







(0)摘要
# 课程链接
4天搞定django rest framework源码和实战_哔哩哔哩_bilibili
# 课程内容
(1)rest framework框架之版本使用
(2)rest framework框架之版本源码
(3)rest framework框架之解析器前戏
(4)rest framework框架之解析器流程分析
(5)rest framework框架之解析器源码
(6)rest framework框架之序列化基本使用
(7)rest framework框架之序列化自定义字段
【补充知识】
# 道阻且长,行则将至
今日概要及知识点的重要等级/内容概要
# 直接上图
# 内容回顾
【主要看补充知识~~~】
(1)rest framework框架之版本使用
# (1)版本使用
1)这里涉及到路由分发的知识,如下图所示,我们新建了一个 app 程序 api,然后路由分发到 api 下的 urls 文件。
2)然后在 api 程序下的 urls 中,我们写的一个接口如下所示。
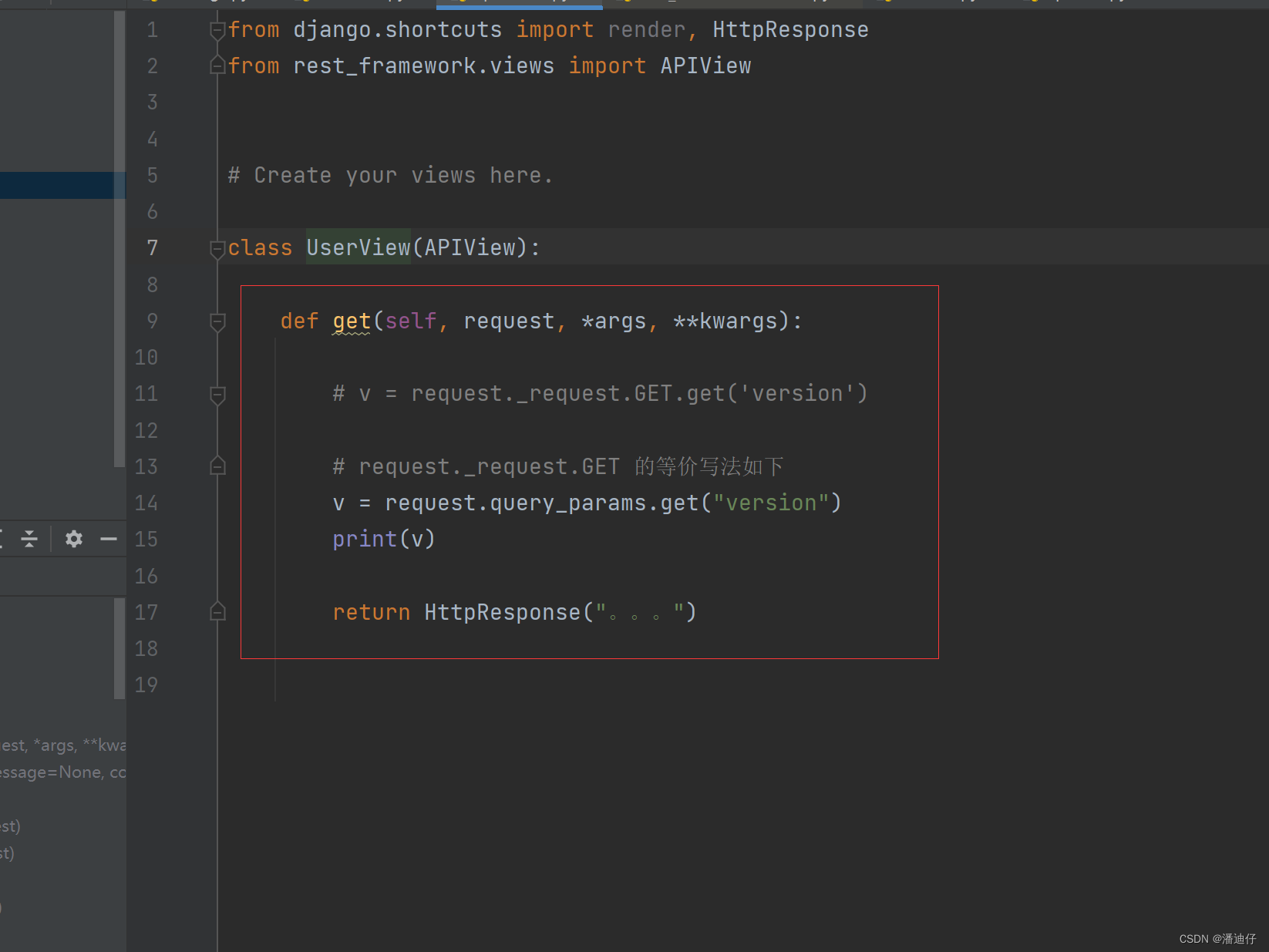
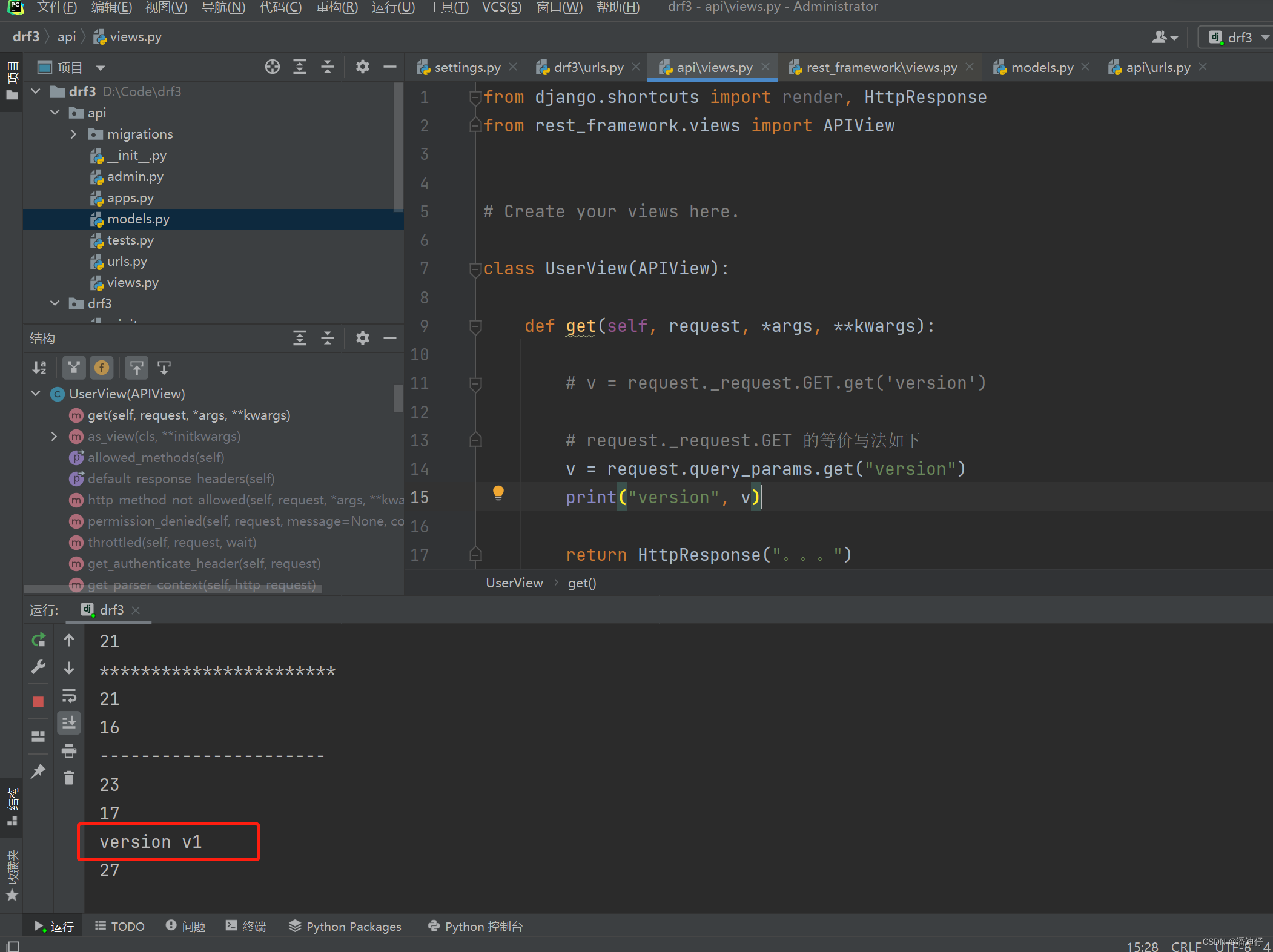
3)那么相应接口的视图类如下,由图中可以看到,我们不再用以往的 request._request.GET 来取前台的传参了。而是使用 request.query_params.get() 来取。query_params 方法是封装的 request 提供的方法。
4)如果此时,我们发一个 get 请求,请求的 url 为http://127.0.0.1:8000/api/users/?version=v1 ,这样就可以取的版本的信息了。如下图所示。(尤其要注意的是,我们传参务必填一个 ? 号)
# (2)内置的版本使用
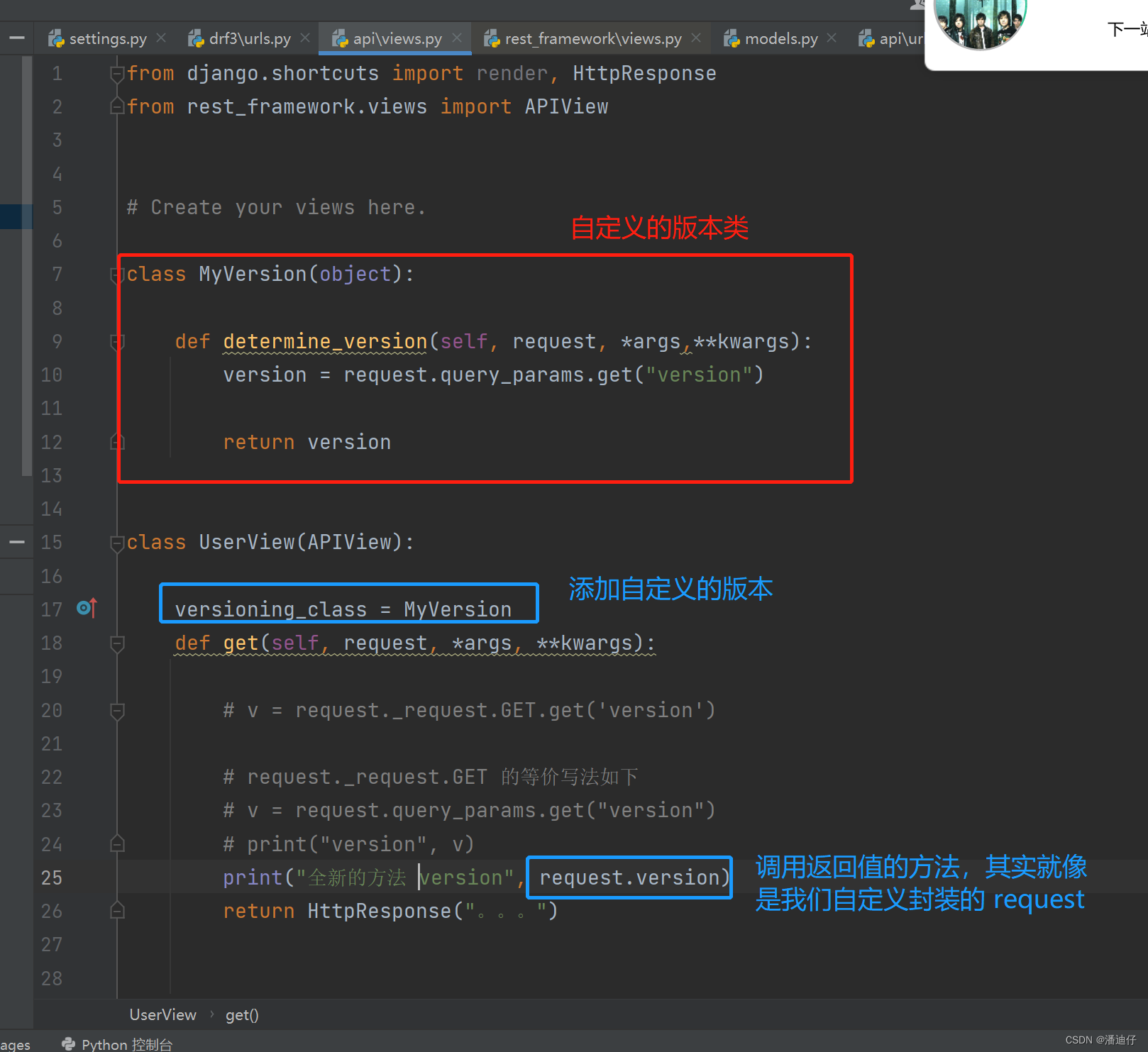
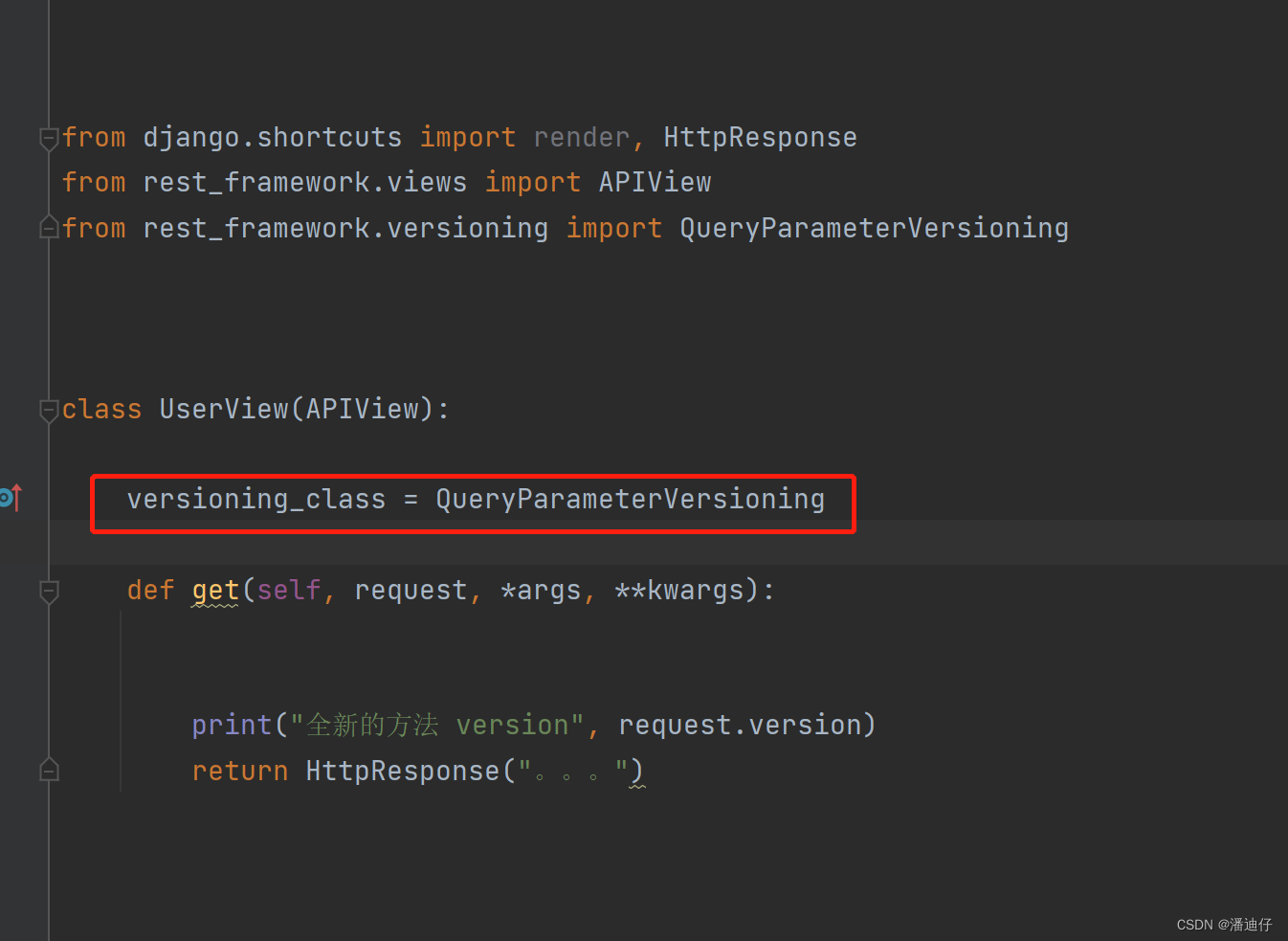
1)事实上,drf 本身也带有版本的使用方法。具体是使用内置 versioning_class ,虽然这个流程的定义和前面的相似,但是它不是一个列表。而前面的大多是内置的列表类。我们可以看如下的代码。
2)事实上我们不需要自己写自定义的版本类,可以直接使用内置的,比如 QueryParameterVersioning ,使用方法就是 from rest_framework.versioning import QueryParameterVersioning ,然后赋值给 versioning_class 即可,如下图的代码所示。
# (3)内置版本类 QueryParameterVersioning 的源码
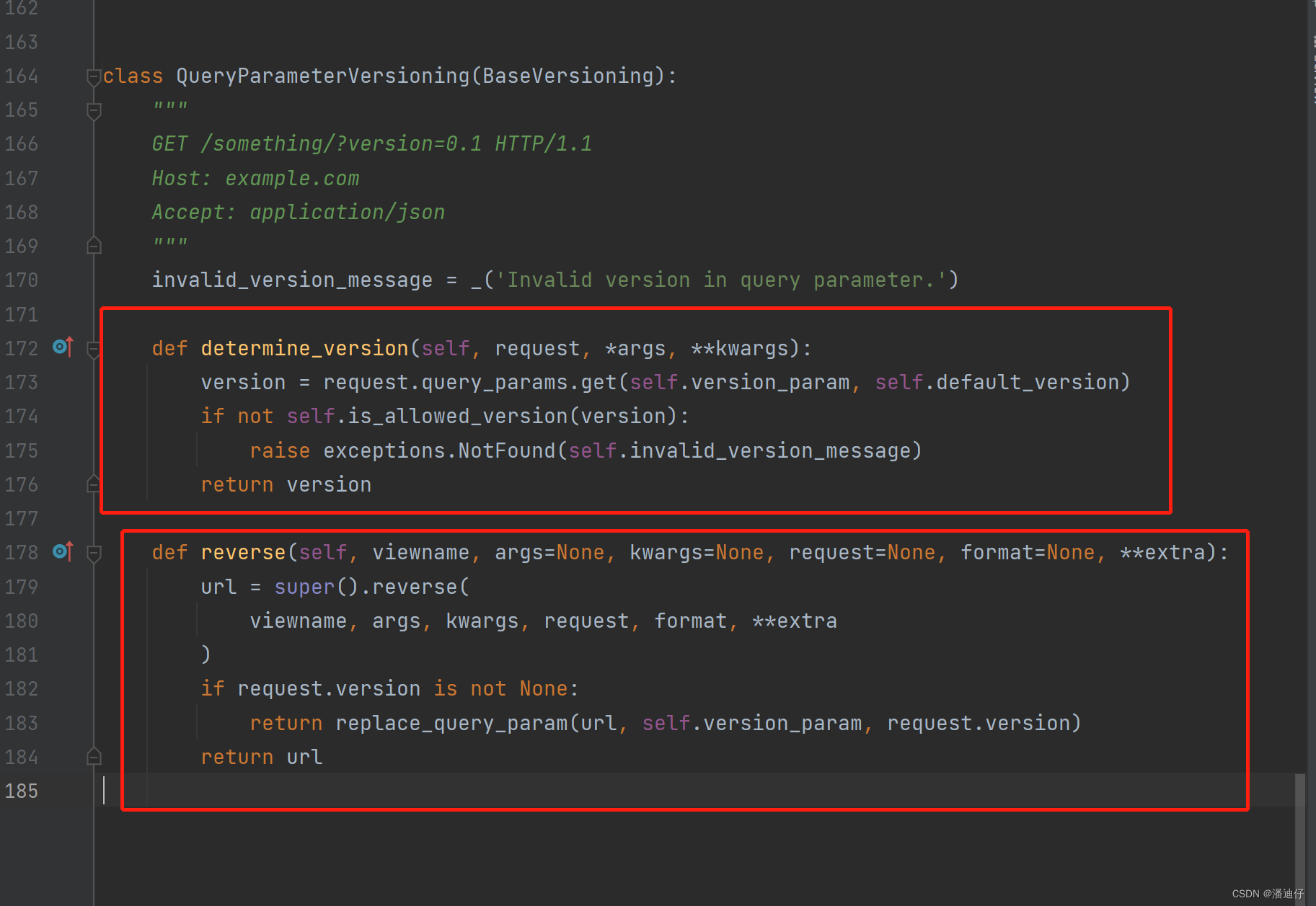
1)QueryParameterVersioning 的源码详情如下。在 determine_version() 方法中,我们主要关注 self.version_param,self.default_version ,self.is_allow_version() 即可。前两个其实是放在配置文件中的,思路其实就是取版本参数,否则就取默认的。后面的是一个方法,其实就是配置准许的版本,具体看下面的源码讲解。这里尤其说一下 self.version_param 这个参数的配置就是 VERSION_PARAM,这个是传参的键等于什么。也就是说,如果我们设置的是 token_version ,那么传参的格式必须是这样的,http://127.0.0.1:8000/api/users/?token_version=v1 ,也就是键为 token_version 。
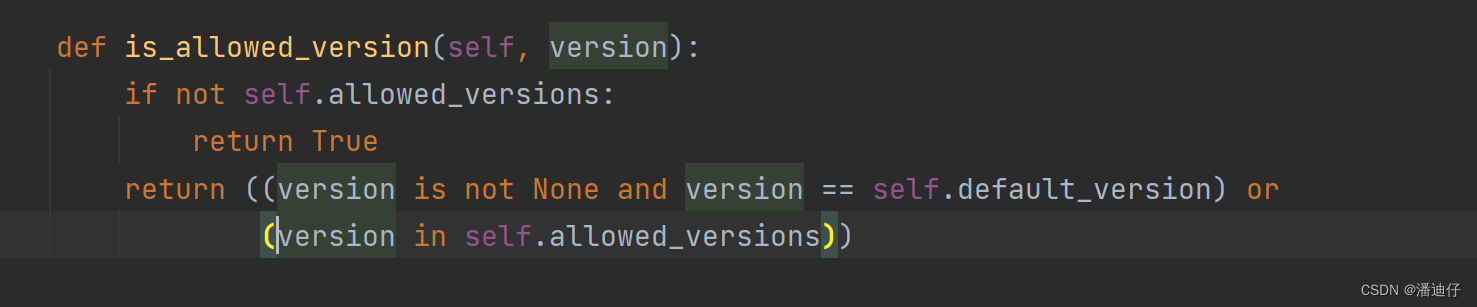
