





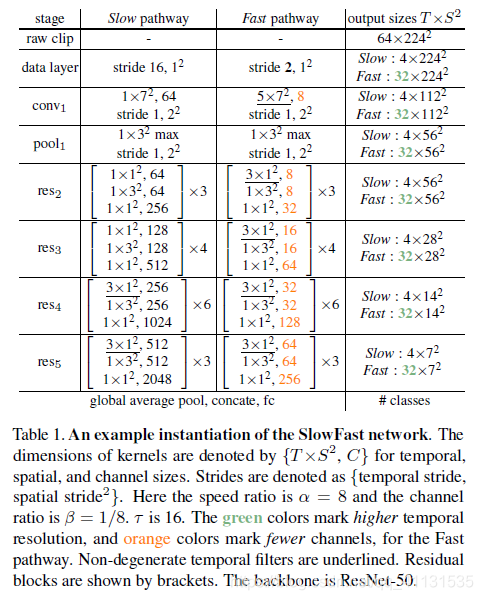
1 Slowfast模型,一共有两个通道,一个Slow pathway,一个Fast pathway,其中Slow pathway采用低采样,高通道数主要提取空时特征;Fast pathway用高时间采样,低通道数量(主要为了降低计算量),来提取时域特征,两个通道都是以3Dresnet作为backbone,提取特征的,基础网络图如下:
2 对于两个通道都没有采用temporal downsampling,假设Slow pathway里面feature shape是
{
T
,
S
2
,
C
}
\{T,S^2,C\}
{T,S2,C},Fast pathway对应的feature shape
{
α
T
,
S
2
,
β
C
}
\{\alpha T,S^2,\beta C\}
{αT,S2,βC}。其中对于Slow pathway,只在res4和res5采用non-degenerate temporal convolutions (temporal kernel size > 1),即311的kernel size,因为发现在前面2个res采用会造成准确率下降,可能原因是We argue that this is because when objects move fast and the temporal stride is large, there is little correlation within a temporal receptive field unless the spatial receptive field is large enough(i.e., in later layers)。对于Fast pathway,全部采用non-degenerate temporal convolutions,因为pathway holds fine temporal resolution for the temporal convolutions to capture detailed motion。
3 横向连接,就是将Fast pathway的特征连接到Slow pathway特征上,论文一共提供了三种方法:
(i) Time-to-channel: 直接将
{
α
T
,
S
2
,
β
C
}
\{\alpha T,S^2,\beta C\}
{αT,S2,βC}reshape成
{
T
,
S
2
,
α
β
C
}
\{ T,S^2,\alpha \beta C\}
{T,S2,αβC}
(ii) Time-strided sampling: 相当于降采样,对没
α
\alpha
α帧,提取一帧,变成
{
T
,
S
2
,
β
C
}
\{ T,S^2,\beta C\}
{T,S2,βC}
(iii) Time-strided convolution: 通过3D卷积,一个
5
∗
1
2
5*1^2
5∗12的kernel和
2
β
C
2\beta C
2βC的channel,以及对应的stride=
α
\alpha
α,padding=2
最终两个特征通过求和或者连接形式保留,通过最终实验得出Time-strided convolution以及连接形式效果最好,作为默认设置
4 对于其中超参数
α
,
β
\alpha ,\beta
α,β,论文设置
α
\alpha
α=8,对于
β
\beta
β,设置从1/32到1/4,最终取1/8
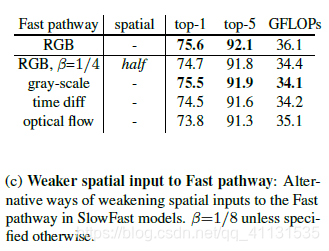
5 对于Fast pathway,采用Weaker spatial inputs,一共设置了half
spatial resolution,gray-scale,“time difference" frames,optical flow作为输入,发现灰度图和RGB图效果接近
行为动作识别(二):SlowFast
最新推荐文章于 2023-08-31 17:08:26 发布















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









