







前言:
Xpath是在XML文档中查找信息的一种语言,使用路径表达式来选取XML文档中的节点或节点集,由于XML与HTML结构类似(前者用于传输数据,后者用于显示数据),所以Xpath也常用于查找HTML文档中的节点或节点集。
####浏览器控制台下下用xpath调试:
1.查看元素是否找到,如果有返回一个列表:$x('xpath路径")][text()="项目总数"]')
2.实现点击:$x('xpath路径")][text()="项目总数"]')[0].click()
说明
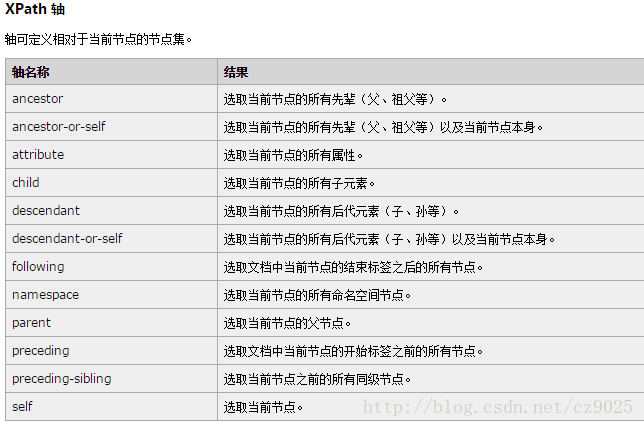
一 路径表达式:
- 路径以“/”开始 表示找到满足该绝对路径的元素;
- 路径以//”开始 表示找到文档中所有满足“//”后规则的元素 如//BBB 表示找到所有BBB元素;
- * 表示所有 如//* 表示选择所有元素;
- [表达式] 进一步限定元素:①[数字] 表示选择第几个, 其中[last()]表示最后一个;②[@属性] 限定满足该属性 ,如//BBB[@name] 表示含有name属性的BBB元素,//BBB[not(@*)]表示所有没有属性的BBB元素;拓展,属性赋值,如 /BBB[@name="yyy"] 表示所有含有name属性且其值为“yyy”的BBB元素;
- | 逻辑或 将多个路径合并到一起 如//BBB | /AAA 选择所有BBB元素和根元素AAA [可合并的路径数目没有限制]
二 辅助工具
Firefox浏览器用FireBug插件查看元素,还可以单击鼠标右键,选择copy Xpath。
Chrome浏览器就F12键就OK
IE浏览器可以一个小程序
xpath是可以解决网页自动化定位99%的问题。
如果一个元素没有id 没有name那我们该怎么定位该元素了,第一想到的就是用xpath了。
在网上copy了一段代码,就以这个做说明吧,xpath定位元素分相对路径和绝对路径,主要说明下相对路径的用法。
示例代码如下:
<html>
<body link="#0000cc">
<div id="wrapper" style="display: block;">
<div id="content" style="display: block;">
<div id="u1" style="display: block;">
<div id="m">
<p id="lg">
<p id="nv">
<div id="fm">
<form id="form" class="fm" action="/s" name="f1">
<span class="s_ipt_wr">
<input id="kw" type="text" name="wd">
......
</body>
</html>1、绝对路径定位(初级)
使用绝对路径的方式定位除非是其父级元素都没有一个唯一识别的元素才使用该方式;
假如要定位到输入框,那么使用绝对路径的方式为:
xpath= /html/body/div[1]/div[2]/div[1]/div[1]/form/span[1]/input
就是从根部开始找,一级一级往下走,如果有同级别的需要用[]标明序号,从1开始
2、相对路径定位(初级)
下面各方法中都是以定位到input做说明,以下不再说明。
2.1 元素本身找(@表示属性)
xpath=//input[@id=”kw” ] 或者xpath=//*[@id=”kw” ]
//input表示匹配input标签的所有元素
//*表示匹配所有元素的标签
当然不限于用id,也可以xpath=//*[@type=”text”]
注意:要保证这些元素可以唯一的识别一个元素
2.2 布尔值写法
如果input标签中 id不是唯一的,type也不是唯一的,但在该页面中包含该id和type的只有这个元素时,那么我们可以用组合的方式定位
xpath=//*[@id=”kw” and @type=”text”]
当然还有or 或,慎用
