







这里写目录标题
- 深度学习入门
-
- 1.深度学习基础
-
- 1.1 深度学习与传统神经网络的区别
- 1.2 深度学习合适的目标函数
- 1.3 Softmax层
- 1.4 激活函数(Relu)
- 1.5 学习步长
- 1.6 关于SGD(随机梯度下降算法)的问题讨论(Deep Learning 最优化方法)
-
- 1.6.1 momentum(动量梯度下降法)
- 1.6.2 Nesterov momentum(牛顿动量)
- [1.6.3Adagrad(Adaptive Gradient)](https://blog.csdn.net/weixin_43378396/article/details/90743268?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164251153116780255215326%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164251153116780255215326&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-90743268.first_rank_v2_pc_rank_v29&utm_term=Adagrad&spm=1018.2226.3001.4187)
- 1.6.4 RMSprop
- 1.6.5 Adam( adaptive moment estimation,自适应矩估计)
- 1.6.6 各种梯度下降算法的比较
- 关于算法
- 总结几节课出现的代码
深度学习入门
1.深度学习基础
1.1 深度学习与传统神经网络的区别
1.2 深度学习合适的目标函数
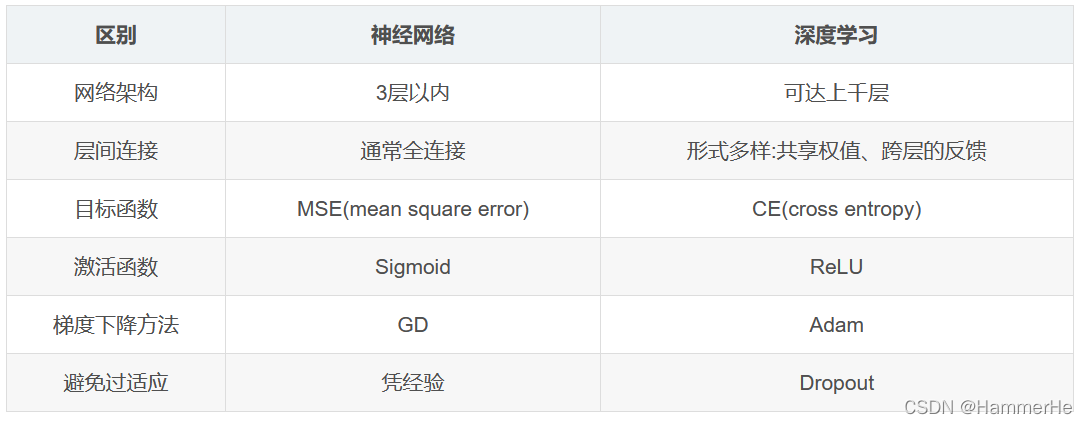
我们在传统神经网络里已经得到一种目标函数就是均方误差:
 但是在深度学习里面最常见的目标函数是交叉熵,如下图所示:
但是在深度学习里面最常见的目标函数是交叉熵,如下图所示:
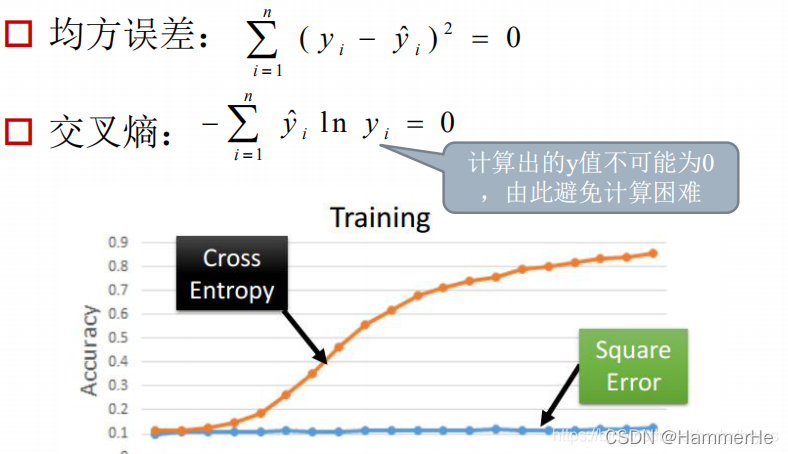 从上图可以的看到交叉熵收敛的比均方差快的多!!可以想象为交叉熵目标函数的最优值搜索空间的“地形”更“陡”,更有利于快速的找到最优值,如下图所示。
从上图可以的看到交叉熵收敛的比均方差快的多!!可以想象为交叉熵目标函数的最优值搜索空间的“地形”更“陡”,更有利于快速的找到最优值,如下图所示。
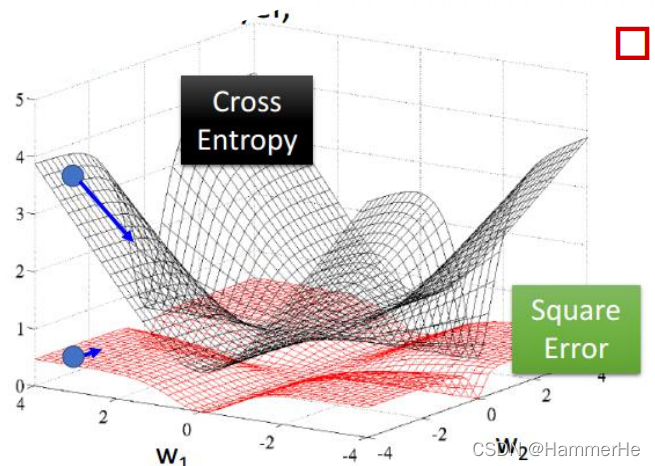
注意线性回归的时候均方差比较好用,但是作分类问题的时候交叉熵比较好用,因为交叉熵涉及到了概率的观念。
有关交叉熵的介绍
1.3 Softmax层
1.3.1Softmax层体现和作用?
在做分类预测的时候,经常会选择在神经网络的最后一层的输出结果上,加一个softmax层,来对输出结果进行分类。
如下图示在output layer后多出来的一个黑色的layer,就是用于分类的softmax层。最后紫色的new output层就是经过softmax层后,转换成概率的新输出层。
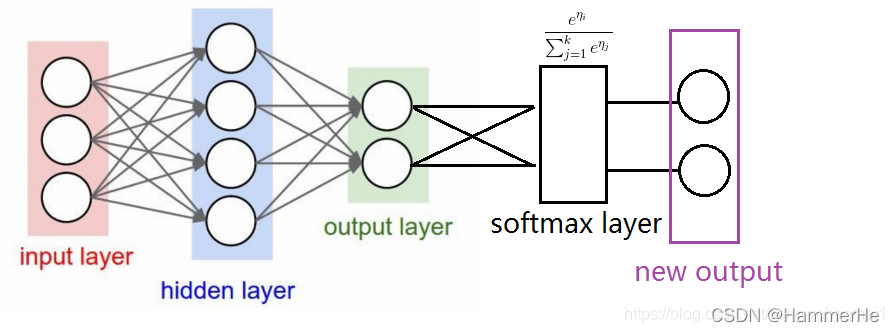 从这个图上可以看出来,softmax层只是对神经网络的输出结果进行了一次换算,将输出结果用概率的形式表现出来,而且它还起到了突出“最大值”的作用。