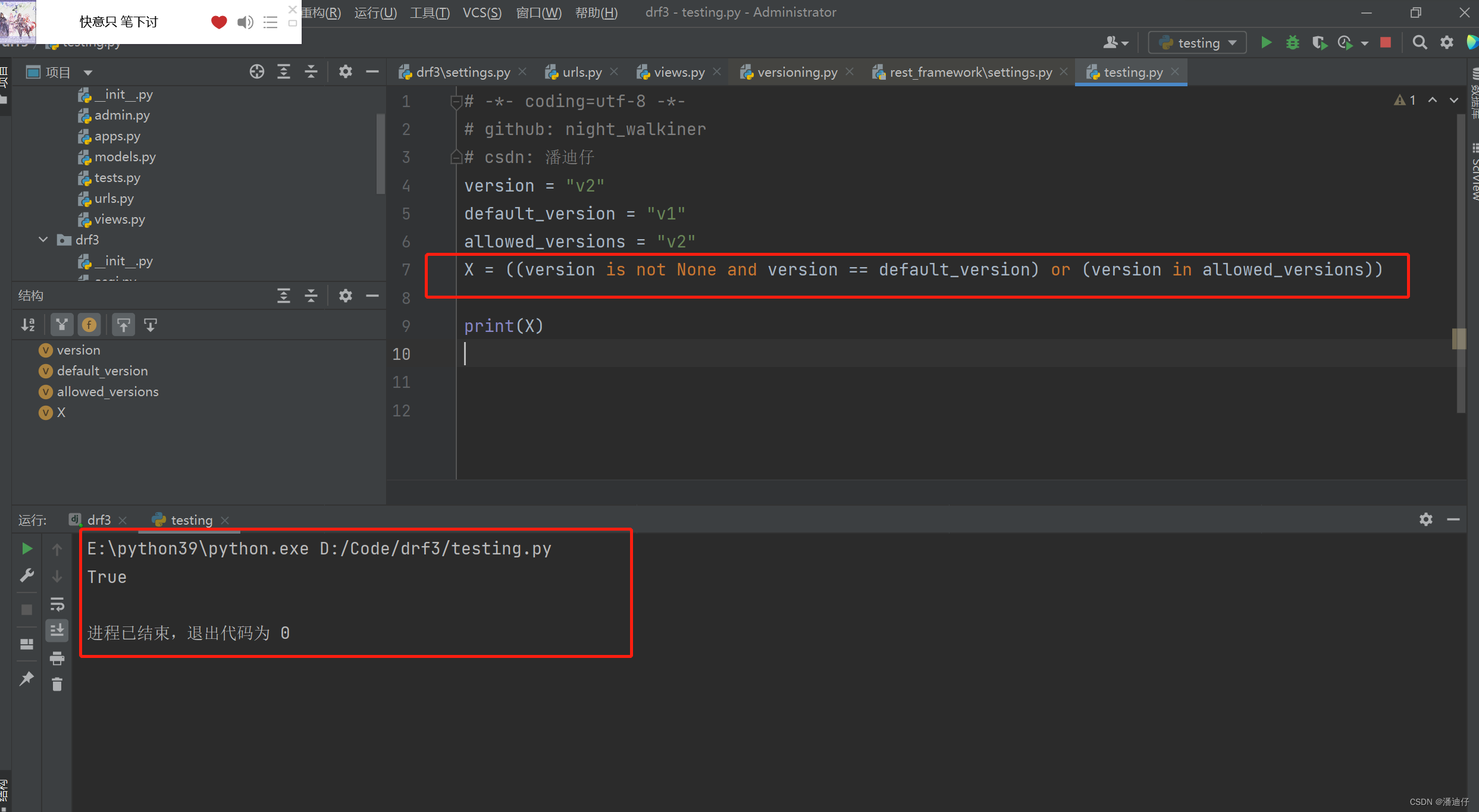
self.is_allow_version() 的源码如下,这里的 self.allowed_versions 就是配置版本控制的,和上述的两个都一样在配置文件中。那么具体的控制思路其实就是,如果没有配置版本控制,那么就直接返回 True。否则就是配置了版本,然后判断获得的 version 是不是在默认版本(默认的版本,只要不是 None 那么返回一定是 True,即是允许的),or 右边就是 判断 version 是不是在 self.allowed_versions 中,由此我们也可以看出,self.allowed_version 是一个列表。
return 的语句可以参考这里,返回值就是 True 或者 False。
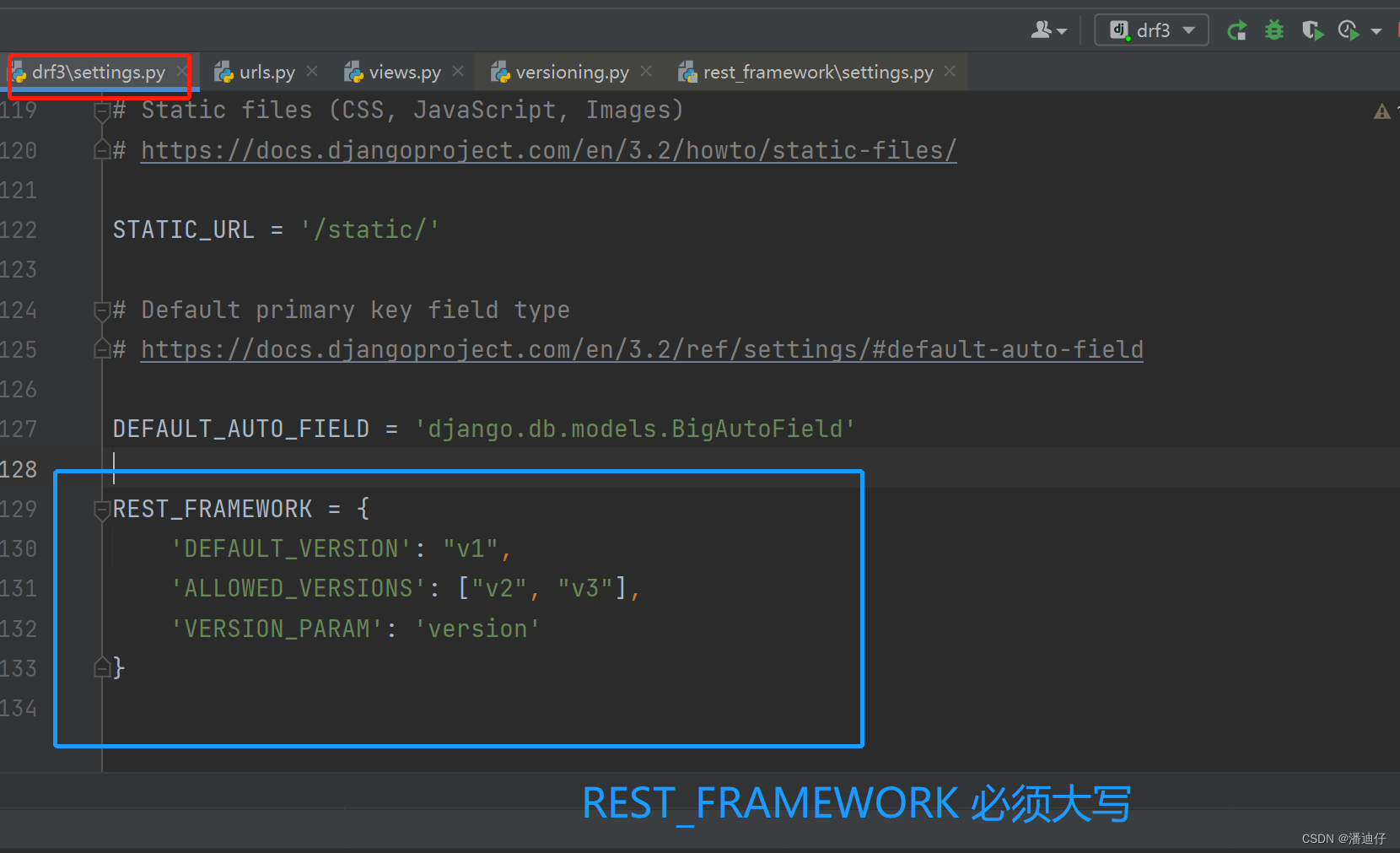
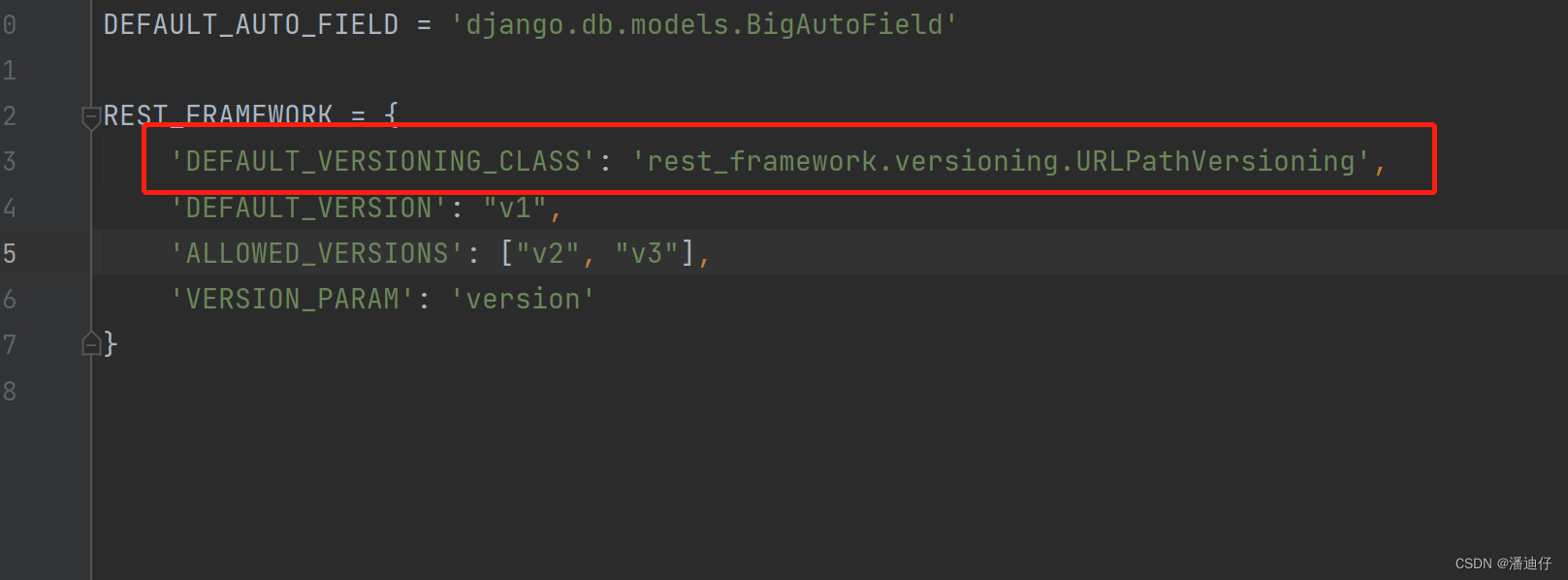
2)全局配置。其实也是在 settings.py 下设置 rest_framework 值。如下所示
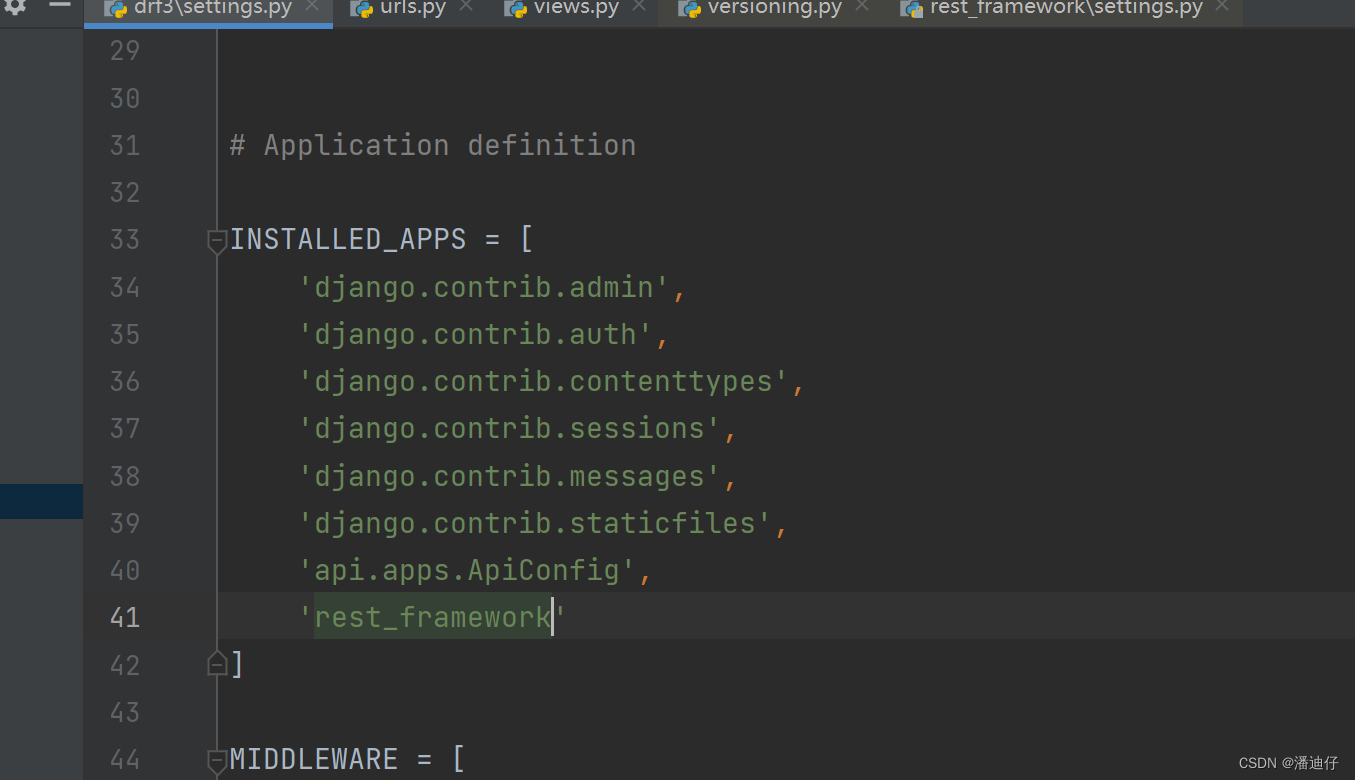
3)然后我们超出了允许的版本,页面就会报错,那么我们在 settings.py 中的 INSTALLED_APPS 加入一个渲染器 'rest_framework' 就可以看到返回的错误信息。
错误信息的渲染界面
# (4)URL 的传参问题(URLPathVersioning 方法类)
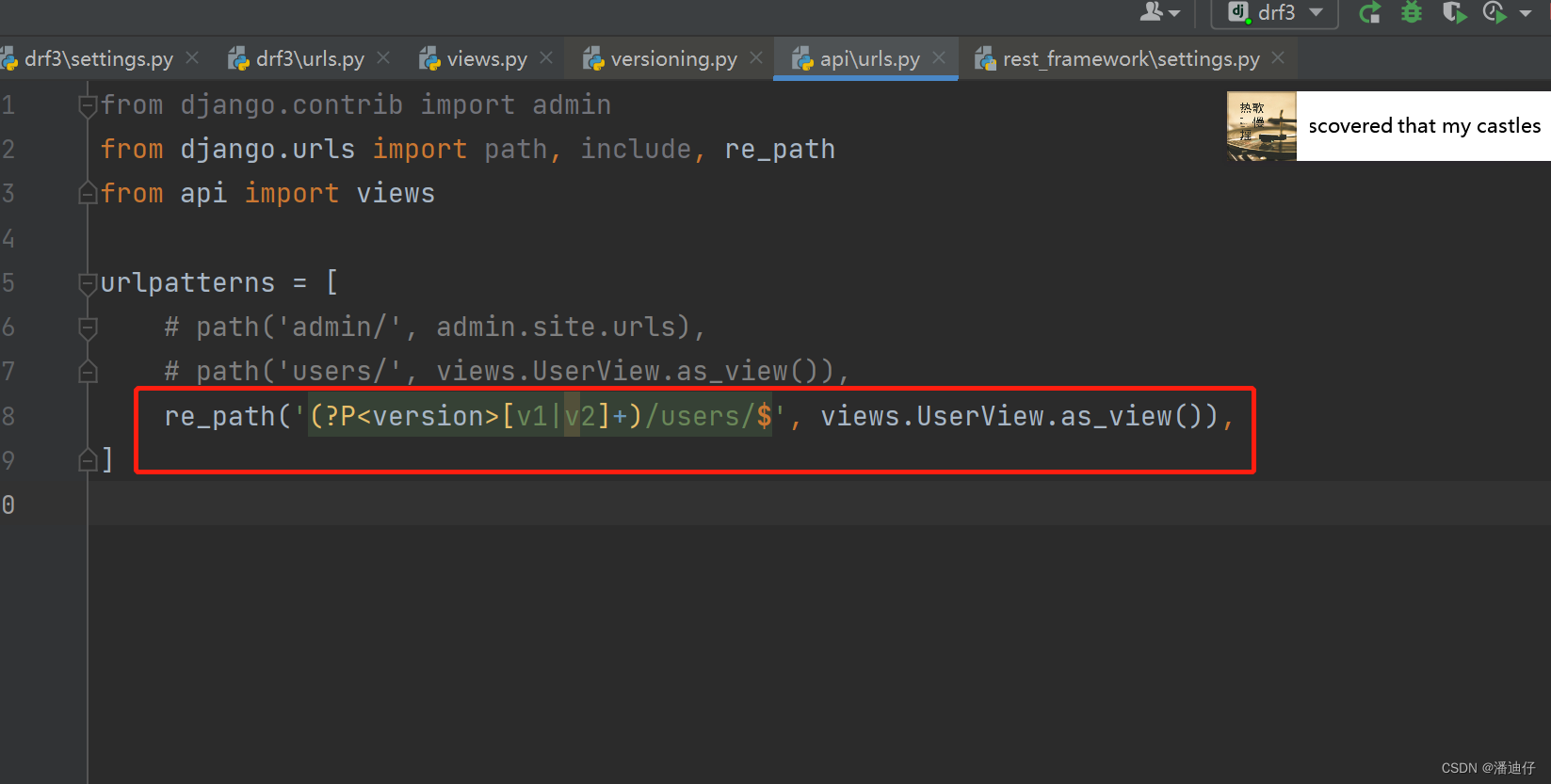
1)然而事实上,我们一般不会使用上述的传参方法,也就是原来是下面的这个url 的传参 http://127.0.0.1:8000/api/users/?version=v22 ,而现在更多的是直接使用 http://127.0.0.1:8000/api/users/v22 即不写传参键的方式。drf 也为我们写了相应的方法类了,即 URLPathVersioning 方法类。导入方法也是 from rest_framework.versioning import URLPathVersioning 。那么具体如下,其实也就是说,使用正则表达式的方式来传递参数。那其实就跟我们之前的取值方法一样,比如 re_path('edit/(?P<v1>\w+)/',views.edit) 是一样的,那么传参的时候,其实就是在 **kwargs 下取值。【这也是推荐的写法】
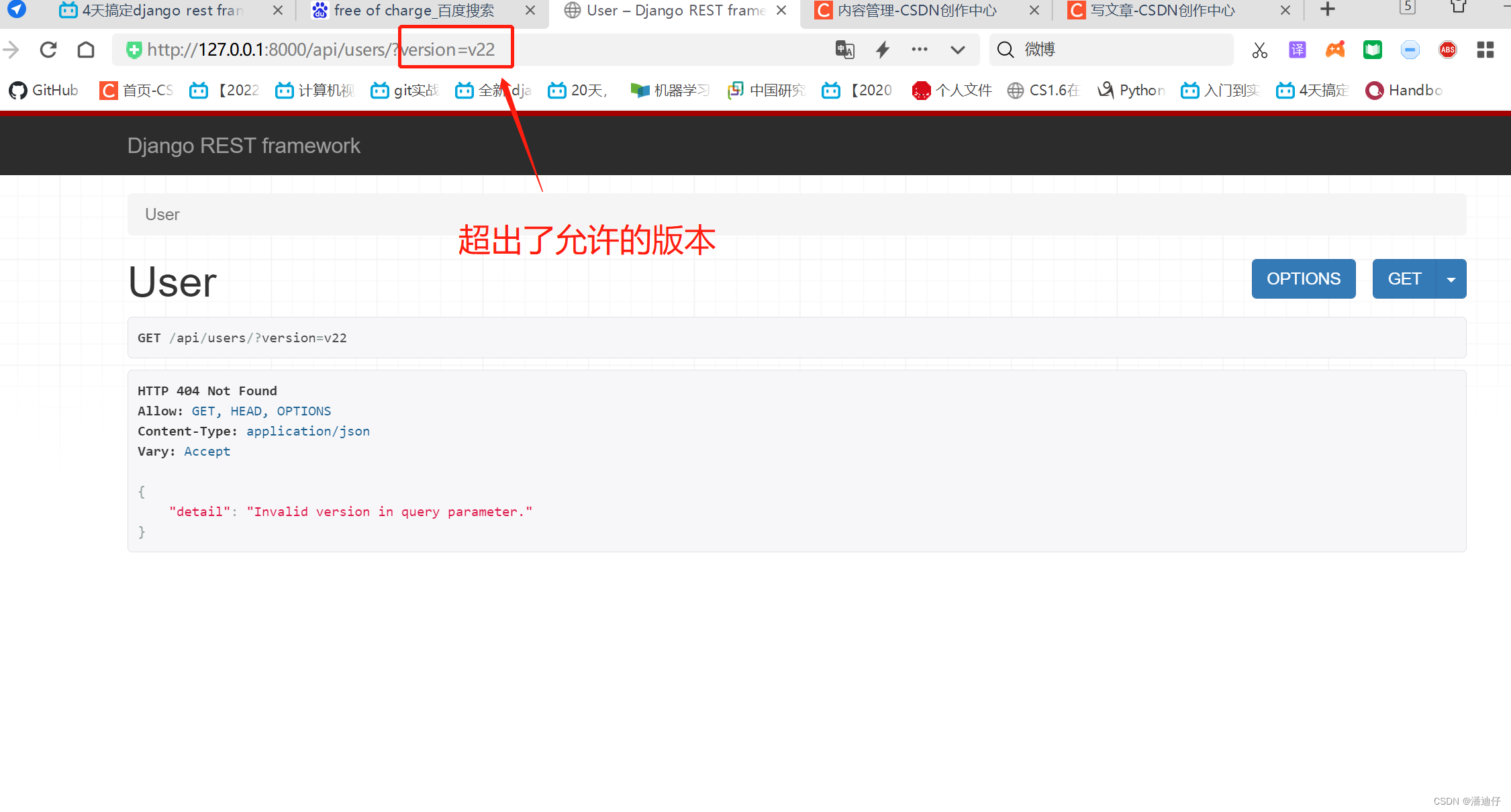
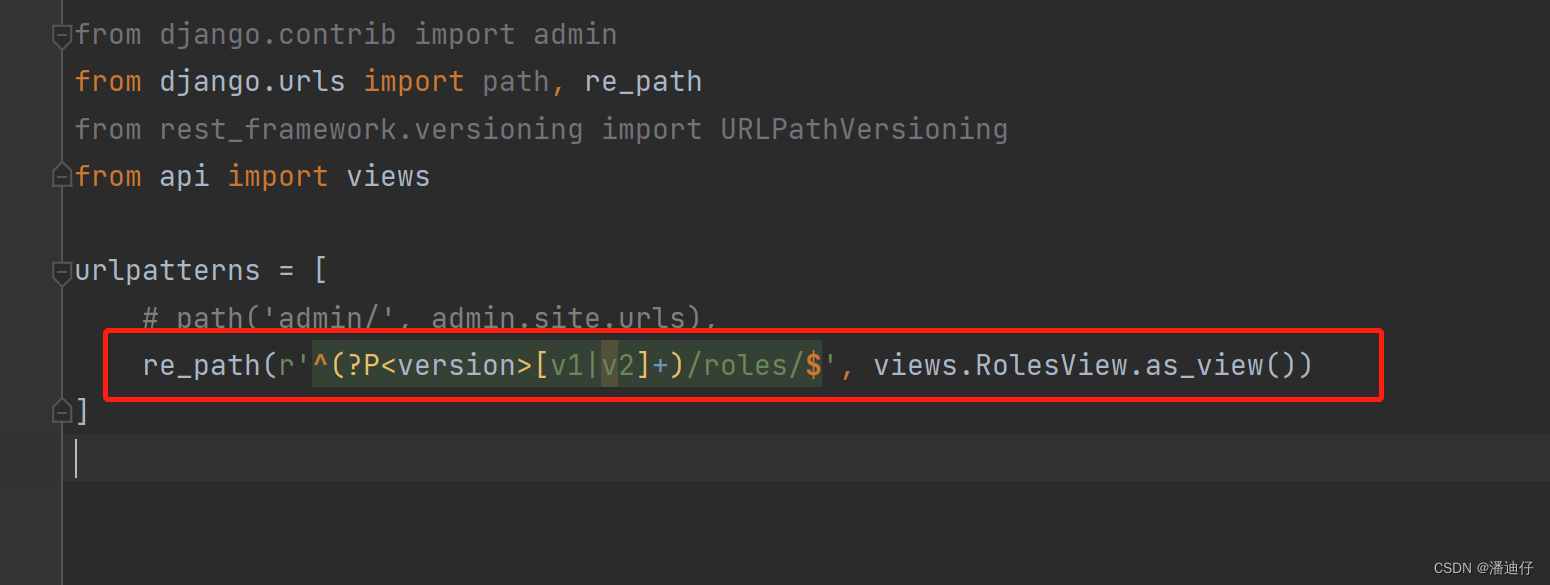
2)然后我们可以测试一下,我们在 api 程序下配置了一个新的 url ,配置好了,就可以试试访问了。显示是成功的。如下图所示。要说明的是,[v1|v2] 其实就是准许请求的版本了,相当于一个初级筛查,如果我们使用了 v3,如这个 url 所示 http://127.0.0.1:8000/api/v3/users/ ,那么就会报错,说找不到路径。
3)那么今后我们可以直接配置这个 URLPathVersioning 方法类作为全局配置,具体的也是在 settings.py 下配置,那这样子就可以不用在各自视图类中配置了。具体的如下所示。
# (5)全局配置的一个大坑---笔者亲历



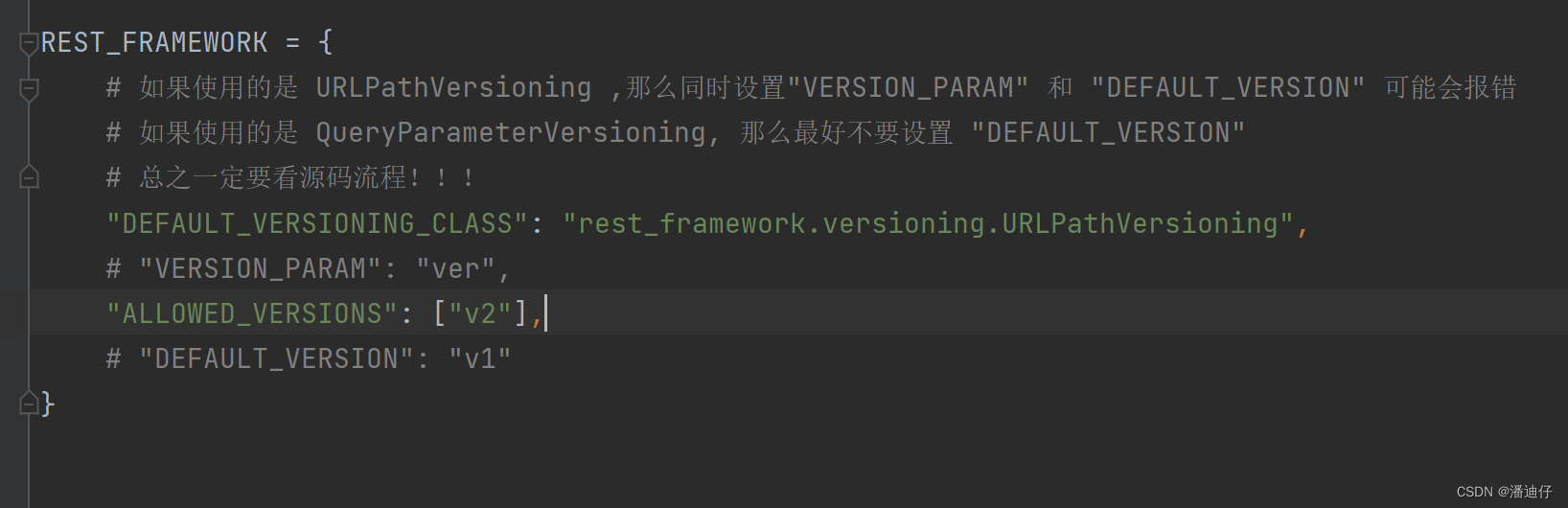
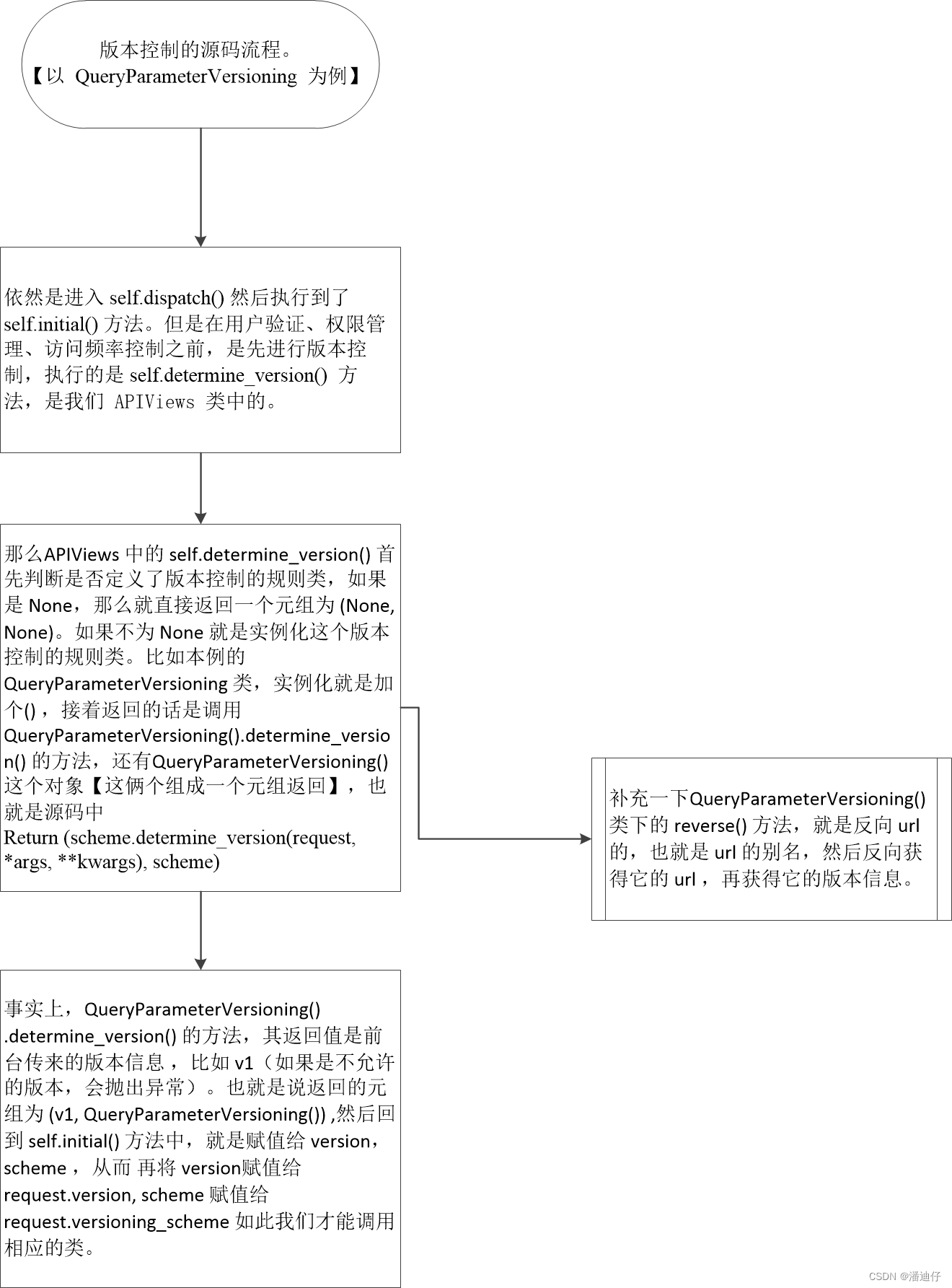
(2)rest framework框架之版本源码 流程
# (1)源码的流程图,如下所示
(3)rest framework框架之解析器前戏
# (1)略
#
(4)rest framework框架之解析器流程分析
