






介绍
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个。Druid是阿里系提供的一个开源连接池,除在连接池之外,Druid还提供了非常优秀的数据库监控和扩展功能,所以在项目开发中一般会使用 Druid 。
Druid是阿里开源的一个JDBC应用组件,通过Druid连接池中间件, 可以实现的功能如下:
- 监控数据库访问性能,通过StatFilter插件,详细统计SQL的执行性能
- SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog 数据库密码加密。
思路
微服务环境下具体的思路如下:依赖放到common模块,然后需要用到的服务单独配置druid,不需要的服务则exclude掉来自common的相关依赖。
步骤
1、添加依赖
<!-- druid数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency>
2、相关配置
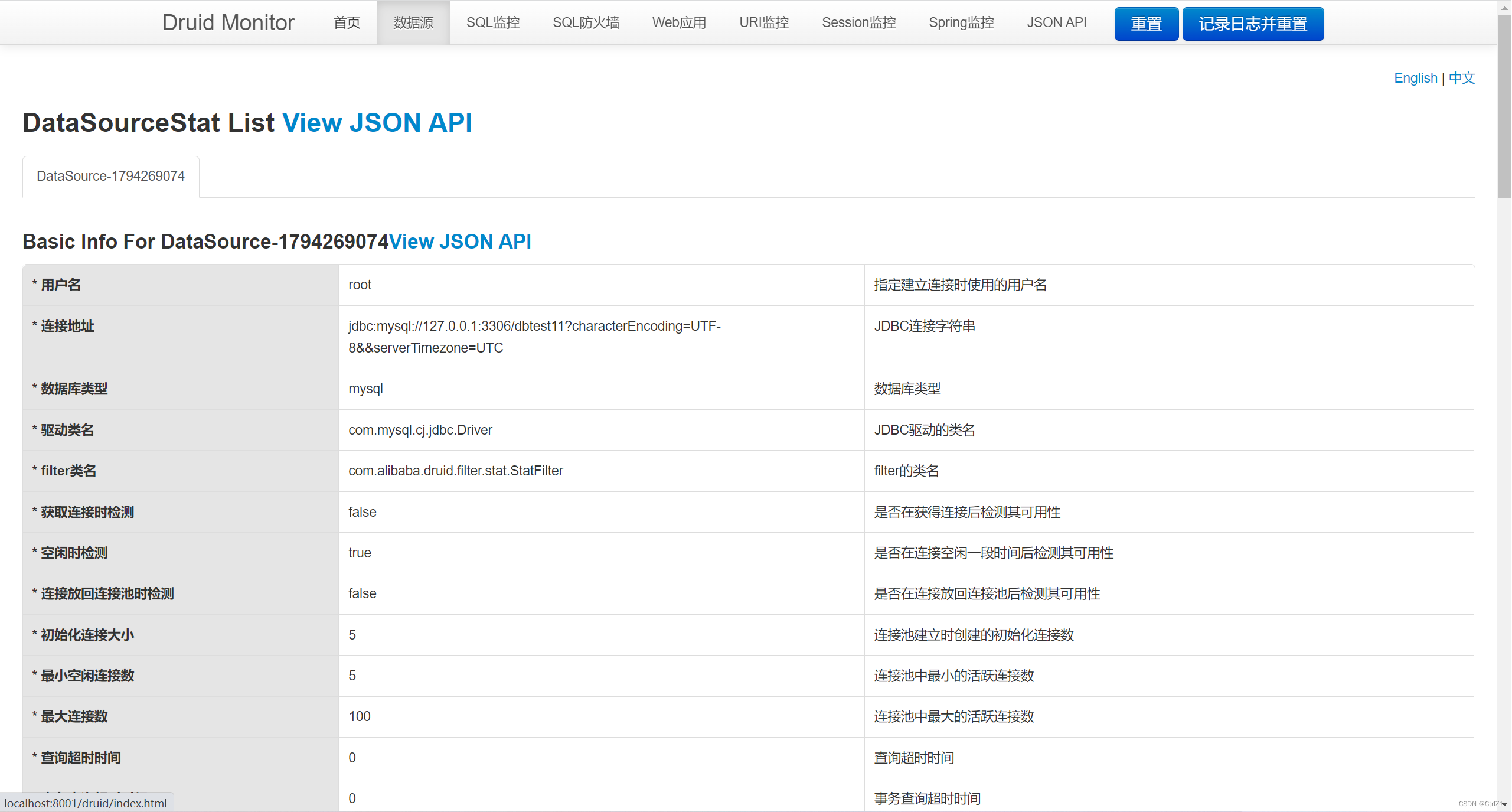
在 application.yml 中 把原有的数据源配置替换成 druid 数据源并配置数据源相关参数
spring:
datasource:
# 使用druid数据源
name: druidDataSource
type: com.alibaba.druid.pool.DruidDataSource
druid:
username: root
password: root
url: jdbc:mysql://127.0.0.1:3306/dbtest11?characterEncoding=UTF-8&&serverTimezone=UTC
#连接池初始化大小,最小值,最大值,
initial-size: 5
min-idle: 5
max-active: 100
#获取连接超时时间,单位:毫秒
max-wait: 10000
#是否缓存preparedStatement,对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭
pool-prepared-statements: false
#间隔多久检测一次需要关闭的空闲连接,单位:毫秒
time-between-eviction-runs-millis: 10000
#用来检测连接是否有效的sql
validation-query: SELECT 1 FROM DUAL
#检测连接是否有效的超时时间, 单位:秒
validation-query-timeout: 3
test-while-idle: true
#开启此配置会降低性能
test-on-borrow: false
test-on-return: false
#配置监控统计filter,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat
#配置监控统计filter的慢sql参数
filter:
stat:
log-slow-sql: true
slow-sql-millis: 80
merge-sql: true
3、配置Servlet和Filter
package com.lyy.yingwudemo.yingwu_member.configs;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.servlet.Filter;
import javax.servlet.Servlet;
/**
* @author :lyy
* @date : 04-03-20:32
*/
@Configuration
