







注:
Unimelb Comp90042 NLP笔记
相关tutorial代码链接
Text Classification(文本分类)
分类定义:
- Input
- 一个文本,通常以向量的形式展示文本的特征
- 一组固定的输出类型 C= {c1, c2, … , ck},非连续(continuous),非有序(ordinal),是分类型(categorical)
- Output
- 文本预测的类型 c ∈ C c \in C c∈C
文本分类包括哪些任务
1 分类类型
1.1 主题分类(Topic Classification)
这段文字是关于收购还是收益?由于文章中出现了“shareholders”,“subsidiary”还有“share stock”,所以可以判断这是关于收购相关的主题。

Motivation:通常用于图书馆学、信息检索
Classes:主题类别有“工作”、“国际新闻”等等
Features:
1)词袋模型(BOW)
2)更长的N-grams用于词组(phrases)
Corpora例子:
1)Reuters news corpus(RCV1,路透社新闻语料库可参阅NLTK);
2)Pubmed abstracts(一个提供生物医学方面的论文搜索和摘要的数据库);
3)Tweets with hashtags(带有话题标签的推文)
1.2 情感分析(Sentiment Analysis)
这个tweet的感情是什么?

Motivation:Opinion mining(意见挖掘),Business Analytics(商业分析)
Classes:正向、负向、中立
Features:
1)N-grams:之前的主题分类会使用BOW(将一句话变成一个向量)是因为我们并不在意语句的顺序。但是情感分析中,单词顺序非常重要。
2)极性词典(Polarity lexicons):本质上包含了一堆正面极性和负面极性的单词的字典。通常是由人们手工创建,精度高,但覆盖范围小,适合用bootstrap的方式提升算法。
Corpora的例子:Movie review dataset(影评数据)、SEMEVAL Twitter polarity dataset(基于推特的情感极性分析数据集)
1.3 母语辨别
以下是什么母语的作者写的文章?

Motivation:司法语言学(forensic linguistics),教育应用(educational application)。前者应用于网络罪犯证据收集,后者帮助缩小有不同文化背景的教师和学生。
Classes:作者的第一语种(比如印度尼西亚语)
Features:
1)词级n-grams(word n-grams)
2)句法模式(syntactic patterns):POS(词性), parse trees(解析树), abstract syntax tree(抽象语法树1)
3)语音特征(phonological features):通过用户的口音来判断
Corpora例子:
托福、雅思短文语料库
1.4 自然语言推论(natural language inference)
这两句话的关系是牵连的还是矛盾的?

AKA Textual Entailment(文本蕴含)
Motivation:语言理解(language understanding)
Classes:Entailment(牵连),contradiction(矛盾),netural(中立)
Features:
1)Word overlap:检查两个短语或句子之间重叠的单词数
2)Length difference between the sentences:橘子们的长度差别
3)N-grams
Corpora例子:
SNLI(斯坦福自然语言推理语料库),MNLI(多类型自然语言推理语料库)
1.5 其他文本分类
自动核对事实(automatic fact-checking)
解释(Paraphrase)
2 分类算法
2.1 文本分类器搭建步骤
- 确定任务
- 收集合适的语料库
- 做标注
- 选择特征
- 选择一个机器学习算法
- 训练模型,使用development data调参
- 如有需要就把前面的几步重复
- 训练最后模型
- 使用test data评估模型
2.2 如何选择分类模型
- 考虑偏差(Bias)和方差(Variance) :
偏差:我们在模型中做出的假设
方差:对训练集的敏感程度
从Overfit和Underfit的角度来记这两个名词。Overfit(过拟合)就是得到的模型在某一数据集上表现太好了,基本百分百贴近,但是放到别的数据集上表现就极差,这个现象就可以说是偏差低,方差高;Underfit(欠拟合)就是这个模型怎么训练都烂,放在其他数据集也烂,那就是偏差高,方差低,本质原因就是模型就没选好。
然而我们希望模型在训练集上表现良好在别的数据也表现良好,就需要一个偏差低方差低的模型,但通常不会有这么完美的模型,所以就需要我们在两者之间权衡:偏差-方差权衡(Bias-Variance Tradeoff) 。 - 有一些最基础的假设,比如贝叶斯模型中最淳朴的假设就是事件之间相互独立,但放在前文提到的文章续写(特别看重前后文),贝叶斯表现肯定就一般。
- 复杂度
- 速度
2.3 朴素贝叶斯(Naïve Bayes)
贝叶斯公式:
P
(
y
∣
x
)
=
P
(
x
∣
y
)
P
(
y
)
P
(
x
)
P(y|x)=\frac{P(x|y)P(y)}{P(x)}
P(y∣x)=P(x)P(x∣y)P(y)
其中我们可以把
x
x
x看作待分类的对象,
y
y
y看作类别,理解为当待分类对象
x
x
x出现后,它是类别
y
y
y的概率有多少?