从这个图上可以看出来,softmax层只是对神经网络的输出结果进行了一次换算,将输出结果用概率的形式表现出来,而且它还起到了突出“最大值”的作用。
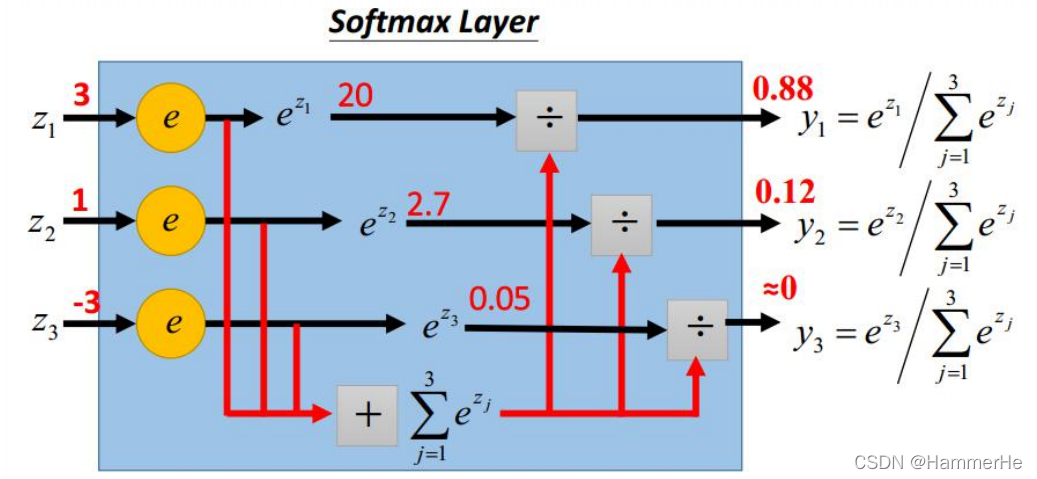
2 Softmax层的实现:
softmax层对L2层传来的数值进行一个换算,换算公式如下:
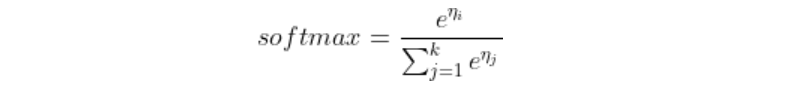 如下图我们最终会得到(3,1,-3)对一的概率是(0.88,0.12,0)且后者和为1:
如下图我们最终会得到(3,1,-3)对一的概率是(0.88,0.12,0)且后者和为1:
1.4 激活函数(Relu)
1.4.1 为什么不用tanh和Sigmoid(梯度消失的直观解释)

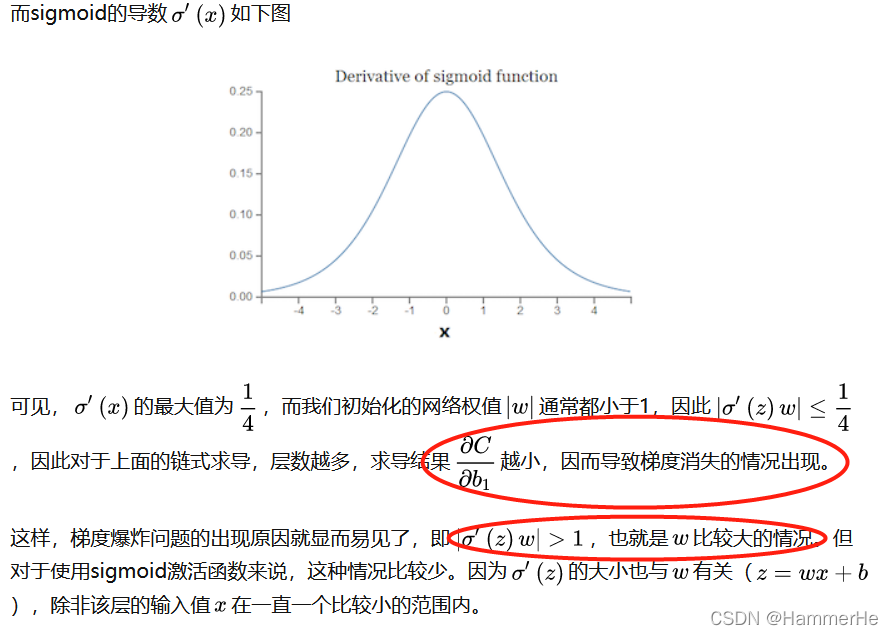
所以所谓的梯度消失和梯度爆炸就是:因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。
而对于更普遍的梯度消失问题,都是考虑用ReLU激活函数取代sigmoid激活函数。
1.4.2 Relu激活函数
之前已经介绍过了Relu函数和其导数如下
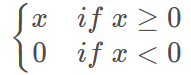
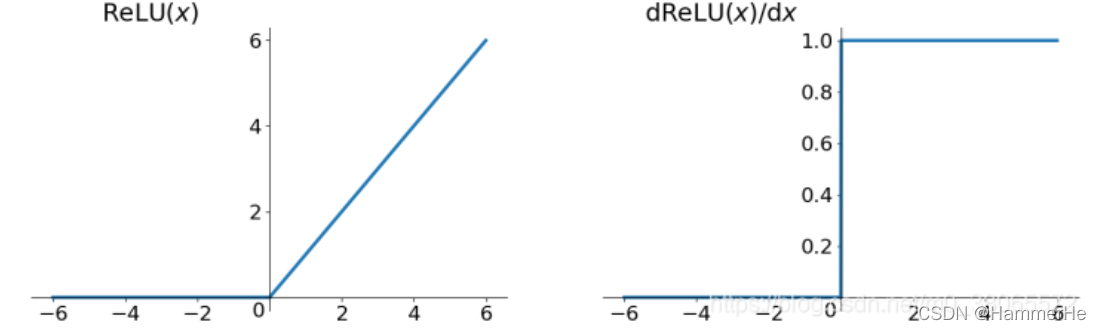
1.4.3 采用ReLU激活函数后
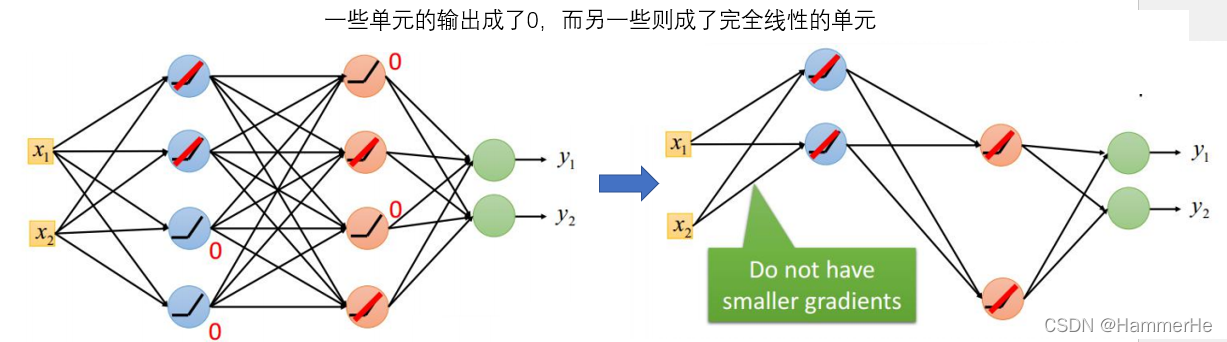 这也避免了调整各层权重时的“梯度消失”的问题。
这也避免了调整各层权重时的“梯度消失”的问题。
1.5 学习步长
学习步长的设置是个难题:若学习步长过大,则目标函数可能不降低;但若学习步长过小,则训练过程可能非常缓慢。
