






摘要: 阿里云大数据计算服务MaxCompute通过灵活性、简单性和创新为您企业的业务环境带来了变革,但是您企业是否通过其实现了原本预期的节省成本的目标呢?本文中,我们将为广大读者诸君介绍优化您企业MaxCompute开销的一些关键性的策略。
阿里云大数据计算服务MaxCompute通过灵活性、简单性和创新为您企业的业务环境带来了变革,但是您企业是否通过其实现了原本预期的节省成本的目标呢?本文中,我们将为广大读者诸君介绍优化您企业MaxCompute开销的一些关键性的策略。
自从MaxCompute于2010年进入市场以来,计算服务MaxCompute就已然永远地改变了整个IT世界了。尽管其价格优势已经领先业界了,但仍然有许多企业客户了解到,迁移到公共云服务并不总是能够帮助他们实现预期的成本节约的目标。
这并不意味着迁移到公共云服务是一个错误。公共云服务在敏捷性、响应性、简化操作和提高创新方面提供了巨大的优势。
这并不意味着迁移到公共云服务是一个错误。公共云服务在敏捷性、响应性、简化操作和提高创新方面提供了巨大的优势。
这方面的错误在于:假设在不实施管理和自动化的情况下迁移到公共云服务,也能带来成本的节约。为了应对不断上涨的云基础设施成本,我们建议您企业组织不妨参考和借鉴本文中所介绍的这些最佳实践方案,以减低和优化成本,并实现您企业环境的价值最大化。
接下来,我们主要从计算、存储、数据同步、日常账单分析几个点来展开优化实践,帮助企业做到节省预算。

