







目录
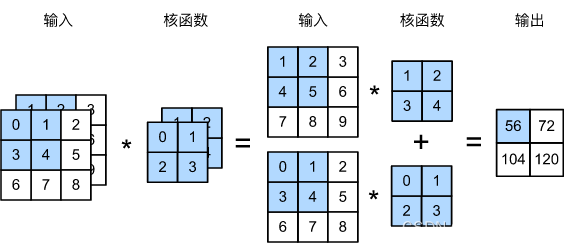
多输入通道
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。
多输出通道
在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。
假设输入是
c
i
c_i
ci个通道,要输出
c
o
c_o
co个通道,我们可以有
c
o
c_o
co个具有
c
i
c_i
ci个通道的卷积核,每个卷积核生成一个输出通道。
输入
X
:
c
i
×
n
h
×
n
w
X:c_i\times n_h\times n_w
X:ci×nh×nw
核
K
:
c
o
×
c
i
×
n
h
×
n
w
K:c_o\times c_i\times n_h\times n_w
K:co×ci×nh×nw
输出
Y
:
c
o
×
m
h
×
m
w
Y:c_o\times m_h\times m_w
Y:co×mh×mw
1 × 1 1\times 1 1×1卷积
1 × 1 1\times 1 1×1卷积层看起来似乎没有多大意义,它并没有提取相邻像素间的相关特征,但却是很受欢迎的,因为它虽然不识别空间模式,但起到了一个融合通道的作用