解决方法:训练几轮后就按一些因素调整学习步长。
介绍一种修改方法:
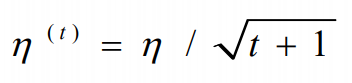 根据学习轮次t来对学习步长进行调整
根据学习轮次t来对学习步长进行调整
1.6 关于SGD(随机梯度下降算法)的问题讨论(Deep Learning 最优化方法)
(1)learning rate不易确定,如果选择的太小,收敛速度会很慢;如果太大,loss function 就会在极小值处不停地震荡甚至偏离。
(2)每个参数的 learning rate 都是相同的,如果数据是稀疏的,则希望对出现频率低的特征进行大一点的更新。
(3)深层神经网络之所以比较难训练,并不是因为容易进入局部最小,而是因为学习过程容易陷入到马鞍面中,在这种区域中,所有方向的梯度值都几乎是 0。
1.6.1 momentum(动量梯度下降法)
针对极小值处不停地震荡甚至偏离的问题引入动量的概念:
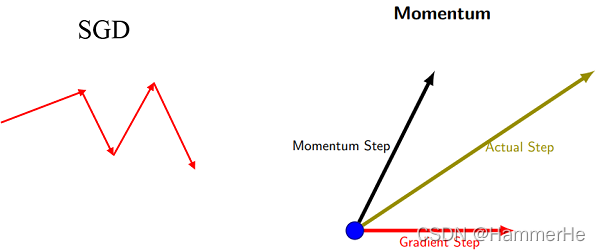 区别: SGD每次都会在当前位置上沿着负梯度方向更新(下降,沿着正梯度则为上升),并不考虑之前的方向梯度大小等等。而动量(moment)为了表示动量,引入了一个新的变量v。v是之前的梯度的累加,但每回合都有一定的衰减。
区别: SGD每次都会在当前位置上沿着负梯度方向更新(下降,沿着正梯度则为上升),并不考虑之前的方向梯度大小等等。而动量(moment)为了表示动量,引入了一个新的变量v。v是之前的梯度的累加,但每回合都有一定的衰减。
一个直观的解释动量梯度下降方法是:若当前的梯度方向与累积的历史梯度方向一致,则当前的梯度会被加强,从而这一步下降的幅度更大。若当前的梯度方向与累积的梯度方向不一致,则会减弱当前下降的梯度幅度。即前后梯度方向一致时,能够加速学习;前后梯度方向不一致时,能够抑制震荡。
