brown 的位置必须比 quick 的位置大 1。
3、fox 的位置必须比 quick 的位置大 2。 - 如果以上的任何一个条件没有被满足,那么文档就不能被匹配。
- 精确短语(Exact-phrase)匹配也许太过于严格了。也许我们希望含有"quick brown fox"的文档也能够匹配"quick fox"查询,即使位置并不是完全相等的。 我们可以在短语匹配使用 slop 参数来引入一些灵活性:
GET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": {
"query": "quick fox",
"slop": 1
}
}
}
}
- slop 参数缺省为 0,它告诉 match_phrase 查询词条能够最远相隔多远时仍然 将文档视为匹配。相隔多远的意思是,你需要移动一个词条多少次来让查询和文 档匹配?比如这样一段文本:
hello world, java is very good, spark is also very good - 使用 match_phrase 搜索 java spark 搜不到
- 如果我们指定了 slop,那么就允许 java spark 进行移动,来尝试与 doc 进 行匹配
java is very good spark is
java spark
java --> spark
java --> spark
java --> spark
- 上面展示了,当固定第一个 term 的时候,后面的 teram 经过移动直到匹 配上搜索词的经过这个移动的次数就是 slop,实际例子如下:
POST /kibana_sample_data_logs/_search
{
"query": {
"match_phrase": {
"message": "firefox 6.0a1"
}
}
}

5.4 match_phrase_prefix 查询
- 基于前缀的短语匹配
{
"match_phrase_prefix": {