# (1)drf 的解析器初识_上
1)解析器简单理解就是解析前台发送的数据的格式。比如我们前台发送 json 格式的数据,后台就要使用相应的解析器来解析 json 数据(显然是 post 请求)。具体的使用的流程的话,我们直接给代码。首先是创建一个新的 urls。如下图所示
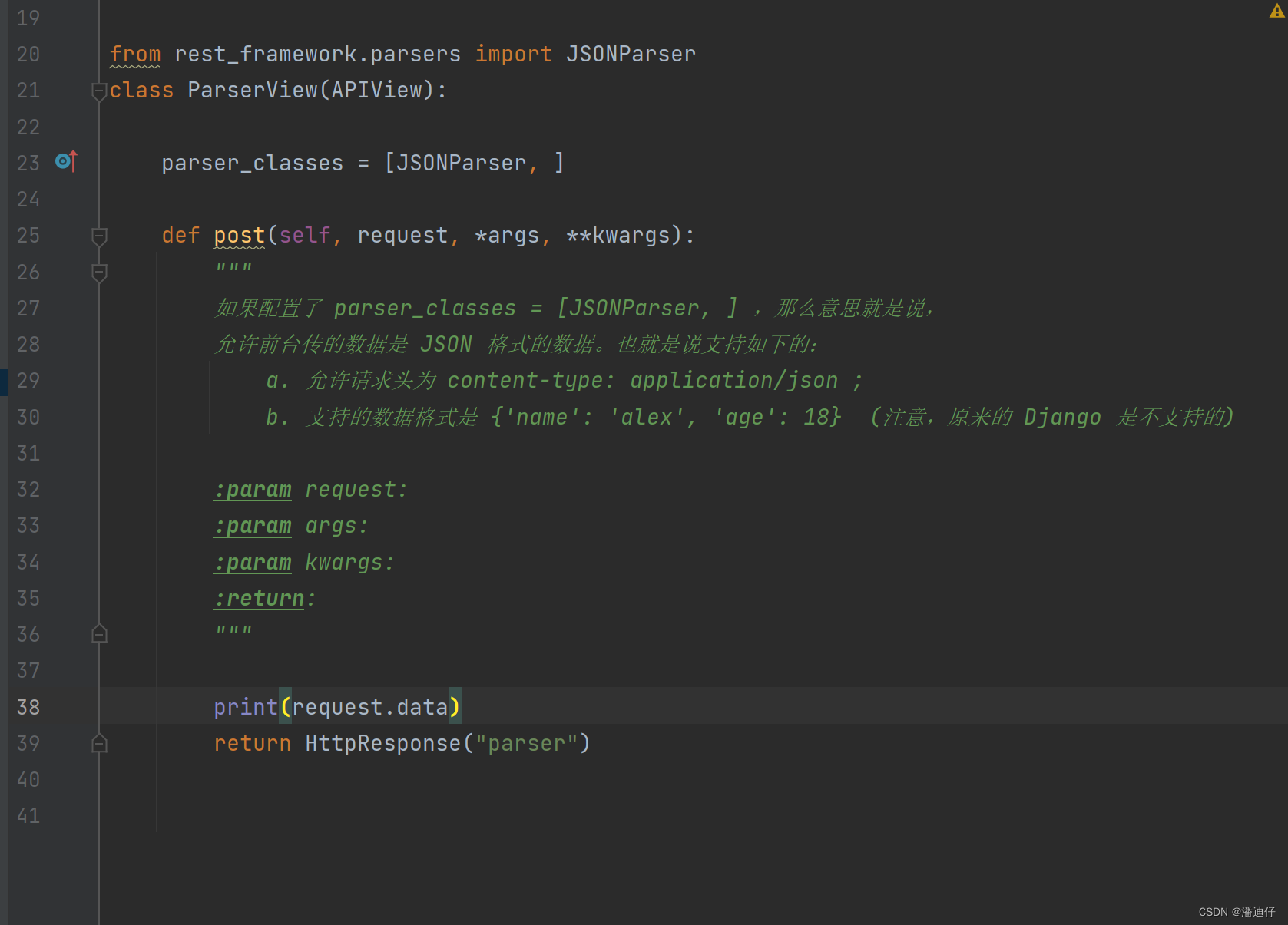
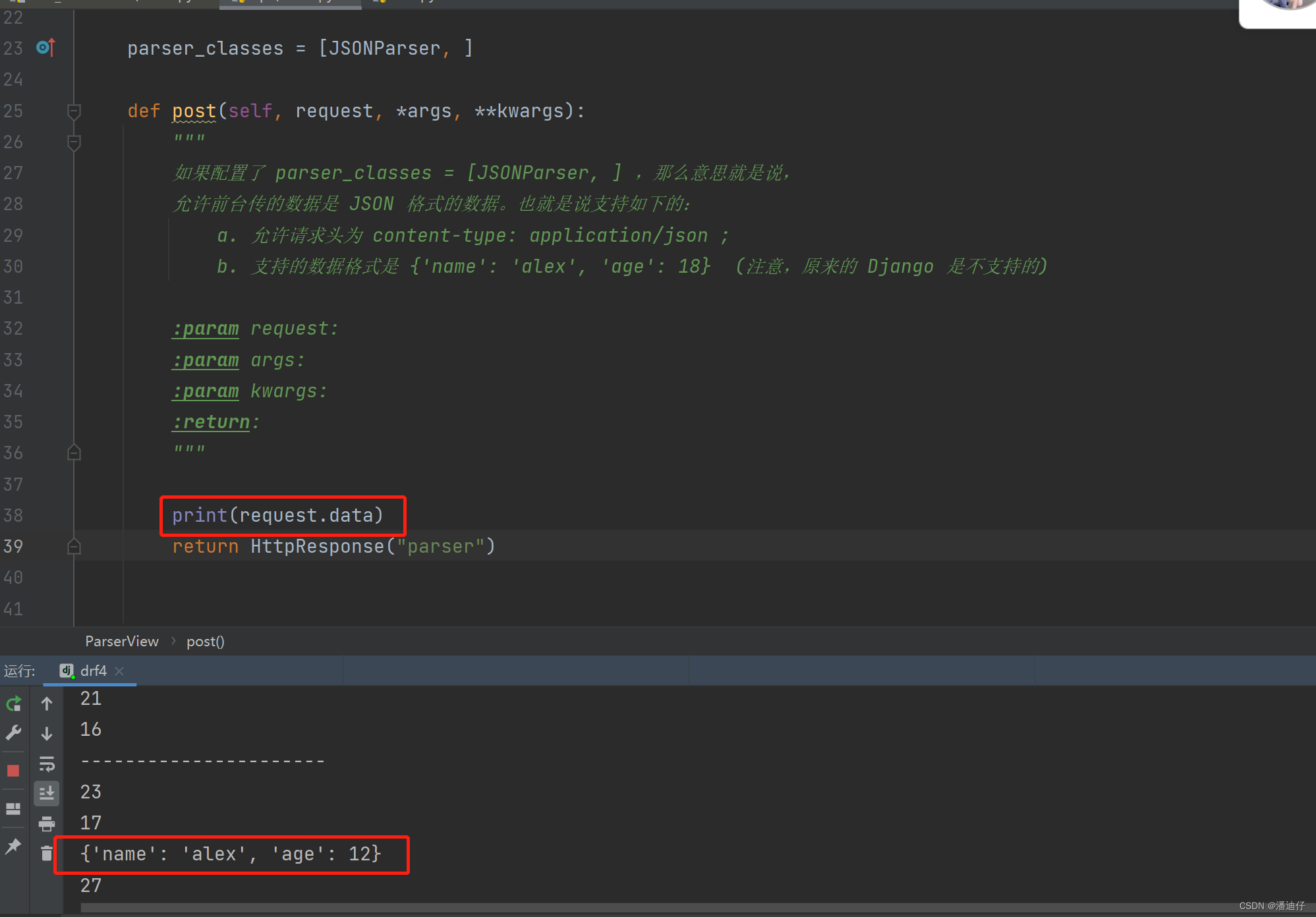
2)ParserView 视图类的定义。如下图所示,在 drf 中设置解析器的话,就是要使用到解析器类列表,那么就是 parser_classes = [] ,可以是多个解析器,比如我们使用的是解析 json 数据,就需要引入 JSONParser 一个内置的 json 解析器。导入方法如图所示。其实整个流程与之前差不多,但是我们要取前台数据的时候,就要使用 request.data 来取了。
3)使用 postman 来验证。具体流程如下,顺序是红、蓝、黄。
4)那么我们测试的结果如下,显然是 json 格式的数据。
# (2)drf 的解析器初识_下
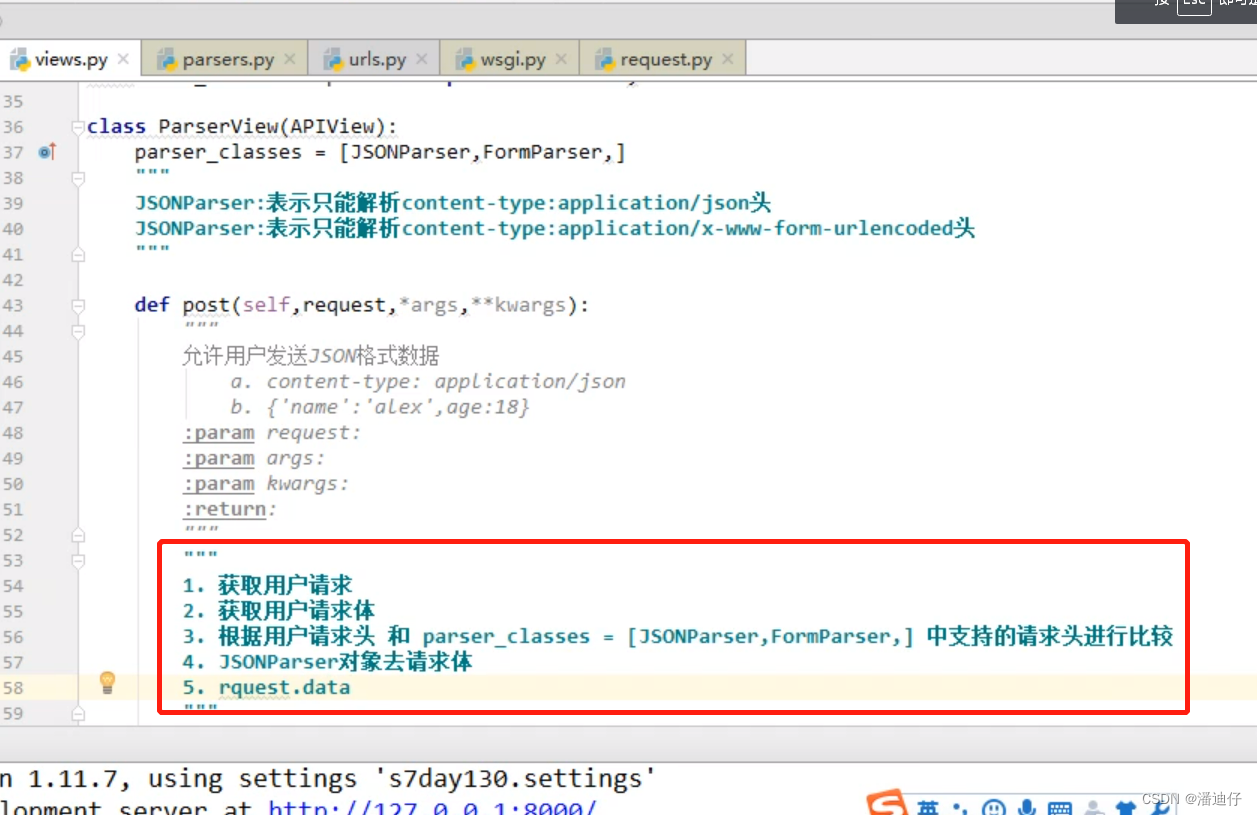
1)除了 json 格式的数据,我们也是支持 x-www-form-urlencoded 类型的请求数据。那么具体使用的话,就是 FormParser 类,具体配置也是和上面的 JSONParser 相似的。但是这里我们讲二者联用,也就是说,支持传来的数据请求头是 json 或者 x-www-form-urlencoded 二者的,那么配置的代码如下。
2)那么我们使用 x-www-form-urlencoded 类型来测试一下。
3)结果如下所示。
# (3)调用问题
如下图所示。事实上, request.data 才是解析器执行的开关。也就是说,即使我们定义了解析器的 parser_classes 列表,但是没有使用 request.data ,那么解析器是不会执行的。解析器首先会将请求体的类型进行分析,比如 JSONParser 就是比较请求头的数据是不是 json 类型,如果是才会执行相应的 parser 方法。
request.data 中其实就是如下的步骤。详情见后面的源码分析






(5)rest framework框架之解析器源码
# (1)源码流程_直接上代码吧
1)直接是 request.data 的流程啦。当然是在 drf 封装 request 的里使用的 Request 类中了。总的流程如下:
2)_hasattr(self, '_full_data') 的用法介绍。
当然了,_hasattr() 方法,我们的具体测试如下:
3)然后是 self._load_data_and_files() 方法,其实就是如下的一个流程,随便看看就行,知道走个什么流程。
这里又出来了一个 self._parse() 方法。这里直接看注释即可。
def _parse(self): """ Parse the request content, returning a two-tuple of (data, files) May raise an `UnsupportedMediaType`, or `ParseError` exception. """ # 获取的是请求头的解析格式类型,比如 application/json media_type = self.content_type # 其实就是获取 self.stream 相当于是请求体的二进制流,源码是写在内存中的。 