优化控制计算成本
1、通过计费提醒估算计算成本
1.1 使用DataWorks 成本估计提醒
step1 通过DataWorks进入 Project工作区
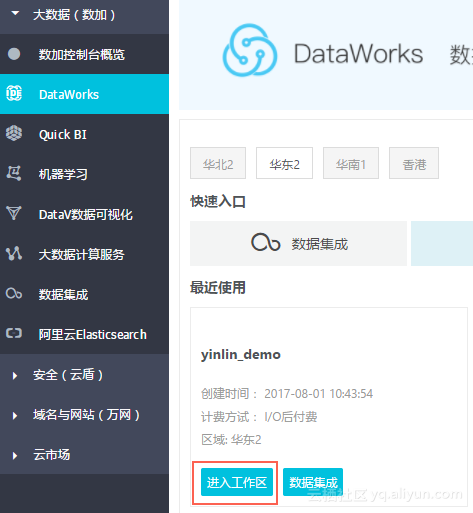
step2 进入数据开发
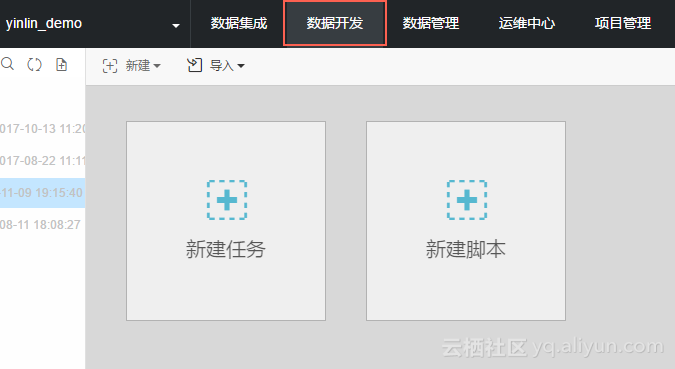
step3 新建脚本文件
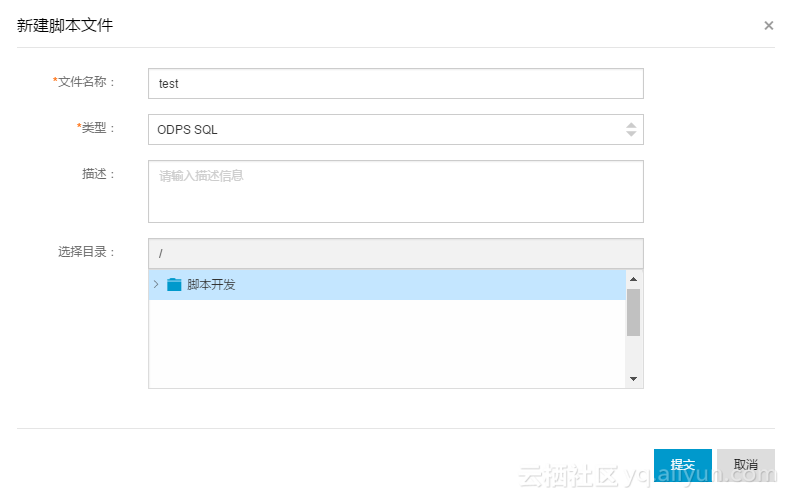
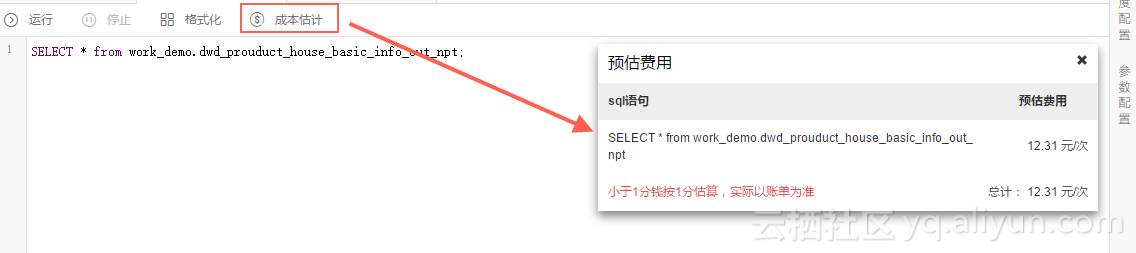
step4 输入SQL后,点击“成本估计“按钮。
1.2 使用Cost SQL费用计算
step1 启动MaxCompute客户端 ;安装及配置项目参照:https://help.aliyun.com/document_detail/27804.html
step2 输入cost +sql语句计费估算代码:
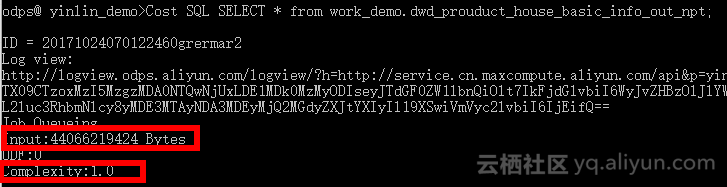
step3 根据返回的输入数据量*复杂度*0.3元/GB/复杂度估算价格。
Input:44066219424 Bytes/10243 x Complexity:1.0 x 0.3元/GB/复杂度 =12.31元
1.3 使用MaxCompute Stuido费用计算
step1 启动MaxCompute Stuido客户端 ;安装及配置项目参照:https://help.aliyun.com/document_detail/50892.html
step2 输入cost +sql语句计费估算代码获取估算量:
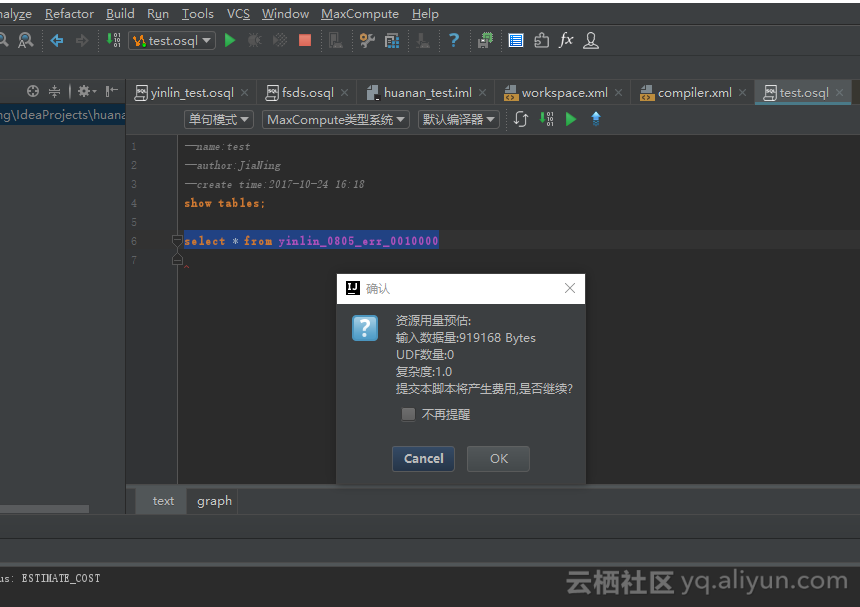
step3根据返回的输入数据量*复杂度*0.3元/GB/复杂度估算价格。Input:919168 Bytes/10243 x Complexity:1.0 x 0.3元/GB/复杂度 =2.57元
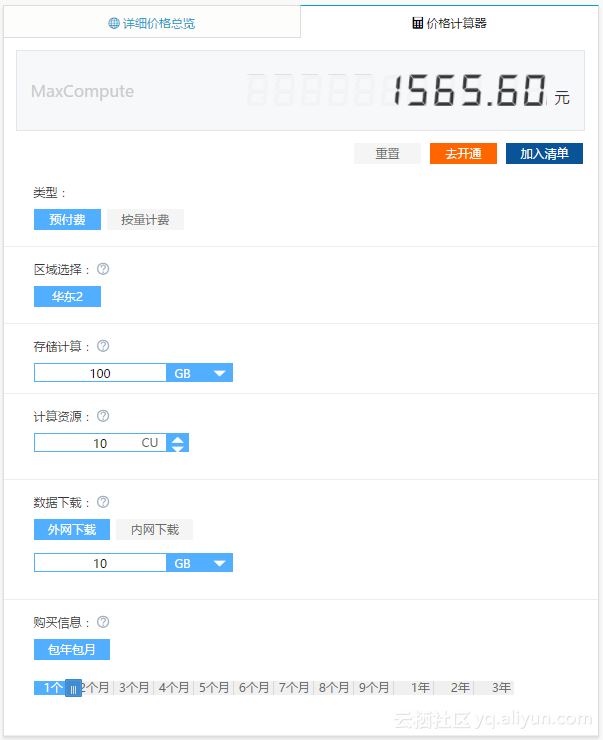
1.4 使用产品价格计算器
目前价格计算器支持预付费估算,
step1 打开计算器计算器:https://www.aliyun.com/price/product#/maxcompute/calculator
step2 输入所需要的存储数量量(GB、TB或PB)
step3 输入查询所需要的计算资源CU(最低10CU),输入数据下载量(GB、TB或PB),系统可以为您自动估算费用。
2、通过优化SQL来控制计算成本
做优化前,大家先来了解一下MaxCompute SQL的技术原理,对后续的优化工作会更加容易理解。
2.1 列裁剪
在读数据的时候,只读取查询中需要用到的列,而忽略其他列,避免使用select * 全表扫描引起的错误及资源浪费。例如,对于查询:
其中,T 包含 5 个列 (a,b,c,d,e),列 c,d 将会被忽略,只会读取a, b, e 列
2.2 分区裁剪
分区剪裁是指对分区列指定过滤条件,使得只读取表的部分分区数据,避免全表扫描引起的错误及资源浪费。例如,对于下列查询:
分区裁剪注意事情:
用户经常觉得已经对分区列做了限制了,但实际还是产生了大量费用。我们看一下如何做好分区裁剪,https://lark.alipay.com/eric.jia/maxcompute_0/ap0ei5
