







在数据预处理时,因为人工采集数据的过程,经常有可能把空值和空格混在一起,一般也注意不到在本来为空的单元格里加入了空格。这就给做数据处理的人带来了麻烦,因为空值和空格都是代表的无数据,而pandas中Series的方法notnull()会把有空格的数据也纳入进来。一般这种情况采用的做法是,先将空格用NaN值替换,再进行空值填充。
源数据形式如下:
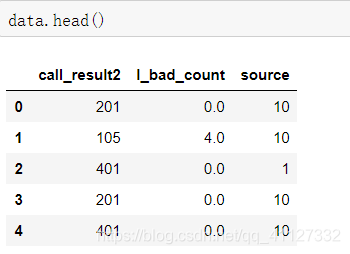
再看一下数据的行数及数据格式:
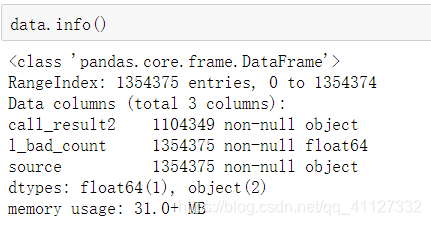
可以看到,对于data["call_result2"]这一列数据是有缺失的,我们先用nan值将空格处理了,再进行空值处理。
# 针对空格处理,用nan替换
import numpy as np
data['call_result2']=data['call_result2'].replace(r'^\s*$',np.nan,regex=True)用一个大值进行空值填充:
data[['call_result2']]=data[['call_result2']].fillna(-9999)处理后的数据情况:
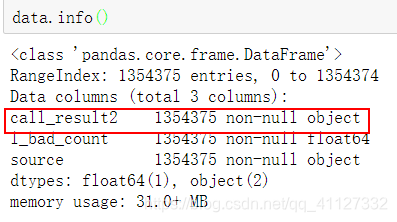
由于data["call_result2"]这一列都是数值,但它的数据类型显示是object,再转一下数据类型:
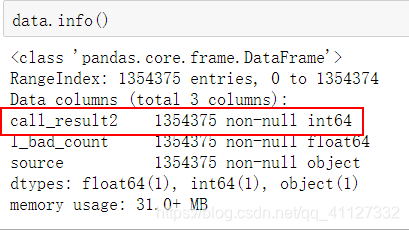
data[['call_result2']]=data[['call_result2']].astype("int64")最后的数据格式:

















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