"brand": "johnnie walker bl"
}
}
- 这种查询的行为与 match_phrase 查询一致,不同的是它将查询字符串的最 后一个词作为前缀使用,换句话说,可以将之前的例子看成如下这样:
"johnnie walker bl*" - 与 match_phrase 一样,它也可以接受 slop 参数(参照 slop )让相对词 序位置不那么严格:
{
"match_phrase_prefix": {
"brand": {
"query": "walker johnnie bl",
"slop": 10
}
}
}
- prefix 查询存在严重的资源消耗问题,短语查询的这种方式也同样如此。前缀 a 可能会匹配成千上万的词,这不仅会消耗很多系统资源,而且结果的用处也不大。
- 可以通过设置 max_expansions 参数来限制前缀扩展的影响,一个合理的值 是是 50 ,这也是系统默认的值:
{
"match_phrase_prefix": {
"brand": {
"query": "johnnie walker bl",
"max_expansions": 50
}
}
}
POST /kibana_sample_data_logs/_search
{
"query": {
"match_phrase_prefix": {
"message": "firefox 6.0"
}
}
}
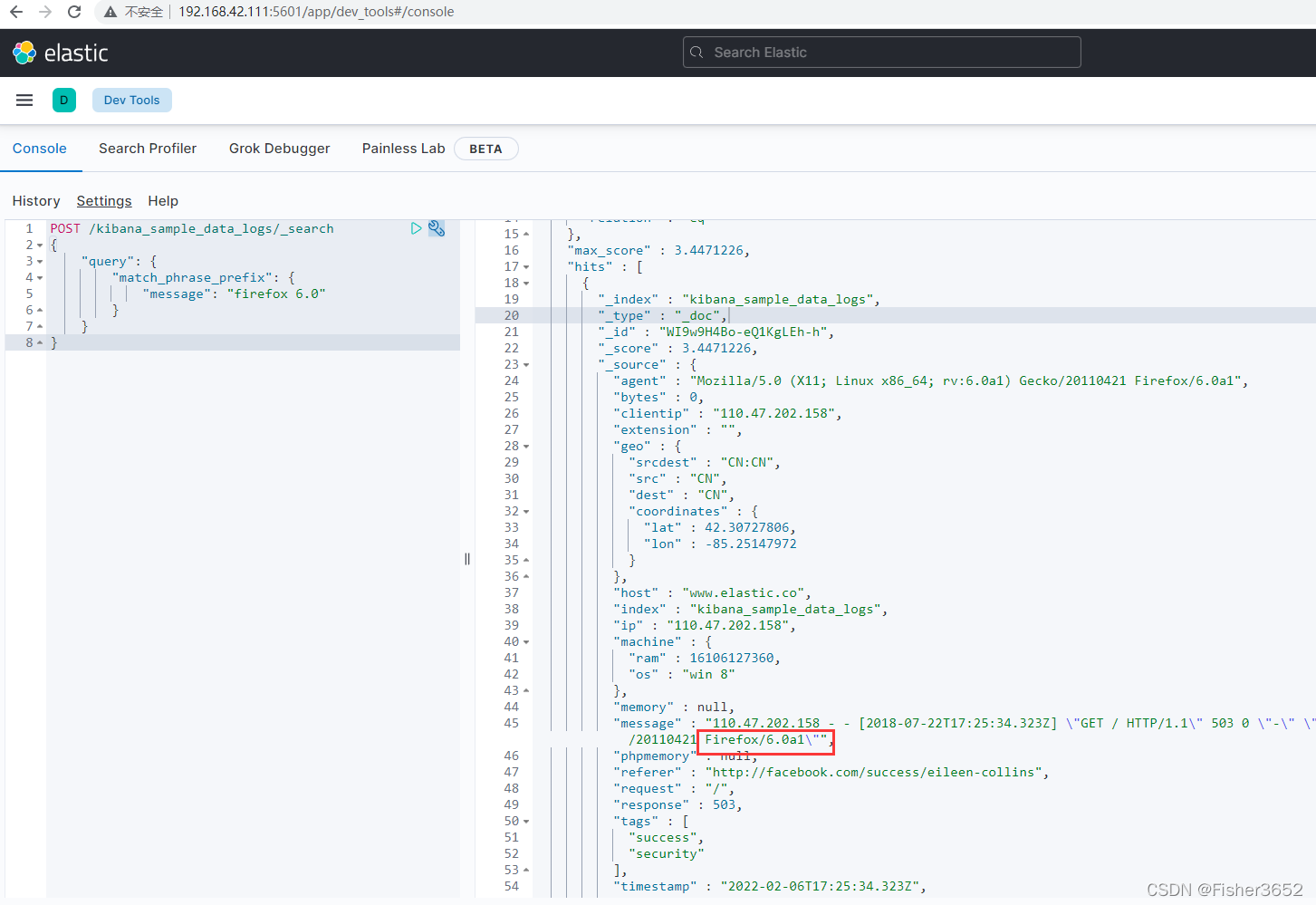
5.5 模糊查询、纠错与提示器
5.5.1 编辑距离算法
- 在 Elasticsearch 基于全文的查询中,除了与短语相关的查询以外,其余查询 都包含有一个名为 fuzziness 的参数用于支持模糊查询。Elasticsearch 支持的模糊 查询与 SQL 语言中模糊查询还不一样,SQL 的模糊查询使用“% keyword%"的形 式,效果是查询字段值中包含 keyword 的记录。Elaticsearch 支持的模糊查询比 这个要强大得多,它可以根据一个拼写错误的词项匹配正确的结果,例如根据 firefix 匹配 firefox。在自然语言处理领域,两个词项之间的差异通常称为距离或 编辑距离,距离的大小用于说明两个词项之间差异的大小,计算词项