2.3 SQL关键字的优化
有一些优化方式官网上已经写出来了,比如避免使用select *,读取分区表时一定要对分区进行过滤。其他的优化方式就需要我们自己去摸索了。
计费的SQL关键字包括:Join / Group By / Order By / Distinct /窗口函数/ Insert into
减少full outer join的使用,改为union all;
在union all内部尽可能不使用group by,改为在外层统一group by;
临时导出的数据如果需要排序,尽量在导出后使用excel等工具进行排序,避免使用order by;
根据优化原则,尽量避免使用distinct关键字,改为多套一层group by;
尽量避免使用Insert into方式写入数据,可以考虑增加一个分区字段;
作用:通过降低SQL复杂度,来节省SQL的费用。
2.4 禁止全表扫描
您可以通过设置参数来关闭全表扫描功能,这样也可以避免过度资源浪费。
例如,
说明:限制扫描全表。默认情况下true,允许扫描全表;否则为false,如果扫描全表,则抛异常。
2.5 不要运行查询来探索或预览表数据
如果您想预览表数据,可以使用表预览选项查看数据,而不会产生费用。
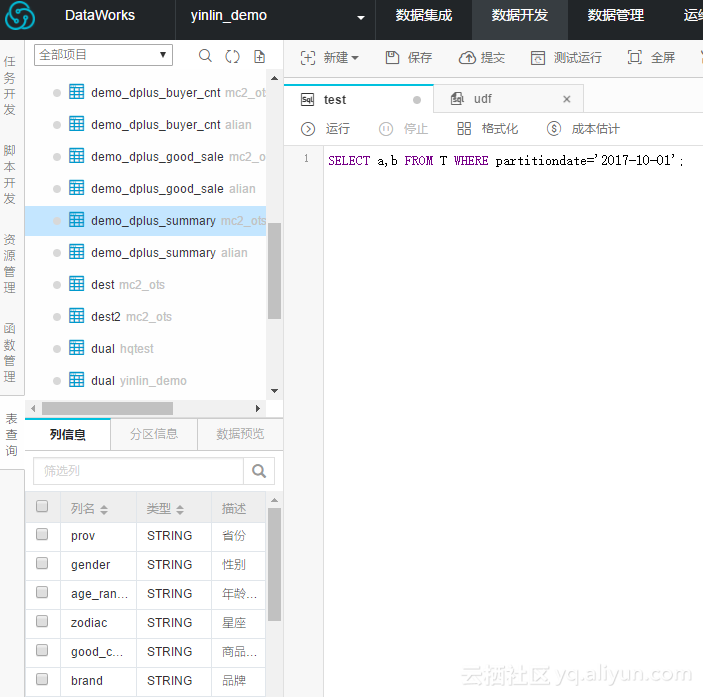
MaxCompute支持下列数据预览选项:
在DataWorks用户界面中,在数据开发-表查询信息页上,单击表进行数据预览。
在CLT使用read命令并指定预览的行数。