然后找出一个
y
^
\hat{y}
y^使得概率最高,那么这个
y
^
\hat{y}
y^就是分类结果。
y
^
=
a
r
g
m
a
x
y
∈
Y
P
(
y
∣
x
)
=
a
r
g
m
a
x
y
∈
Y
P
(
x
∣
y
)
P
(
y
)
P
(
x
)
=
a
r
g
m
a
x
y
∈
Y
P
(
x
∣
y
)
P
(
y
)
(
P
(
x
)
不
影
响
最
大
值
可
省
略
)
\begin{aligned} \hat{y} =& argmax_{y \in Y}P(y|x)\\ =& argmax_{y \in Y}\frac{P(x|y)P(y)}{P(x)} \\ =& argmax_{y \in Y}P(x|y)P(y) & (P(x)不影响最大值可省略) \end{aligned}
y^===argmaxy∈YP(y∣x)argmaxy∈YP(x)P(x∣y)P(y)argmaxy∈YP(x∣y)P(y)(P(x)不影响最大值可省略)
但一件事情、一个物品或者一句话它通常会被提取出很多特征,比如判断一台电脑是否适合做nlp,我们可能会去看电脑是否是独显、内存是否大、价格是否贵等等,从而判断电脑是否合适。所以把对象
x
x
x变成
x
1
,
x
2
,
.
.
.
,
x
m
x_1,x_2,...,x_m
x1,x2,...,xm个特征。
y
^
=
a
r
g
m
a
x
y
∈
Y
P
(
x
1
,
x
2
,
.
.
.
,
x
m
∣
y
)
P
(
y
)
\hat{y} = argmax_{y \in Y}P(x_1,x_2,...,x_m|y)P(y)
y^=argmaxy∈YP(x1,x2,...,xm∣y)P(y)
为了简单地得到这个式子的结果,我们做一个朴素的假设,假设特征之间毫无联系。
P
(
x
1
,
x
2
,
.
.
.
,
x
m
∣
y
)
P
(
y
)
≈
P
(
x
1
∣
y
)
P
(
x
2
∣
y
)
.
.
.
