







 本文通过分析kaggle上的学生成绩数据,利用线性回归模型预测成绩。研究涉及数据预处理、相关性分析和模型训练。发现失败次数、父母教育水平和学生升学意愿对成绩有显著影响。
本文通过分析kaggle上的学生成绩数据,利用线性回归模型预测成绩。研究涉及数据预处理、相关性分析和模型训练。发现失败次数、父母教育水平和学生升学意愿对成绩有显著影响。
通过训练集训练和测试集测试来生成多个线性模型,从而预测学生成绩,本文所有代码请点击Github
1. 实验数据背景
1.1 数据来源
本项目的数据来源于kaggle.com,数据集的名称为Student Grade Prediction,Paulo Cortez,Minho大学,葡萄牙吉马良斯,http://www3.dsi.uminho.pt/pcortez
1.2 数据简介
该数据接近了两所葡萄牙学校的中学学生的学习成绩。数据属性包括学生成绩,人口统计学,社会和与学校相关的特征),并通过使用学校报告和调查表进行收集。提供了两个关于两个不同学科表现的数据集:数学(mat)和葡萄牙语(por)
该数据集共有396条,每列33个属性,属性简介如下:
1.学校-学生学校(二进制:“ GP”-加布里埃尔·佩雷拉(Gabriel Pereira)或“ MS”-Mousinho da Silveira)
2.性别-学生的性别(二进制:“ F”-女性或“ M”-男性)
3.年龄-学生的年龄(数字:15至22)
4.地址-学生的家庭住址类型(二进制:“ U”-城市或“ R”-农村)
5.famsize-家庭大小(二进制:“ LE3”-小于或等于3或“ GT3”-大于3)
6.Pstatus-父母的同居状态(二进制:“ T”-同居或“ A”-分开)
7.Medu-母亲的教育(数字:0-无,1-初等教育(四年级),2 – 5至9年级,3 –中等教育或4 –高等教育)
8.Fedu-父亲的教育(数字:0-无,1-初等教育(四年级),2 – 5至9年级,3 –中等教育或4 –高等教育)
9.Mjob-母亲的工作(名义:“教师”,“与健康”有关的,民事“服务”(例如行政或警察),“在家”或“其他”)