在MaxCompute Studio双击表进行表数据预览。

2.6 在通过MaxCompute计算和通过RDS计算中寻找平衡
由于MaxCompute的查询响应是分钟级,不适合直接用于前端查询。所以计算出的结果数据都会被保存到外部存储中,而对于大部分人来说,关系型数据库是最优先的选择。
所以这里就会涉及到一个“度”的问题。要把数据计算到什么程度,才会存放到MYSQL中?
(比如现在的用户登陆日志表、用户维度表)
(比如近一周各省份、地市登陆人数、近一周每天登陆人数、近一周每种注册渠道的登陆人数)
完全计算
直接出最终结果。前端展示时,不做任何判断、聚合、关联字典表、甚至不带where条件。
(结果表1:省份ID、省份名称、地市ID、地市名称、登陆人数)
(结果表2:日期、登陆人数)
(结果表3:注册渠道ID、注册渠道描述、登陆人数)
理解难度:1⭐
沟通难度:1⭐
MaxCompute费用:4⭐
下行流量:2⭐
离线数据维护成本:2⭐
适度计算
后续关联字段表等简单步骤直接在关系型数据库中计算
(结果表1:省份ID、地市ID、登陆人数)
(结果表2:日期、登陆人数)
(结果表3:注册渠道ID、登陆人数)
理解难度:2⭐
沟通难度:2⭐
MaxCompute费用:3⭐
下行流量:1⭐
离线数据维护成本:1⭐
轻度计算
后续大量计算任务直接在关系型数据库中计算
(结果表:用户ID、登陆日期、省份ID、地市ID、注册渠道ID)
理解难度:5⭐
沟通难度:5⭐
MaxCompute费用:2⭐
下行流量:5⭐
离线数据维护成本:1⭐
3、MR作业计算控制成本
做优化前,大家先来了解一下MapReduce的技术原理,对后续的优化工作会更加容易理解。https://help.aliyun.com/document_detail/27875.html?spm=5176.100239.blogcont78108.99.BPYOnj#h1-u5904u7406u6D41u7A0B
3.1 设置合理的参数
split size
map默认的split size是256MB,split size的大小决定了map的个数多少,如果用户的代码逻辑比较耗时,map需要较长时间结束,可以通过JobConf#setSplitSize方法适当调小split size的大小。然而split size也不宜设置太小,否则会占用过多的计算资源。
MapReduce reduce instance
单个 job 默认 reduce instance 个数为 map instance 个数的1/4,用户设置作为最终的 reduce instance 个数,范围 [0, 2000],数量越多,计算时消耗越多,成本越高,应合理设置。
3.2 MR减少中间环节
如果有多个MR作业,之间有关联关系,前一个作业的输出是后一个作业的输入,可以考虑采用Pipeline的模式,将多个串行的MR作业合并为一个,这样可以用更少的作业数量完成同样的任务,一方面减少中间落表造成的的多余磁盘IO,提升性能;另一方面减少作业数量使调度更加简单,增强流程的可维护性。具体使用方法参见Pipeline示例。
3.3 输入表的列裁剪
对于列数特别多的输入表,Map阶段处理只需要其中的某几列,可以通过在添加输入表时明确指定输入的列,减少输入量;
例如只需要c1,c2俩列,可以这样设置:
例如只需要c1,c2俩列,可以这样设置:
设置之后,你在map里的读取到的Record也就只有c1,c2俩列,如果之前是使用列名获取Record数据的,不会有影响,而用下标获取的需要注意这个变化。
3.4 避免资源重复读取
资源的读取尽量放置到setup阶段读取,避免资源的多次读取的性能损失,另外系统也有64次读取的限制,资源的读取参见使用资源示例。
3.5 减少对象构造开销
对于Map/Reduce阶段每次都会用到的一些java对象,避免在map/reduce函数里构造,可以放到setup阶段,避免多次构造产生的开销;
3.6 合理选择partition column或自定义partitioner
合理选择partition columns,可以使用JobConf#setPartitionColumns这个方法进行设置(默认是key schema定义的column),设置后数据将按照指定的列计算hash值分发到reduce中去, 避免数据倾斜导致作业长尾现象,如有必要也可以选择自定义partitioner,自定义partitioner的使用方法如下:
在jobconf里进行设置:
另外需要在jobconf里明确指定reducer的个数:
3.7 合理使用combiner