实现方法:
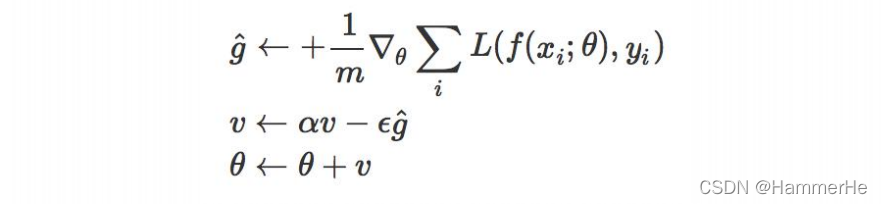
1.6.2 Nesterov momentum(牛顿动量)
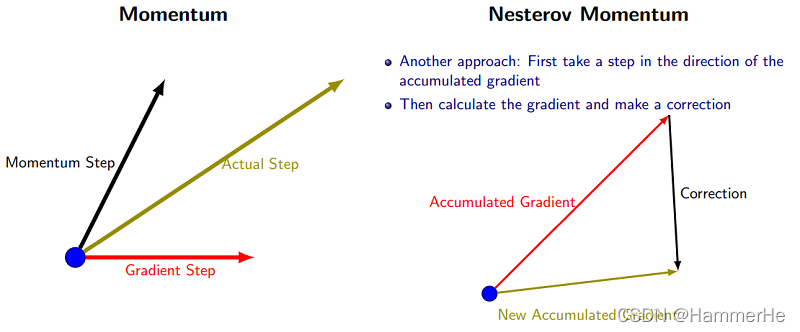
Nesterov Momentum是对Momentum的改进,可以理解为nesterov动量在标准动量方法中添加了一个校正因子。用一张图来形象的对比下momentum和nesterov momentum的区别:
 实现方法:
实现方法:
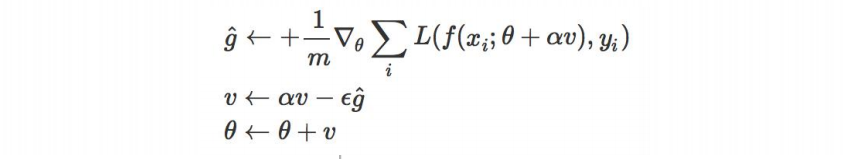 这个算法的运行速度比momentum要慢两倍,因此在实际实现过程中几乎没人直接用这个算法,而都是采用了变形版本。
这个算法的运行速度比momentum要慢两倍,因此在实际实现过程中几乎没人直接用这个算法,而都是采用了变形版本。
1.6.3Adagrad(Adaptive Gradient)
通常,我们在每一次更新参数时,对于所有的参数使用相同的学习率。而AdaGrad算法的思想是:每一次更新参数时(一次迭代),不同的参数使用不同的学习率。AdaGrad 的公式为:
 梯度越小,则学习步长越大,反之亦然。通俗的解释是:在缓坡上,可以大步地往下跑;而且陡坡上,只能小步地往下挪。
梯度越小,则学习步长越大,反之亦然。通俗的解释是:在缓坡上,可以大步地往下跑;而且陡坡上,只能小步地往下挪。
优点:对于梯度较大的参数, r相对较大,则θ较小,意味着学习率会变得较小。而对于梯度较小的参数,则效果相反。这样就可以使得参数在平缓的地方下降的稍微快些,不至于徘徊不前。