10.Fjob-父亲的工作(名义:“教师”,“与健康”相关的,民事“服务”(例如行政或警察),“在家”或“其他”)
11.理由-选择这所学校的理由(名义:接近“家”,学校“声誉”,“课程”偏好或“其他”)
12.监护人-学生的监护人(名词:“母亲”,“父亲”或“其他”)
13.traveltime-学校到学校的旅行时间(数字:1-<15分钟,2-15至30分钟,3-30分钟至1小时或4-> 1小时)
14.学习时间-每周学习时间(数字:1-<2小时,2-2至5小时,3-5至10小时或4-> 10小时)
15.失败-过去类失败的次数(数字:如果1 <= n ❤️,则为n,否则为4)
16.schoolup-额外的教育支持(二进制:是或否)
17.famsup-家庭教育支持(二进制:是或否)
18.付费-课程主题内的额外付费课程(数学或葡萄牙语)(二进制:是或否)
19.活动-课外活动(二进制:是或否)
20.托儿所-上托儿所(二进制:是或否)
21.更高-想要接受高等教育(二进制:是或否)
22.互联网-在家上网(二进制:是或否)
23.浪漫-具有浪漫关系(二进制:是或否)
24.家族-家庭关系的质量(数字:从1-非常差到5-极好)
25.空闲时间-放学后的空闲时间(数字:从1-非常低到5-非常高)
26.外出-与朋友外出(数字:从1-非常低到5-非常高)
27.Dalc-工作日酒精消耗(数字:从1-非常低到5-非常高)
28.Walc-周末酒精消耗(数字:从1-非常低至5-非常高)
29.健康-当前的健康状况(数字:从1-非常差到5-非常好)
30.缺勤-缺勤人数(数字:0到93)
这些成绩与课程主题(数学或葡萄牙语)相关:
31.G1-第一期成绩(数字:0至20)
32.G2-第二学期成绩(数字:0至20)
33.G3-最终成绩(数字:0到20,输出目标)
2. 研究思路
数据集中存在不少非数值型数据,所以在进行建模之前要进行数据清洗,主要是抛弃掉一些非相关性数据以及缺失值处理,对数据进行分析的时候要注意其中是否有缺失值。
一些机器学习算法能够处理缺失值,比如神经网络,一些则不能。对于缺失值,一般有以下几种处理方法:
(1)如果数据集很多,但有很少的缺失值,可以删掉带缺失值的行;