P
(
x
M
∣
y
)
=
P
(
y
)
∏
m
=
1
M
P
(
x
m
∣
y
)
P(x_1,x_2,...,x_m|y)P(y) \approx P(x_1|y)P(x_2|y)...P(x_M|y) = P(y)\prod_{m=1}^MP(x_m|y)
P(x1,x2,...,xm∣y)P(y)≈P(x1∣y)P(x2∣y)...P(xM∣y)=P(y)m=1∏MP(xm∣y)
优点:
- 训练和分类过程非常快
- 具有很好的鲁棒性,低方差。适用于低数据量情况
- 当独立假设是正确地时候,他就是最好的分类器之一
- 实现起来非常简单
缺点:
- 相互独立的假设很少成立
- 在大多数情况下,相比其他方法,它的准确率比较低
- 对于没有见过的 class/feature 组合需要smoothing
2.4 逻辑回归(Logistic Regression)
一个线性模型,通过softmax函数将输出“压缩到”(0, 1)之间,这样才能得到一个有效概率。
P
(
c
n
∣
f
1
…
f
m
)
=
1
Z
×
e
x
p
(
∑
i
=
0
m
w
i
f
i
)
P(c_n|f_1\dots f_m) = \frac{1}{Z}\times exp(\sum_{i=0}^mw_if_i)
P(cn∣f1…fm)=Z1×exp(i=0∑mwifi)
逻辑回归模型在训练过程中会最大化所有训练数据的概率,因此适合拟合数据,但同时也就会存在过拟合的风险。所以需要逻辑回归总会包含一个正则项(或者说惩罚项)使得权重降低或者稀疏。
优点:
不会像朴素贝叶斯那样被不同的、相关的特征所迷惑,在这种情况下逻辑回归会有更好的性能。
缺点:
- 训练过程慢
- 需要特征缩放,因为当不同特征之间的量级差别特别大的时候,逻辑回归结果就很差
- 需要很多训练数据
- 选择正则化策略(regularisation strategy)是很重要的,因为在逻辑回归这里过拟合是个大问题
2.5 支持向量机(Support Vector Machines)
找到一个超平面(hyperplane)可以将训练数据根据最大边际划分。
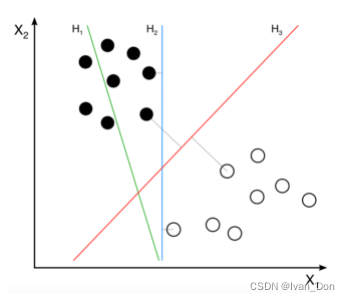
H
3
H_3
H3是比较好的hyperplane,相比
H
1
H_1
H1来说它分开了黑白点,相比
H
2
H_2
H2来说它和两个类别的距离更大更合理。
优点:
- 更快更准确的线性分类器
- 用不同内核(kernel trick)也可以实现非线性分类器
- 有大量特征数据集的时候能很好的工作
缺点:
- 多分类问题会有点笨拙
- 需要特征缩放
- 当数据集中类别分布不均匀时表现欠佳
- 可解释性较差
相比deep learning,为什么SVM在NLP中更受欢迎?
- 非线性的内核(kernel trick)对文本效果特别好
- NLP中特征缩放不是一个问题
- NLP数据集一般很大,并包含很多特征集,这也是SVM最喜欢的。
2.6 K 近邻(KNN)
根据最近的k个训练集样本特征中的多数来分类。
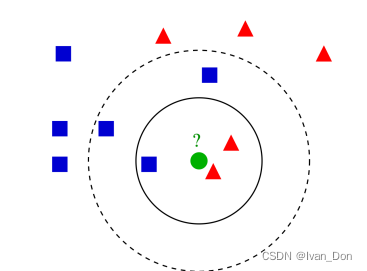
上图中绿点当看最近的三点,那么就会被分成红三角,当看最近的五点,则会被分成蓝正方。
距离定义公式可以不同:
一般会有欧拉距离(Euclidean distance)、余弦距离(Cosine distance)
优点:
- 简单但意外的有效
- 不需要训练集
- 本身就可以做多分类
- 对于无限数据集是个很好的分类器
缺点:
- 需要选择一个k
- 当数据的类别非常不平衡时会有问题
- 通常在找邻近点的时候非常慢
- 特征通常要小心选择,因为当数据越来越多的时候,特征集不能太大,不然计算的越来越慢
2.7 决策树(Decision Tree)
构建以可树,树上的每个节点(node)都对应一个独立的特点。
树叶(Leaves)是最终的决定。
基于相互信息(mutual information)的贪婪最大化(greedy maximization)
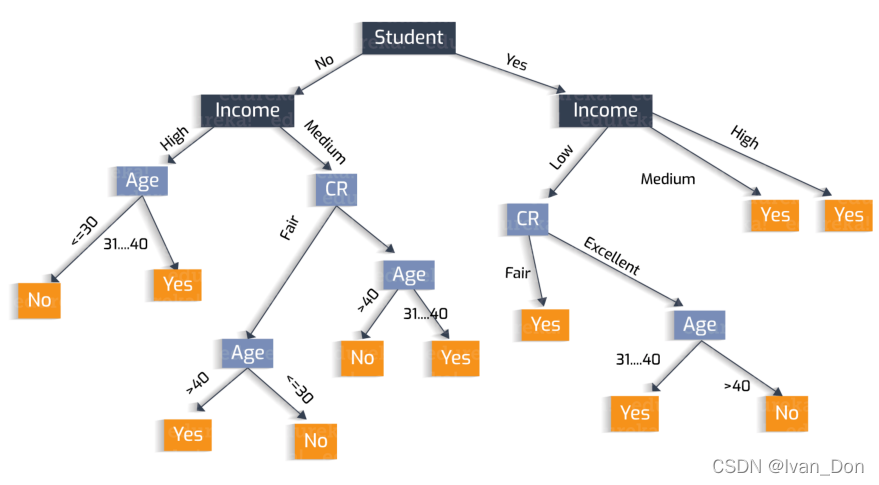
关于怎么选取哪个节点应该是什么特征,到时候会在其他文章讲到,大致意思会通过计算信息增益(information gain),得到这个特征区分样本的能力如何,IG越大能力就越强,就可以最先放入树。
优点:
- 能够快速搭建和测试
- 和特征缩放毫不相关
- 对于小的特征集是好的
- 可以处理非线性分割的问题
缺点:
- 可解释性可能不太好。当数据量很大包含很多特征时,不同特征的组合会导致树又大又深,很难发现其中的信息
- 会有很冗余的子树,因为特征之间可能存在依赖关系
- 当特征集很大的时候,相比其他模型没有竞争性
2.8 随机森林(Random Forests)
一种基于决策树的集合型分类器,它包含了很多决策树模型。这些决策树都是通过子集和子特征集训练出来的。
最终的类型是由这些子分类器通过众数投票决定的。
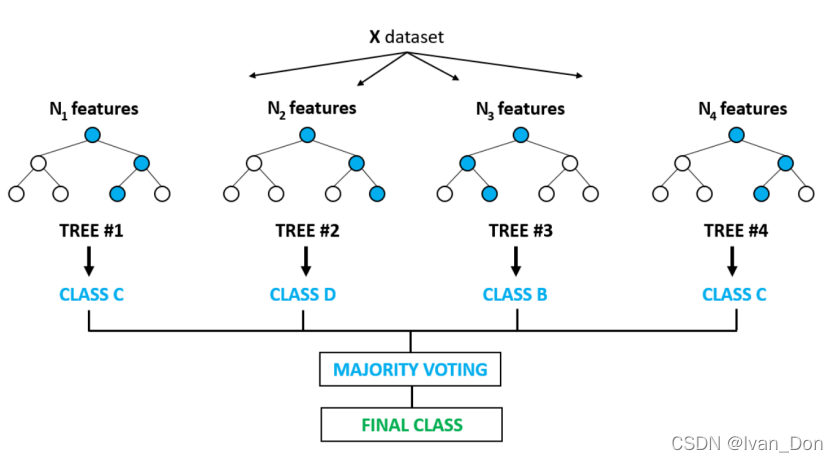
优点:
- 通常比决策树更准确也更鲁棒
- 对于中小型特征集效果不错
- 可以将训练平行化
缺点:
- 缺乏解释性
- 大型特征集处理起来很慢
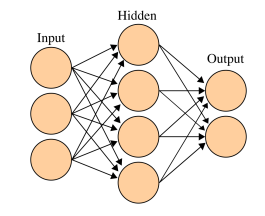
2.9 神经网络(Neural Networks)
一组相互连接的节点,被分配在不同的层。
输入层(特征),输出层(一个类别的概率),还有至少一层隐藏层。
每个节点对其来自上一层的输入进行线性加权,通过激活函数将结果传递给下一层的节点。
优点:
- 非常强大,nlphecv的主宰算法
- 只需要很小的特征工程
缺点:
- 不是一个现成(off-the-shelf)的分类器
- 有很多超参数,很难进行优化
- 训练起来很慢
- 容易出现过拟合
调参:
- 需要调参的数据集:
- Development set(验证集)
- 训练集和测试集不需要
- k 折交叉验证(k-fold cross-vallidation),适用于较少数据量的情况
- 特定的分类模型有特定的超参数,比如决策树中的树的深度
- 很多参数和正则化有关,正则化超参数会对模型的复杂度有所惩罚,经常是用来防止过拟合。
- 多个超参的时候,可以用grid search来调参(一次性尝试很多不同组合的参数)
3 评估(Evaluation)
3.1 准确性(Accuracy)
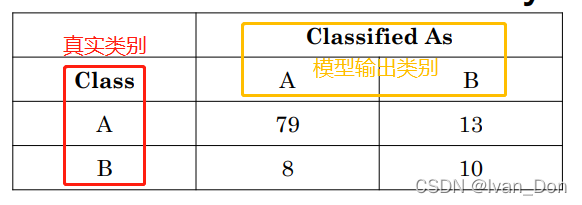
准确性 = 完全正确的分类 / 所有的分类
a
c
c
=
(
79
+
10
)
/
(
79
+
13
+
8
+
10
)
=
0.81
acc =(79+10) / (79+13+8+10) = 0.81
acc=(79+10)/(79+13+8+10)=0.81
通常我们在做预测的时候会有一个简单的baseline,就是把所有的类都预测成一个,比如说这里我们简单的就把所有预测见过设为A,因为原本这个数据集中就有 79 + 13 个A,那baseline的准确率就有
79
+
13
