







Pandas是Python的一个扩展程序库,常用于数据分析。它是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。Pandas 作为一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算),可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
一、数据结构 - Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。语法如下:
pandas.Series(
data (数据组),
index (索引开始位置,默认从0开始),
dtype (数据类型,默认pandas会自己判断),
name (设置名称,默认为空),
copy (是否复制数据,默认False)
)实例:虽然索引可以为字典但是不要使用,否则在读取数据时会报"typeerror",此处只是为了演示
import pandas as pd
name = ['老王','老李','老刘']
myvar = pd.Series(data=name,index=[1,'a',{'abc':123}],name='人名',copy=False)
print(myvar) 
根据索引值读取数据,索引目标数据不存在时返回'NaN':
print(myvar['a']) ![]()
我们也可以使用 key/value 对象,类似字典来创建 Series:
import pandas as pd
name = {4:'老王',5:'老李',a:'老刘'}
myvar = pd.Series(name)
print(myvar)我们可以看到,key值自动变成了索引值
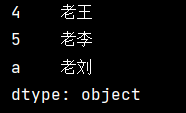
基于此只需要字典中的一部分数据,只需要指定需要数据的索引即可:
import pandas as pd
name = {4:'老王',5:'老李','a':'老刘'}
myvar = pd.Series(name,index=[1,'a'])
print(myvar) 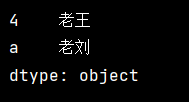
二、数据结构 - DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
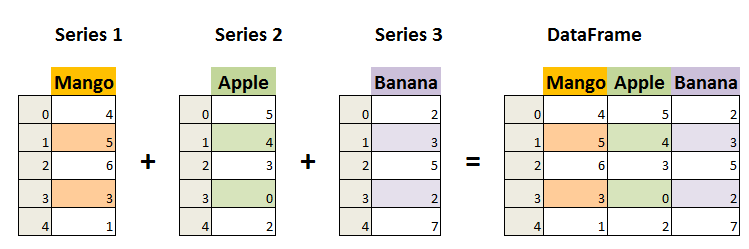
DataFrame 构造方法如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 110
110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