(2)如果该属性相对学习来说不是很重要,可以对缺失值赋均值或者众数。
(3)对于标称属性,可以赋一个代表缺失的值,比如‘U0’。因为缺失本身也可能代表着一些隐含信息。
(4)使用回归 随机森林等模型来预测缺失属性的值。因为Age在该数据集里是一个相当重要的特征(先对Age进行分析即可得知),所以保证一定的缺失值填充准确率是非常重要的,对结果也会产生较大影响。一般情况下,会使用数据完整的条目作为模型的训练集,以此来预测缺失值。对于当前的这个数据,可以使用随机森林来预测也可以使用线性回归预测。这里使用随机森林预测模型,选取数据集中的数值属性作为特征(因为sklearn的模型只能处理数值属性,所以这里先仅选取数值特征,但在实际的应用中需要将非数值特征转换为数值特征)
数据规范化后方可进行数据分析,本项目将首先拿出一些特定属性,通过绘制图标的形式单独分析该属性反映出来的信息,试图分析该属性对结果的影响。
最后将对全部数据建立线性模型,并把数据集分为训练集和测试集,以测试模型的准确性。
3. 具体步骤
3.1 数据总体分析
利用padans库的read_csv函数,可以读取数据集:
# 初始化数据
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
student = pd.read_csv('student-mat.csv')
格式化后展示如图3-1-1
3.2 利用图表分析属性
3.2.1各分数段学生计数
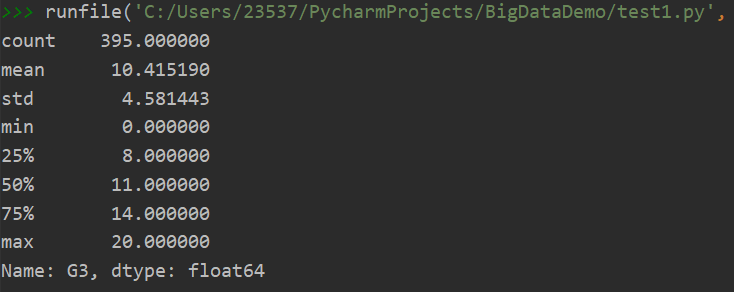
对学生期末成绩直接分析,可以得出成绩的大致分布,那么后文在分析其他因素对成绩的影响时也会更有针对性
# 根据人数多少统计各分数段的学生人数
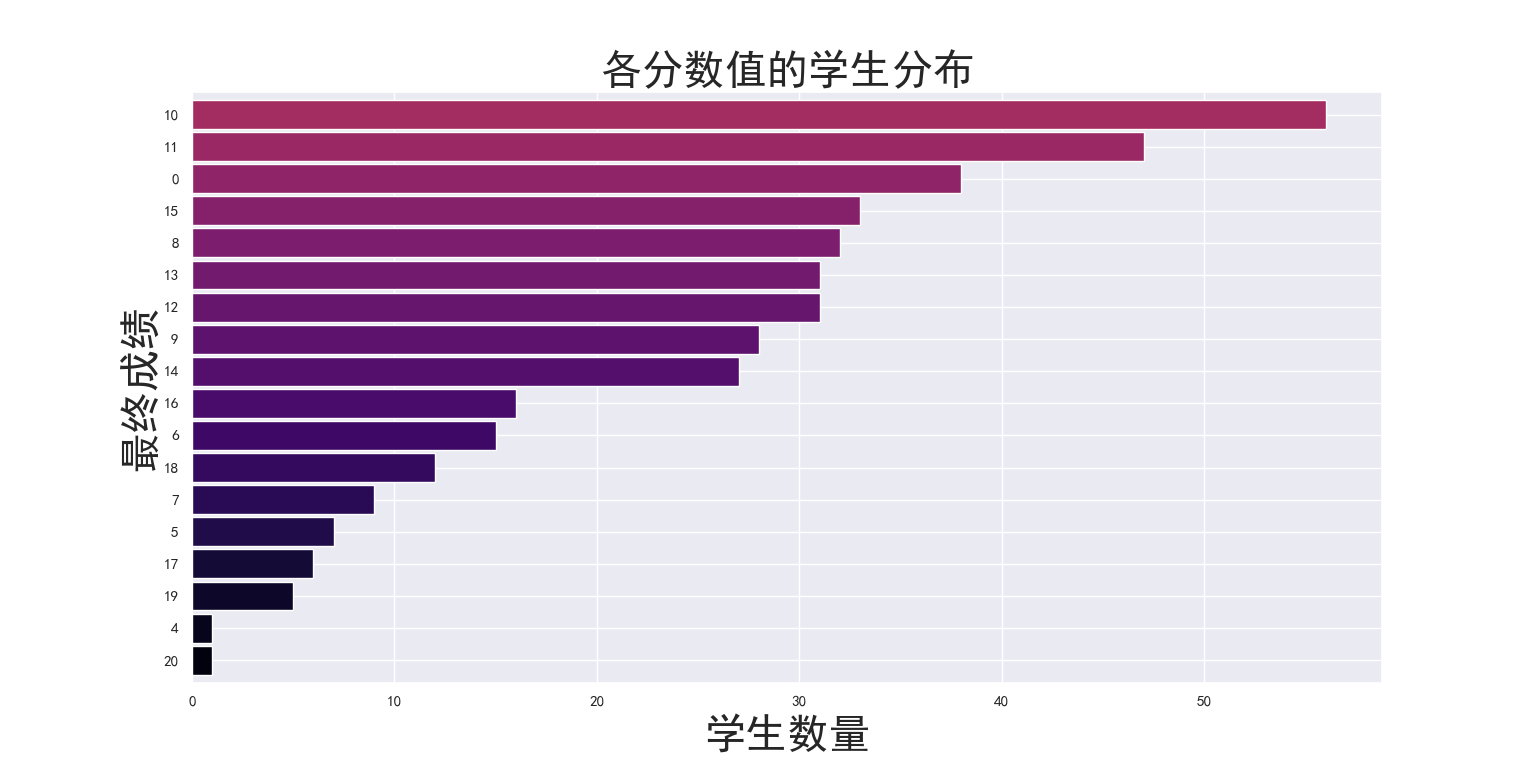
grade_counts = student['G3'].value_counts().sort_values().plot.barh(width=.9,color=sns.color_palette('inferno',40))
grade_counts.axes.set_title('各分数值的学生分布',fontsize=30)