/
79
+
13
+
8
+
10
=
0.84
79 + 13 / 79+13+8+10 = 0.84
79+13/79+13+8+10=0.84。
所以说当训练集存在不平衡问题的时候,准确率就不是很好的评估指标。
3.2 精度和召回率(Precision & Recall)
假设分类B是Positive类别。
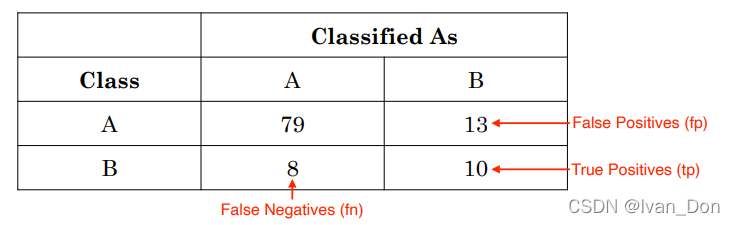
False Positive:本身不是B但是预测成了B(positive)
False Negative:本身是B但是预测成了A(Negative)。
True Positive:本身是B预测也是B
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
=
10
10
+
13
=
0.43
Precision = \frac{TP}{TP+FP} = \frac{10}{10+13} = 0.43
Precision=TP+FPTP=10+1310=0.43
R
e
c
a
l
l
=
T
P
T
P
+
F
N
=
10
10
+
8
=
0.56
Recall = \frac{TP}{TP+FN} = \frac{10}{10+8}=0.56
Recall=TP+FNTP=10+810=0.56
我们希望Recall和Precision的值都提高。
Recall:拿现在疫情为例,我们不希望一个小阳人核酸检测结果是阴性的吧,就是希望FN少一点,那这样Recall就高了。
Precision:以癌症为例子,如果说得了癌症是positive,那我们肯定不希望说我原本是健康的,但是医院给我检测出癌症,所以希望FP少一点,那Precision就高了。
3.3 F1 - score
将精度和召回率结合成一个指标:
F
1
=
2
×
p
r
e
c
i
s
i
o
n
×
r
e
c
a
l
l
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
F1 = \frac{2 \times precision \times recall}{precision + recall}
F1=precision+recall2×precision×recall
- 与精度和召回率一样,评估之前我们要确定一个类别是positive的。
- 但是可以作为一个通用的多类别指标
- 宏观平均(Macroaverage):不同类别之间的平均F值
通过分别计算类别A与类别B的F1,然后计算平均,这样可以平等地看待两个类别。 - 微观平均(Microaverage):利用计数累加和计算F值
当类别A、B的重要程度不一样时(根据出现的数量决定的),那我们可以采用此方法。
- 宏观平均(Macroaverage):不同类别之间的平均F值
虽然讲了这么多算法,但是如果能有一个标注很好的、类别丰富的大型数据集还是最重要的。
4 sklearn简单例子
以sklearn中路透社语料库(reuters corpus)为数据,调用现成的包来完成简单的文本分类。后期准备在机器学习部分手撕基本的代码。
路透社语料库:
简单介绍一下,它是新闻类的语料库,总共分了 90 个topics,数据集里面分为train和test两类。
reuter主要有三个属性 reuter.fileid,reuter.category,reuter.words。
# 显示的都是数据id,这里可以看到id前半段是会区分train和test
reuters.fileids()