- 编辑距离的算法有多种,在 Elasticsearch 中主要使用 Levenshtein 和 NGram 两种。其他与此相关的算法也都是在这两种算法基础上进行的改造,基本思想都 是一致的。所以理解这两个算法的核心思想是学习这部分内容的关键。
5.5.2 Levenshtein 与 NGram
- Levenshein算法是前苏联数学家 Vladimir Levenshein在1965 年开发的一套算 法, 这个算法可以对两个字符申的差异程度做量化。量化结果是一一个正整数, 反映的是一个字符申变成另一个字符申最少需要多少次的处理。由于 Levenshtein 算法是最为普遍接受的编辑距离算法,所以在很多文献中如果没有特殊说明编辑 距离算法就是指 Levenshtein 算法。
- 在 Levenshtein 算法中定义了三种字符操作,即替换、插人和删除,后来又 由其他科学家补充了一个换位操作。在转换过程中,每执行次操作编辑距离就加 1, 编辑距离越大越能说明两个字符串之间的差距大。
- 比如从 firefix 到 firefox 需要将“i"替换成“o”, 所以编辑距离为 1;而从 fax 到 fair 则需要将“x”替换为“i"并在结尾处插人“r”,所以编辑距离为 2。显然 在编辑距离相同的情况下,单词越长错误与正确就越接近。比如编辑距离同样为 2 的情况下,从 fax 到 fair 与从 elascsearxh 到 elasticsearch,后者 elastesearsh 是由 拼写错误引起的可能性就更大此。所以编辑距离这种量化标准一般还需要与单词 长度结合起来 明虑,在一些极端情况下编辑距离还应该设置为 0,比如像 at、 on 这类长度只有 2 的短单词。