grade_counts.set_xlabel('学生数量', fontsize=30)
grade_counts.set_ylabel('最终成绩', fontsize=30)
plt.show()
绘制出的图像如图3-2-1所示:
3.2.2 学生成绩分布直方图
3.2.1节中的图像并没有告诉我们有价值的信息,也许我们真正需要的是成绩分布直方图,即把成绩作为一个坐标轴,代码如下:
# 从低到高展示成绩分布图
grade_distribution = sns.countplot(student['G3'])
grade_distribution.set_title('成绩分布图', fontsize=30)
grade_distribution.set_xlabel('期末成绩', fontsize=20)
grade_distribution.set_ylabel('人数统计', fontsize=20)
plt.show()
绘制出的图像如图3-2-2所示:
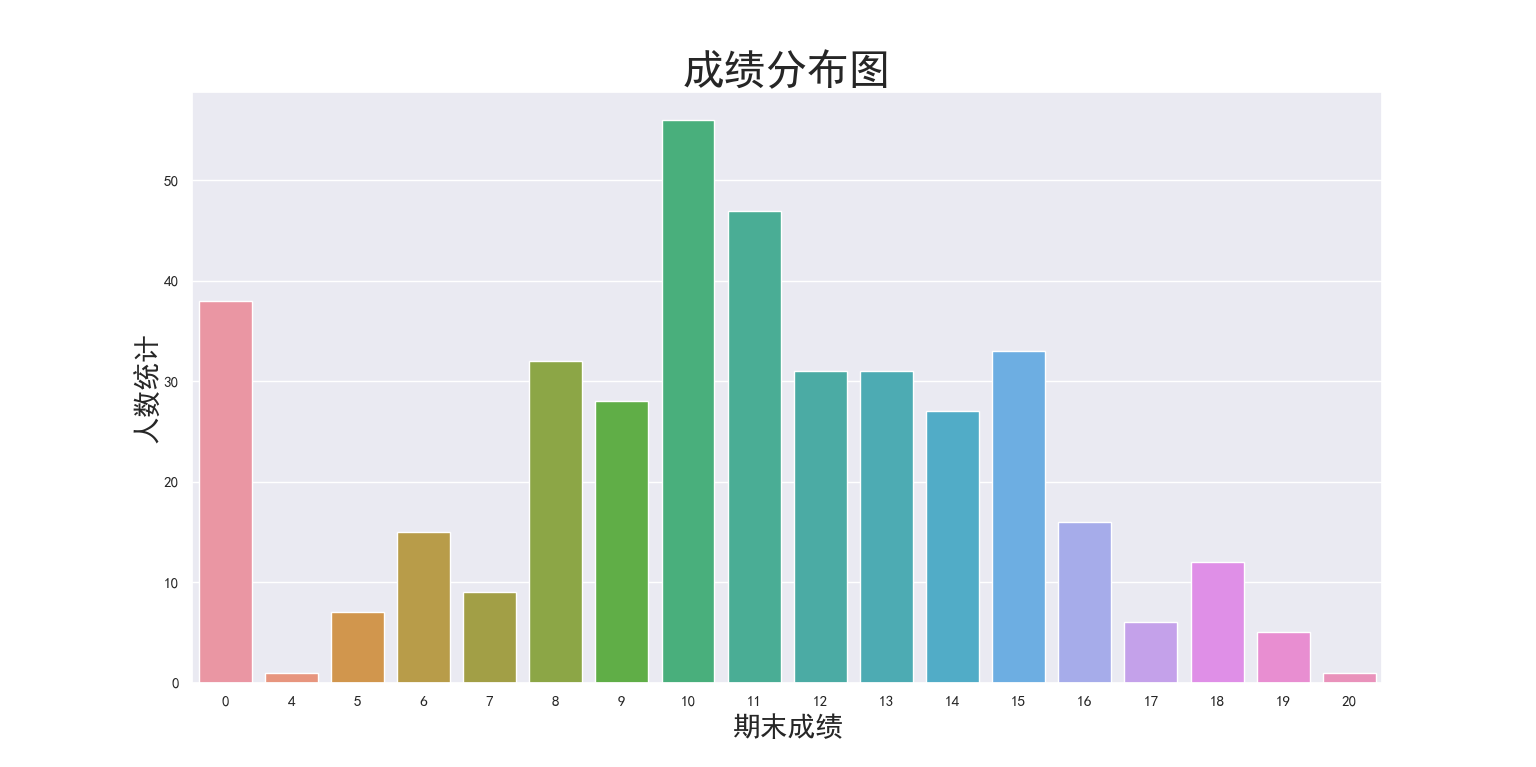
可以看出得10分和11分的学生数量很多,虽然这只是一个中等成绩,大部分学生的成绩分布在8-15分之间。更值得注意的是,居然有接近40个人得了0分,不由得让我怀疑0其实是null值,但是在检查之后发现,确实是0值,外国学生这么菜?
3.2.3 年龄因素分析
中学生正处在身体机能快速发育的时期,大脑亦是如此,不同智力水平的学生势必会得到不同的分数,因此有必要分析一下年龄对成绩的影响,并且考虑到性别因素。
以下代码可以得出性别的相关数据:
# 分析性别比例
male_studs = len(student[student['sex'] == 'M'])
female_studs = len(student[student['sex'] == 'F'])
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6493
6493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









