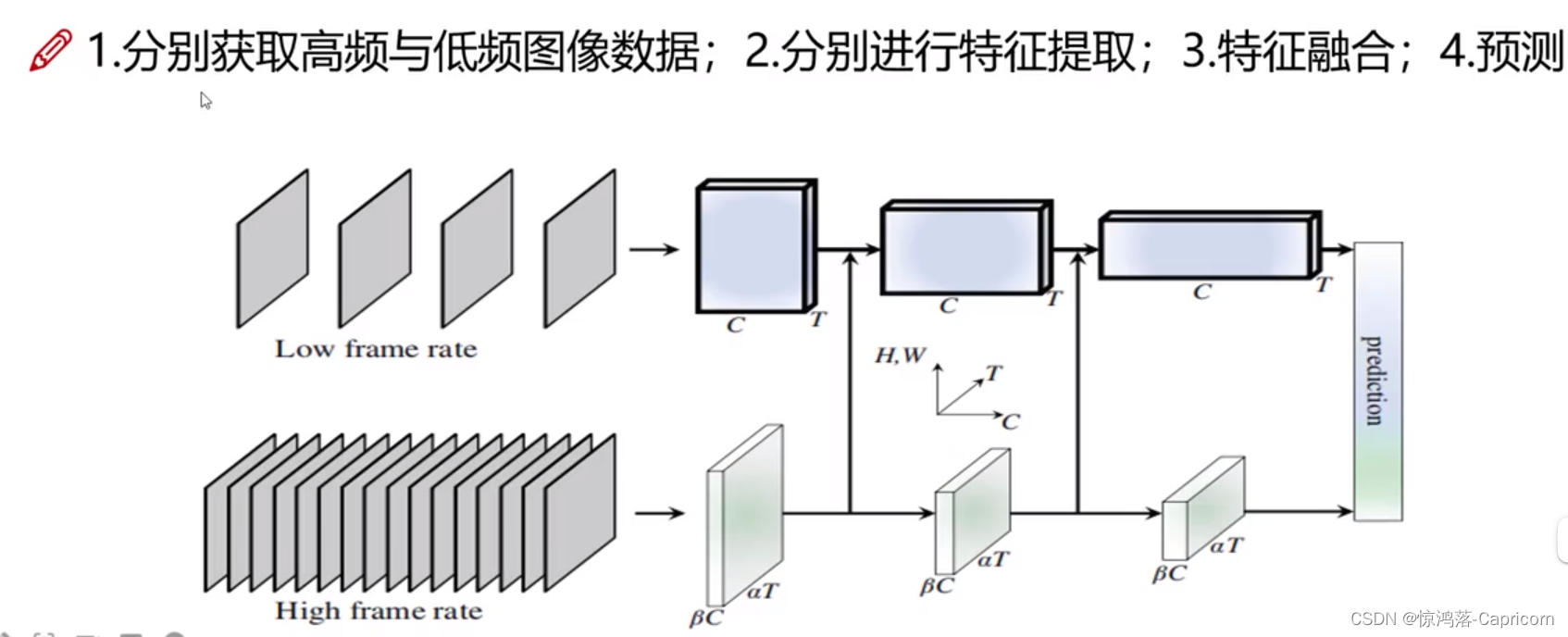
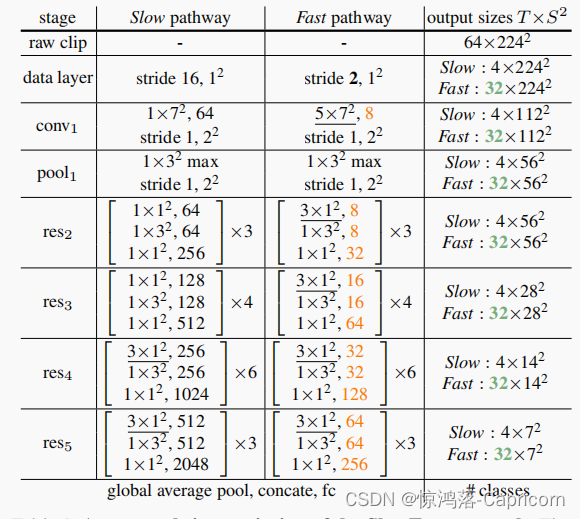
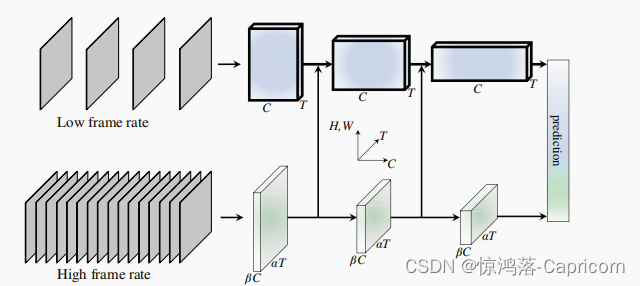
SlowFast架构是一种在视频行为识别中广泛使用的架构,它结合了慢速和快速两种不同的卷积神经网络。以下是SlowFast架构的核心代码:
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
class Bottleneck(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv3d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm3d(planes)
self.conv2 = nn.Conv3d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm3d(planes)
self.conv3 = nn.Conv3d(planes, planes*4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm3d(planes*4)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes*4:
self.shortcut = nn.Sequential(
nn.Conv3d(in_planes, planes*4, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm3d(planes*4)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class SlowFast(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(SlowFast, self).__init__()
self.in_planes = 64
self.fast = nn.Sequential(
nn.Conv3d(3, 8, kernel_size=(1, 5, 5), stride=(1, 2, 2), padding=(0, 2, 2), bias=False),
nn.BatchNorm3d(8),
nn.ReLU(inplace=True),
nn.Conv3d(8, 16, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False),
nn.BatchNorm3d(16),
nn.ReLU(inplace=True),
nn.Conv3d(16, 32, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False),
nn.BatchNorm3d(32),
nn.ReLU(inplace=True),
nn.Conv3d(32, 64, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True)
)
self.slow = nn.Sequential(
nn.Conv3d(3, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), padding=(0, 0, 0), bias=False),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
nn.Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
nn.Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
nn.Conv3d(64, 128, kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), bias=False),
nn.BatchNorm3d(128),
nn.ReLU(inplace=True)
)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool3d((1, 1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
fast = self.fast(x[:, :, ::2])
slow = self.slow(x[:, :, ::16])
x = torch.cat([slow, fast], dim=2)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
```
该代码定义了SlowFast架构中的Bottleneck块和SlowFast类,用于构建整个网络。其中,Bottleneck块是SlowFast中的基本块,用于构建各个层;SlowFast类则是整个网络的主体部分,定义了各个层的结构和前向传播的过程。在构建网络时,可以根据需要调整Bottleneck块和SlowFast类的超参数,以满足不同的视频行为识别任务需求。



























 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