# ['test/14826', 'test/14828', 'test/14829', 'test/14832', ...]
reuters.categories()
#['acq', 'alum', 'barley', 'bop', 'carcass', 'castor-oil', 'cocoa',
#'coconut', 'coconut-oil', 'coffee', 'copper', 'copra-cake', 'corn',
#'cotton', 'cotton-oil', 'cpi', 'cpu', 'crude', 'dfl', 'dlr', ...]
# 可以通过reuters.fileid(category)来查找这个topic下有哪些文章
reuters.fileids('barley')
#['test/15618', 'test/15649', 'test/15676', 'test/15728', 'test/15871', ...]
# 可以通过reuters.category(fileid)来查询这个文章属于什么topic
reuters.categories('training/9865')
# ['barley', 'corn', 'grain', 'wheat']
#可以通过reuters.words(categories/fileid)来查询这个topic下BOW内容,比如这个就给出'barley'类别下的bow有哪些
reuters.words('training/9865')[:14]
# ['FRENCH', 'FREE', 'MARKET', 'CEREAL', 'EXPORT', 'BIDS',
# 'DETAILED', 'French', 'operators', 'have', 'requested', 'licences', 'to', 'export']
reuters.words(['training/9865', 'training/9880'])
# ['FRENCH', 'FREE', 'MARKET', 'CEREAL', 'EXPORT', ...]
reuters.words(categories='barley')
#['FRENCH', 'FREE', 'MARKET', 'CEREAL', 'EXPORT', ...]
reuters.words(categories=['barley', 'corn'])
#['THAI', 'TRADE', 'DEFICIT', 'WIDENS', 'IN', 'FIRST', ...]
reuters有意思的是一篇新闻中往往会有多个主题,所以可能同一篇数据新闻会被标记在多个topic下。
导入语料库
import nltk
nltk.download("reuters") # if necessary
from nltk.corpus import reuters
假设我们现在把数据根据acq类来划分,分成是acq类和不是acq类。
from sklearn.feature_extraction import DictVectorizer
def get_BOW(text):
# 先得到一个文本的词袋,即这个文本中每个词的词频
BOW = {}
# 通常这里会用stemm或者lemma来统计,但这里没有
for word in text:
BOW[word] = BOW.get(word,0) + 1
return BOW
# 根据topic来找数据,并存下每个数据的bow,用于后期来预测某一个text是acq还是不是acq,做一个二值分类
def prepare_reuters_data(topic,feature_extractor):
training_set = []
training_classifications = []
test_set = []
test_classifications = []
# 遍历所有数据集file,里面有train 有test
for file_id in reuters.fileids():
# 得到这个数据集下的bow
feature_dict = feature_extractor(reuters.words(file_id))
if file_id.startswith("train"):
# 有多少train文件就有多少元素,每个元素是一个bow
training_set.append(feature_dict)
# 看看这个数据属不属于topic,标注是和不是
if topic in reuters.categories(file_id):
training_classifications.append(topic)
else:
training_classifications.append("not " + topic)
else:
# 区分测试集
test_set.append(feature_dict)
if topic in reuters.categories(file_id):
test_classifications.append(topic)
else:
test_classifications.append("not " + topic)
# 向量化,所有bow的长度为向量的长度,text中有这个词出现则为1,没有则为0,整个训练集是一个很稀疏的矩阵。
vectorizer = DictVectorizer()