- NGram 一般是指 N 个连续的字符,具体的字符个数被定义为 NGram 的 size。 size 为 1 的 NGram 称为 Unigram, size 为 2 时称为 Bigram,而 size 为 3 时则称为 Trigram。如果 NGram 处理的单元不是字符而是单词,一般称之为 Shingle。使用 NGram 计算编辑距离的基本思路是让字符串分解为 NGram,然后比较分解后共 有 NGram 的数量。假设有 a、b 两个字符申,则 NGram 距离的具体运算公式为
ngram( a )+ngram(b) -2 * ngram(a)∩ngram( b)
- 式中,ngram(a)和 ngram(b)代表 a、b 两个字符串 NGram 的数量; ngram(a) ∩ ngram(b)则是两者共有 NGram 的数量。
- 例如按 Bigram 处理 firefix 和 firefox 两个单词,分别为“fi,ir,re, ef, fi,ix”和“fi, ir, re, ef, fi, ox"。 那么两个字符申的 Bigram 个数都为 6,而共有 Bigram 为 4,则 最终 NGram 距离为 6+6-2x4=4。
- 在应用上,Levenshtein 算法更多地应用于对单个词项的模糊查询上,而 NGram 则应用于多词项匹配中。Elasticseareh 同时应用了两种算法。
5.5.3 模糊查询
- 返回包含与搜索字词相似的字词文档;为了找到相似的术语,fuzzy 查询将 在指定的编辑距离内创建一组搜索词的所有可能的变体或扩展。查询然后返回每个扩展的完全匹配。
get kibana_sample_data_logs/_search
{
"query": {
"fuzzy": {
"message": {
"value": "firefix",
"fuzziness": "1"
}
}
}
}
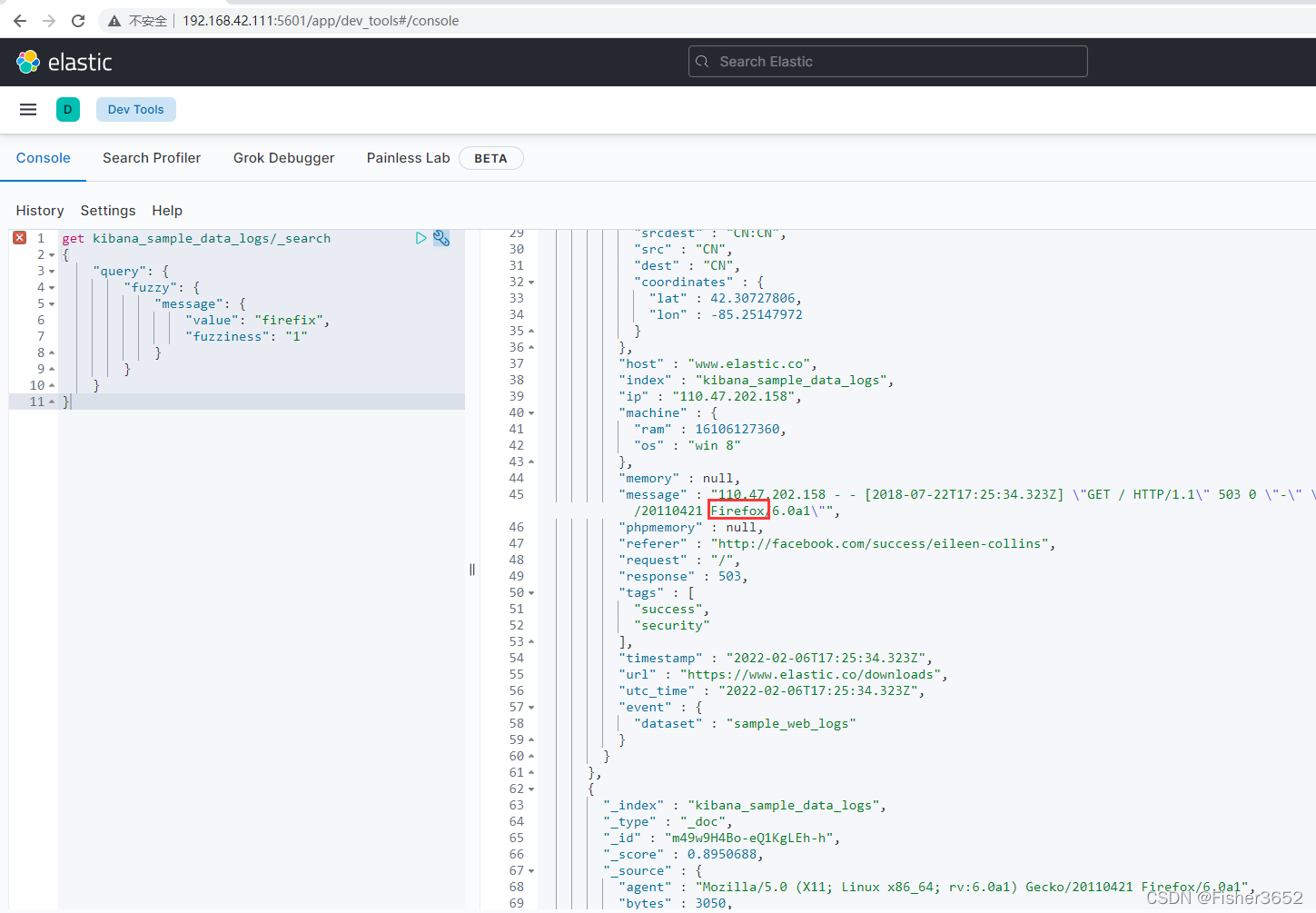
- 我们想找到文档中 message 字段包含 firefox,而查询条件中给出的是 firefix, 因为两者的编辑距离为 1,所以包含 firefox 的文档依然可以找到,但是,如果使 用 firefit,因为编辑距离为 2,则不会找到任何文档。