如果map的输出结果中有很多重复的key,可以合并后输出,combine后可以减少网络带宽传输和一定shuffle的开销,如果map输出本来就没有多少重复的,就不要用combiner,用了反而可能会有一些额外的开销。combiner实现的是和reducer相同的接口,例如一个WordCount程序的combiner可以定义如下:
4、计费模式转换
4.1 后付费转预付费
当后付费产生的账单超出您的企业预算时,您可以转换为预付费,将CU计算资源包月。
注意事项:请合理评估计算作业性能与时间关系,很多企业转为预付费后,由于购买的CU数量少,作业计算周期长,达不到预期,又转回后付费。
合理预估预付费CU资源方法参照(仅供参考):
SQL估算资源建议:show -p后,通过logview查看历史作业平均消耗的worker数量,一个worker 近似1CU;
MR估算资源建议:show -p后,通过logview查看历史作业平均消耗的cost * min计算时,cost数量近似CU。
4.2 预付费+后付费混合模式
当企业预算有限时,可以选择此模式,将非周期性的大规模数据处理作业放到后付费模式上。将周期性的消耗计算资源少的作业放到预付费模式。数据可以存储在预付费模式下,后付费模式不用存储数据,通过跨表计算省去一份存储成本。注意:不同账号下跨表计算需要通过Grant授权来实现,参考:https://help.aliyun.com/document_detail/27927.html
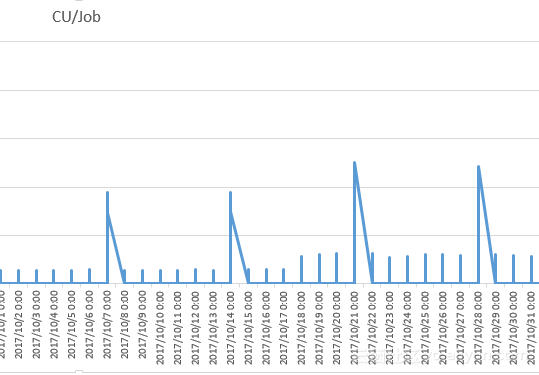
案例分析:这个案例是后付费月账单1万元的3个月计算消耗明细,Max最大200CU,平时用到30CU;
此方案的结构可以优化为:
最经济型:月4500元(30CU,不预留水位)+1800 元(1000GB数据*1.5复杂度*0.3元/GB/复杂度*4次),节节省:3700元/月,虽然节省较多,但数据业务的增长会遇到水位线瓶颈,需要定期扩展CU。
次经济性:月7500元(50CU,预留30%水位)+1800 元(1000GB数据*1.5复杂度*0.3元/GB/复杂度*4次)
节省:节省800元/月,虽然节省少,但资源还比原来更充裕了。
优化控制存储成本
1、设置合理的表生命周期
MaxCompute中存储资源是非常宝贵的。可以根据数据本身的使用情况,对表设置生命周期,MaxCompute会及时删除超过生命周期的数据,达到节省存储空间的目的。比如
创建一张生命周期为100的表。如果这张表或者分区的最后修改时间超过了100天将会被删掉。需要注意的是生命周期是以分区为最小单位的,所以一个分区表,如果部分分区达到了生命周期的阀值,那么这些分区会被直接删掉,未达到生命周期阀值的分区不受影响。
另外可以通过命令
另外可以通过命令
修改已经创建好的表的生命周期。
2、合理设置数据分区
MaxCompute将分区列的每个值作为一个分区(目录)。用户可以指定多级分区,即将表的多个字段作为表的分区,分区之间正如多级目录的关系。在使用数据时如果指定了需要访问的分区名称,则只会读取相应的分区,避免全表扫描,提高处理效率,降低费用。
假如最小统计周期为天,宜采用日期作为分区字段。每天将数据覆盖迁移到指定分区,再读取指定分区的数据进行下游统计。
假如最小统计周期为小时,宜采用日期+小时作为分区字段。每小时将数据覆盖迁移到指定分区,再读取指定分区的数据进行下游统计。若小时调度的统计任务也按天分区,数据每小时追加,则每小时将多读取大量的无用数据,增加的流入数据量,增加了不必要的费用。
分区字段不一定非得是时间,根据实际需要,也可以使用其他的枚举值个数相对固定的字段,比如渠道、比如国家省份地市。或者使用时间和其他字段共同作为分区字段。
优化控制数据同步成本
1、尽可能使用经典网络和VPC网络
通过使用内部网络(经典网络、VPC)实现零成本数据导入、导出。
2、合理利用ECS的公共下载资源
很多企业客户ECS带宽是包月的,可以使用Tunnel等数据同步工具,将MaxCompute数据同步到ECS上,然后下载到本地。下载方法参考:
3、Tunnl文件上传优化
当文件量小的时候,会消耗更多计算资源参与计算,建议文件量积累较大时一次性上传,比如,用户在调用tunnel sdk时当buffer达到64M时提交一次。
分析账单与明细
1、账单及时查看
养成定期查看账单的好习惯,及时优化使用成本。通过阿里云控制台-消费-消费记录-消费明细,查看MaxCompute/odps每日计费清单及账单(计算、存储、下载)明细。
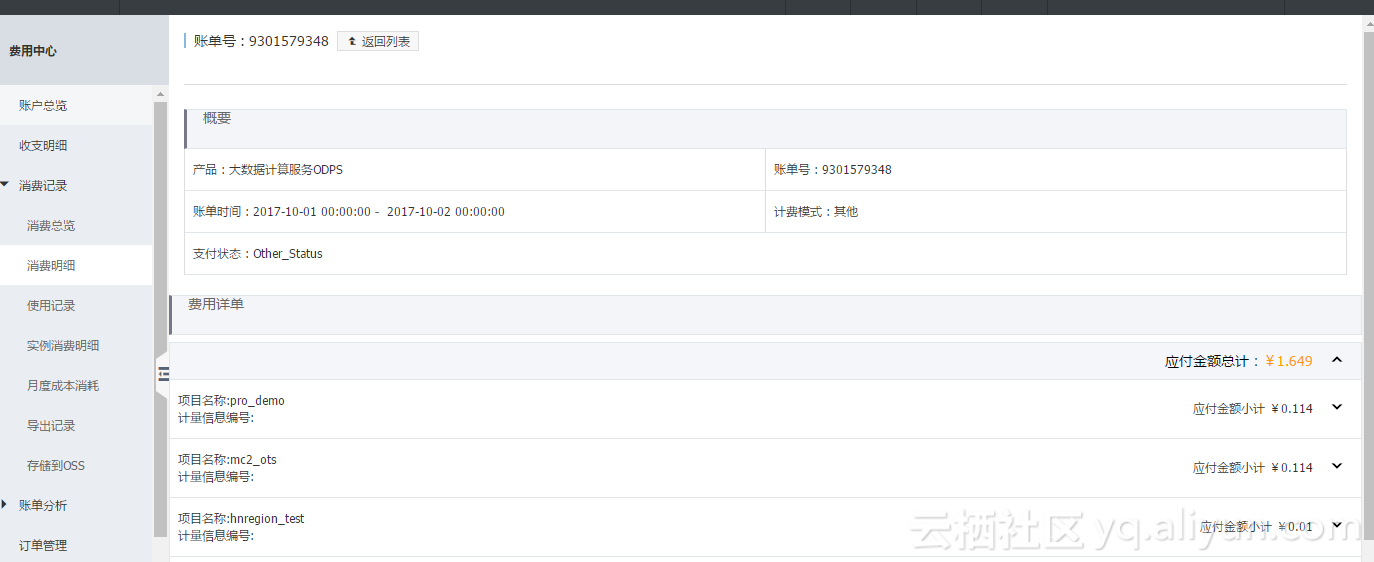
案例分析:
场景1,查看昨天的收费情况
出账后,通过控制台消费明细来查看。
出账时间:
预付费出账单时间次日12点
后付费出账单时间是次日9点
step1 进入阿里云控制台-消费,https://expense.console.aliyun.com/#/
step2打开消费总览,看到当月账单。