try: stream = self.stream except RawPostDataException: if not hasattr(self._request, '_post'): raise # If request.POST has been accessed in middleware, and a method='POST' # request was made with 'multipart/form-data', then the request stream # will already have been exhausted. if self._supports_form_parsing(): return (self._request.POST, self._request.FILES) stream = None # 如果请求体是 None 或则 请求的格式是 None,那么直接返回空元组就好了 if stream is None or media_type is None: if media_type and is_form_media_type(media_type): empty_data = QueryDict('', encoding=self._request._encoding) else: empty_data = {} empty_files = MultiValueDict() return (empty_data, empty_files) parser = self.negotiator.select_parser(self, self.parsers) # 没定义解析器的话,就抛出异常 if not parser: raise exceptions.UnsupportedMediaType(media_type) try: # 调用解析器的方法 parsed = parser.parse(stream, media_type, self.parser_context) except Exception: # If we get an exception during parsing, fill in empty data and # re-raise. Ensures we don't simply repeat the error when # attempting to render the browsable renderer response, or when # logging the request or similar. self._data = QueryDict('', encoding=self._request._encoding) self._files = MultiValueDict() self._full_data = self._data raise # Parser classes may return the raw data, or a # DataAndFiles object. Unpack the result as required. try: return (parsed.data, parsed.files) except AttributeError: empty_files = MultiValueDict() return (parsed, empty_files)然后 self.stream() 方法是获取请求头的二进制流的。代码如下
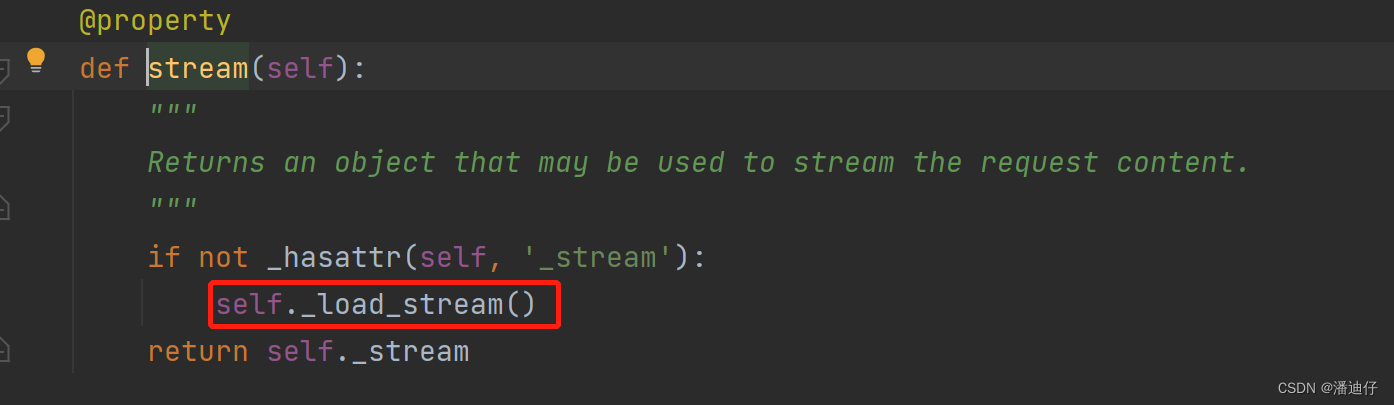
其实上面的 self.stream() 要关注 的是 self._load_stream() 方法,具体如下:
def _load_stream(self): """ Return the content body of the request, as a stream. """ # 获取一个 META 属性 meta = self._request.META try: # 获取请求体的长度,如果是 0 就是异常 content_length = int( meta.get('CONTENT_LENGTH', meta.get('HTTP_CONTENT_LENGTH', 0)) ) except (ValueError, TypeError): content_length = 0 # 请求体的长度是 0 ,那么 self_stream 就是 None if content_length == 0: self._stream = None # self._request._read_started 默认给的是 True elif not self._request._read_started: self._stream = self._request else: # 如果请求体是有长度的说明是有内容的,就调用BytesIO方法写入内存。 self._stream = io.BytesIO(self.body)
# 上面是具体流程了,这节就不做更多的流程图了。没什么意义。




(6)rest framework框架之序列化基本使用
# (1)drf 的序列化_初识
1)序列化其实简单理解就是,将后端的数据格式化成一个字典(在 json 中)传回前台。那么我们直接上一个 demo 来做一下。
如下图所示,如果是 roles = models.Role.objects.all() , 那么返回的对象是不能使用 json 序列化(json 只能对 python 的基本类型进行序列化)。 具体可以查看下面的注释,json.dumps() 中,如果我们不设置 ensure_ascii=False,那么就会选择显示 ascii 码的数据。
返回结果如下(这里记得给数据库弄几条测试数据先)。当然了这只是第一种方式,但是并没有使用 drf 的序列化器。
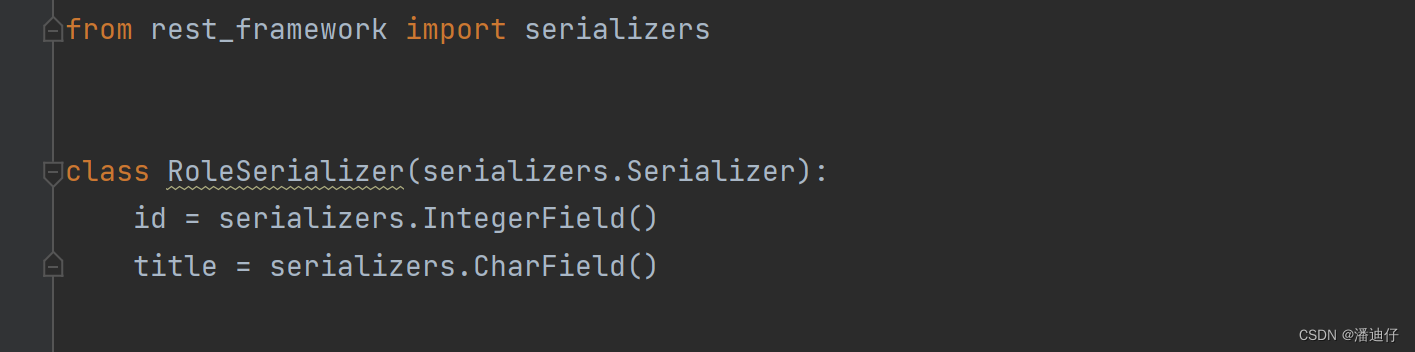
2)第二种利用 drf 的序列化器来做。我们只看具体的操作流程,原理暂且不想。如下图所示,首先是导入依赖的序列化模块 serializers,然后我们可以自定义一个序列化类,然后继承自 serializers.Serializer ,然后在此类下写的字段,必须与数据库 models 中定义的字段和类型是一致的。
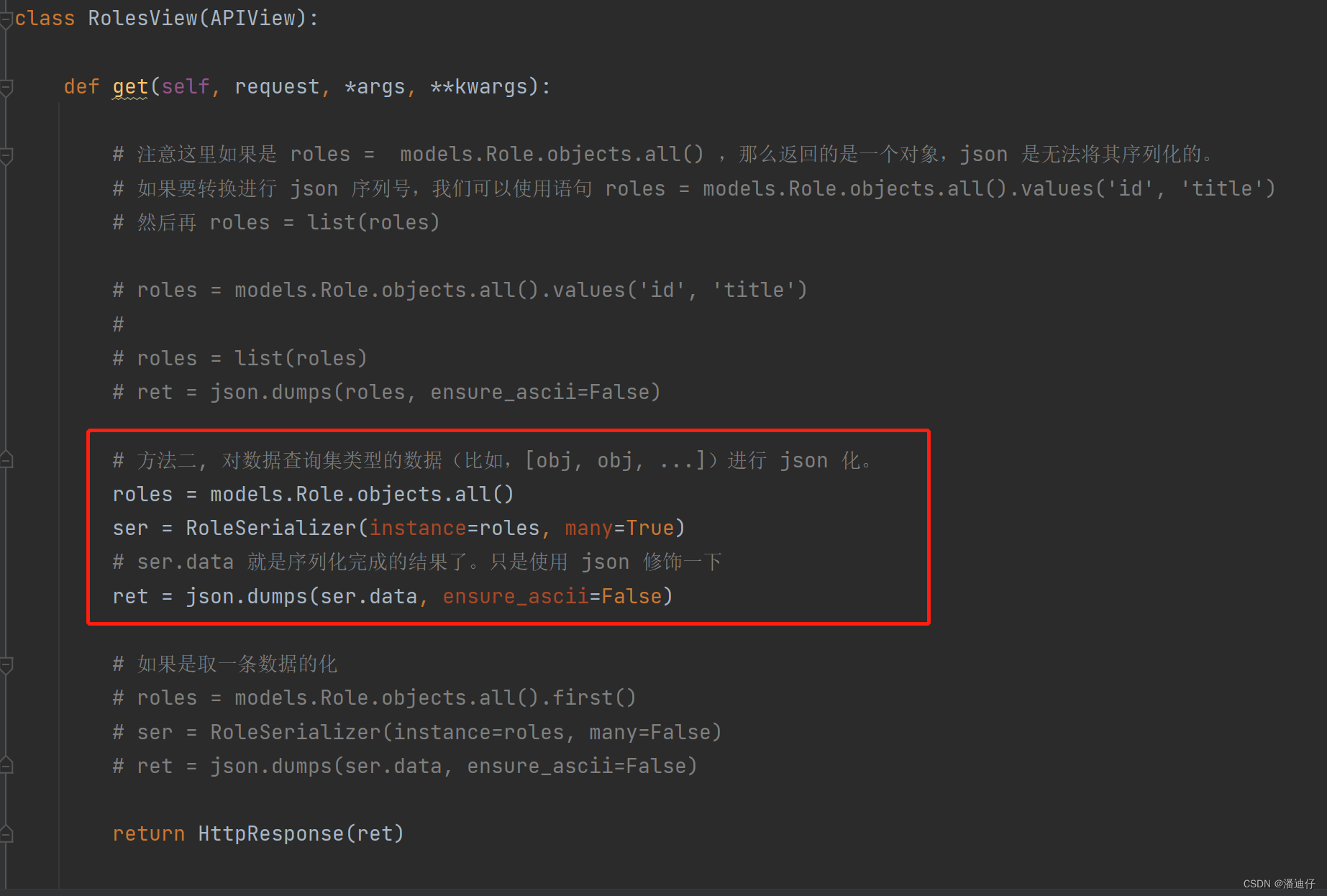
然后我们的 RoleView() 视图类如下。注意一下,因为我们使用的是 roles = models.Role.objects.all() ,之前说了此时的 roles 是不能被 json 序列化的,但是我们可以使用 drf 的serializers 的序列化来做。首先是实例化上面的自定义序列化类 RolesSerializer() ,然后实例化。实例化的时候传参 instance 属性是 roles,属性 many 的意思是数据有多条。
此时的结果可以查看一下:
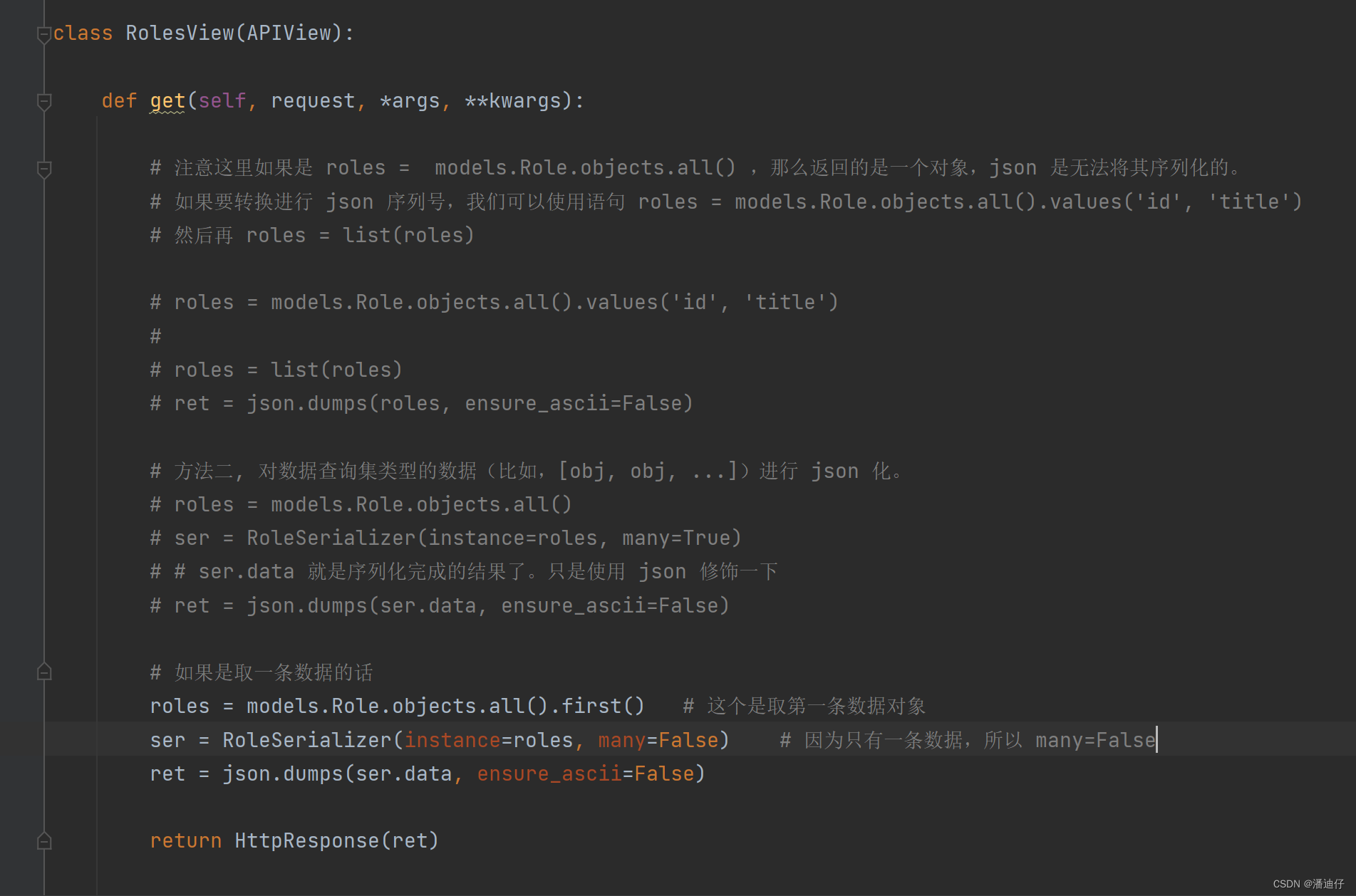
3)当然了,如果我们只是取一条数据的话,也可以是这种写法。里面的自定义序列化类依然是使用上面的。
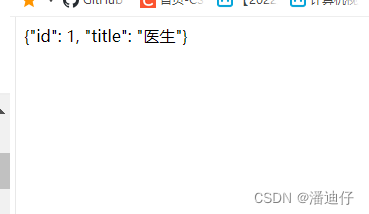
然后我们可以看看返回值。



(7)rest framework框架之序列化自定义字段
# (1)drf 的序列化_初识2
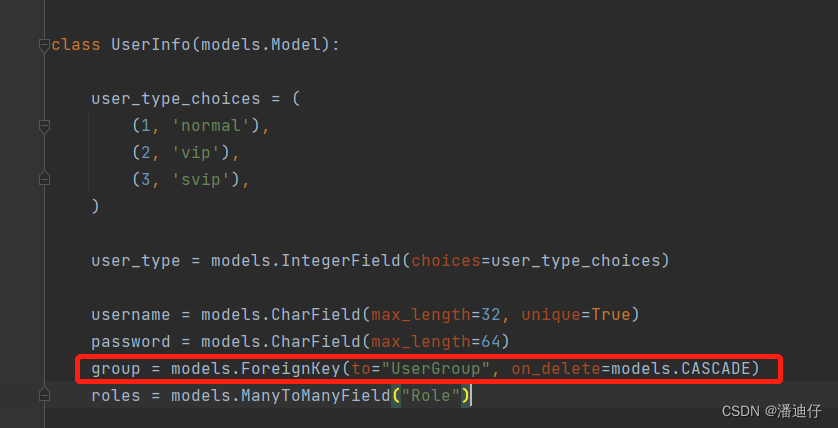
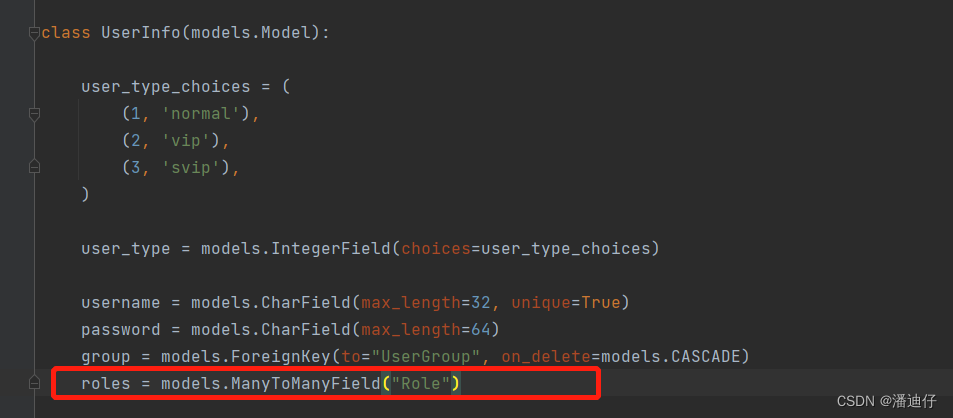
1)为了引出新的知识点,我们直接弄一个新 demo ,首先我们先知道 models.py 下的数据库表设计如下:
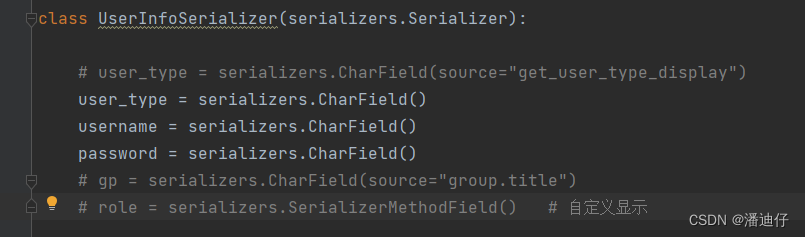
同上面例子,我们要自定义相应的序列化类(暂时不看自定义显示那里),至于视图类,我们可以沿用上例。