- 相关的参数有:
value,必填项,希望在 field 中找到的术语
fuzziness,选填项,匹配允许的最大编辑距离;可以被设置为“0”, “1”, “2”或“auto”。“auto”是推荐的选项,它会根据查询词的长度定义距离。
max_expansions,选填项,创建的最大变体项,默认为 50。应该避免使用较 大的值,尤其是当 prefix_length 参数值为 0 时,如果过多,会影响查找性能。
prefix_length,选填项,创建扩展时保留不变的开始字符数。默认为 0
transpositions,选填项,指示编辑是否包括两个相邻字符串的转置(ab→ba)。 默认为 true。
5.5.4 纠错与提示器
- 纠错是在用户提交了错误的词项时给出正确词项的提示,而输人提示则是在 用户输人关键字时给出智能提示,甚至可以将用户未输人完的内容自动补全。大 多数互联网搜索引擎都同时支持纠错和提示的功能,比如在用户提交了错误的搜 索关键字时会提示:“ 你是不是想查找…”.而在用户输人搜索关键字时还能自动 弹出提示框将用户可能要输人的内容全都列出来供用户选择。
- Elasticsearch 也同时支持纠错与提示功能,由于这两个功能从实现的角度来 说并没有本质区别,所以它们都由一种被称为提示器或建议器( Suggester)的特殊 检索实现。由于输人提示需要在用户输人的同时给出提示词,所以这种功能要求 速度必须快,否则就失去了提示的意义。在实现上,输人提示是由单独的提示器 完成。而在使用上,提示器则是通过检索接口_ search 的一个参数设置,例如:
POST /kibana_sample_data_logs/_search?filter_path=suggest
{
"suggest": {
"msg-suggest": {
"text": "firefit chrom",
"term": {
"field": "message"