xpath=//*[@id=”kw” or @type=”text”]
2.3 找父级
如果自己没有唯一的标志,那么就找自己的上级(父级),或者上级的上级,以此类推。
找父级:xpath=//span[@class=’s_ipt_w’]/input
找父级的父级:xpath=//form[@id=”form”]/span[1]/input
2.4 跳级
如果需要定位的元素在该页面不是唯一,但在某个容器内是唯一的,当然那个容器必须要有唯一的标志;
跳级的话要用两个//
那么可以这样表示:xpath=//div[@id=”wrapper”]//input [@id=”kw”]
注意:该方法要保证在某容器内该元素是唯一的。
3.过滤(中阶方法)----Xpath函数
3.1.contains (): //div[contains(@id,'in')] ,表示选择id中包含有’in’的div节点
3.2.text():由于一个节点的文本值不属于属性,比如“<a class=”baidu“ href=”http://www.baidu.com“>baidu</a>”,所以,用text()函数来匹配节点://a[text()='baidu']
3.3.last():前面已介绍
3.4.starts-with(): //div[starts-with(@id,'in')] ,表示选择以’in’开头的id属性的div节点
3.5.not()函数,表示否定,//input[@name=‘identity’ and not(contains(@class,‘a’))] ,表示匹配出name为identity并且class的值中不包含a的input节点。 not()函数通常与返回值为true or false的函数组合起来用,比如contains(),starts-with()等,但有一种特别情况请注意一下:我们要匹配出input节点含有id属性的,写法如下://input[@id],如果我们要匹配出input节点不含用id属性的,则为://input[not(@id)]
4.轴(高阶方法)
following-sibling 选取当前节点之后同级节点。
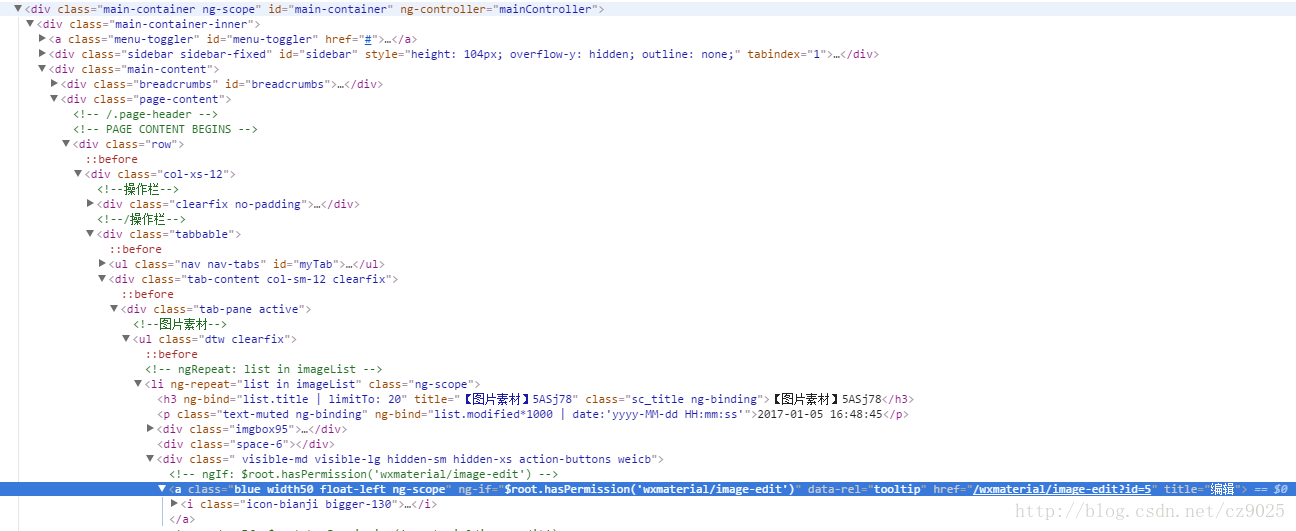
用我实际工作中的介绍下,如图:
要定位要编辑按钮(图片底部处)
假如要定位列表中的某些数据某个按钮,但不能确定他的位置在第一个还是第二个还是其他,那么可以用轴的方式定位;
xpath=//*[@id=”main-container”]//div[@class=”tabbable”]//li/h3[starts-with(text(),”【图片素材】”)]/ancestor::li[1]/div[3]/a[@title=”编辑”]
ancestor的前半部分,表示先定位到要找名称以“【图片素材】”开头的数据;后半部分定位到名称处后,再根据ancestor的功能(ancestor表示选取当前节点的所有先辈,那么要从名称处的父级开始定位)定位要需要定位的元素“编辑”按钮。
注意:该方法很实用,能定位到比较复杂的元素,还要加两个::
5.步(高阶方法)
语法:轴名称::节点测试[谓语]
这里介绍下last();上面的轴方法中,还存在一个问题就是,一条数据中图片数量不同的话,上面的方法又不能使用了,需用到步方法
xpath=//*[@id=”main-container”]//div[@class=”tabbable”]//li/h3[starts-with(text(),”【图片素材】”)]/ancestor::li[1]/div[last()]/a[@title=”编辑”]
因为编辑按钮在最后一个div中,所以前面不管有多少图片的话他总是会定位到最后一个,如果要定位要其他的则在()输入数字即可。
差不多了,用以上这些方式进行定位基本能应付常规工作中的定位了















 3736
3736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