public class DruidConfig {
/**
* 注册Servlet信息, 配置监控视图
*
* @return
*/
/**
* Druid 提供了一个 StatViewServlet 用于展示 Druid 的统计信息
* 这个 StatViewServlet 的用途包括:
* 1. 提供监控信息展示的 HTML 页面
* 2. 提供监控信息的 JSON API
*/
@Bean
@ConditionalOnMissingBean
public ServletRegistrationBean<Servlet> druidServlet() {
ServletRegistrationBean<Servlet> servletRegistrationBean = new ServletRegistrationBean<Servlet>(new StatViewServlet(), "/druid/*");
//白名单:
servletRegistrationBean.addInitParameter("allow", "127.0.0.1");
//IP黑名单 (存在共同时,deny优先于allow) : 如果满足deny的话提示:Sorry, you are not permitted to view this page.
servletRegistrationBean.addInitParameter("deny", "192.168.1.119");
//登录查看信息的账号密码, 用于登录Druid监控后台
servletRegistrationBean.addInitParameter("loginUsername", "admin");
servletRegistrationBean.addInitParameter("loginPassword", "admin");
//是否能够重置数据.
servletRegistrationBean.addInitParameter("resetEnable", "true");
return servletRegistrationBean;
}
/**
* 注册Filter信息, 监控拦截器
*
* @return
*/
@Bean
@ConditionalOnMissingBean
public FilterRegistrationBean<Filter> filterRegistrationBean() {
FilterRegistrationBean<Filter> filterRegistrationBean = new FilterRegistrationBean<Filter>();
filterRegistrationBean.setFilter(new WebStatFilter());
//添加过滤规则.
filterRegistrationBean.addUrlPatterns("/*");
//添加不需要忽略的格式信息.
filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
return filterRegistrationBean;
}
}
为什么要配置servlet和拦截器,其实还是比较容易理解的,前者提供展示Druid监控的统计信息的页面,而拦截器当然是拦截相应的请求进行统计嘛。
资料参考网址:
https://blog.csdn.net/fly_west/article/details/122443046
https://zhuanlan.zhihu.com/p/614857719

















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