}
}
}
}
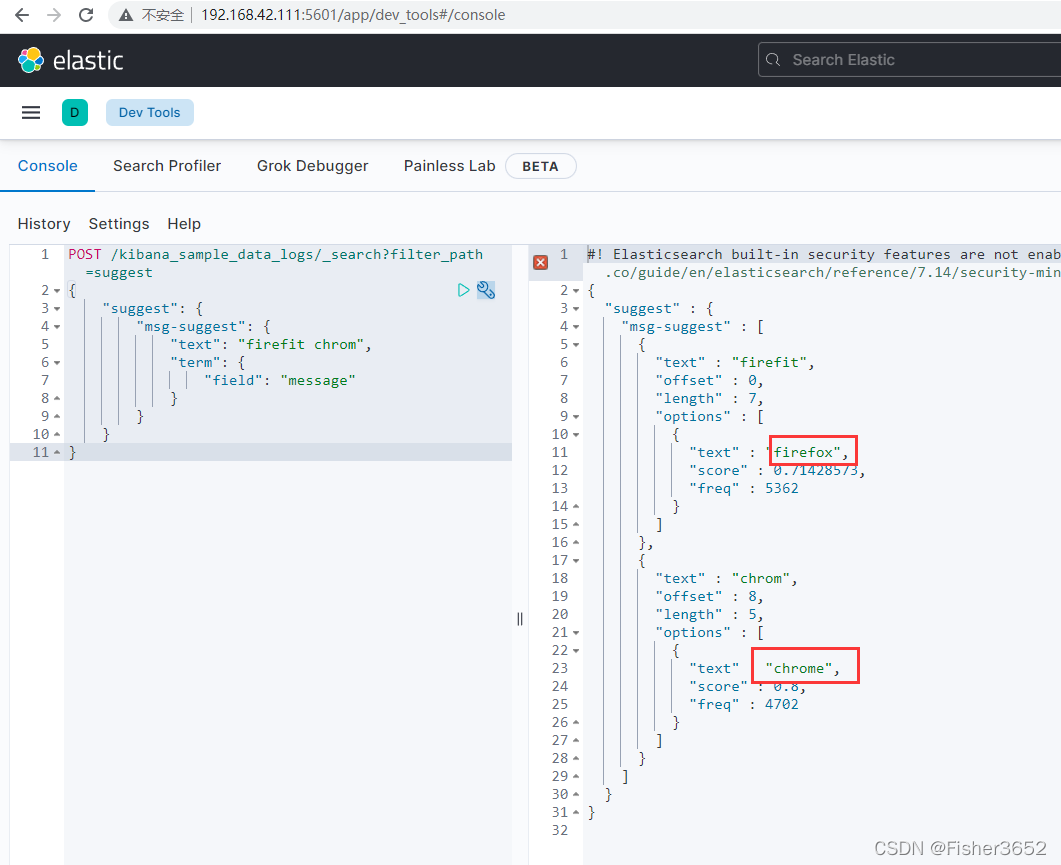
- 在示例中,search 接口的 suggest 参数中定义了一个提示 msg- suggest,并通 过 text 参数给出需要提示的内容。另一个参数 term 实际上是一种提示器的名称, 它会分析 text 参数中的字符串并提取词项,再根据 Levenshtein 算法找到满足编 辑距离的提示词项。所以在返回结果中会包含一个 suguggest 字段,其中列举了 依照 term 提示器找到的提示词项
- Elaticearch 提供了三种提示器,它们在本质上都是基于编辑距离算法。下面 就来看看这此提示器如何使用。
5.5.4.1 term 提示器
- 在示例中使用的提示器就是 term 提示器,这种提示器默认使用的算法是称 为 internal 的编辑距离算法。intermal 算法本质上就是 Levenshtein 算法,但根 据 Elasticsearch 索引特征做了一些优化而效率更高,可以通过 string _distance 参 数更改算法。
- term 提示器使用的编辑距离可通过 max_ edits 参数设置,默认值为 2。
5.5.4.2 phrase 提示器
- terms 会将需要提示的文本拆分成词项,然后对每一个词项做单独的提示, 而 phrase 提示器则会使用整个文本内容做提示。所以在 phrase 提示器的返回结 果中,不会看到一个词项一个词项的提示,而是针对整个短语的提示。但从使用 的角度来看几乎是一样的,例如:
POST /kibana_sample_data_logs/_search
{
"suggest": {
"msg-suggest": {
"text": "firefix with chrime",
"phrase": {
"field": "message"
}
}
}
}
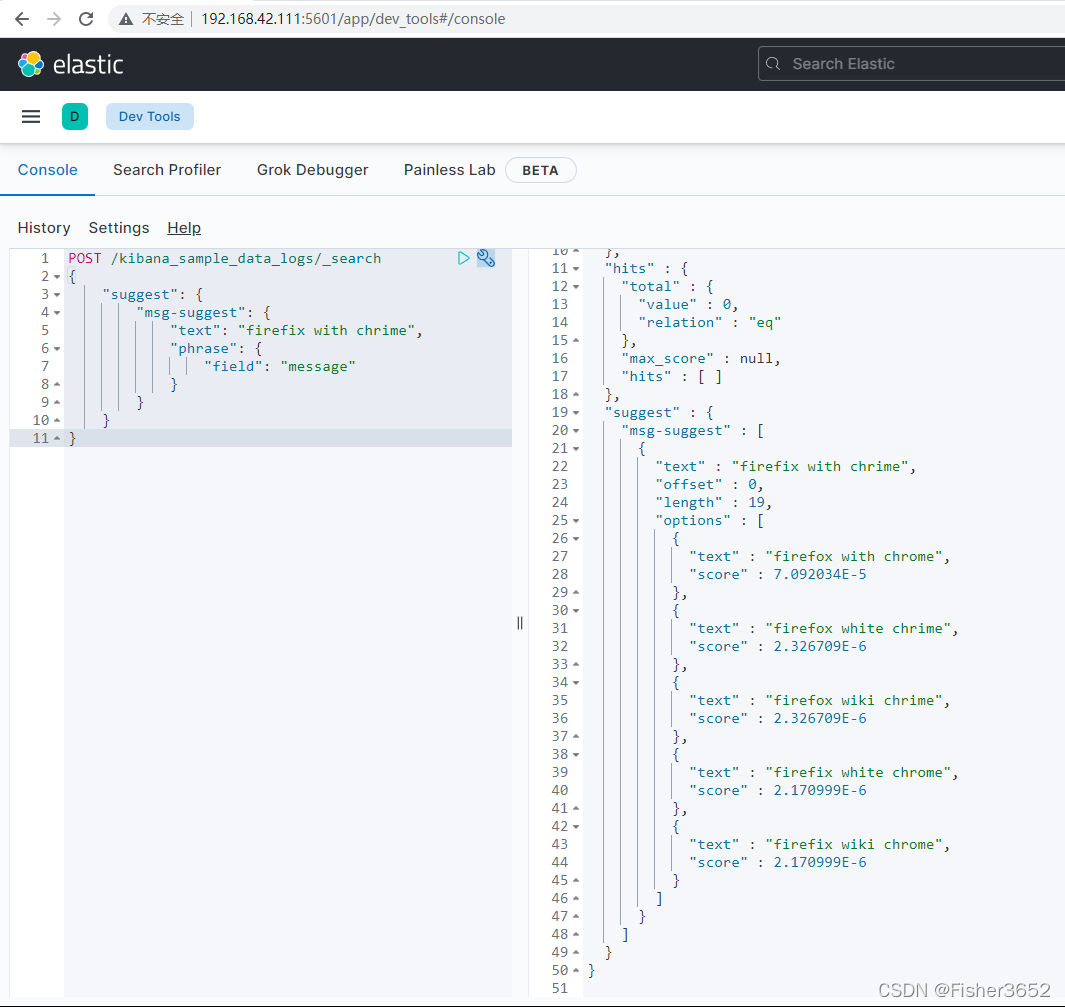