step3点击左侧消费明细,根据产品分类Maxcompute及时间来筛选昨天的消费金额,https://expense.console.aliyun.com/#/consumption/list/flow/afterpay

step4点击详情,展开每个项目的消费情况,查看有无“贵”收费

如发现“贵“的项目,可根据存储、计算、下载几个场景对应到下面的解决方法。
场景2,分析某一天计算收费“贵“原因
通过导出使用记录,分析消费多的作业instance具体情况。

step1打开消费明细后,看到账单异常后,请到左侧消费记录下载导出使用记录。

step2下载记录后,打开excel表,定位异常数据的instanceid。
比如,计量信息编号20171106100629865g4iplf9这个SQL任务,产生的费用是SQL读取量(7352600872/1024/1024/1024)*SQL复杂度 1 * 0.3元/GB/复杂度=2元 ,计算公式参考官网:https://help.aliyun.com/document_detail/27989.html?spm=5176.product27797.6.559.QL7dYV#h2-u6309u91CFu540Eu4ED8u8D39

step3查看这个“贵”instanceID 的logview
wait 20171106100629865g4iplf9

step4通过Logview我们发现产生了全表扫描、长尾计算等问题,及时优化我们的SQL/MR作业。

长尾优化参考:
场景3,分析存储收取1分钱的原因
通过导出使用记录,分析消费多的存储Storeage明细。
step1 下载记录后,打开excel表。

step2 查看数据分类中的Storage,会发现在yinlin_test_huabei2_io Project下存储了384字节数据。
按照官网存储定价规则,存储(384/1024/1204)*0.0192元/GB不到1分钱,但官网提到小于等于512M数据最低收取1分钱。计算公式参考官网:https://help.aliyun.com/document_detail/27989.html?spm=5176.product27797.6.559.QL7dYV#h1-u5B58u50A8u8BA1u8D39

step3 如果这份数据是用来测试的,你可以通过IDE删除Project下的表数据。
场景4,分析数据上传和下载是否产生了费用
部分用户总担心数据同步会产生费用,我们可以通过分析账单来解决。
step1 点击消费明细详情,查看上行、下载有无收费。
我们可以看到收费明细里面并没有上行计费项,所以用户不必担心数据上传产生了费用。
同时,我们看到了下载产生了0.12元。
step2 通过导出使用记录,分析消费多的下载消耗明细。

step3 可以看到公网下行流量产生了一条约0.153GB(164223524byte)的下行流量,根据官网收费标准,0.153GB*0.8 元/GB=0.12元。计费公式参考:https://help.aliyun.com/document_detail/27989.html?spm=5176.product27797.6.559.QL7dYV#h1-u4E0Bu8F7Du8BA1u8D39
step4 下行优化
a 查看你的tunnel设置的service,是否设置成了公共网络。参考:https://help.aliyun.com/document_detail/34951.html
b 如果你本地在苏州,Region在华东2上海,那么你可以先通过华东2的ECS把数据下载到虚机,然后利用ECS包月下载资源。
结论
重要的是要记住,这些最佳实践方法并不意味着是一次性的活动,而是持续性的过程。由于大数据的动态性和不断变化的性质,企业用户成本优化的活动最好应不断进行。

















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