我们可以将
1
×
1
1\times 1
1×1卷积层看作是在每个像素位置应用的全连接层,以个
c
i
c_i
ci输入通道转换为
c
o
c_o
co个输出通道。
此外,引入
1
×
1
1\times 1
1×1卷积层,有助于减少需要学习的参数数量。
GoogleNet中的 1 × 1 1\times 1 1×1卷积:降低网络复杂性
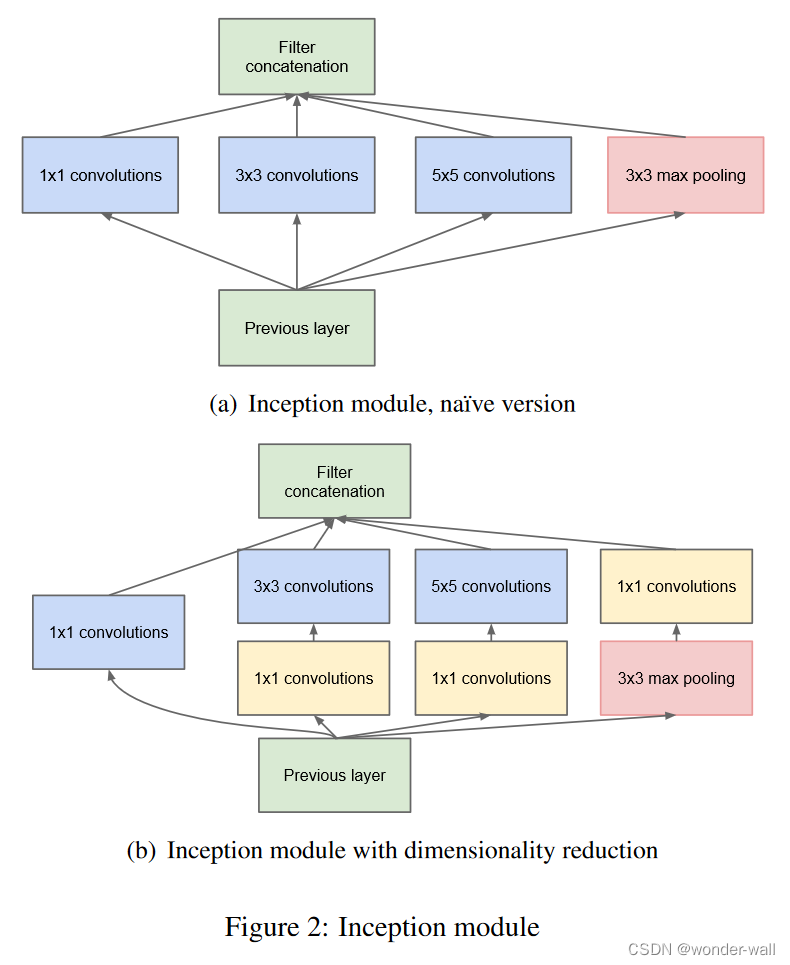
比如在上图的GoogleNet的Inception模块中,图(a)是原始模块结构,图(b)是添加了
1
×
1
1\times 1
1×1卷积层后的结构
图(a)的参数总数为
(
1
×
1
×
192
×
64
)
+
(
3
×
3
×
192
×
128
)
+
(
5
×
5
×
192
×
32
)
=
387072
(1\times 1\times 192\times 64)+(3\times 3\times 192\times 128)+(5\times 5\times 192\times 32) =387072
(1×1×192×64)+(3×3×192×128)+(5×5×192×32)=387072
图(b)的参数总数为
(
1
×
1
×
192
×
64
)
+
(
1
×
1
×
192
×
96
)
+
(
1
×
1
×
192
×
16
)
+
(
3
×
3
×
96
×
128
)
+
(
5
×
5
×
16
×
32
)
+
(
1
×
1
×
192
×
32
)
=
163328
(1\times 1\times 192\times 64)+(1\times 1\times 192\times 96)+(1\times 1\times 192\times 16)+(3\times 3\times 96\times 128)+(5\times 5\times 16\times 32)+(1\times 1\times 192\times 32)=163328
(1×1×192×64)+(1×1×192×96)+(1×1×192×16)+(3×3×96×128)+(5×5×16×32)+(1×1×192×32)=163328
NiN中的 1 × 1 1\times 1 1×1卷积:通道层面的全连接
经典的CNN架构(如LeNet、AlexNet和VGG)都有一个共同的设计模式:
通过一系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进行处理。
然而,如果使用了全连接层,可能会完全放弃表征的空间结构。
网络中的网络(NiN)提供了一个非常简单的解决方案:
在每个像素的通道上分别使用多层感知机(MLP),也就是在每个像素位置应用全连接层,
而不是将最后一个卷积层的输出一维展开然后再接上一个全连接层,从而保留了表征的空间结构。
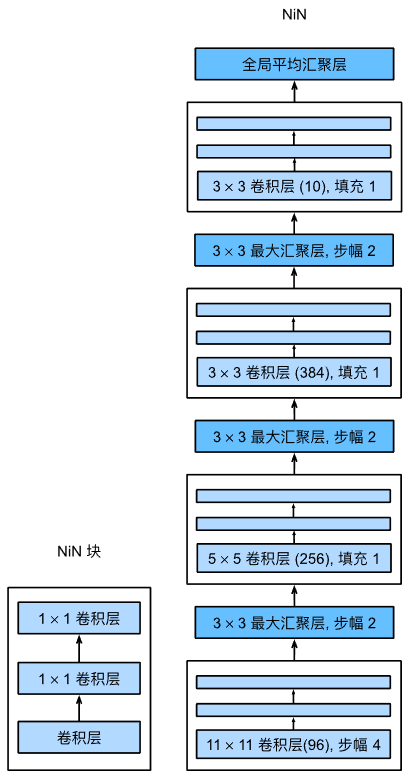
NiN块以一个普通卷积层开始,后面是两个
1
×
1
1\times 1
1×1的卷积层。这两个
1
×
1
1\times 1
1×1卷积层充当带有ReLU激活函数的逐像素全连接层。
参考资料
6.4. 多输入多输出通道 — 动手学深度学习 2.0.0-beta1 documentation
7.3. 网络中的网络(NiN) — 动手学深度学习 2.0.0-beta1 documentation
7.4. 含并行连结的网络(GoogLeNet) — 动手学深度学习 2.0.0-beta1 documentation















 3807
3807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