- 但不要被 phrase 提示器返回结果欺骗,这个提示器在执行时也会对需要提 示的文本内容做词项分析,然后再通过 NGram 算法计算整个短语的编辑距离。 所以本质上来说,phrase 提示是基于 term 提示器的提示器,同时使用了 Levenshtein 和 NGram 算法。
5.5.4.3 completion 提示器
- completion 提示器一般应用于输人提示和自动补全,也就是在用户输人的同 时给出提示或补全未输入内容。这就要求 completion 提示器必须在用户输人结 束前快速地给出提示,所以这个提示器在性能上做了优化以达到快速检索的目的。
- 首先要求提示词产生的字段为 completion 类型,这是一种专门为 completion 提示器而设计的字段类型,它会在内存中创建特殊的数据结构以满足快速生成提 示词的要求。例如在示例中创建了 aricles 索引,并向其中添加了 1 份文档
PUT articles
{
"mappings": {
"properties": {
"author": {
"type": "keyword"
},
"content": {
"type": "text"
},
"suggestions": {
"type": "completion"
}
}
}
}
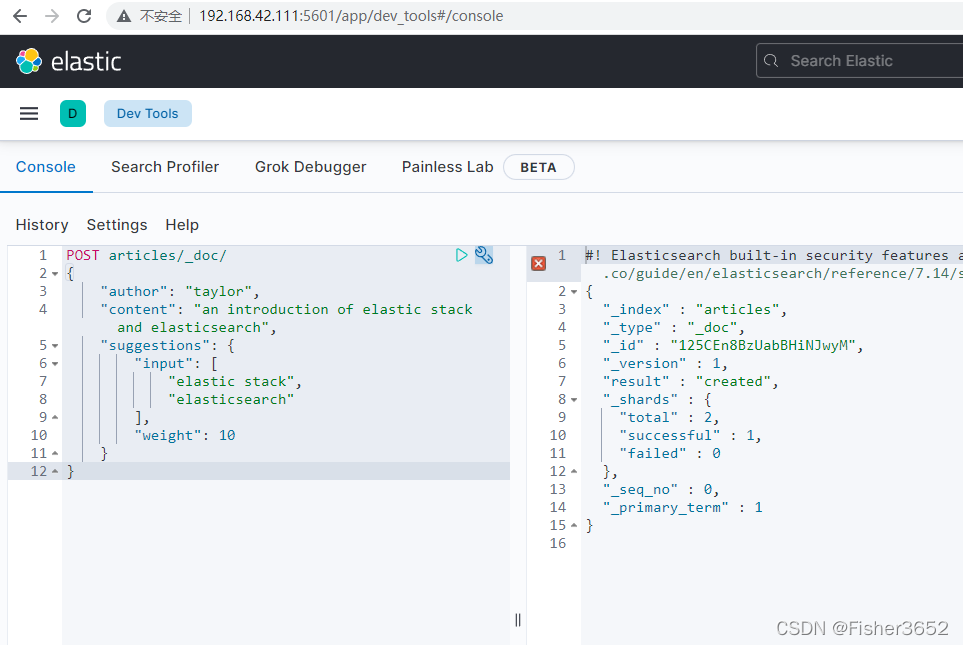
POST articles/_doc/
{
"author": "taylor",
"content": "an introduction of elastic stack and elasticsearch",
"suggestions": {
"input": [
"elastic stack",
"elasticsearch"
],
"weight": 10
}
}
- 或者
POST articles/_doc/
{
"author": "taylor",
"content": "an introduction of elastic stack and elasticsearch",