2)引入一个 get_user_type_display ,如果我们的语句是 user_type = serializers.CharField() ,那么显示的只是相应的 id,如下面代码所示。
然后显示的结果如下:
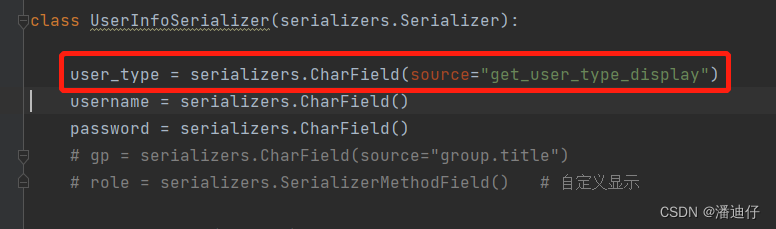
3)显然如果我们要显示完整的 user_type 的真实意思的话,那么就需要使用如下的语句,那么就是 user_type = serializers.CharField(source="get_user_type_display") ,这样就能显示了。
结果如下所示。
# (2)显示 group 字段
1)我们继续承接上面的来说,我们要显示 group 字段的信息,在数据库中 group 是属于外键。
2)那么字段的代码如下,在填写了相应的测试数据后,我们还是使用 source 属性来做,group.title 其实这个 title 就是 UserGroup 表里面的。
那么显示结果如下所示:
# (3)自定义显示部分
1)现在让我们直接来整 roles 字段吧,但是这个在表设计中, roles 字段是属于多对多的关系,指向的表是 Role,那么以下是相应的数据库表信息。
Role 表结构如下:
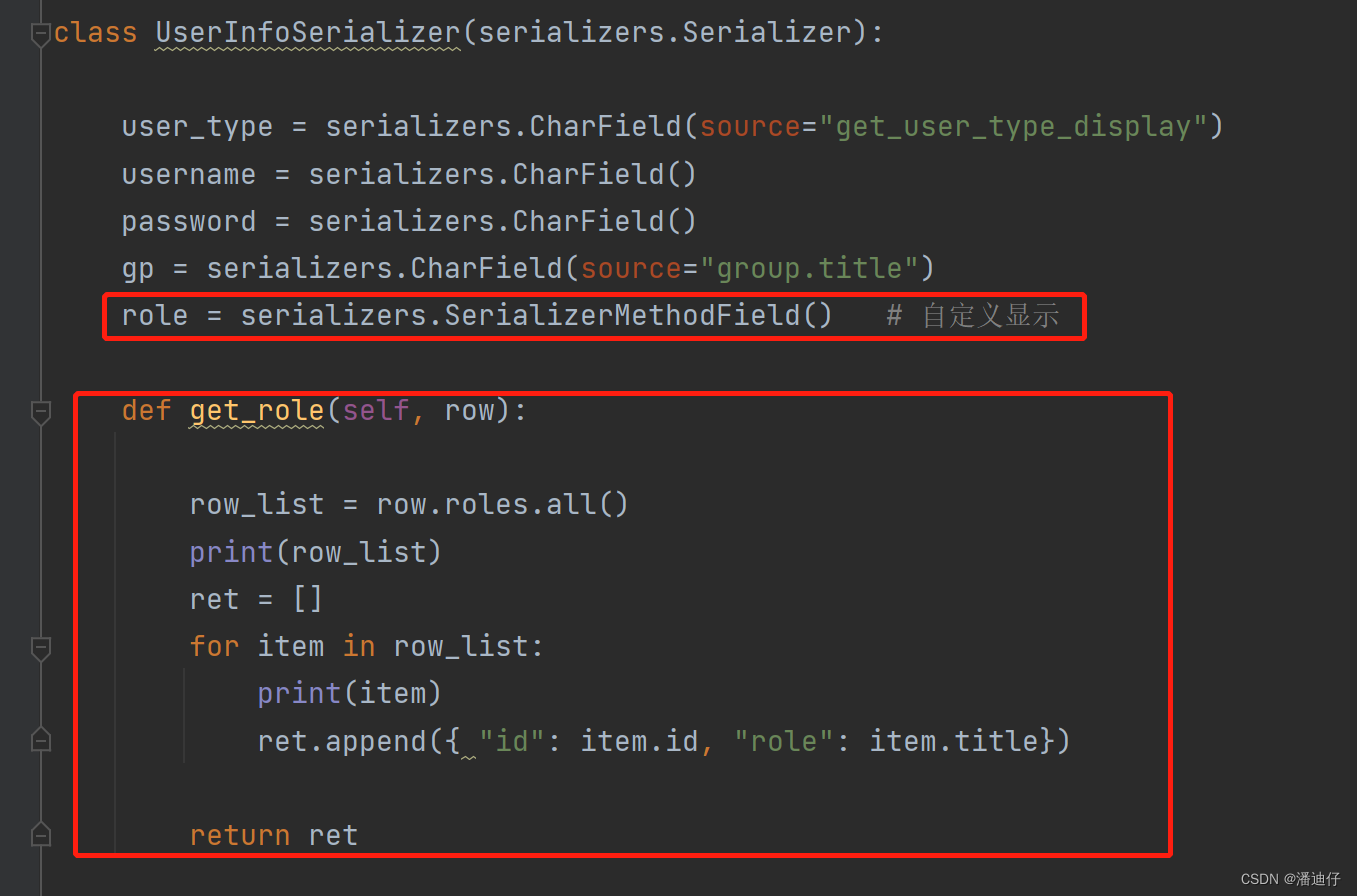
2)那么对于多对多关系,就需要使用自定义的字段格式来做了。如下图所示,我们首先对于多对多的,使用 role = serializers.SerializerMethodField() 来自定义显示,然后这下面就需要定义一个显示的函数了,基本格式就是 get_字段名。比如我们这里的是 role,那么就是定义一个 get_rolw() 的函数。传参是 row。就记住这个固定写法就行,row.roles.all() 取到的就是数据对象,是一个列表装着的,比如 [obj,] 。要注意 roles 是数据库表中定义的字段。然后我们遍历一下这个列表,就可以取出 obj 对象,就可以使用取属性的点的方式来取到所需要的数据了。【这里还有一个细节,后续会说】

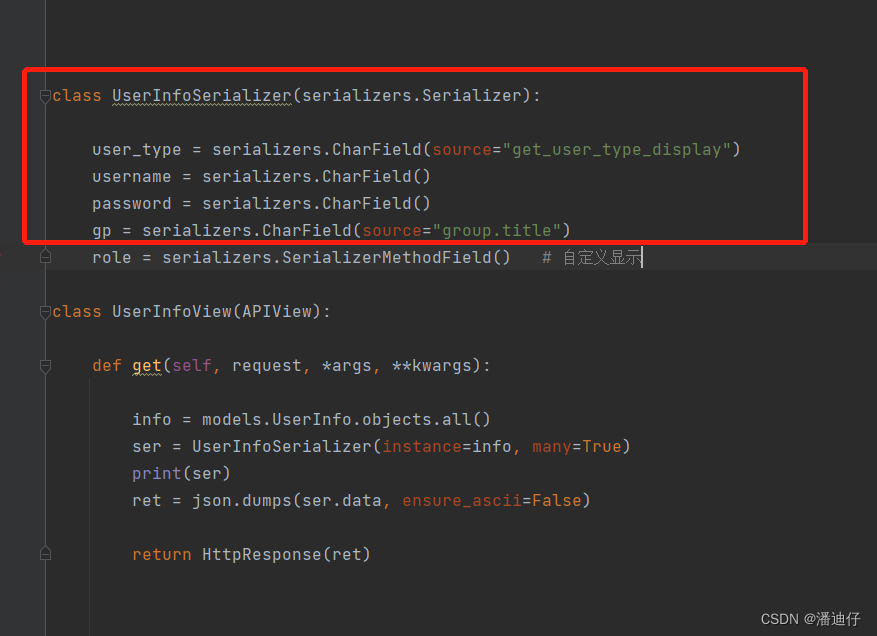





【补充知识】
# (1)wsgi 协议和 jinja2
1)参考链接:【2020 最新python教程】第五部分:Django框架_哔哩哔哩_bilibili
这里我们直接把这一个课程的 01~09 节课做成笔记。
【有空再补】
# (2)路由分发和反向 url 的相关的知识
1)参考链接:15天django入门到放弃_哔哩哔哩_bilibili 的 P63~P69
2)对应的课程章节的笔记,如下:
【##########################】
1)04 day70 Django程序目录介绍。
首先我们可以知道的是,在终端可以输入 python manage.py startapp api 来生成新的 app 程序。一般来说,项目的每一个业务会对应一个 app 来做。那么相应的程序目录介绍如下:
migrations:是和数据库迁移相关的文件夹。
admin:这是一个默认的后台管理系统。
apps.py:当前 app 的相关配置文件。
models.py:定义数据库表的文件,这里涉及后续的 orm 操作。
tests.py:做单元测试的。
views.py:视图函数的编写(就是业务处理)
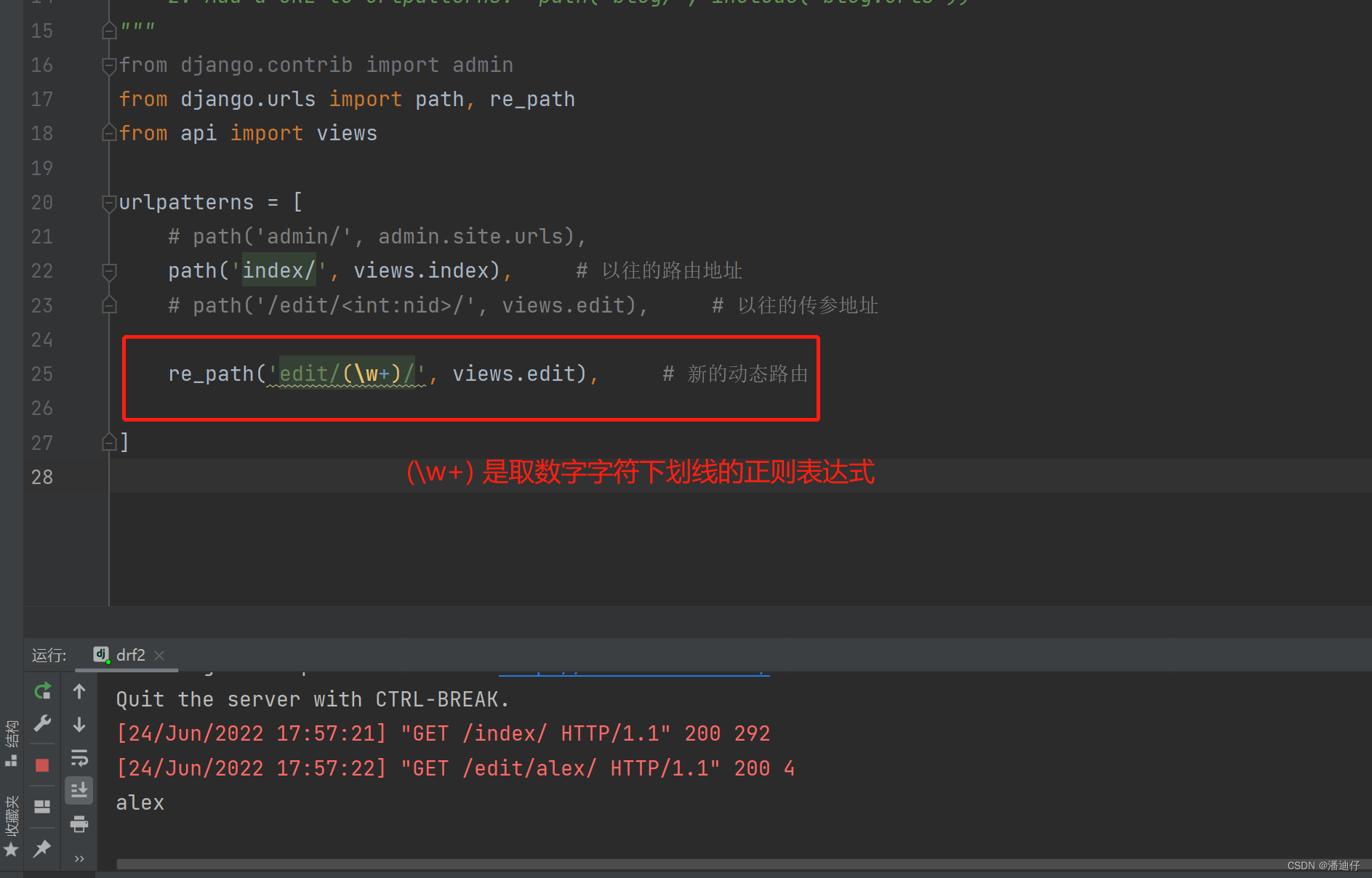
2)05 day70 路由系统之动态路由(一)
以往的路由函数系统,我们基本用的都是一对一的方式,比如一个 url 对应一个视图函数,具体的传参也是再添加相应的接口名,如下图所示。前端页面
后台 url 的设计如下,这种方法虽然简单,但是不利于 seo 优化(即检索的优先级),因而我们采用新的方法。
【新方法】