缺点:由于是累积梯度的平方,到后面 r累积的比较大,会导致梯度 趋向于0,导致梯度消失。
1.6.4 RMSprop
RMSprop是一种改进的Adagrad,通过引入一个衰减系数,让r每回合都衰减一定比例,从而使得梯度不会一直累加。这种方法很好的解决了Adagrad过早结束的问题,适合处理非平稳目标,对于RNN效果很好。
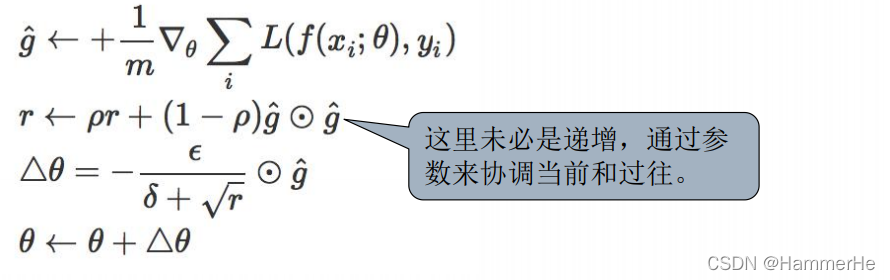
1.6.5 Adam( adaptive moment estimation,自适应矩估计)
Adam本质上是带有动量项的RMSprop,它利用梯度的一阶矩(momentum)估计和二阶矩(Adagrad,RMSprop)估计动态调整每个参数的学习率。
 一个有关动量,rmsprop,adam的帖子,内容很完整
一个有关动量,rmsprop,adam的帖子,内容很完整
1.6.6 各种梯度下降算法的比较
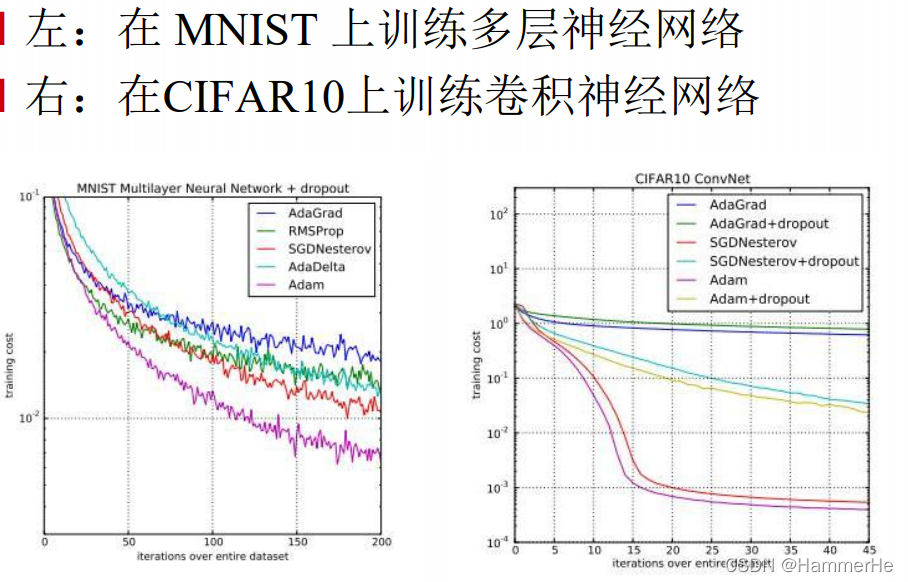 如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。通常,Adam 是最好的选择。
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然也能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。SGD相对稳定——据说老司机都是开手动挡的。
关于算法
(1)首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑 SGD+Nesterov Momentum或者Adam.