"suggestions": [
{
"input": "elasticsearch",
"weight": 30
},
{
"input": "elastic stack",
"weight": 1
}
]
}
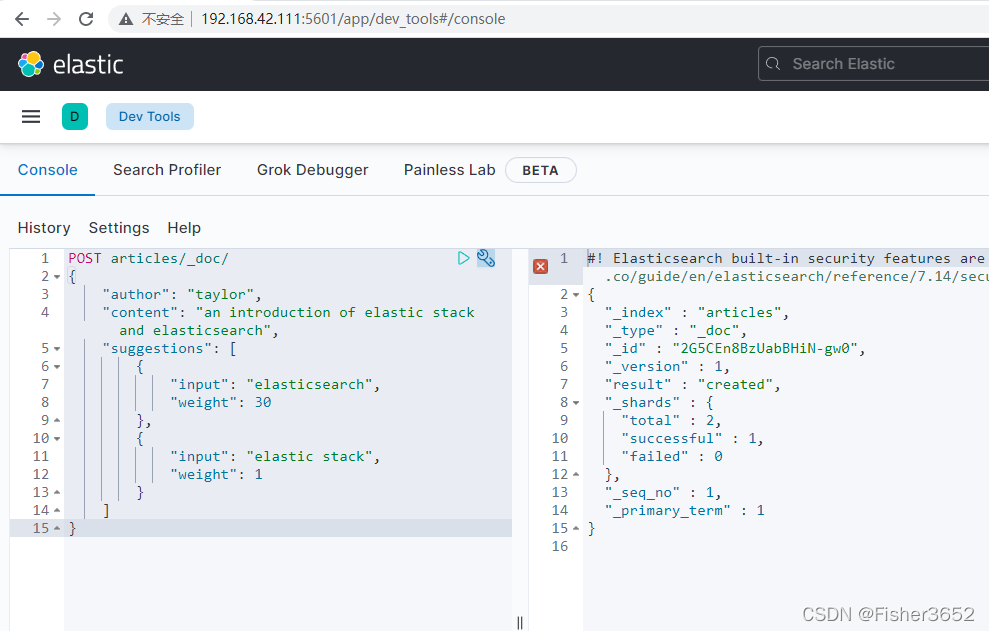
- 在向 completion 类型的字段添加内容时可以使用两个参数,input 参数设置 字段实际保存的提示词;而 weight 参数则设置了这些提示词的权重,权重越高它 在返回的提示词中越靠前。在示例中给出了两种设置提示词权重的方式, 第一种是将一组提示词的权重设置为统一值,另一种则是分开设置它们的权重值。
- 需要注意的是,completion 类型字段保存的提示词是不会分析词项的,比如示例中的“elastic stack”并不会拆分成两个提示词,而是以整体出现在提示词列表中。
- completion 提示器专门用于输人提示或补全,它根据用户已经输人的内容提 示完整词项,所以在 completion 提示器中没有 text 参数而是使用 prefix 参数。例如:
POST articles/_search
{
"_source": "suggest",
"suggest": {
"article_suggestion": {
"prefix": "ela",
"completion": {
"field": "suggestions"
}
}
}
}
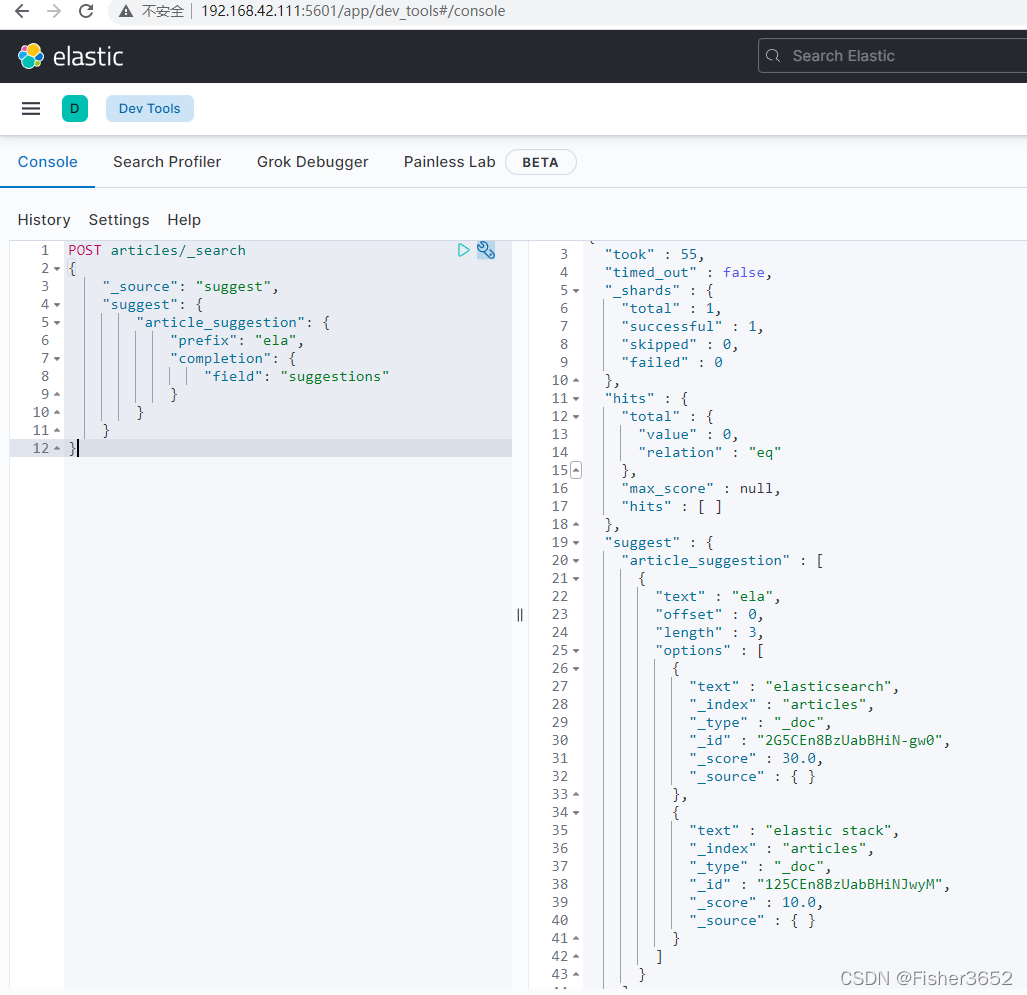
- 总结一下,term 和 phrase 提示器主要用于纠错,term 提示器用于对单个词 项的纠错而 phrase 提示器则主要针对短语做纠错。completion 提示器是专门用于输入提示和自动补全的提示器,在使用上依赖前缀产生提示并且速度更快。















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