新方法中我们对 url 进行改造,利用正则表达式来取得前端的参数。但是在 Django 2.0 版本之后,要使用正则表达式的 url 的话,需要导入 re_path 模块。
至于所取的参数,我们可以到视图函数中取出来。如下图所示。
同时补充一下,如果我们不使用 re_path 模块来做 url 的话(正则表达式情况下),那么我们可能需要设置settings.py 中的 DEBUG = False,同时需要设置 ALLOWED_HOSTS = ["*"] ,比如 "*" 就是允许所有 ip 地址访问。
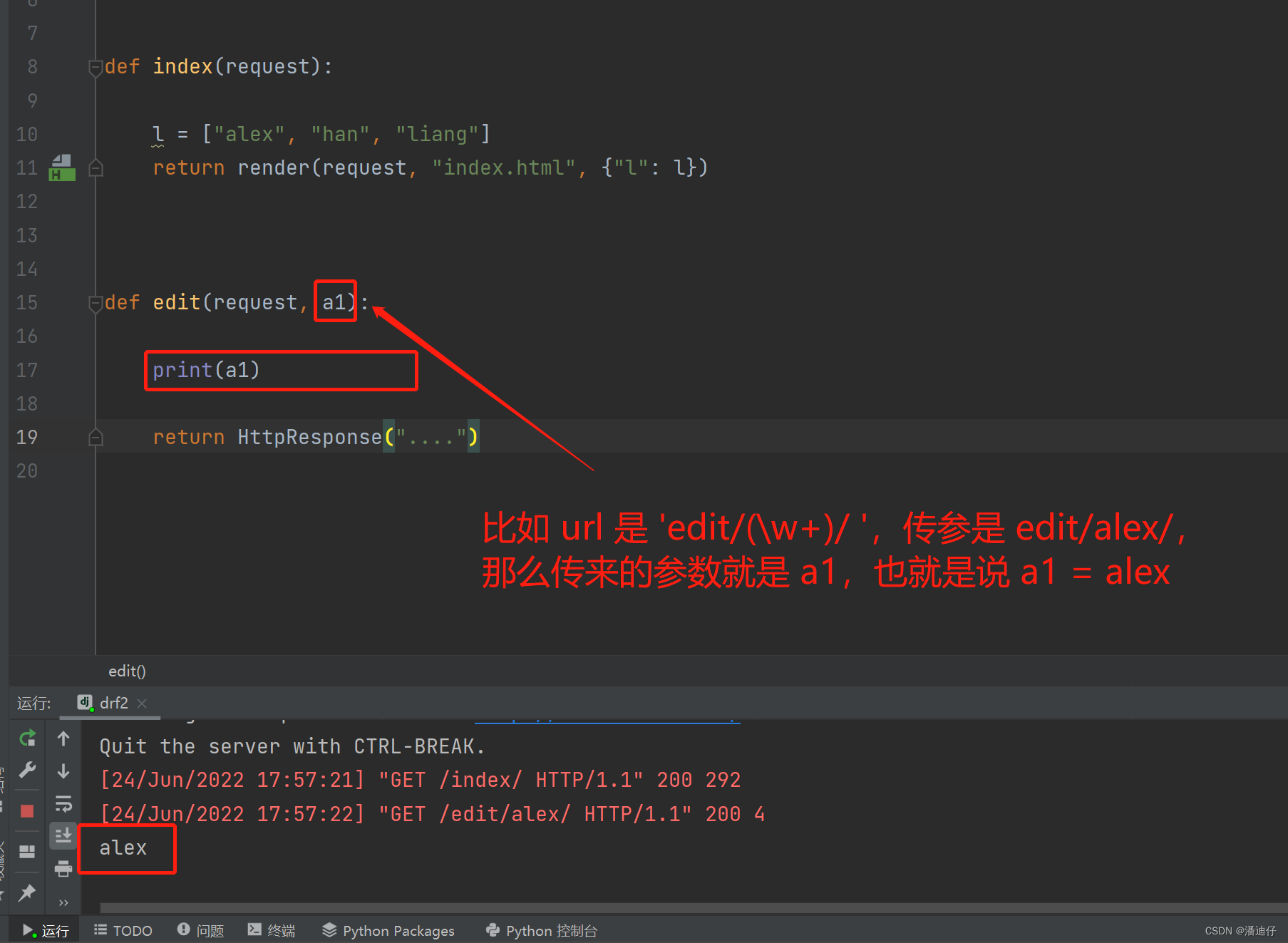
3)06 day70 路由系统之动态路由(二)
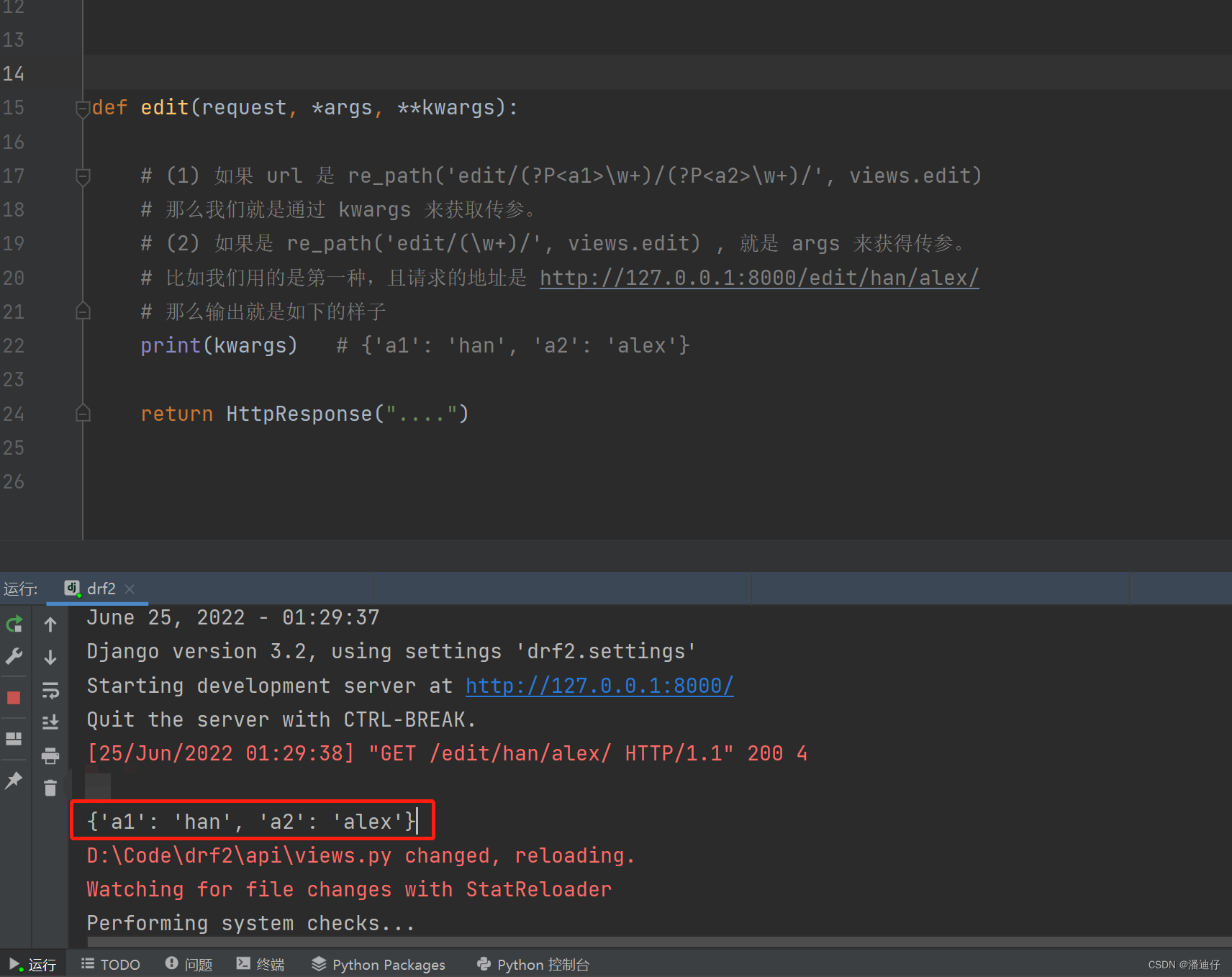
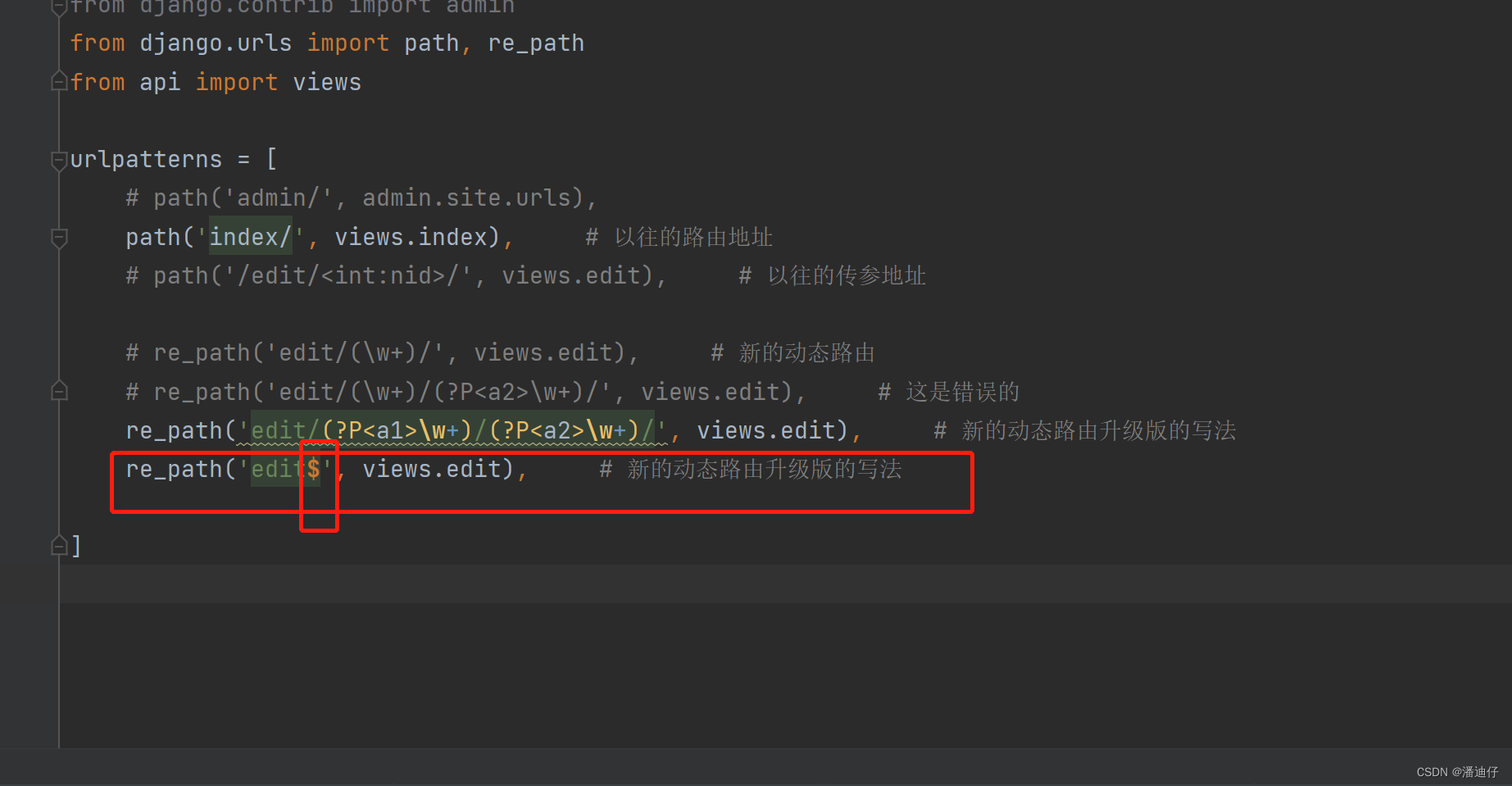
正则表达式的进一步用法。如下图所示,正则表达式的进一步写法是在原有的 ..../(\w+)/(\w+)/ 的基础上改进的。其实就是为了表明传参的时候给谁的,比如说我们改成了这样 .../(?P<a1>\w+)/)/(?P<a2>\w+)/ ,这个意思是第一个传参是 a1,第二个传参的 a2,那么后台的视图函数定义的时候,就得是 def edit(request, a1, a2) 。其中注意的一点就是,第一种和第二种(就是进一步的写法)这两个是不能混用的。
基于此,我们设计的视图函数就如下图所示了。具体可以看注释。
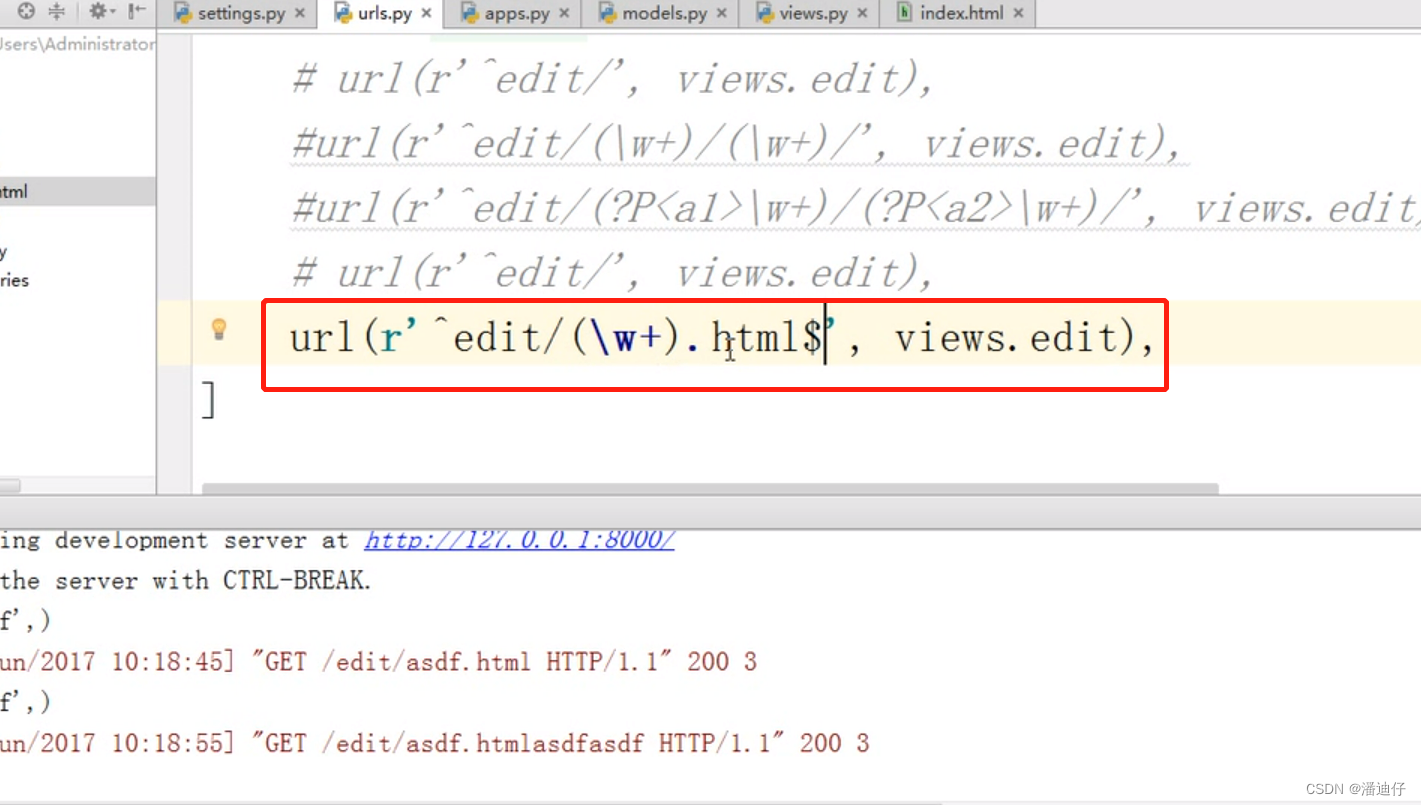
页面终止符 $。其实这就是我们在输入的 url 是这样的, http://127.0.0.1:8000/edit/han/alex/ 那么我们会发现在 alex 的结尾处会放一个斜杠,其实有一个 $ 终止符,我们只需要写上这个,后台就会自动帮我们加入 / ,也就是说 $ 就是 url 的终止了,后面带参数都是报错的。如下图所示,
伪静态页面。伪静态的意思就是在设计 url 的时候,在末尾加一个 .html 。这就是假装一个静态页面(因为静态页面的加载速度比动态页面更快)。那么根据 seo 优化的规则,加入伪静态的话,能够优先检索。
4)07 day70 路由系统之路由分发
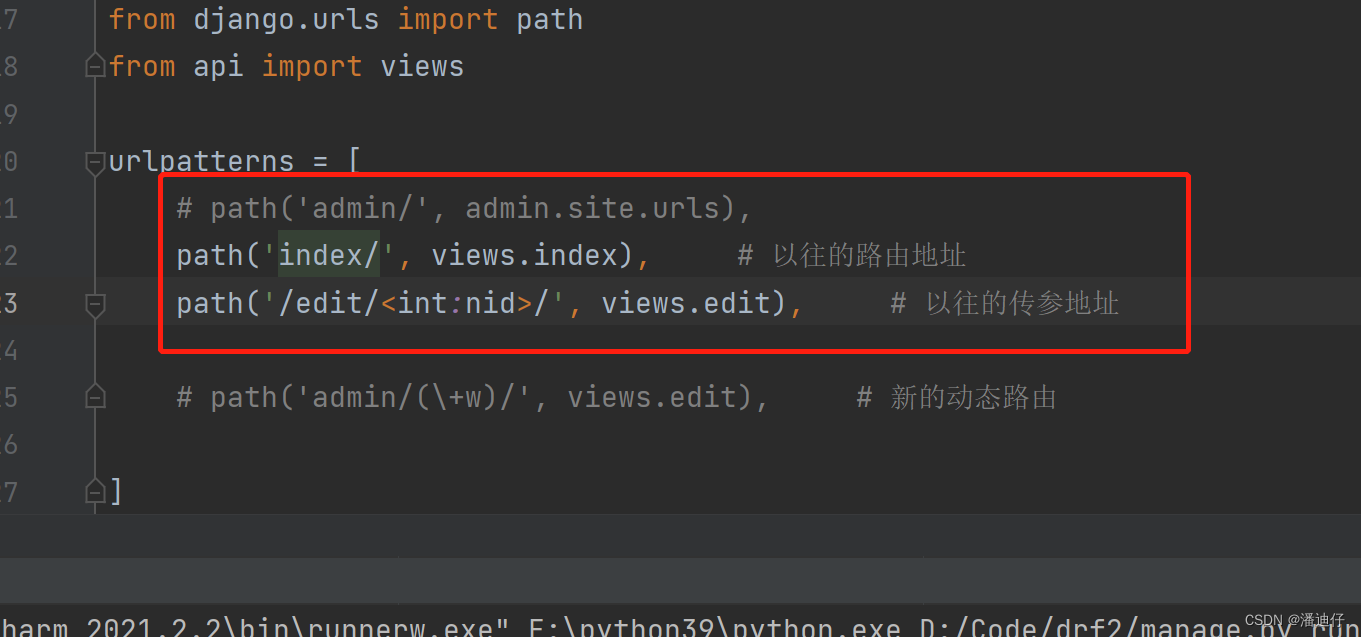
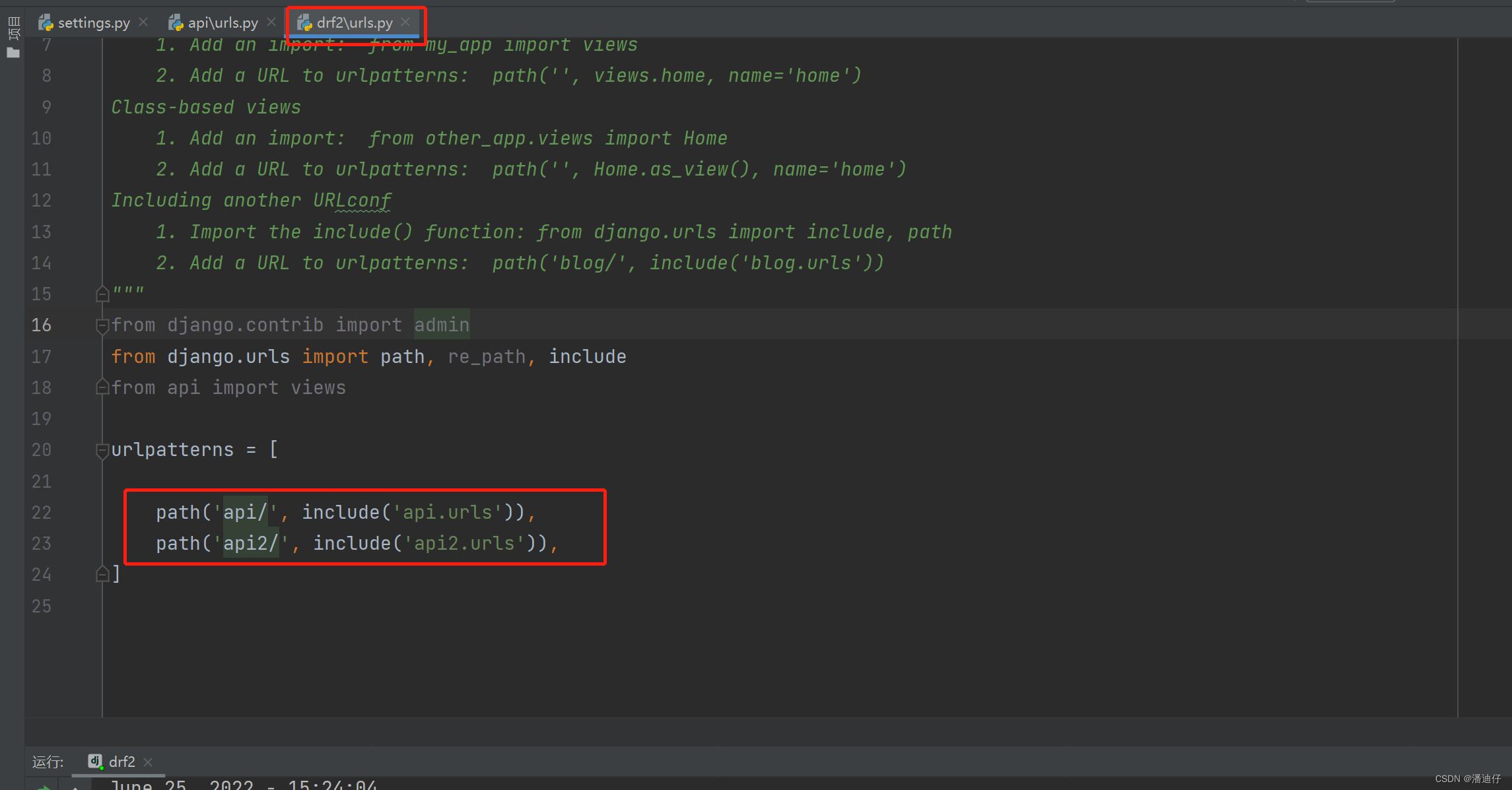
路由分发。其实就是为了更好的协同开发。我们知道一个项目中,一个业务对应一个 app 程序,路由分发的思路就是,在总的项目 url 配置中,我们只给出每一个业务对应的 app 程序的地址,请求进来后先索引到目标 app 程序,然后再由 app 程序自己的 url 配置中找到相应功能的视图函数。具体的话是要应用 include 模块,即 from django.urls import url, include ,如下图所示,是项目的 urls 文件,里面只放了 app 程序的路径,格式如下。
那么,请求交付的时候,就是先匹配对应的 app 程序,然后才是到对应 app 程序下的 urls 文件找到相应的地址。如下图所示,是 app 程序下的 urls 文件内容。比如我们的请求是 http://127.0.0.1:8000/api/index.html ,那么我们首先是索引到 api/ ,接着到了api 的 urls 文件下,接着再又 api 内的 url 匹配后面的 index.html 路径。这就是所谓的路由分发了。
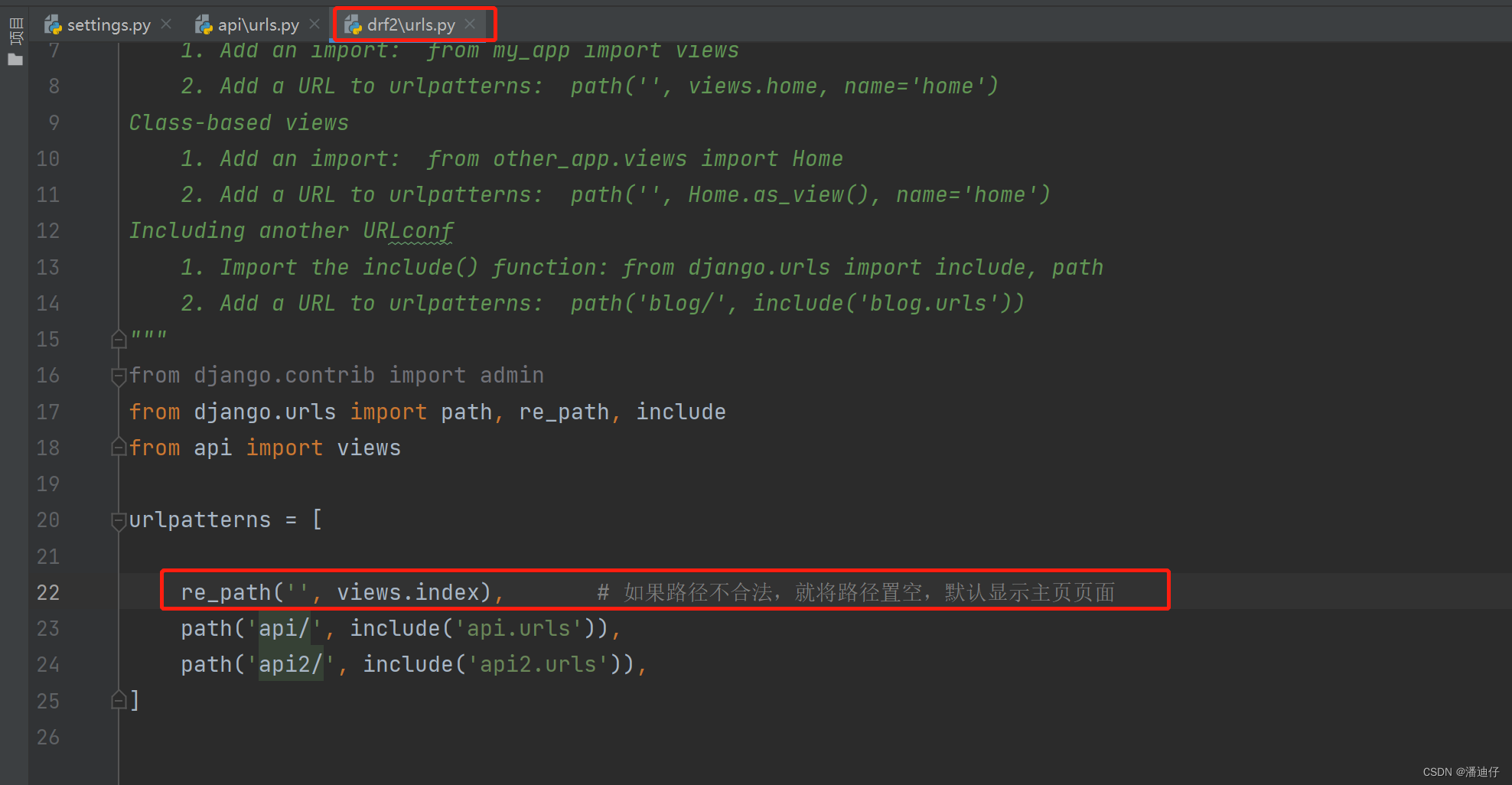