# 保证训练集和测试集的向量长度相同,主要是通过忽略那些没有在training data中出现却在test中出现的单词。
training_data = vectorizer.fit_transform(training_set)
test_data = vectorizer.transform(test_set)
return training_data,training_classifications,test_data,test_classifications
trn_data,trn_classes,test_data,test_classes = prepare_reuters_data("acq",get_BOW)
然后通过不同分类模型进行10-fold cross validation得出每个模型的准确率如何。
from sklearn import model_selection
#from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import LinearSVC
from sklearn.linear_model import LogisticRegression
# 这里包含了6个没有调超参的模型
clfs = [KNeighborsClassifier(),DecisionTreeClassifier(),RandomForestClassifier(),
MultinomialNB(),LinearSVC(),LogisticRegression()]
# 普通的validation:将数据等类别比例的拆分成train和test,但这个会造成每次train和test数据不同,可能造成结果有偏差
# loocv,遍历整个数据,每次就留下一个作为test,其他都是train,但这样会很慢
# k-fold cv,把数据先分成k份,遍历k次,每次用其中一份作为test,剩下的k-1作为trian
# 关于k-fold的一些内容
"""
1、在训练模型时,如果已经预先指定好超参数了,这时候k交叉验证训练出来的模型只是不同数据训练出来的参数(权重)不同的相同结构的模型。
一些文章中预先指定了超参数,再用k交叉验证只能单单说明在这组超参数下,模型的准确率是这样的,并不能说明当下的这组超参数是比其他的好。
2、k交叉验证的用法是分别对自己想要尝试的n组超参数进行k交叉验证训练模型,然后比较n组超参数下用k交叉验证方法得到的n个平均误差,然后选出误差较小的那组超参数。
3、在做实验时,比如要比较不同学习算法的效果,要先分别对不同算法用k交叉验证方法确定一组较好的超参数,然后在测试集上比较他们的准确率
"""
# 简而言之就是用我给model的一组超参数,在不停变化的数据集上(不同的train、test组合方法)进行验证,每一次预测完都会有一个结果,然后对这些结果的值进行平均。
# 然后看这个平均值怎么样,如果好的话说明我的超参选的好。
def do_multiple_10foldcrossvalidation(clfs,data,classifications):
for clf in clfs:
predictions = model_selection.cross_val_predict(clf, data,classifications, cv=10)
print (clf)
print ("accuracy")
# 准确率是原数据的和预测的
print (accuracy_score(classifications,predictions))
print (classification_report(classifications,predictions))
do_multiple_10foldcrossvalidation(clfs,trn_data,trn_classes)
其实上述代码出来的结果中,KNN的结果是最差的,这是因为它特别容易受到具有与任务无关的维度的噪声特征空间的影响。所以我们刚刚的数据处理并不完整,需要对 BOW 先小写化,再进行lemmatize或者stemm,然后再过滤一遍停用词,这样才算最基础的预处理。
from nltk.corpus import stopwords
nltk.download('stopwords')
stopwords = stopwords.words('english')
def get_BOW_lowered_no_stopwords(text):
# 通常这个在一开始bow那边就要做的,把字母lower,避免大小字母还分不同单词。去除停用词
BOW = {}
for word in text:
word = word.lower()
if word not in stopwords:
BOW[word] = BOW.get(word,0) + 1
return BOW
trn_data,trn_classes,test_data,test_classes = prepare_reuters_data("acq",get_BOW_lowered_no_stopwords)
do_multiple_10foldcrossvalidation(clfs,trn_data,trn_classes)
解析树与抽象语法树:https://blog.csdn.net/qq_36097393/article/details/88866898 ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