(2)选择熟悉的算法——这样可以更加熟练地利用经验进行调参。
(3)充分了解数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。
(4)根据需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
(5) 先用小数据集进行实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。因此可以先用一个具有代表性的小数据集进行实验。
(6)考虑不同算法的组合。先用Adam进行快速下降,而后再换到SGD进行充分的调优。
(7) 数据集一定要充分的打散(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。
(8)训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。对训练数据的监控是要保证模型进行了充分的训练;对验证数据的监控是为了避免出现过拟合。
(9)制定一个合适的学习率衰减策略。可以使用定期衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控。
总结几节课出现的代码
Grabcut的opencv实现
几个关键函数的解读:
(1)
grabCut(img, mask, rect, bgdModel, fgdModel, iterCount, mode=None)
img: 输入图像,必须是8位3通道图像,在处理过程中不会被修改
mask: 掩码图像,用来确定哪些区域是背景,前景,可能是背景,可能是前景等。GCD_BGD (=0), 背景; GCD_FGD (=1),前景;GCD_PR_BGD (=2),可能是背景;GCD_PR_FGD(=3),可能是前景。
rect: 包含前景的矩形,格式为(x, y, w, h)
bdgModel,fgdModel: 算法内部使用的数组,只需要创建两个大小为(1,65),数据类型为np.float64的数组
iterCount: 算法迭代的次数
mode: 用来指示grabCut函数进行什么操作:
cv.GC_INIT_WITH_RECT (=0),用矩形窗初始化GrabCut;
cv.GC_INIT_WITH_MASK (=1),用掩码图像初始化GrabCut。
(2)在图像上绘制矩形和圆形区域区域
cv.rectangle(img, (ix, iy), (x, y), BLUE, 2)
cv.circle(img, (x, y), thickness, value['color'], -1)
(3)创建鼠标响应事件
窗体对象是’input‘,响应函数是onmouse
cv.setMouseCallback('input', onmouse) # 创建鼠标响应事件
实现源码:
import numpy as np
import cv2 as cv
BLUE = [255, 0, 0] # rectangle color
RED = [0, 0, 255] # PR BG
GREEN = [0, 255, 0] # PR FG
BLACK = [0, 0, 0] # sure BG
WHITE = [255, 255, 255] # sure FG
DRAW_BG = {
'color': BLACK, 'val': 0}
DRAW_FG = {
'color': WHITE, 'val': 1}
DRAW_PR_FG = {
'color': GREEN, 'val': 3}
DRAW_PR_BG = {
'color': RED, 'val': 2}
# setting up flags
rect = (0, 0, 1, 1)
drawing = False # flag for drawing curves
rectangle = False # flag for drawing rect
rect_over = False # flag to check if rect drawn
rect_or_mask = 100 # flag for selecting rect or mask mode
value = DRAW_FG # drawing initialized to FG
thickness = 3 # brush thickness
def onmouse(event, x, y, flags, param):
global img, img2, drawing, value, mask, rectangle, rect, rect_or_mask, ix, iy, rect_over
# 以下为绘制矩形的整个阶段:鼠标右键按下,鼠标移动,鼠标右键松开
if event == cv.EVENT_RBUTTONDOWN:
rectangle = True
ix, iy = x, y
elif event == cv.EVENT_MOUSEMOVE:
if rectangle is True:
img = img2.copy()
cv.rectangle(img, (ix, iy), (x, y), BLUE, 2)
rect = (min(ix, x), min(iy, y), abs(ix - x), abs(iy - y))
rect_or_mask = 0
elif event == cv.EVENT_RBUTTONUP:
rectangle = False
rect_over = True
cv.rectangle(img, (ix, iy), (x, y), BLUE, 2)
rect = (min(ix, x), min(iy, y), abs(ix - x), abs(iy - y))
rect_or_mask = 0
print(" 如确定当前图无需再改按下'n' \n")
# 绘制细节
if event == cv.EVENT_LBUTTONDOWN:
if rect_over is False:
print("矩形区域还没有绘制!! \n" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1611
1611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