匹配不成功的情况。我们索引到目标的app 程序后,但是在该程序的 urls 文件下,没有找到相应的后缀文件。比如请求是 http://127.0.0.1:8000/api/indexaa.html ,但是 api 下的 urls 没有 indexaa.html 的接口路径,如此就会报错。我们可以设置一个默认的路径来操作。设置方法可以下图注释,注意,我们所说的置空是 urls 文件里面的(个人理解的抽象概念)。直接在项目的 urls 文件下设置即可。
5)08 day70 路由系统之别名反向生成URL(一)
反向生成 url 。在 urls 文件中,其实在配置 url 的时候,我们还可以给某一个指定的 url 设置一个别名。如下图所示,即 re_path('index/',views.index,name="n1"),也就是给 index/ 取一个别名是 n1。
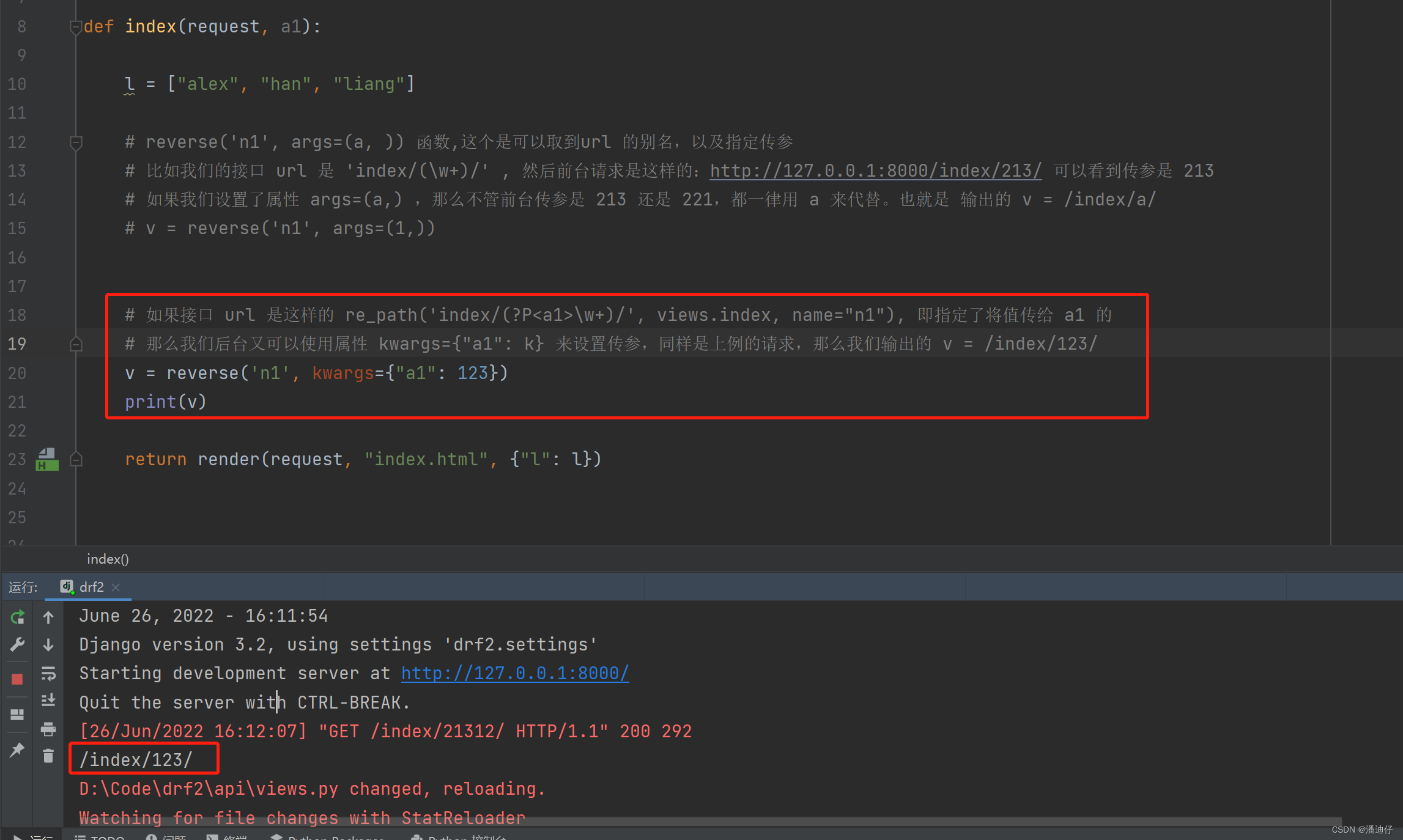
我们可以到对应的视图函数,views.index 下看一下输出的 n1 是什么。如下图所示,我们使用 reverse 反向模块,然后 v = reverse("n1") ,那么 v 输出的就是 /index/ 。当然下图的我们还设置了属性 args=(1, ),这个的意思可以见下面注释。注意我们要传参啊!!
当然了,不只如此,如果我们设置接口的时候,是 re_path('index/(?P<a1>\w+)/', views.index, name="n1"),那么我们又可以按照下图的配置。
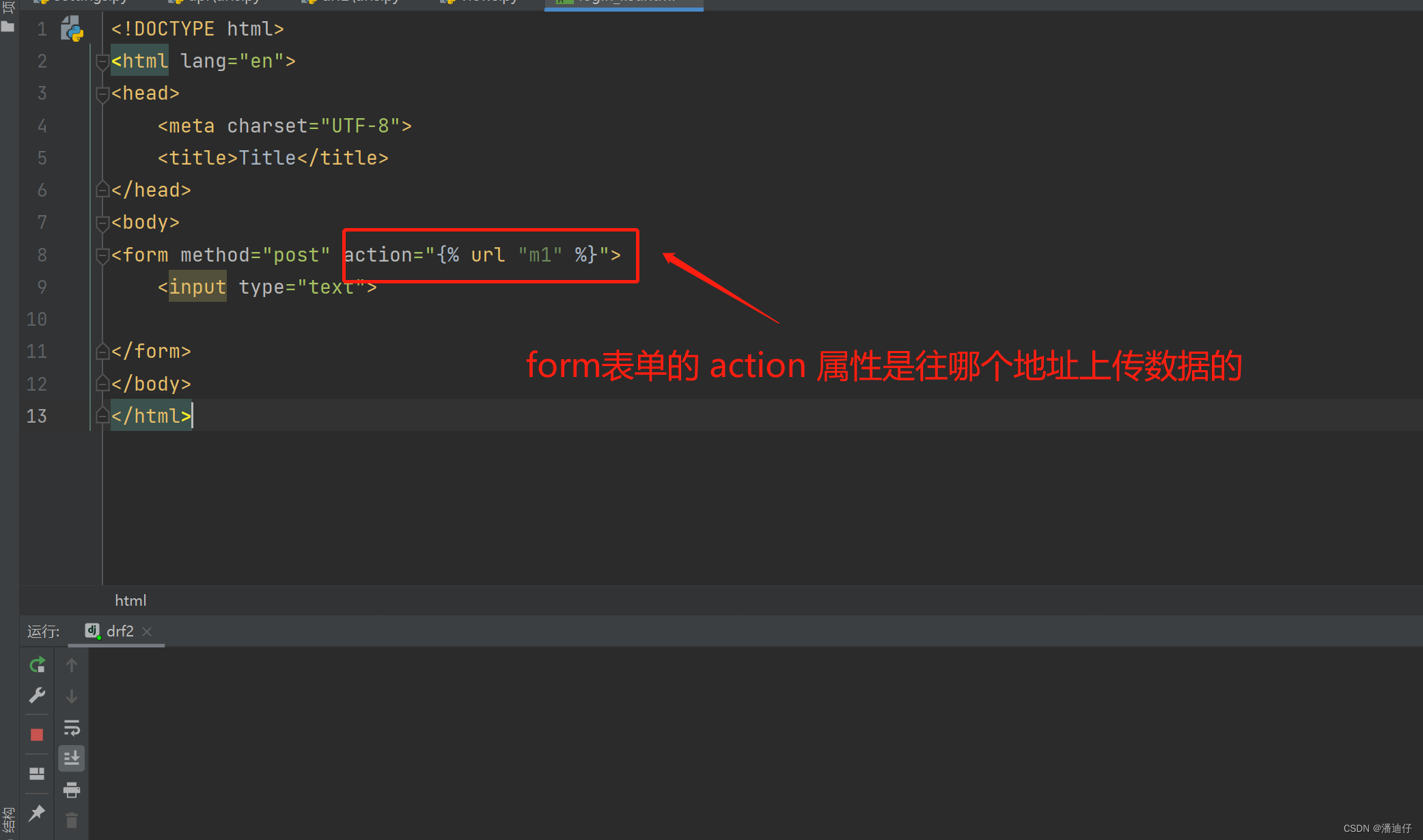
一个小实战。在模板中反生成 url 的demo。我们随便创建一个 login 的接口,且别名是 m1 ,然后写相应的视图函数,不赘述了。然后前台的模板代码如下,action 处的写法就是如下图所示了。
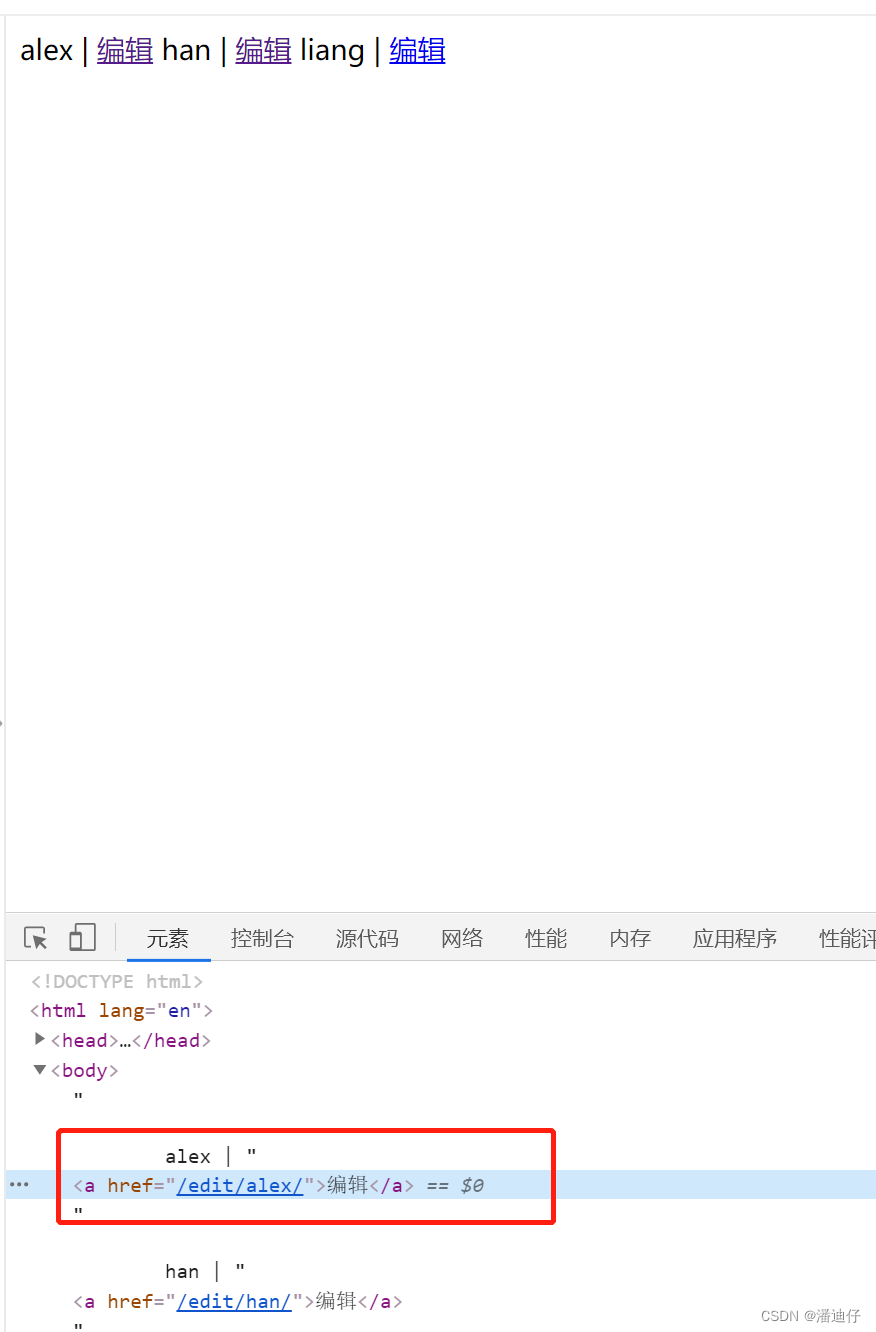
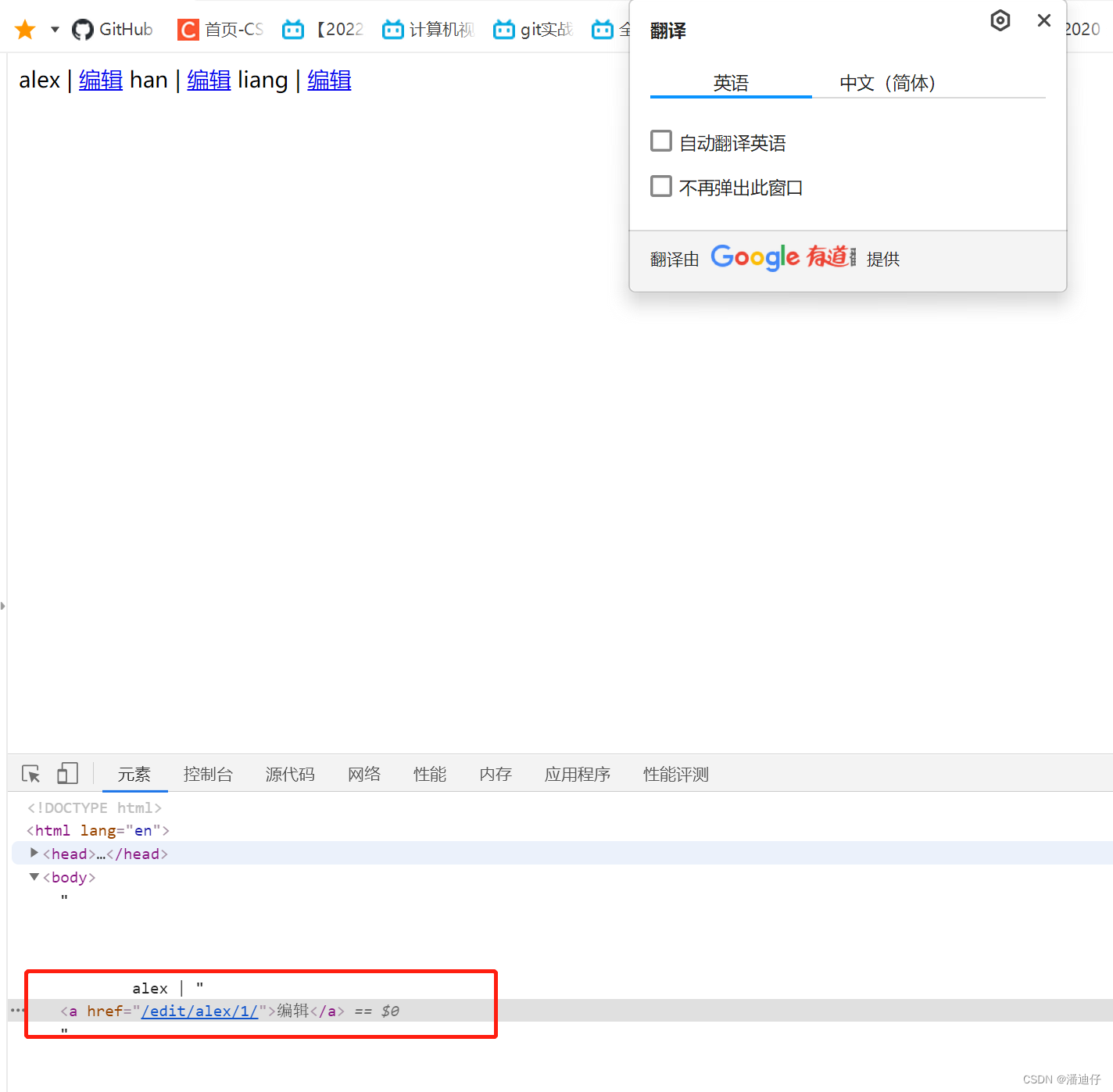
我们打开控制台可以看见,前端的模板已经帮我们自动取到了 m1 别名对应的接口名称 /login/,如下图所示。(但这只是 django 独有的)
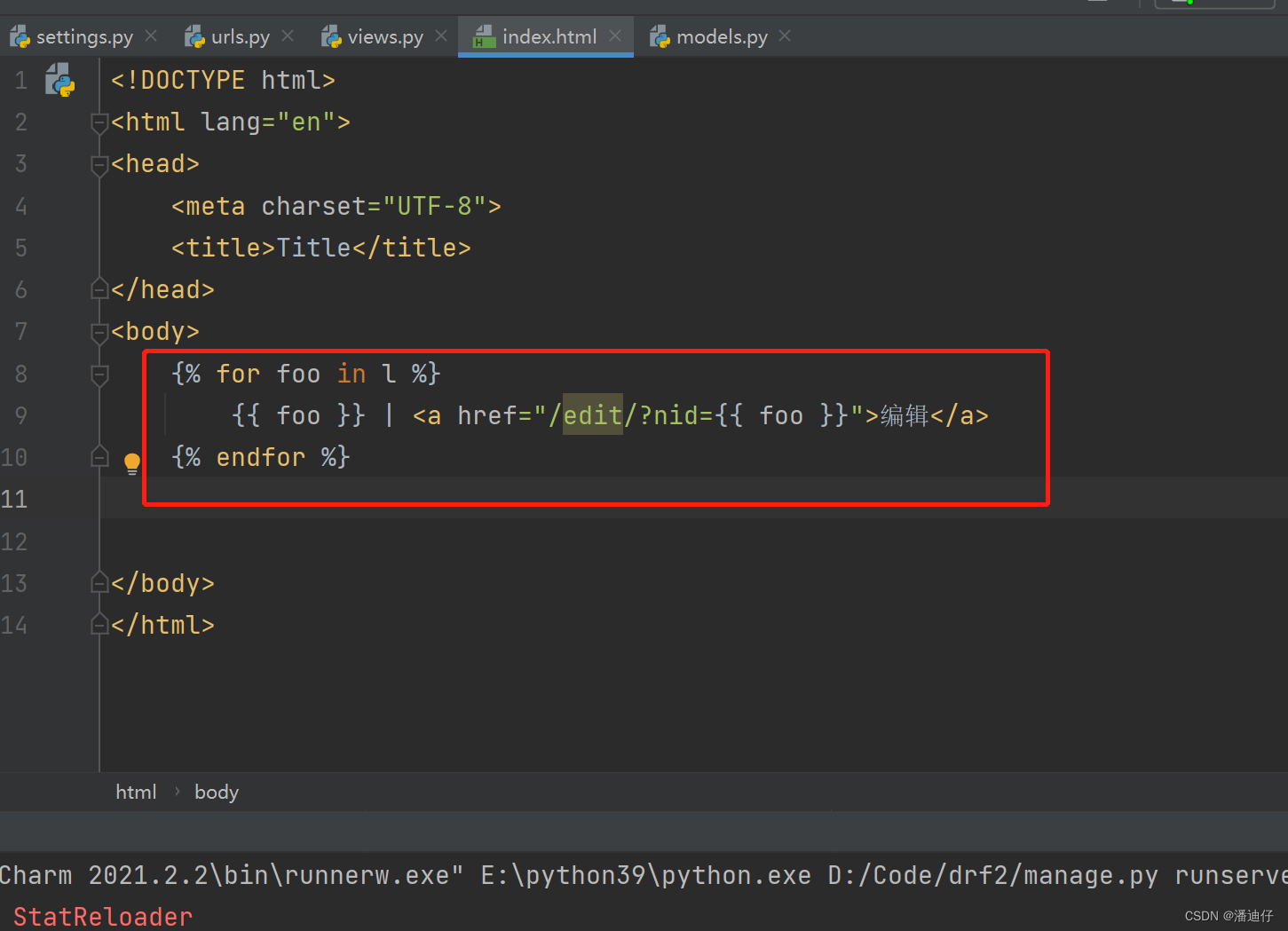
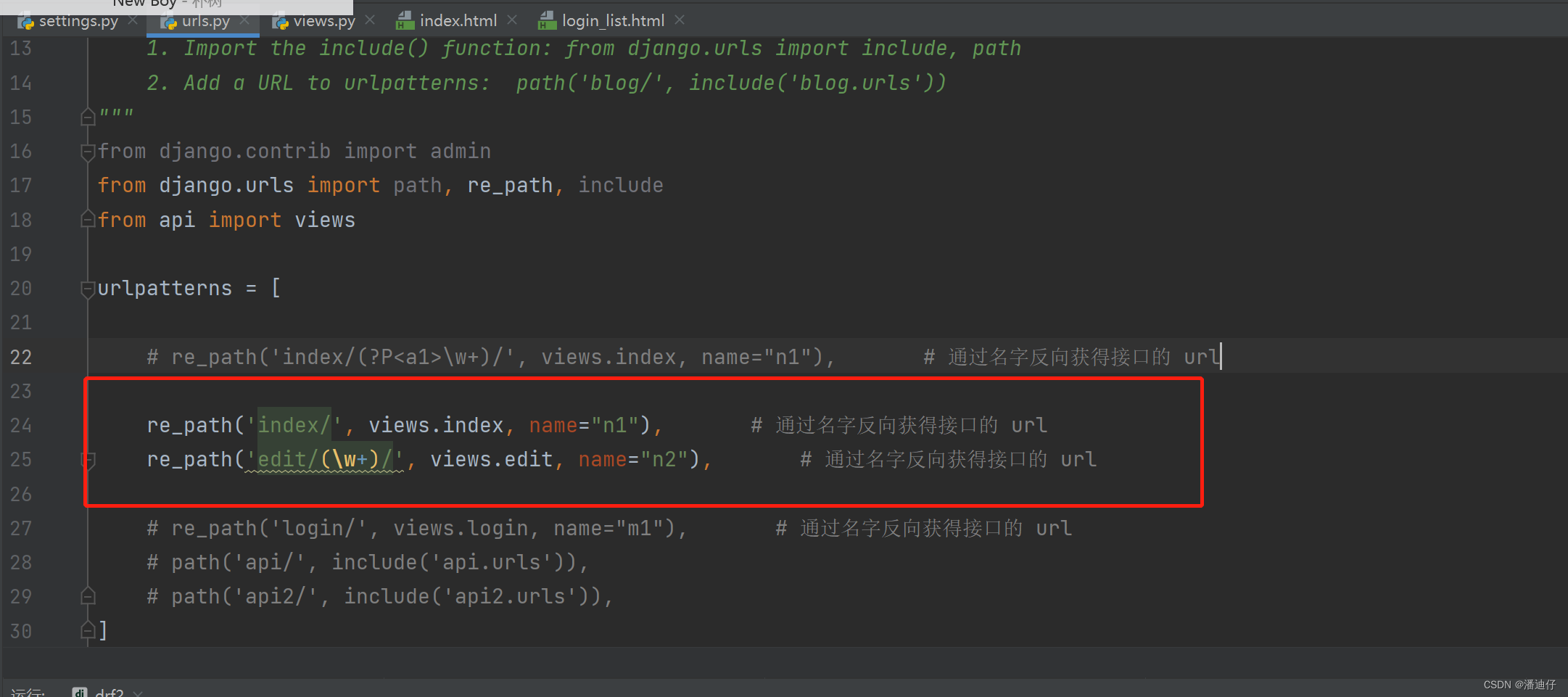
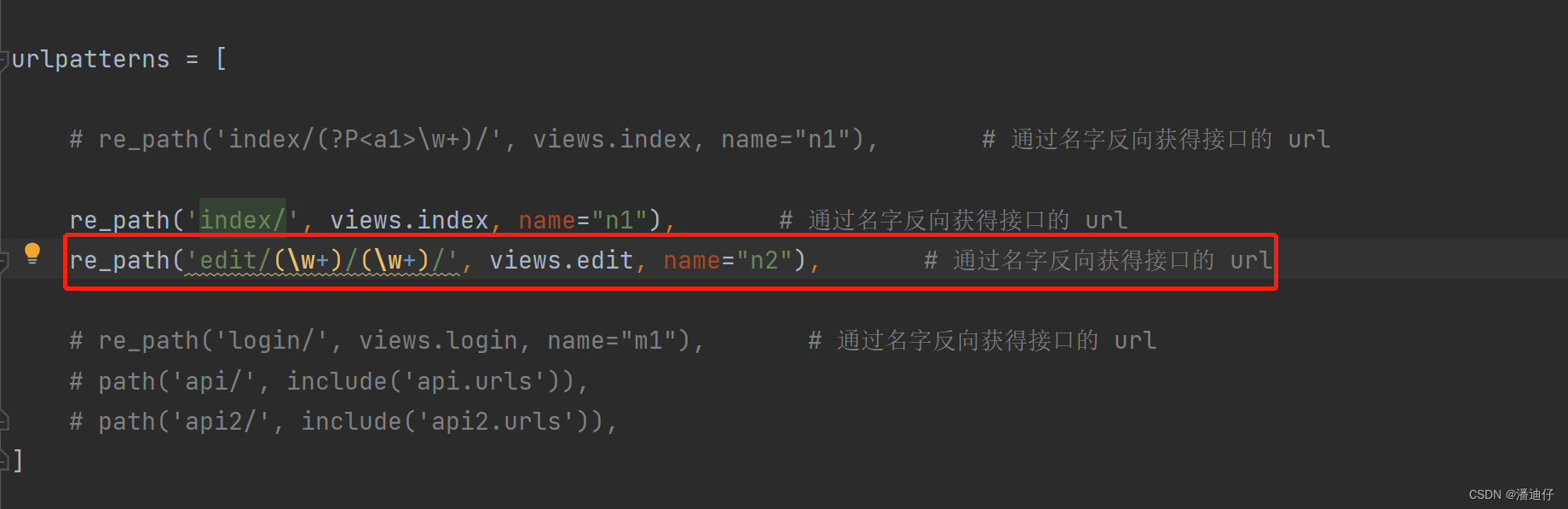
有了上面的例子,我们可以再深入一点,比如接口设置如下图所示。可以看到我们给接口 index/ 的别名是 n1,接口 edit/(\w+)/ 的别名是 n2 。
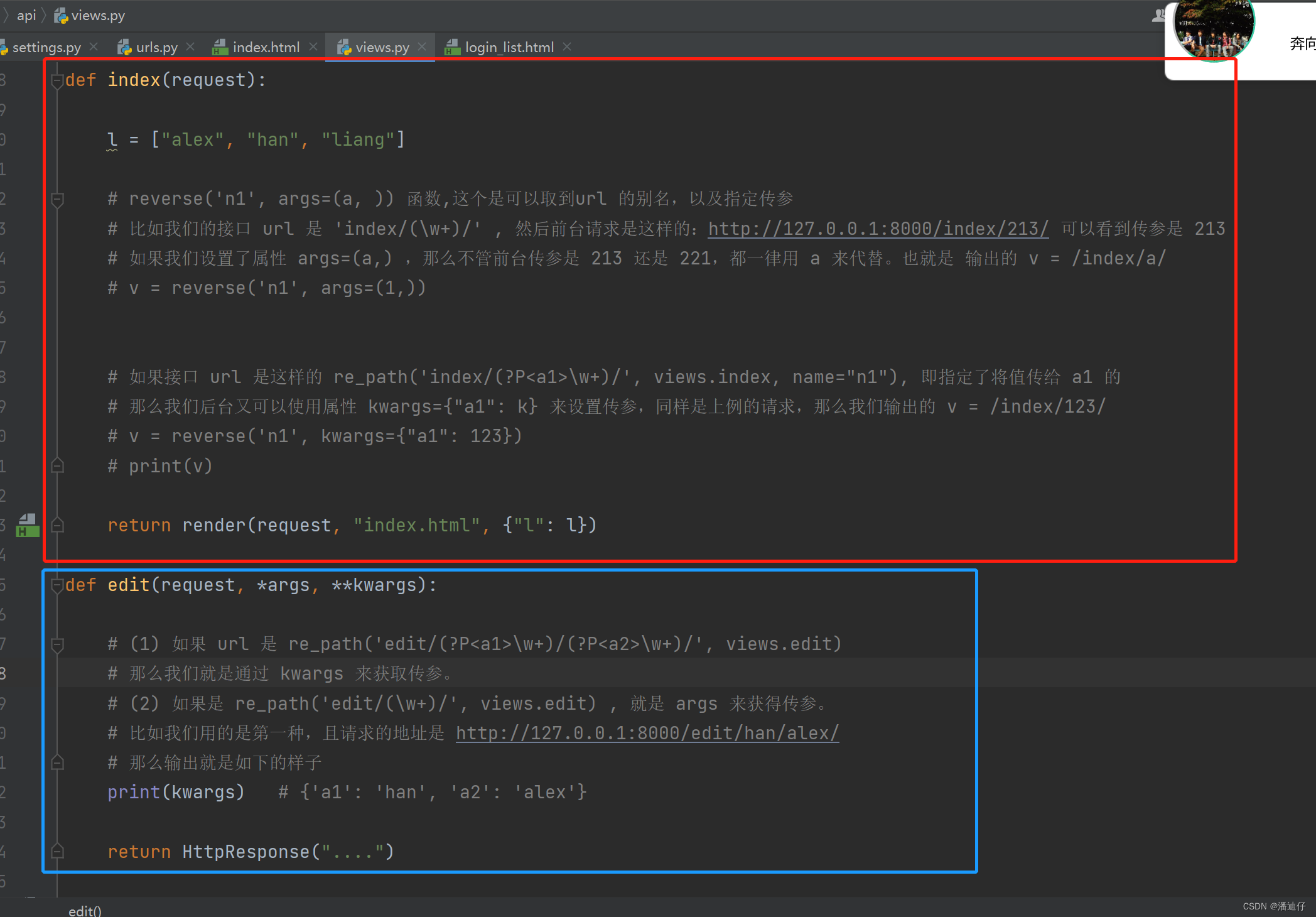
然后我们对上述两个接口的视图函数的编写如下,可以看出我们首先是访问 index/ ,然后页面的某个值进行编辑,那么对应的传参就会赋值给 (\w+)。
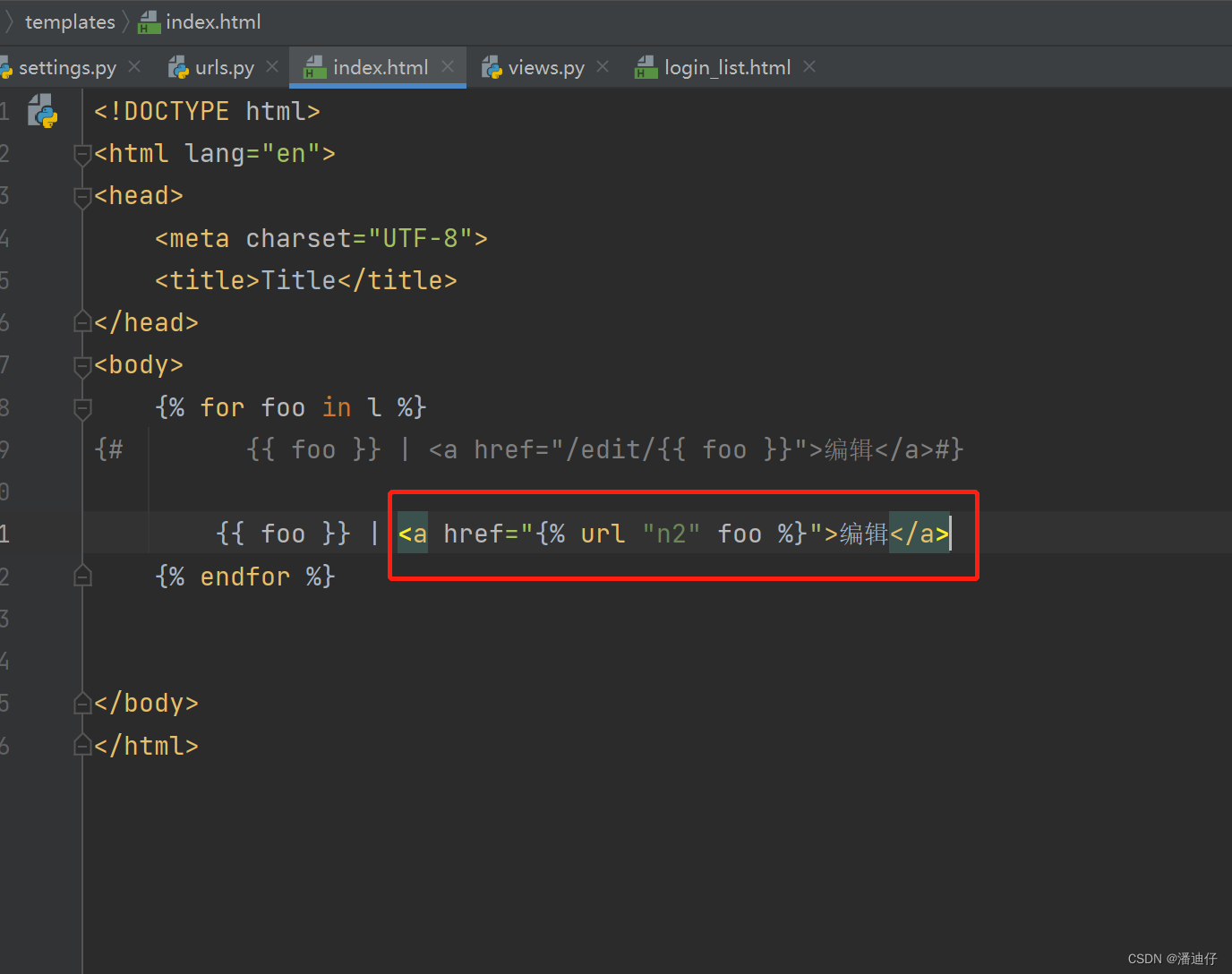
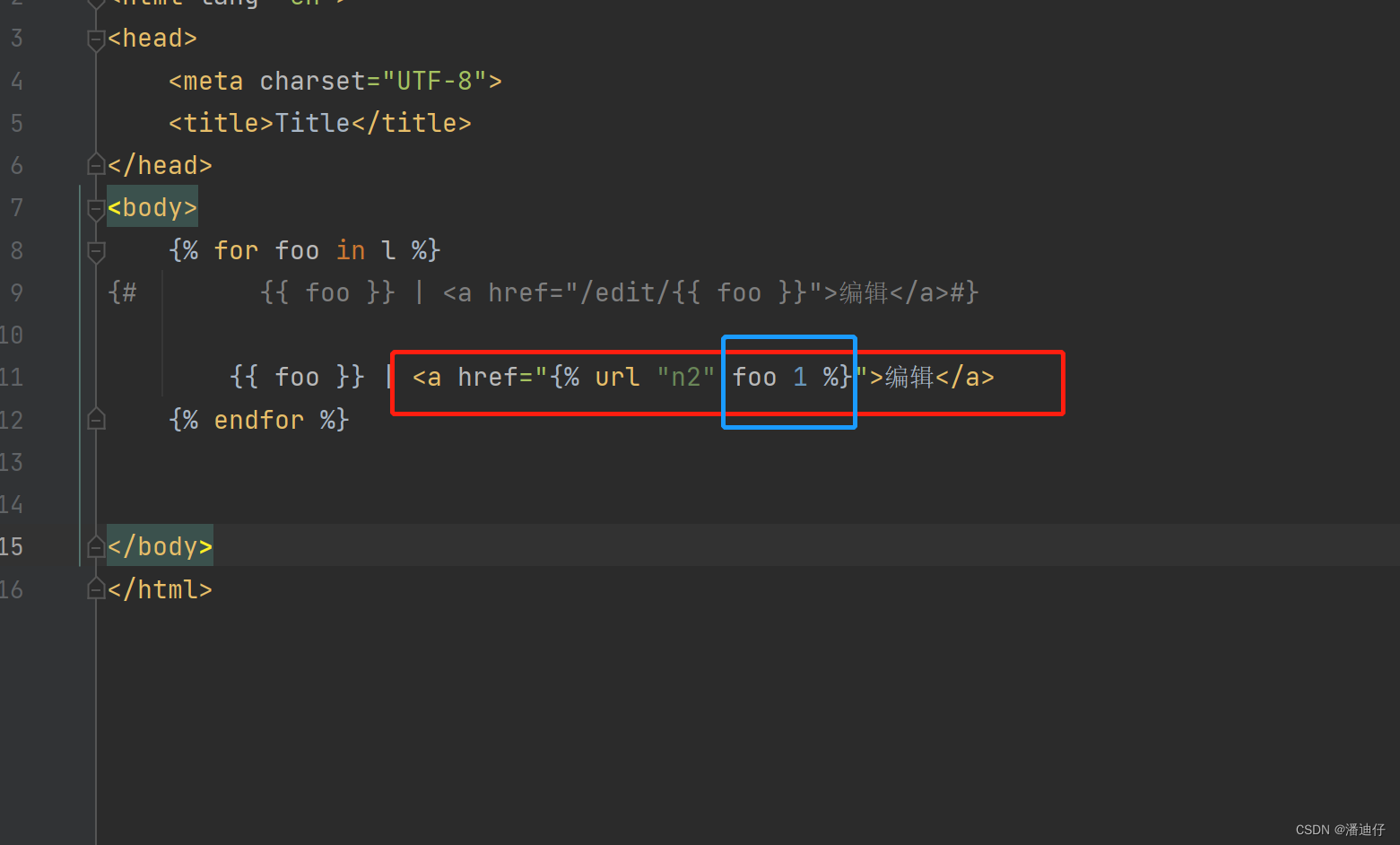
那么我们要传参的话,前台页面又可以这样写了,如下图所示。原来的方法是注释的写法,而下面红框的就是全新的传参写法了。首先前面的 url "n2" 指明了是 /edit/ ,后面的 参数 foo 则是传去的参数,也就是 /edit/foo/ (这里的 foo 代指要编辑的那个值)。
那么我们看看前端的控制台,就可以理解了
如果传参是两个的话,也就是接口的设计如下图所示。
那么我们前端的传参可以这么写,就是直接以空格再写就行了。
我们再查看一下前端的控制台。
6)09 day70 路由系统之别名反向生成URL(二)_就是小总结【略】
7)10 day70 路由系统之别名反向生成URL(三)_ 略
#






















 4543
4543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









